
承接上文:算法效率与时间复杂度(8条消息) 时间复杂度计算超全整理!!(数据结构和算法的第一步_vpurple__的博客-CSDN博客
目录
1.2.3计算用数组实现还有用变量实现的斐波拉契数列的空间复杂度
相比而言现在算法不那么关注空间复杂度,因为现在的设备的存储空间都比较大。
1GB=1024*1024*1024字节
1GB 大概是10亿字节
1MB 大概是100万字节
1GB=1024MB 1MB=1024KB 1KB=1024字节
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 ,也就是额外占取的空间的大小。
空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定。
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
O()括号里面的数更多的表达的是这个算法的量级,大O是一个估算,并不是准确的执行次数。
推导大O阶方法:
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项系数存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
// 计算BubbleSort的空间复杂度?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}冒泡排序的空间复杂度为:O(1)
分析如下:

// 计算阶乘递归Fac的空间复杂度?
long long Fac(size_t N)
{
if(N == 0)
return 1;
return Fac(N-1)*N;
}阶乘递归的时间复杂度:O(N).
分析如下:

// 计算Fibonacci的空间复杂度?
// 返回斐波那契数列的前n项
long long* Fibonacci(size_t n)
{
if(n==0)
return NULL;
long long * fibArray = (long long *)malloc((n+1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n ; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray [i - 2];
}
return fibArray;
}
用数组实现斐波拉契数列的空间复杂度:O(N).
用三个变量来回计算斐波拉契数列的空间复杂度是:O(N).
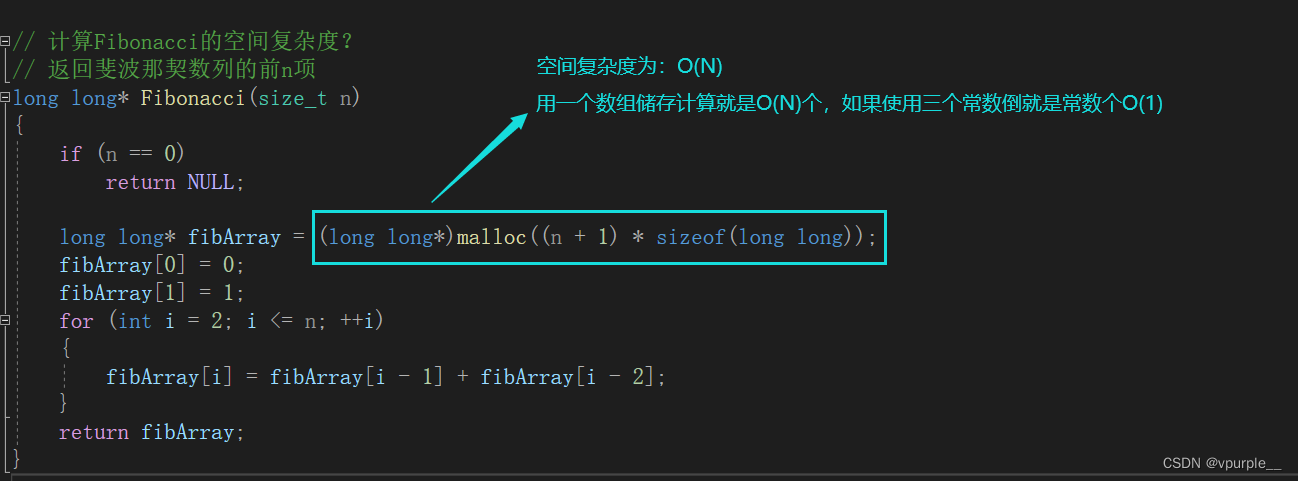
// 计算斐波那契递归Fib的时间复杂度?
long long Fib(size_t N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}用递归实现的斐波拉契数的空间复杂度:O(N).
