某个接口耗时长(247ms),但里面逻辑不算复杂,只进行了简单的对象引用以及操作了多次Redis
接口里通过链路追踪以及日志查询发现主要是操作Redis的这条链路耗时变长
原因可能是:
经测试发现以下这些问题
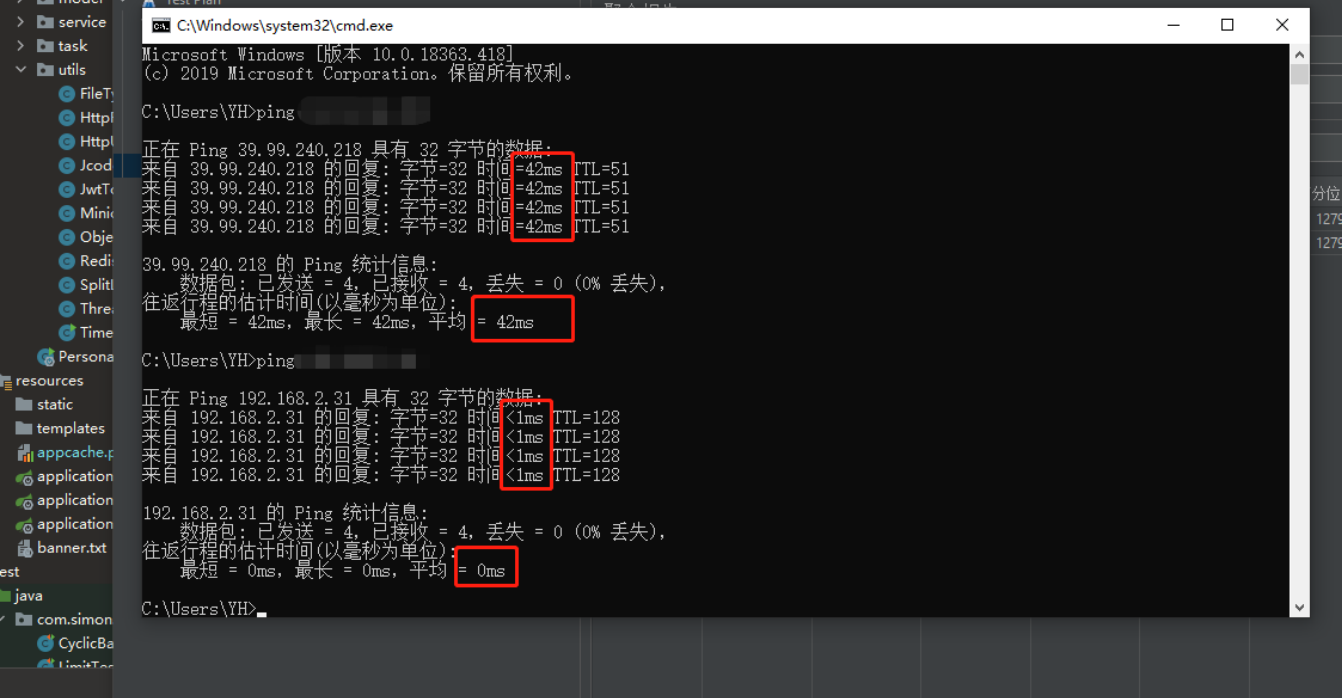
使用本机ping服务器,网络延迟大概在42ms(ping内网<1ms,ping公司线上环境7ms),属于 高延迟
内部逻辑对获取Redis连接进行耗时记录,发现除首次获取连接需30ms,后续获取连接耗时 <1ms,
内部对Redis的一个get操作需要47ms(高耗时)
步骤二总结:
由于Redis是使用Docker搭建,在虚拟化环境可能会差一些,不过还是先查看延迟峰值以及平均响应时 间
100秒内测试结果

60秒内测试结果
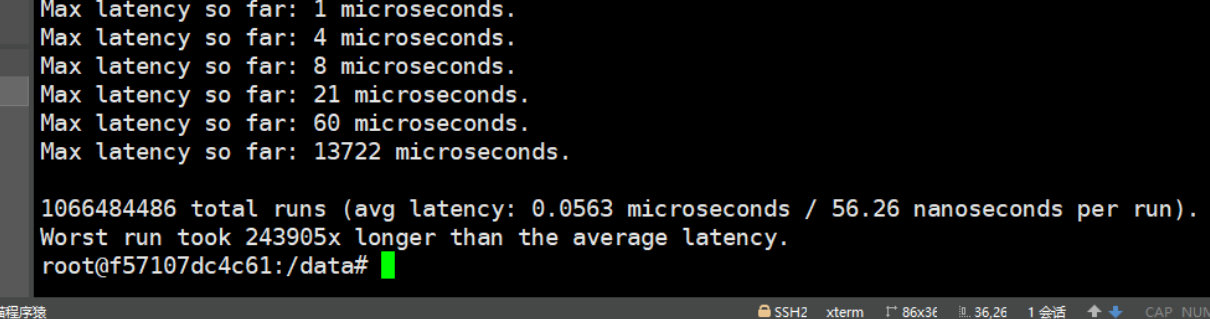
从测试数据可以看出
总结:从这一测试数据看单一get命令是不会到40+ms
通过给Redis设置slowlog时间为5ms,从业务代码里操作set和get命令各200条,均无发现slowlog。
接口里使用的命令只是简单的get,set操作,并不是SORT、SUNION等聚合类容易导致操作延迟变大的 命令。
且O(N)里的N值并不大,也不需要花费很多时间在数据协议的组装和网络传输过程中。
所以该指标不做测试。⚠ Ps:若是想测试该指标也可用slowlog进行排查。
接口里操作的都不是bigkey,该指标不做测试。有需要可先使用redis命令扫描bigkey。注意:扫描时与 上述提到的延迟峰值都会使Redis的OPS突增。
该Redis里并没有过多数据,该指标不做测试。
从数据上来看,内存并没有使用很多。
如3.5中所说,该指标不做测试
从springboot里使用了nio开发的lettuce Redis线程池,当设置连接数为500时,在代码层面开启多个线 程一直跑,Redis客户端连接数可以达到峰值,所以这块暂时没有问题。
