前缀和差分
在解释什么是前缀和之前,我们先回顾一下高中学过的数列:
我们这里所说的前缀和其实就是我们在高中学的数列中的Sn(前n项和),只是我们这里需要将S1 , S2 , S3 , S4 …… Sn当作一个新的数组。
为了这个式子的高度统一性,我们的S0和a0都是不存储数据的,将其设置为0,这样当n等于1的时候,也满足上面的式子。
我们看下面这段数学推导:

如果我们想特定几项an的和,那么我们就需要取遍历数组an,然后才能求出最终的和,我们发现这种情况的时间复杂度是O(N)。
但是我们使用前缀和Sn去计算的话,我们发现只需要一个简单是式子,其时间复杂度是O(1)。因此,我们便能够发掘出前缀和的作用:更快地求解数列的和
而这除了是利用了数学中的数列知识,更是一种用空间换时间的重要思想。
其实前缀和就是一个公式,因此其模板是很简单的。
#include<iostream>
using namespace std;
const int N=1e6+10;
int arr[N];
int S[N];
int main()
{
int n,m;
scanf("%d %d",&n,&m);
for(int i=1;i<=n;i++)scanf("%d",&arr[i]);
for(int i=1;i<=n;i++)S[i]=S[i-1]+arr[i];
while(m--)
{
int l,r;
scanf("%d %d",&l,&r);
printf("%d\n",S[r]-S[l-1]);
}
return 0;
}
#include<stdio.h>
const int N=1e6+10;
int main()
{
int arr[N];
int S[N];
int n,m;
scanf("%d %d",&n,&m);
for(int i=1;i<=n;i++)scanf("%d",&arr[i]);
for(int i=1;i<=n;i++)S[i]=S[i-1]+arr[i];
while(m--)
{
int l,r;
scanf("%d %d",&l,&r);
printf("%d\n",S[r]-S[l-1]);
}
return 0;
}
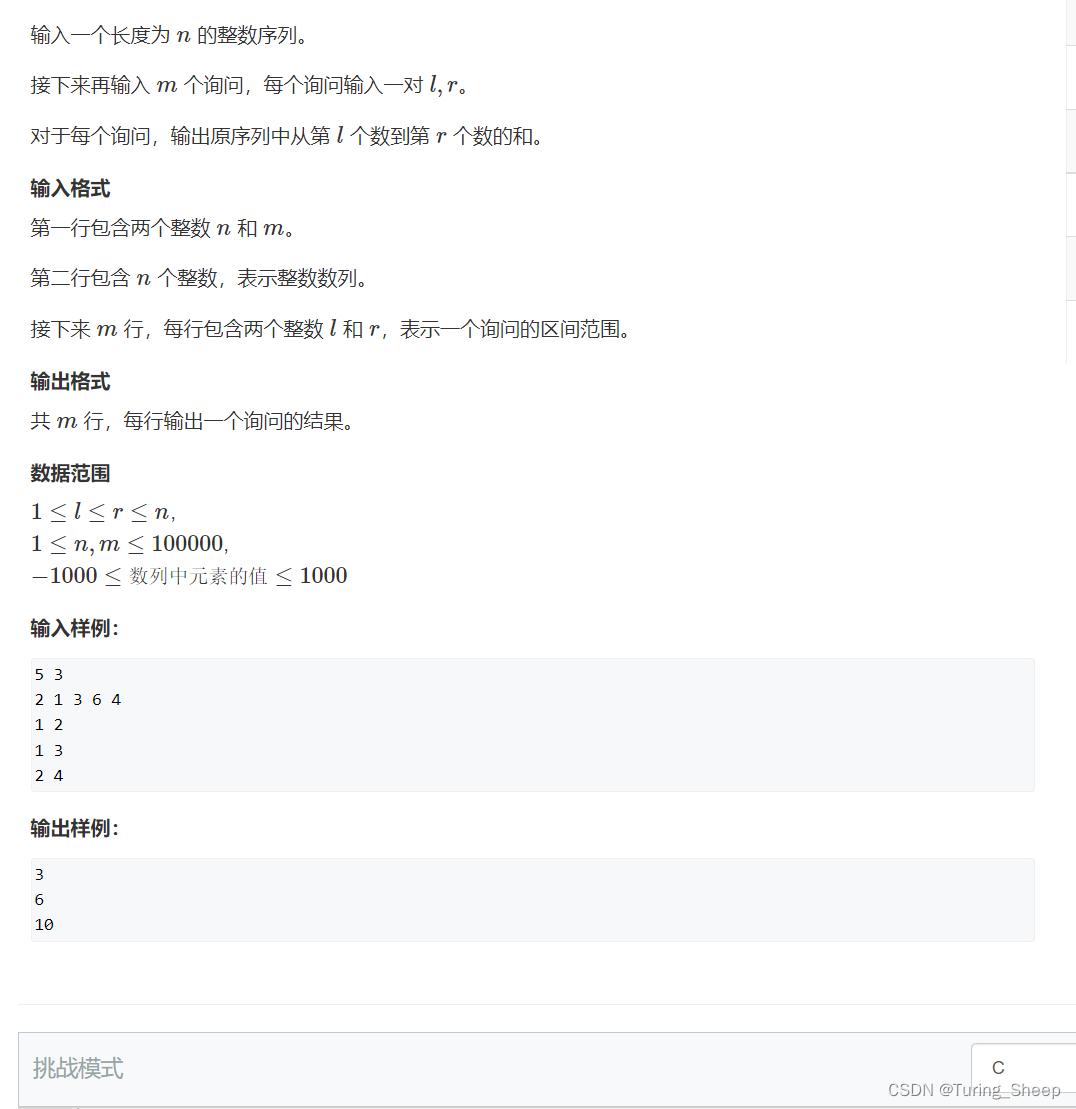
在了解思路之前,我们应该先明白,什么是二维数组的前缀和,即二维数组的前n项和所指的是哪几项的和?
