文章目录
本文来自技术群小伙伴的分享,想加入按照如下方式
目前开通了技术交流群,群友已超过3000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:dkl88191,备注:来自CSDN+技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群+CSDN
任何收集而来的庞大数据往往是不可能一拿到就可以立马用得上的,比如一些数值大的数据,计算量复杂度高,不容易收敛,很难进行统计处理。
数据不符合正态分布,无法做一些符合正态分布的数学分析。
所以为了对数据进行更好的利用,我们需要使数据标准化。
数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。
经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。这里我们重点讨论最常用的数据归一化处理,即将数据统一映射到[0,1]区间上。
1.把数据转换为(0,1)区间的小数, 主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
2.把有量纲表达式变为无量纲表达式,解决数据的可比性。
1.归一化后加快了梯度下降求最优解的速度,如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
2.归一化有可能提高精度,一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。

概率模型(树形模型)不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、RF。而像Adaboost、SVM、LR、Knn、KMeans之类的最优化问题就需要归一化。
通过遍历feature vector里的每一个数据,将Max和Min的记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据的归一化处理:其中Max为样本数据的最大值,Min为样本数据的最小值。
def MaxMinNormalization(x,Max,Min):
x = (x - Min) / (Max - Min);
return x;
使用numpy中的np.max()和np.min()就可找到最大和最小值。这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min。
ps: 将数据归一化到[a,b]区间范围的方法:
(1)首先找到原本样本数据X的最小值Min及最大值Max
(2)计算系数:k=(b-a)/(Max-Min)
(3)得到归一化到[a,b]区间的数据:Y=a+k(X-Min) 或者 Y=b+k(X-Max)
最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法,spss默认的标准化方法就是z-score标准化。
也叫标准差标准化,这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。
def Z_ScoreNormalization(x,mu,sigma):
x = (x - mu) / sigma;
return x;
numpy中mean和std函数,sklearn提供的StandardScaler方法都可以求得均值和标准差。标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。
下面使用numpy来实现一个矩阵的标准差标准化
import numpy as np
x_np = np.array([[1.5, -1., 2.],
[2., 0., 0.]])
mean = np.mean(x_np, axis=0)
std = np.std(x_np, axis=0)
print(‘矩阵初值为:{}’.format(x_np))
print(‘该矩阵的均值为:{}\n 该矩阵的标准差为:{}’.format(mean,std))
another_trans_data = x_np - mean
another_trans_data = another_trans_data / std
print(‘标准差标准化的矩阵为:{}’.format(another_trans_data))
矩阵初值为:[[ 1.5 -1. 2. ]
[ 2. 0. 0. ]]
该矩阵的均值为: [ 1.75 -0.5 1. ]
该矩阵的标准差为:[0.25 0.5 1. ]
标准差标准化的矩阵为:[[-1. -1. 1.]
[ 1. 1. -1.]]
下面使用sklearn提供的StandardScaler方法
from sklearn.preprocessing import StandardScaler # 标准化工具
import numpy as npx_np = np.array([[1.5, -1., 2.],
[2., 0., 0.]])
scaler = StandardScaler()
x_train = scaler.fit_transform(x_np)
print(‘矩阵初值为:{}’.format(x_np))
print(‘该矩阵的均值为:{}\n 该矩阵的标准差为:{}’.format(scaler.mean_,np.sqrt(scaler.var_)))
print(‘标准差标准化的矩阵为:{}’.format(x_train))
矩阵初值为:[[ 1.5 -1. 2. ]
[ 2. 0. 0. ]]
该矩阵的均值为: [ 1.75 -0.5 1. ]
该矩阵的标准差为:[0.25 0.5 1. ]
标准差标准化的矩阵为:[[-1. -1. 1.]
[ 1. 1. -1.]]
以发现,sklearn的标准化工具实例化后会有两个属性,一个是mean_(均值),一个var_(方差)。最后的结果和使用numpy是一样的。
为什么z-score 标准化后的数据标准差为1?
x-μ只改变均值,标准差不变,所以均值变为0;(x-μ)/σ只会使标准差除以σ倍,所以标准差变为1。
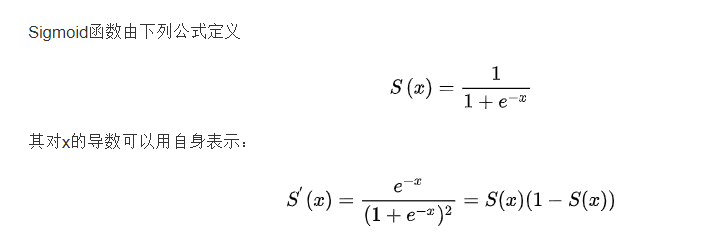
Sigmoid函数是一个具有S形曲线的函数,是良好的阈值函数,在(0, 0.5)处中心对称,在(0, 0.5)附近有比较大的斜率,而当数据趋向于正无穷和负无穷的时候,映射出来的值就会无限趋向于1和0。根据公式的改变,就可以改变分割阈值,这里作为归一化方法,我们只考虑(0, 0.5)作为分割阈值的点的情况:
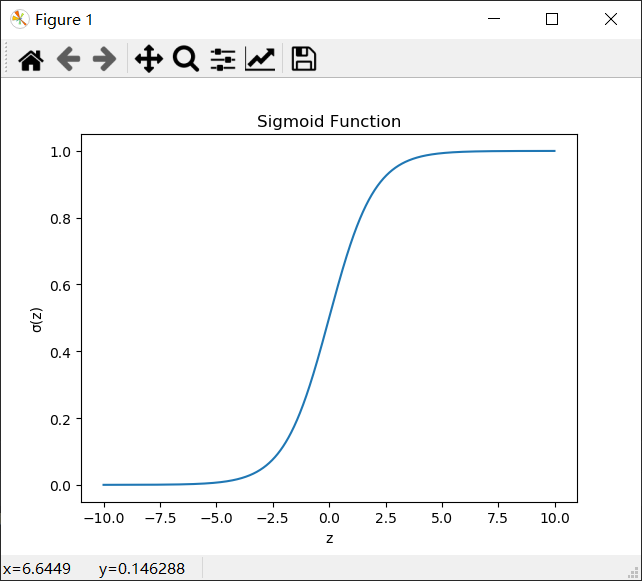
from matplotlib import pyplot as plt
import numpy as np
import math
def sigmoid_function(z):
fz = []
for num in z:
fz.append(1 / (1 + math.exp(-num)))
return fz
if __name__ == '__main__':
z = np.arange(-10, 10, 0.01)
fz = sigmoid_function(z)
plt.title('Sigmoid Function')
plt.xlabel('z')
plt.ylabel('σ(z)')
plt.plot(z, fz)
plt.show()
主要还是对机器学习中的sklearn提供的StandardScaler方法后发现数据标准化这一概念,对大佬Friedman检验进一步理解。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
question的一些答案关于redirect_to让我想到了其他一些问题。基本上,我正在使用Rails2.1编写博客应用程序。我一直在尝试自己完成大部分工作(因为我对Rails有所了解),但在需要时会引用Internet上的教程和引用资料。我设法让一个简单的博客正常运行,然后我尝试添加评论。靠我自己,我设法让它进入了可以从script/console添加评论的阶段,但我无法让表单正常工作。我遵循的其中一个教程建议在帖子Controller中创建一个“评论”操作,以添加评论。我的问题是:这是“标准”方式吗?我的另一个问题的答案之一似乎暗示应该有一个CommentsController参