根据上述数据总结出99%是网络问题造成的获取数据延迟。当然还有很多指标都没有列举,例如:是否 开启内存大页、是否开启AOF造成Redis、或者是是否使用Swap等。由于服务器的Redis也算比较简 单,这些也就默认是正常了
后续可以再继续监控
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我喜欢RVM。我意识到它的主要用例是让不同的用户在不同版本的Ruby之间切换。但是假设我正在将Rails应用程序部署到服务器,并且我只想运行单个版本的Ruby。特别是,我想要1.9.2,用RVM安装它很容易,但没有它就很痛苦。有没有一种方法可以让我说“我希望这是所有用户的规范Ruby安装”(连同它的所有gem),而不必手动创建一堆符号链接(symboliclink)并在每次更新到更新时更改它们Ruby版本? 最佳答案 以root身份安装RVM并执行sudorvmuse1.9.2--default。任何采购/usr/local/rvm
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
我已经开始学习Ruby,我已经阅读了一些教程,甚至还买了一本书(“ProgrammingRuby1.9-ThePragmaticProgrammers'Guide”),我遇到了一些以前从未见过的新东西使用我知道的任何其他语言(我是一名PHP网络开发人员)。block和过程。我想我明白它们是什么,但我不明白的是为什么它们如此伟大,以及我应该在何时何地使用它们。我到处都看到他们说block和过程是Ruby中的一个很棒的特性,但我不理解它们。这里有人能给像我这样的Ruby新手一些解释吗? 最佳答案 block有很多好处。电梯演讲:bloc
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭9年前。Improvethisquestion我现在是java专业人士,我喜欢使用ruby。这两种语言有什么相似之处吗?主要区别是什么?因为两者都是面向对象的。