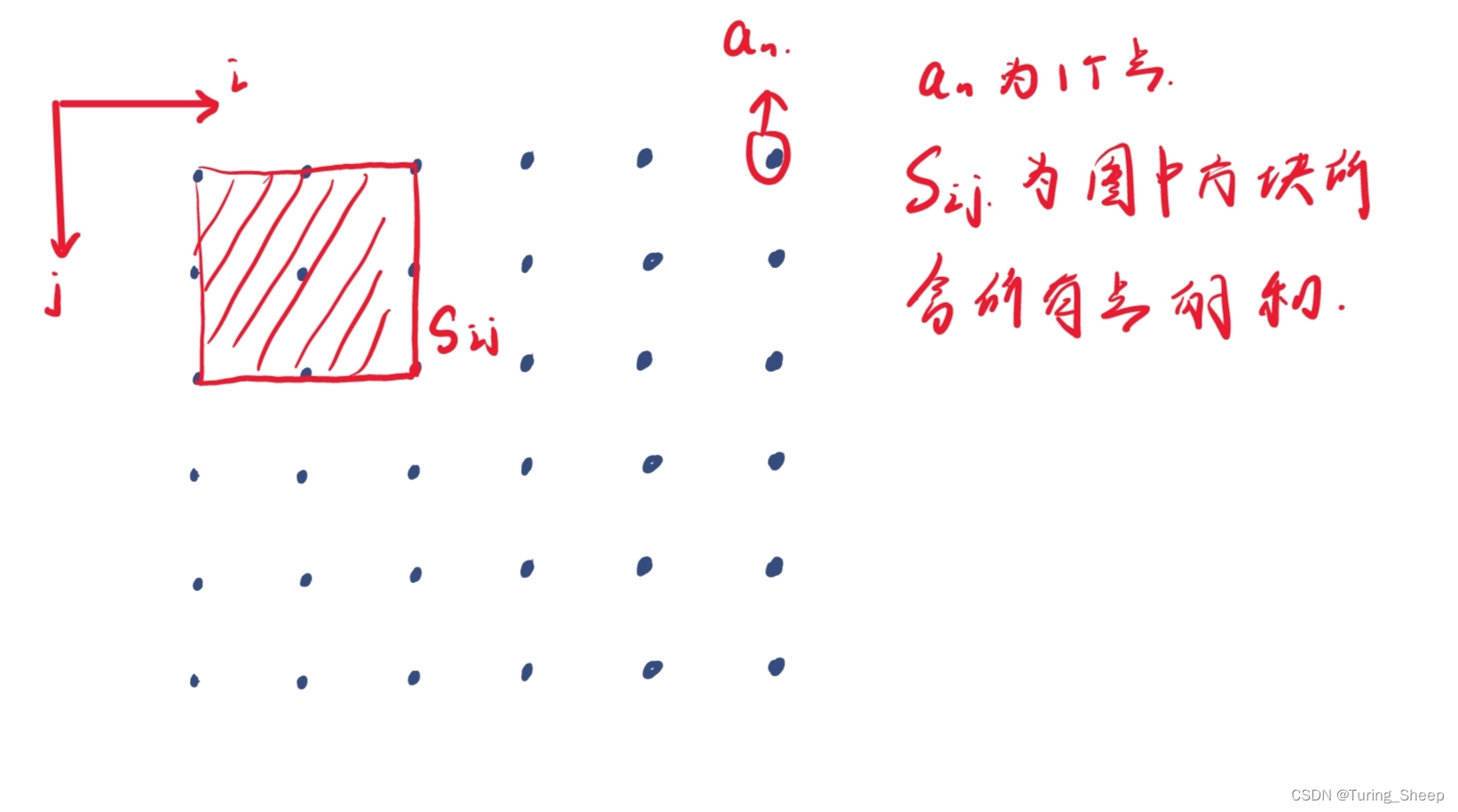
如图中所示,二维数组的前缀和就是图中方形所覆盖的an的和,包括边界!!!!
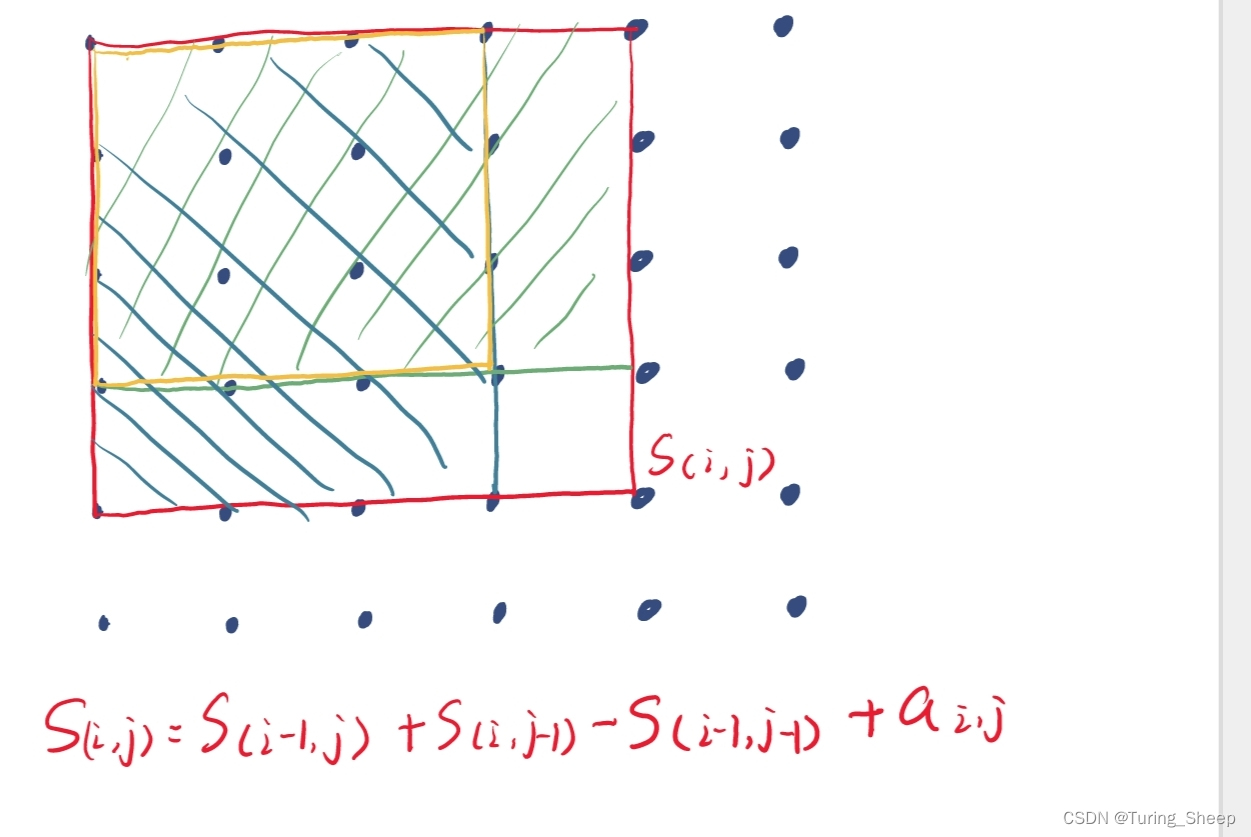
那么我们如何利用递推公式写出前缀和呢?
如下图所示:
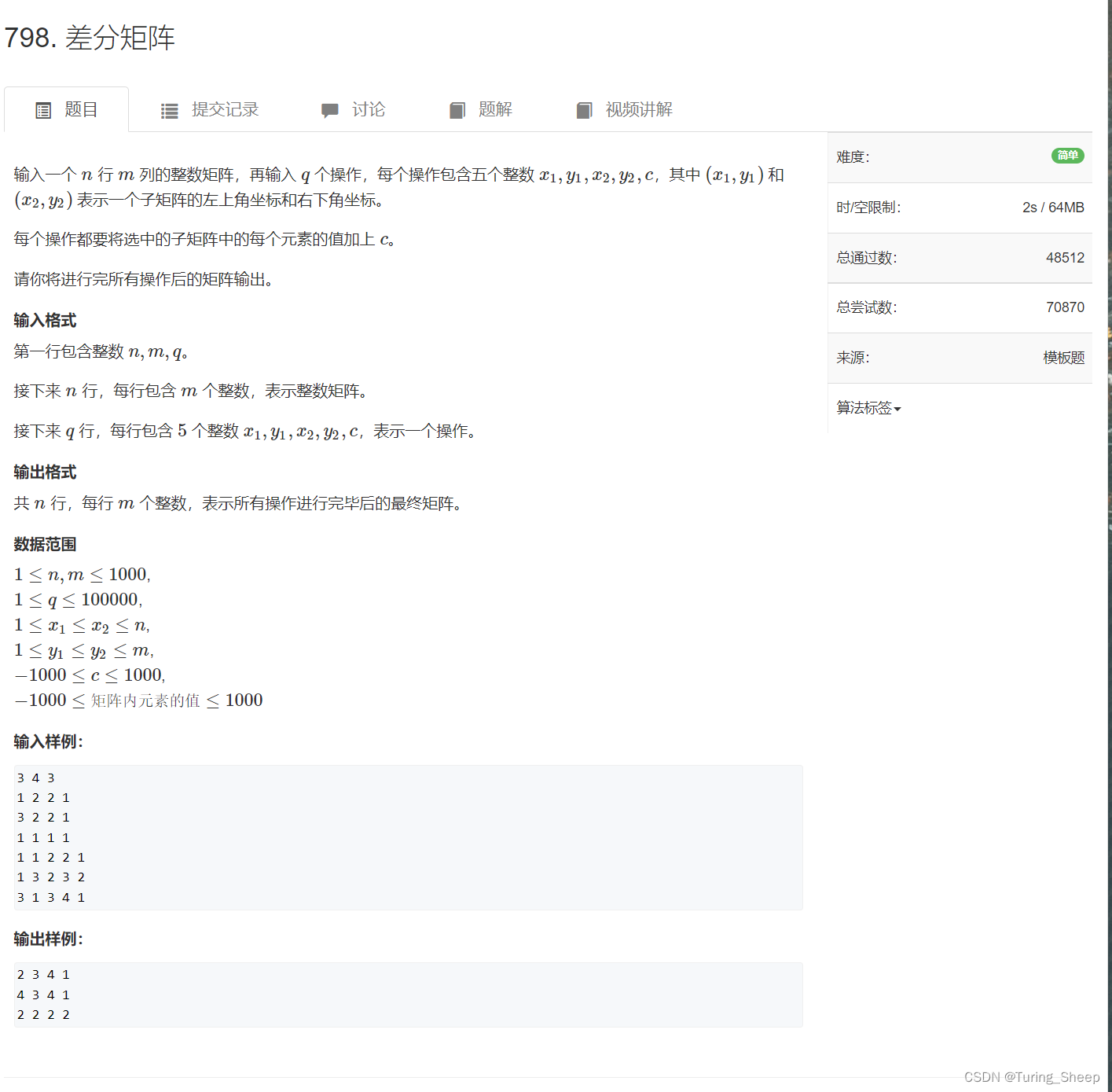
那么在理解了二维数组的前缀和的概念后,我们看下面这个问题:
我们如何计算这个紫色方形范围内的an的面积呢?
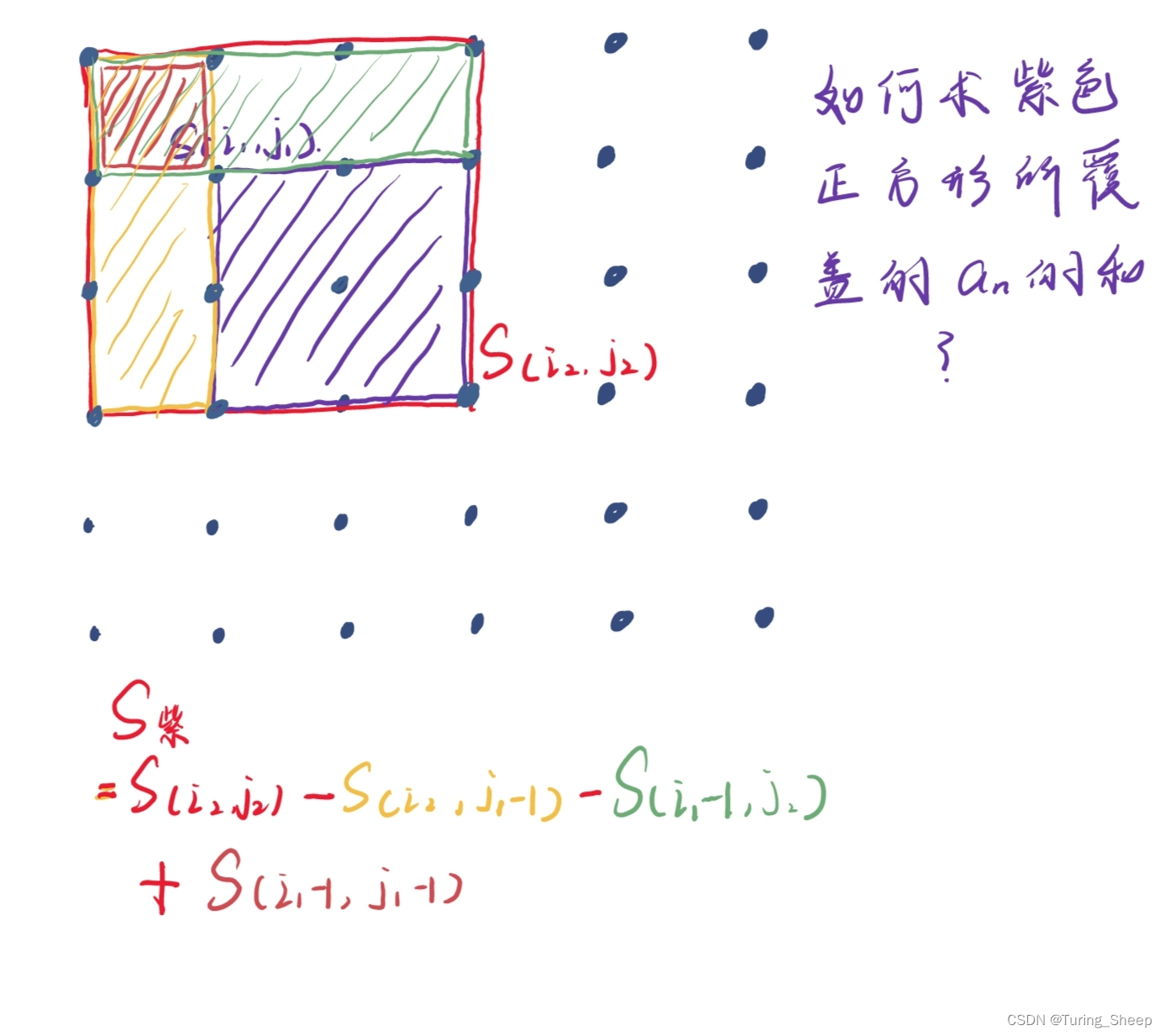
图中所示的求法类似于我们高中所学的概率内容中的容斥原理。
即我们先减去两部分,然后再加上重复减去的部分。但是我们要时刻注意边界问题,图中的式子之所以减一,就是因为紫色方形的边界也要算到前缀和中。
题目:

#include<iostream>
using namespace std;
const int N=1010;
int a[N][N];
int S[N][N];
int main()
{
int n,m,q;
scanf("%d %d %d",&n,&m,&q);
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
scanf("%d",&a[i][j]);
}
}
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
S[i][j]=S[i-1][j]+S[i][j-1]-S[i-1][j-1]+a[i][j];
}
}
while(q--)
{
int x1,y1,x2,y2;
scanf("%d %d %d %d",&x1,&y1,&x2,&y2);
printf("%d\n",S[x2][y2]-S[x2][y1-1]-S[x1-1][y2]+S[x1-1][y1-1]);
}
return 0;
}
#include<stdio.h>
const int N=1010;
int main()
{
int a[N][N];
int S[N][N];
int n,m,q;
scanf("%d %d %d",&n,&m,&q);
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
scanf("%d",&a[i][j]);
}
}
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
S[i][j]=S[i-1][j]+S[i][j-1]-S[i-1][j-1]+a[i][j];
}
}
while(q--)
{
int x1,y1,x2,y2;
scanf("%d %d %d %d",&x1,&y1,&x2,&y2);
printf("%d\n",S[x2][y2]-S[x2][y1-1]-S[x1-1][y2]+S[x1-1][y1-1]);
}
return 0;
}
我们知道前缀和是一个数组中的前N项和,其实差分就是原数组an。
因此我们就能够发现,一个数列当中,an是差分,an的前n项和sn是前缀和。
我们通过前缀和可以在时间复杂度为O(1)的情况下,计算出几项的和。那么差分则可以在时间复杂度为O(1)的情况下,给数列中的某几项都加上常数C。假设我们不适用差分的话,我们需要遍历原数组然后逐一加上常数C,此时的时间复杂度就是O(N)。
由此我们就能够总结出差分的作用:在时间复杂度是O(1)的前提下,将数组中的某几项加上特定的常数C。那么怎么加呢?我们看下面的内容。
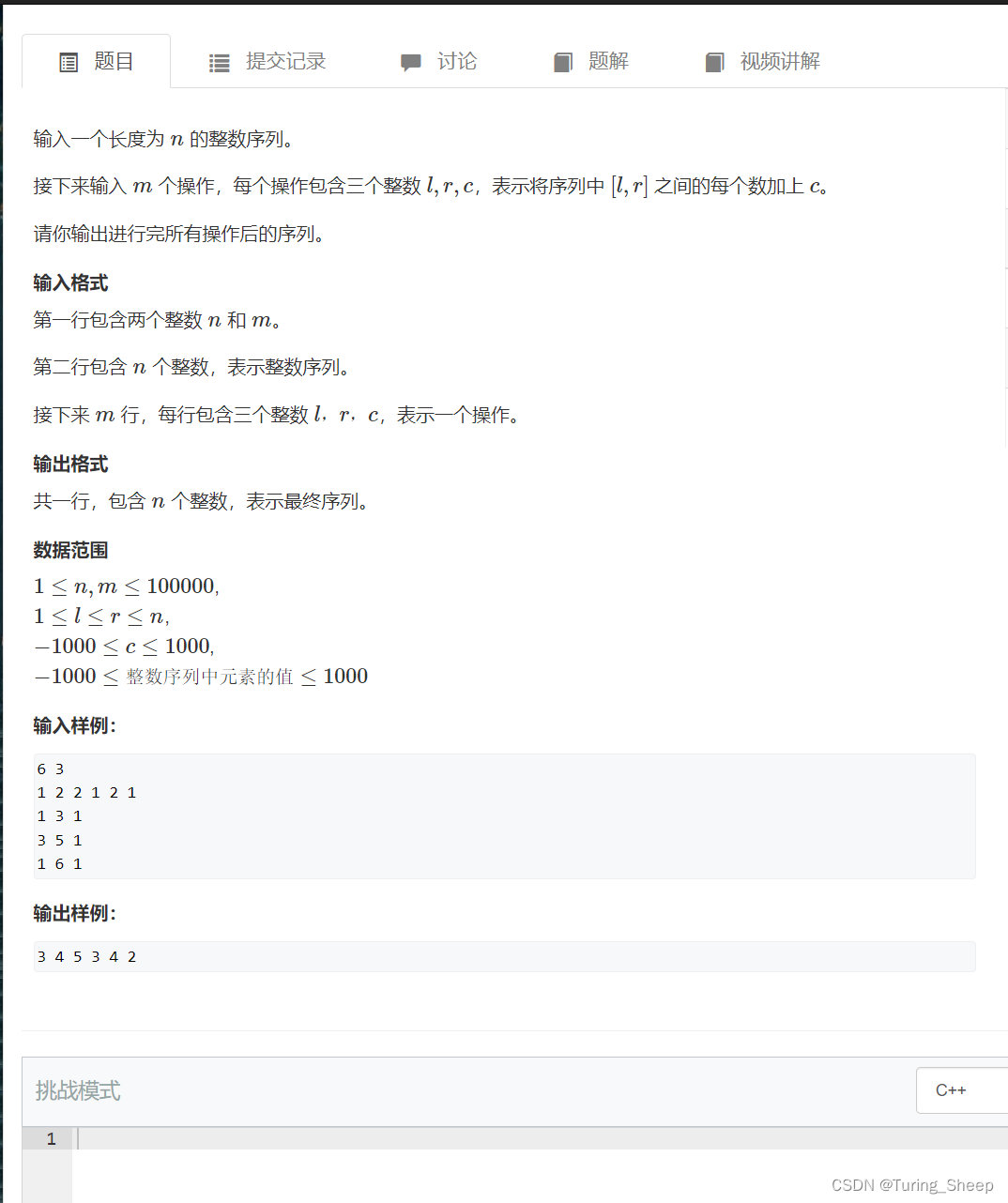
我们应该如何实现上面所说的差分的作用呢?我们看下面这张图片:

由上图可知:
我们只需要将bn中的第L项加上C,第r+1项减去C即可。这样我们在通过bn算an的时候,就能够在L到r的闭区间上的an都加上常数C。但此时的时间复杂度仅仅是O(1)。
#include<iostream>
using namespace std;
const int N=100001;
int a[N];
int b[N];
int main()
{
//读取数据
int n,m;
scanf("%d %d",&n,&m);
for(int i=1;i<=n;i++)scanf("%d",a+i);
//构造b数组:使得ai是bi的前缀和
for(int i=1;i<=n;i++)b[i]=a[i]-a[i-1];
while(m--)
{
//读取插入的区间和数据
int l,r,c;
scanf("%d %d %d",&l,&r,&c);
b[l]+=c;
b[r+1]-=c;
}
//利用b数组打印a数组
for(int i=1;i<=n;i++)printf("%d ",b[i]+=b[i-1]);
return 0;
}
#include<stdio.h>
const int N=100001;
int main()
{
int a[N];
int b[N];
int n,m;
scanf("%d %d",&n,&m);
for(int i=1;i<=n;i++)scanf("%d",a+i);
for(int i=1;i<=n;i++)b[i]=a[i]-a[i-1];
while(m--)
{
int l,r,c;
scanf("%d %d %d",&l,&r,&c);
b[l]+=c;
b[r+1]-=c;
}
for(int i=1;i<=n;i++)printf("%d ",b[i]+=b[i-1]);
return 0;
}
这里我们在介绍一种不用特意构造b数组的方法。
我们假设an数列初始化全为0,那么此时我们输入a1的时候,就相当于在[1,1]上插入一个a1。同理,an就相当于在[n,n]上插入一个an。我们就能够采用这种方式来初始化bn数组,如果不理解的话,大家可以自己写几个例子。
#include<iostream>
using namespace std;
const int N=100010;
int a[N],b[N];
void insert(int l,int r,int c)
{
b[l]+=c;
b[r+1]-=c;
}
int main()
{
int n,m;
cin>>n>>m;
for(int i=1;i<=n;i++)
{
scanf("%d",a+i);
insert(i,i,a[i]);
}
while(m--)
{
int l,r,c;
scanf("%d %d %d",&l,&r,&c);
insert(l,r,c);
}
for(int i=1;i<=n;i++)printf("%d ",b[i]+=b[i-1]);
return 0;
}
#include<stdio.h>
int a[100010],b[100010];
void insert(int l,int r,int c)
{
b[l]+=c;
b[r+1]-=c;
}
int main()
{
int n,m;
scanf("%d %d",&n,&m);
for(int i=1;i<=n;i++)
{
scanf("%d",a+i);
insert(i,i,a[i]);
}
while(m--)
{
int l,r,c;
scanf("%d %d %d",&l,&r,&c);
insert(l,r,c);
}
for(int i=1;i<=n;i++)printf("%d ",b[i]+=b[i-1]);
return 0;
}
我们先上下面的图示:
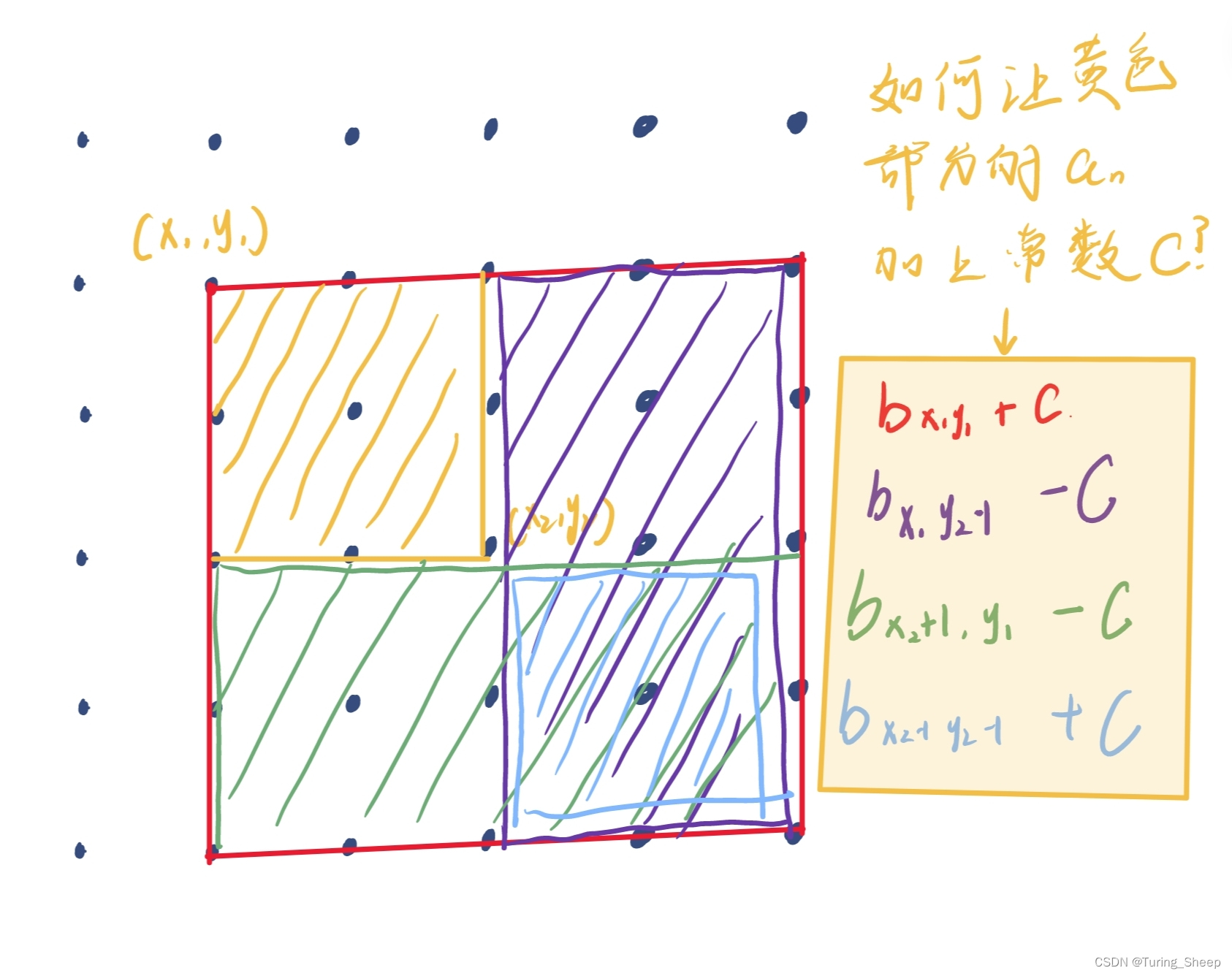
先解决第一个问题,为什么b[i,j]+c后是右下角的数列元素加c呢?其实很好理解,因为an是bn的前n项和,因此只有右下角的an计算时,才会包括该点。因此,b[i,j]+c后影响的是右下角。
然后我们就可以根据上图中公式使得黄色区域的an都加上C。
#include<iostream>
using namespace std;
const int N=1010;
int a[N][N];
int b[N][N];
void insert(int x1,int y1,int x2,int y2,int c)
{
b[x1][y1]+=c;
b[x2+1][y1]-=c;
b[x1][y2+1]-=c;
b[x2+1][y2+1]+=c;
}
int main()
{
int n,m,q;
cin>>n>>m>>q;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
scanf("%d",&a[i][j]);
insert(i,j,i,j,a[i][j]);
}
}
while(q--)
{
int x1,y1,x2,y2,c;
cin>>x1>>y1>>x2>>y2>>c;
insert(x1,y1,x2,y2,c);
}
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
a[i][j]=a[i][j-1]+a[i-1][j]-a[i-1][j-1]+b[i][j];
printf("%d ",a[i][j]);
}
cout<<endl;
}
return 0;
}
#include<stdio.h>
int a[1010][1010];
int b[1010][1010];
void insert(int x1,int y1,int x2,int y2,int c)
{
b[x1][y1]+=c;
b[x2+1][y1]-=c;
b[x1][y2+1]-=c;
b[x2+1][y2+1]+=c;
}
int main()
{
int n,m,q;
scanf("%d %d %d",&n,&m,&q);
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
scanf("%d",&a[i][j]);
insert(i,j,i,j,a[i][j]);
}
}
while(q--)
{
int x1,y1,x2,y2,c;
scanf("%d %d %d %d %d",&x1,&y1,&x2,&y2,&c);
insert(x1,y1,x2,y2,c);
}
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
a[i][j]=a[i][j-1]+a[i-1][j]-a[i-1][j-1]+b[i][j];
printf("%d ",a[i][j]);
}
printf("\n");
}
return 0;
}
在DavidFlanagan的TheRubyProgrammingLanguage中;松本幸弘theystatethatthevariableprefixes($,@,@@)areonepricewepayforbeingabletoomitparenthesesaroundmethodinvocations.谁可以给我解释一下这个? 最佳答案 这是我不成熟的意见。如果我错了,请纠正我。假设实例变量没有@前缀,那么我们如何声明一个实例变量?classMyClassdefinitialize#Herefooisaninstanceva