先计算一下在主函数中重复调用两个函数,函数所占用的空间大小。

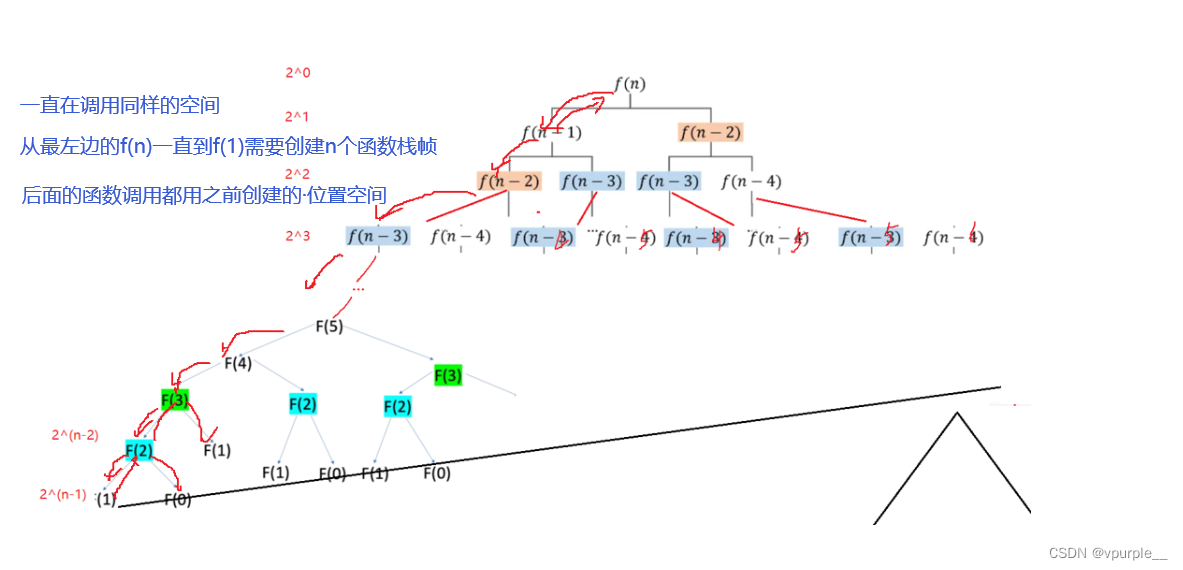
空间是可以重复利用的。
把空间还给操作系统,释放了,而不是销毁了,只是把使用权交给操作系统了
空间复杂度基本上是O(1)或者O(N),其它的空间复杂度不常见。假设开一个N*N的数组,那么它的空间复杂度是O(N^2)。结构体不讨论结构体个数,只看整体。不看具体,只看量级。
一般算法常见的复杂度如下:
表格越往下复杂度相对越高
| 5201314 | O(1) | 常数阶 |
| 3log(2)n+4 | O(log(2)n) | 对数阶 |
| 3n+4 | O(n) | 线性阶 |
| 2n+3nlog(2)n+14 | O(nlog(2)n) | nlogn阶 |
| 3n^2+4n+5 | O(n^2) | 平方阶 |
| 4n^3+3n^2+4n+5 | O(n^3) | 立方阶 |
| 2^n | O(2^n) | 指数阶 |
图例如下所示(图片来源于百度):
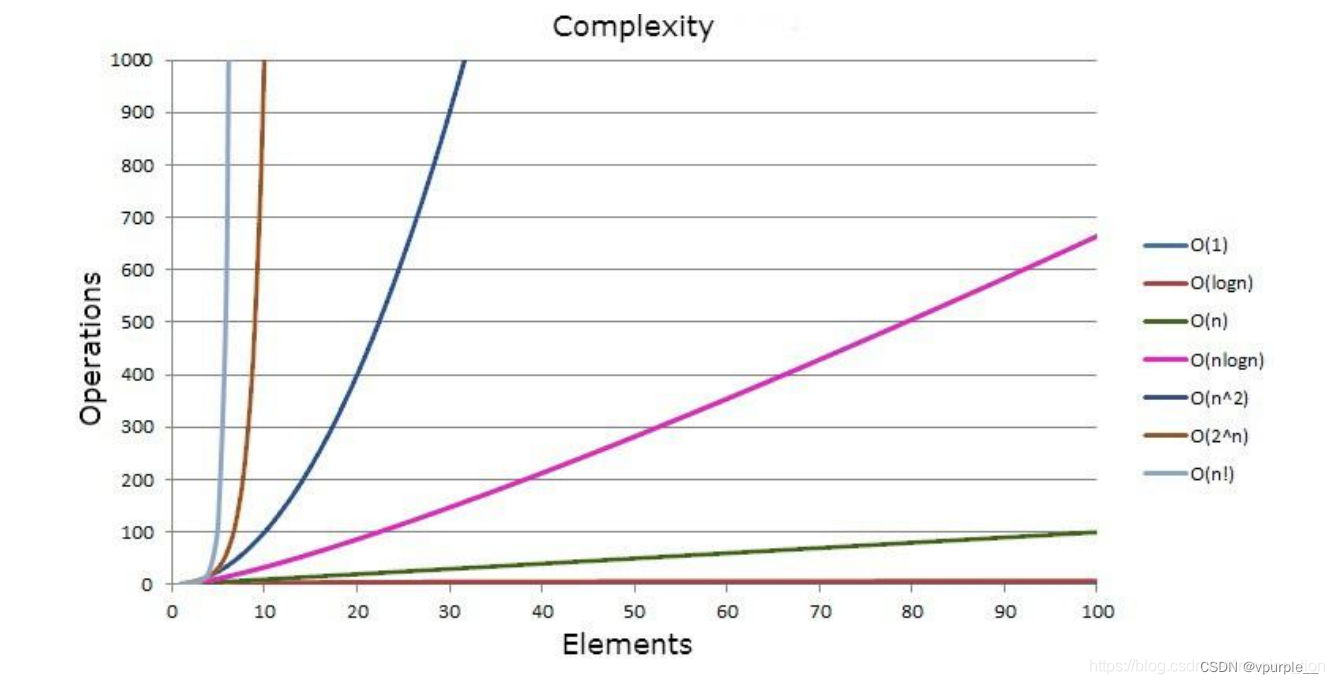
请注意: 与 logN 是等价的。
你好!这里是媛仔,希望这篇对于空间复杂度的总结对你有所帮助,可以关注我的专栏《数据结构进阶之路———努力版》,这个专栏之后也会同步更新数据结构相关内容,希望对你有所帮助,也希望可以与大家多多交流,共同进步!!祝你天天开心^-^,媛仔去肝下一篇啦~~

我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
