文章目录
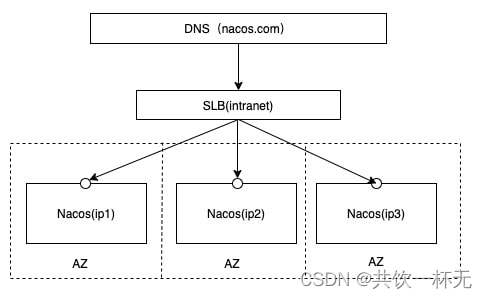
官方推荐用户把所有服务列表放到一个vip下面,然后挂到一个域名下面。
http://nacos.com:port/openAPI 域名 + SLB模式(内网SLB,不可暴露到公网,以免带来安全风险),可读性好,而且换ip方便,推荐模式:
Nacos 集群架构的设计要点:
第一步,环境准备。
Nacos 因为选举算法的特殊性,要求最少三个节点才能组成一个有效的集群。一般选举算法都建议奇数个节点,2个节点的数据一致性可能无法保障。
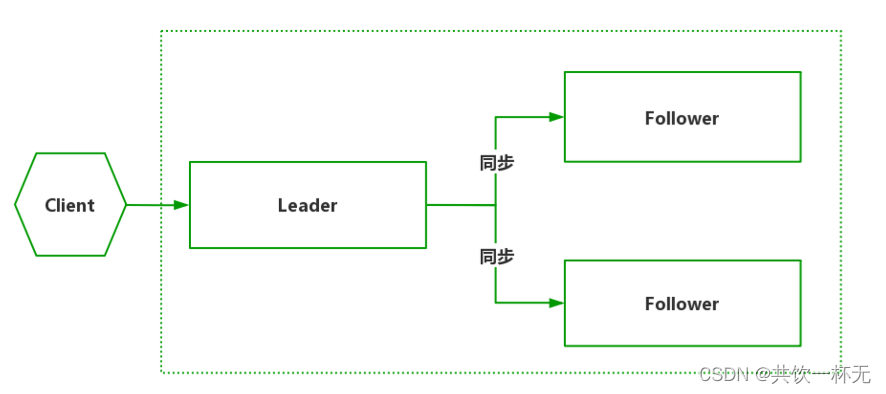
Nacos 采用 Raft 选举算法构成集群
配置需要:

官方建议最低运行内存:
准备三台服务器(虚拟机),在这三个节点上安装好 JDK1.8,并配置 JAVA_HOME 环境变量。
此外还需要额外部署一台 MySQL 数据库用于保存 Nacos 的配置管理、权限控制信息。这里推荐版本为 MySQL5.7 或者 MySQL 8.0。
第二步,下载安装 Nacos。
访问到 https://github.com/alibaba/nacos/releases/ 网址下载 Nacos 2.0.2 版本,上传到每一台 CentOS 服务器的 /usr/data 目录下,执行解压缩命令,生成 Nacos 目录
tar -xvf nacos-server-2.0.2.tar.gz
第三步,配置数据库。
使用任意 MySQL 客户端工具连接到 MySQL 数据库服务器,创建名为nacos_config的数据库,之后使用 MySQL 客户端执行 /usr/data/nacos/conf/nacos-mysql.sql 文件,完成建表工作。
nacos_config 数据库初始化脚本
nacos_config 表结构
相关表说明:
第四步,配置 Nacos 数据源。
依次打开 3 台 Nacos 服务器中的核心配置文件 application.properties,文件路径如下:
/usr/data/nacos/conf/application.properties
定位到 36 行 Count of DB “数据源”配置附近,默认数据源配置都被#号注释,删除注释按下方示例配置数据源即可。
### 设置数据库平台为mysql
spring.datasource.platform=mysql
### Count of DB: 数据库总数
db.num=1
### Connect URL of DB: 数据库连接,根据你的实际情况调整
db.url.0=jdbc:mysql://xxx:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user=root
db.password=root
第五步,Nacos 集群节点配置
在 /nacos/config 目录下提供了集群示例文件cluster.conf.example
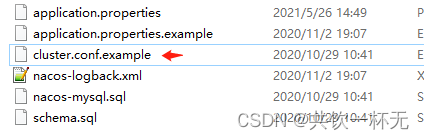
通过 cluster.conf.example 创建集群节点列表
首先利用复制命令创建 cluster.conf 文件。
cp cluster.conf.example cluster.conf
之后打开 cluster.conf,添加所有 Nacos 集群节点 IP 及端口。
ip1:8848
ip2:8848
ip3:8848
每个nacos服务器上都需要设置cluster.conf文件,Nacos 通过 cluster.conf 了解集群节点的分布情况。
第六步,启动 Nacos 服务器。
在 3 台 Nacos 节点上分别执行下面的启动命令。
sh /usr/local/nacos/bin/startup.sh
注意,集群模式下并不需要增加“-m”参数,默认就是以集群方式启动。
启动时可以通过 tail 命令观察启动过程。
tail -f /usr/local/nacos/logs/start.out
启动日志关键内容如下:
#-Xms2g -Xmx2g 默认运行时 JVM 要求 2G 可用内存
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.275.b01-0.el7_9.x86_64/bin/java -server -Xms2g -Xmx2g ...
...
#列出 Nacos 所有集群节点
INFO The server IP list of Nacos is [xxx1:8848, xxx2:8848, xxx3:8848]
...
#Nacos 正在启动
INFO Nacos is starting...
...
#集群模式启动成功,采用外置存储 MySQL 数据库
INFO Nacos started successfully in cluster mode. use external storage
当确保所有节点均启动成功,打开浏览器访问任意节点地址:
http://ip:8848/nacos/#/clusterManagement?dataId=&group=&appName=&namespace=
登录后便可看到集群列表。
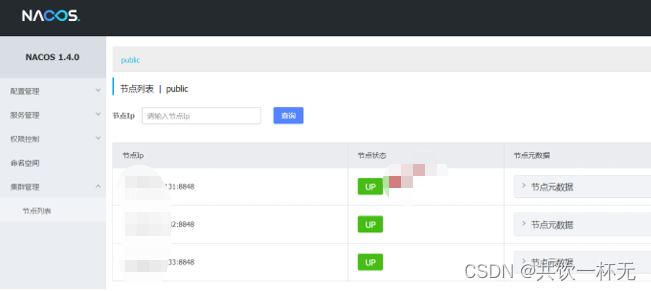
所有节点均已上线
UP 代表节点已就绪,DOWN 代表节点已离线,目前所有节点均已就绪。
第七步,微服务接入。
在开发好的微服务程序中,在 application.properties 配置 Nacos 集群的任意节点都可以完成接入工作,Nacos 内置的数据同步机制会保证各节点数据一致性。
# 应用名称,默认也是在微服务中注册的微服务 ID
spring.application.name=sample-service
# 配置 ip1/ip2/ip3 都可以接入 Nacos
spring.cloud.nacos.discovery.server-addr=ip1:8848,ip2:8848,ip3:8848
#连接 Nacos 服务器使用的用户名、密码,默认为 nacos
spring.cloud.nacos.discovery.username=nacos
spring.cloud.nacos.discvery.password=nacos
#微服务提供 Web 服务的端口号
server.port=9000
启动微服务后,访问下面三个 URL,会发现服务列表的结果是一致的,这也证明集群模式下 Nacos 能够保证各节点的数据同步。
http://ip1:8848/nacos/#/serviceManagement?dataId=&group=&appName=&namespace=
http://ip2:8848/nacos/#/serviceManagement?dataId=&group=&appName=&namespace=
http://ip3:8848/nacos/#/serviceManagement?dataId=&group=&appName=&namespace=
到这里 Nacos 集群的主体配置工作已完成,但仅会部署是远不够的,我们还需了解集群的内部运行机制。
官方参考地址:https://nacos.io/zh-cn/docs/quick-start-docker.html
https://zhuanlan.zhihu.com/p/150400342
https://blog.csdn.net/qq_40168110/article/details/103260470
https://www.cnblogs.com/jinit/p/13619493.html
Nacos 集群采用 Raft 算法实现。它是一种比较简单的选举算法,用于选举出 Nacos 集群中最重要的 Leader(领导)节点。
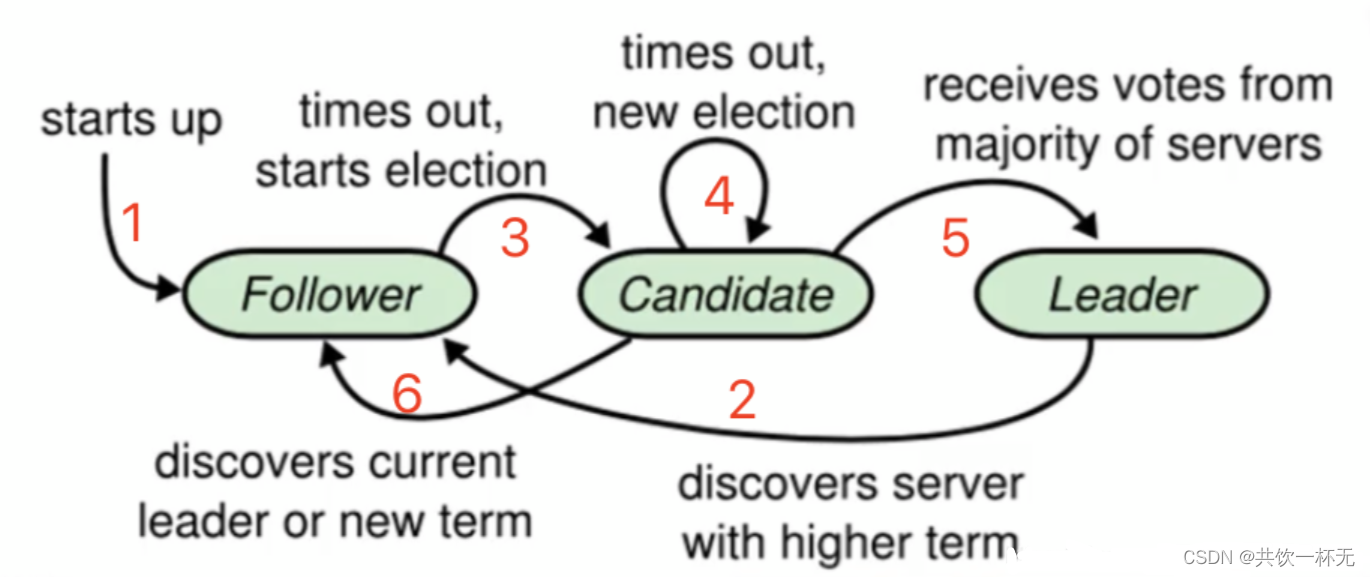
在 Nacos 集群中,每个节点都拥有以下三种角色中的一种。
在集群中选举出 Leader 是最重要的工作,产生选举的时机有三个:
在开始介绍选举过程前,先理解任期(Term)的含义:
Raft 算法将时间划分成为任意不同长度的任期(Term)。任期用连续的数字进行表示。每一个任期的开始都是一次选举(Election),一个或多个候选人会试图成为 Leader。
为了便于理解,我们使用文字+表格的形式说明选举过程。
1. 当最开始的时候,所有 Nacos 节点都没有启动。角色默认为 Follower(跟随者),任期都是 0。
| 节点 | 角色 | 任期 | 状态 |
|---|---|---|---|
| ip1 | Follower | 0 | down |
| ip2 | Follower | 0 | down |
| ip3 | Follower | 0 | down |
2. 当第一个节点(ip1)启动后,节点角色会变为 Candidate(参选者),ip1 节点在每一个任期开始时便会尝试向其他节点发出投票请求,征求自己能否成为 Leader(领导者)节点。只有算上自己获得超过半数的选票,这个 Candidate 才能转正为 Leader。在当前案例,因为 ip1 发起选举投票,但 ip2/ip3 两个节点不在线,尽管 ip1 会投自己一票,但在总 3 票中未过半数,因此无法成为 Leader。因为第一次选举没有产生 Leader,过段时间在下一个任期开始时,ip1 任期自增加 1,同时会再次向其他节点发起投票请求争取其他节点同意,直到同意票过半。
| 节点 | 角色 | 任期 | 状态 |
|---|---|---|---|
| ip1 | Candidate | 10 | up |
| ip2 | Follower | 0 | down |
| ip3 | Follower | 0 | down |
3. 在 Raft 算法中,成为 Leader 的必要条件是某个 Candidate 获得过半选票,如果 ip2 节点上线,遇到 ip1 再次发起投票。ip2 投票给 ip1 节点,ip1 获得两票超过半数就会成为 Leader,ip2 节点自动成为 Follower(跟随者)。之后 ip3 节点上线,因为集群中已有 Leader,因此自动成为 Follower。
| 节点 | 角色 | 任期 | 状态 |
|---|---|---|---|
| ip1 | Leader | 11 | up |
| ip2 | Follower | 5 | up |
| ip3 | Follower | 0 | up |
4. 当 Leader 节点宕机或停止服务,会在剩余 2 个 Nacos 节点中产生新的 Leader。如下所示ip3获得两票成为 Leader,ip2 成为 Follower,ip1已经下线但角色暂时仍为 Leader。
| 节点 | 角色 | 任期 | 状态 |
|---|---|---|---|
| ip1 | Leader | 11 | down |
| ip2 | Follower | 12 | up |
| ip3 | Leader | 12 | up |
之后 ip1 恢复上线,但此时 Nacos 集群已有 Leader 存在,ip1 自动变为 Follower,且任期归0。
| 节点 | 角色 | 任期 | 状态 |
|---|---|---|---|
| ip1 | Follower | 0 | up |
| ip2 | Follower | 12 | up |
| ip3 | Leader | 12 | up |
对于 Nacos 集群来说,只要 UP 状态节点不少于"1+N/2",集群就能正常运行。但少于“1+N/2”,集群仍然可以提供基本服务,但已无法保证 Nacos 各节点数据一致性。
以上就是 Nacos 基于 Raft 算法的 Leader 选举过程,确定 Leader 是维持 Nacos 集群数据一致的最重要前提,下面咱们来讲解在微服务注册时 Nacos 集群节点信息同步的过程。
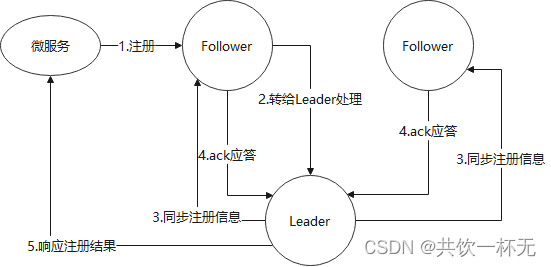
Nacos 节点间的数据同步过程:
在 Raft 算法中,只有 Leader 才拥有数据处理与信息分发的权利。因此当微服务启动时,假如注册中心指定为 Follower 节点,则步骤如下:
第一步,Follower 会自动将注册心跳包转给 Leader 节点;
第二步,Leader 节点完成实质的注册登记工作;
第三步,完成注册后向其他 Follower 节点发起“同步注册日志”的指令;
第四步,所有可用的 Follower 在收到指令后进行“ack应答”,通知 Leader 消息已收到;
第五步,当 Leader 接收过半数 Follower 节点的 “ack 应答”后,返回给微服务“注册成功”的响应信息。
此外,对于其他无效的 Follower 节点,Leader 仍会不断重新发送,直到所有 Follower 的状态与 Leader 保持同步。
本文内容到此结束了,
如有收获欢迎点赞👍收藏💖关注✔️,您的鼓励是我最大的动力。
如有错误❌疑问💬欢迎各位指出。
主页:共饮一杯无的博客汇总👨💻保持热爱,奔赴下一场山海。🏃🏃🏃
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven
我有一个类unzipper.rb,它使用Rubyzip解压文件。在我的本地环境中,我可以成功解压缩文件,而无需使用require'zip'明确包含依赖项但是在Heroku上,我得到一个NameError(uninitializedconstantUnzipper::Zip)我只能通过使用明确的require来解决问题:为什么这在Heroku环境中是必需的,但在本地主机上却不是?我的印象是Rails自动需要所有gem。app/services/unzipper.rbrequire'zip'#OnlyrequiredforHeroku.Workslocallywithout!class
出于某种原因,heroku尝试要求dm-sqlite-adapter,即使它应该在这里使用Postgres。请注意,这发生在我打开任何URL时-而不是在gitpush本身期间。我构建了一个默认的Facebook应用程序。gem文件:source:gemcuttergem"foreman"gem"sinatra"gem"mogli"gem"json"gem"httparty"gem"thin"gem"data_mapper"gem"heroku"group:productiondogem"pg"gem"dm-postgres-adapter"endgroup:development,:t
有没有办法在liquidtemplate中输出(用于调试/信息目的)可用对象和对象属性??也就是说,假设我正在使用jekyll站点生成工具,并且我在我的index.html模板中(据我所知,这是一个液体模板)。它可能看起来像这样{%forpostinsite.posts%}{{post.date|date_to_string}}»{{post.title}}{%endfor%}是否有任何我可以使用的模板标签会告诉我/输出名为post的变量在此模板(以及其他模板)中可用。此外,是否有任何模板标签可以告诉我post对象具有键date、title、url、摘录、永久链接等