Ruby错误消息通常包含带单字母前缀的词法常量,例如:syntaxerror,unexpectedtIDENTIFIER,expectingkENDt和k从哪里来?还有其他字母吗?可能的关键字的主列表? 最佳答案 对于此类问题,parse.y通常是看的地方。如果没记错的话,'t'代表token,而'k'代表关键字。以下是表示标识符的不同标记(在其他事物的名称意义上):%tokentIDENTIFIERtFIDtGVARtIVARtCONSTANTtCVARtLABEL我通过快速搜索找到的kEND的唯一定义是k_end:k_end:k
我似乎找不到一种优雅的方式来做到这一点......给定一个日期,我如何找到下一个星期二,即日历月的第2个或第4个星期二?例如:给定2012-10-19然后返回2012-10-23或给定2012-10-31然后返回2012-11-13OctoberNovemberSuMoTuWeThFrSaSuMoTuWeThFrSa12345612378910111213456789101415161718192011121314151617212223242526271819202122232428293031252627282930 最佳答案
我的哈希中有以下键:address,postcode我想为它们中的每一个添加“shipping_”前缀,这样它们就变成了:shipping_address,shipping_postcode相反。我该怎么做? 最佳答案 hsh1={'address'=>"foo",'postcode'=>"bar"}hsh2=Hash[hsh1.map{|k,v|[k.dup.prepend("shipping_"),v]}]phsh2#>>{"shipping_address"=>"foo","shipping_postcode"=>"bar"}
本文已收录于专栏?《Java入门一百例》?学习指引序、专栏前言一、递推与记忆化二、【例题1】1、题目描述2、解题思路3、模板代码4、代码解析5.原题链接三、【例题1】1、题目描述2.解题思路3、模板代码4、代码解析5、原题链接三、推荐专栏四、课后习题序、专栏前言 本专栏开启,目的在于帮助大家更好的掌握学习Java,特别是一些Java学习
RubyString类中是否有任何内置函数可以为我提供Ruby中字符串的所有前缀。像这样的东西:"ruby".all_prefixes=>["ruby","rub","ru","r"]目前我已经为此做了一个自定义函数:defall_prefixessearch_stringdup_string=search_string.dupreturn_list=[]while(dup_string.length!=0)return_list但我正在寻找更像ruby、更少代码和神奇的东西。注意:当然不用说original_string应该保持原样。 最佳答案
我正在尝试解析YoutubeGdata以查看是否存在具有给定ID的视频。但是没有普通的标签,而是带有命名空间。在链接上http://gdata.youtube.com/feeds/api/videos?q=KgfdlZuVz7I有标签:1有命名空间openSearch:xmlns:openSearch='http://a9.com/-/spec/opensearchrss/1.0/'但我不知道如何在Nokogiri和Ruby中处理它。部分代码如下:xmlfeed=Nokogiri::HTML(open("http://gdata.youtube.com/feeds/api/videos
在ruby中追加和前置冒号有什么区别?例子:#Inrailsyouoftenhavethingslikethis:has_many:models,dependent::destroy为什么dependent:有一个冒号,而:models和:destroy有一个冒号?有什么区别? 最佳答案 这是Ruby1.9中的新语法,用于定义散列中作为键的符号。前置和附加的:都定义了一个symbol,但后者仅在散列初始化期间有效。你可以想到一个symbol作为轻量级字符串常量。相当于:dependent=>:destroy在1.9之前,散列是使
首先,DateTime格式变量似乎没有在任何地方记录,因此对可以在rubydocs中向我展示此内容的任何人+1。其次,在查看Date.strftime函数代码时,我没有看到任何可以让我执行以下操作的内容:2010年9月9日,星期四有人知道这是否可行吗? 最佳答案 您可能想要takealookhere.总结time=DateTime.nowtime.strftime("%A,%B#{time.day.ordinalize}%Y")请注意,您在纯Ruby(2.0)中运行,您需要调用:require'active_support/core
我正在使用OSX(使用bash),并且是unix的新手。我想知道是否可以修改一些文件以便运行ruby程序,我不需要“rubyfile.rb”,而是可以运行“ruby.rb”。有理由不这样做吗?谢谢! 最佳答案 是的,你可以做到这一点。假设ruby.rb里面有这样的东西:#!/usr/bin/envrubyputs'Helloworld'在命令行:chmod+xruby.rb这使其可执行。然后你可以这样执行:./ruby.rb有关详细信息,请参阅wikibooks.编辑(JörgWMittag):使用#!/usr/bin/en