我在加密来self正在使用的第三方供应商的值时遇到问题。他们的指令如下:1)Converttheencryptionpasswordtoabytearray.2)Convertthevaluetobeencryptedtoabytearray.3)Theentirelengthofthearrayisinsertedasthefirstfourbytesontothefrontofthefirstblockoftheresultantbytearraybeforeencryption.4)EncryptthevalueusingAESwith:1.256-bitkeysize,2.25
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
我正在开发西洋跳棋实现,其中有许多易于测试的方法,但我不确定如何测试我的主要#play_game方法。我的大多数方法都可以很容易地确定输入和输出,因此也很容易测试,但这种方法是多方面的,实际上并没有容易辨别的输出。这是代码:defplay_gameputs@gui.introwhile(game_over?==false)message=nil@gui.render_board(@board)@gui.move_requestplayer_input=getscoordinates=UserInput.translate_move_request_to_coordinates(play
我已经找到了几个使用datamapper的示例,并且能够让它们正常工作。不过,所有这些示例都是针对sqlite数据库的。我正在尝试将数据映射器与postgresql一起使用。我将datamapper中的调用从sqlite3更改为postgres,并且我已经安装了dm-postgres-adapter。但它仍然不起作用。我还需要做什么? 最佳答案 与SQLite不同,PostgreSQL不将数据库存储在单个文件中。在你拥有createdyourdatabase之后,尝试这样的事情:DataMapper.setup:default,{: