慢查询定义及作用
查询慢的日志,指mysql记录所有执行超过long_query_time参数设定的时间阈值的SQL语句的日志,该日志能为SQL语句的优化带来很好的帮助,默认情况下慢查询日志是关闭的,要使用慢查询日志功能,首先要开启慢查询日志功能。
show variables like 'slow_query_log';
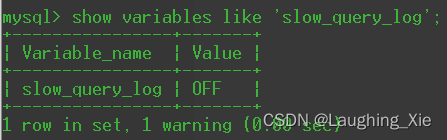
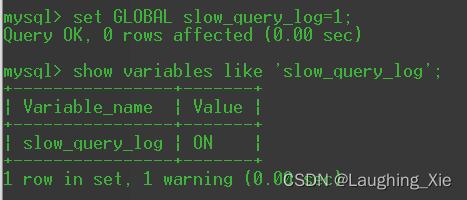
将其开启
但是多慢算慢?MySQL中可以设定一个阈值,将月星时间超过该值的所有SQL语句都记录到慢查询日志中。long_query_time参数就是这个阈值,默认值为10 ,代表10秒。如下图:
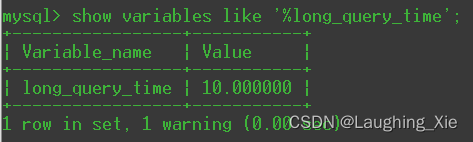
# 默认10秒,这里自测 可设为0
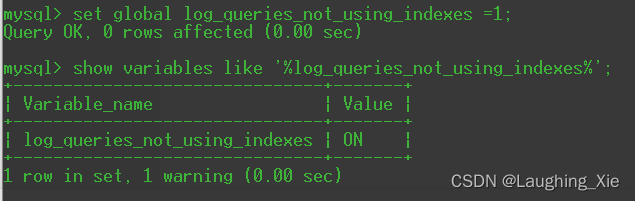
set global long_query_time=0 ; 同时,表中可能有SQL没走索引走的全表扫描,但是由于数据量少,又达不到慢查询的时间标准,但后续表数据可能越来越大,对于这种情况而言,可以通过控制参数,让 MySQL对于没有使用索引的SQL语句也会记录到慢查询日志文件中
show variables like '%log_queries_not_using_indexes%'; --默认可能关闭的
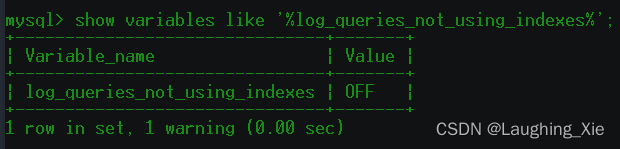
通过设置全局变量的值,来开启此功能
对于产生的慢查询日志,可以指定输出的位置,通过参数log_output来控制,可以输出到表(一般不推荐)或者文件或者一起都保存。(推荐放到文件中),一般都会放到data中,文件名末尾有-slow.log; 其中会有执行的时间,sql语句的名字,Rows_sent: 返回出去的结果行数,Rows_examined:为了获取到结果,扫描了多少数据量。日志文件是所有的数据,可通过bin目录下的 mysqldumpslow工具去查看慢查询日志去分析。可用
# 查看此工具的使用命令
./mysqldumpslow --help
# -s 对结果排序 t 按时间 -t 10 取前10条 把这个慢查询日志中 总耗时排前10位的拿出来看
./mysqldumpslow -s t -t 10 /home/mysql/mysql158/data/sefddkj-slow.log
# -g 加上正则表达式,通过grep来筛选,只关心select语句
./mysqldumpslow -s t -t 10 /home/mysql/mysql158/data/sefddkj-slow.log -g select慢查询的根本原因是访问的数据太多了,优化的目的都是减少mysql访问的数据量。
业务层:是否请求了不需要的数据?
1.查询不需要的记录 2.总是取出全部列 3.重复查询相同的数据
(如果数据时需要缓存起来,以后要用可直接查询所有的,也可用select *,*是肯定要走回表的或者直接全表扫)
执行层:是否在扫描额外的记录?典型的limit 10000,10 ,mysql扫了10010条记录,取了10条
1.响应时间 2.扫描的行数和返回的行数差距很大 3.扫描的行数和访问类型(每一行的成本是否达到了最优,通过explain可看到sql访问的类型获得的方式,type越靠前越好,扫描的记录数越少。尽可能只扫描所需要的数据行)
重构查询方法:
1.一个复杂查询还是多个简单查询?部分逻辑可交由代码层处理,更易扩展
2.切分查询。查询语句数据量太大了,切分成小查询,分而治之,一条sql返回的数据量一般5000~10000条数据最好。
3.分解关联查询?a.常用数据进行缓存,让缓存的效率更高,减少冗余记录的查询,关联可放在应用层,更易扩展。b.可减少锁竞争。c.更容易做到高性能和可扩展 d.相当于在应用中实现了哈希关联
TCP协议角度来说是全双工的。MySQL的协议,在应用层来说,是半双工的,客户端发送完了数据给服务器,服务器才能发送数据给客户端。同时,发完了,客户端才能再发命令给服务端。(没法做流量控制的)
对于java程序来说,很有可能由于mysql给的数据量过大过多,需要花很多的时间和内存来存储所有的结果集,很有可能发生OOM,所以MySQL的JDBC里提供了setFetchSize()之类的功能来解决这个问题。
A.当statement设置以下属性时,采用的是流数据接收方式,每次只从服务器接收部分数据,直到所有数据处理完成,不会发生JVM OOM 。
setResultSetType(ResultSet.TYPE_FORWARD_ONLY);
setFetchSize(Integer.MIN_VALUE);
B.调用statement的enableStreamingResults方法,实际上enableStreamingResult方法内部封装的就是第一种方式
C.设置连接属性useCursorFetch=true(5.0版本驱动开始支持),statement以TYPE_FORWARD_ONLY打开,再设置fetch size参数,表示采用服务器端游标,每次从服务器取fetch_size条数据。
具体SQL语句数据监控
MySQL查出来一条数据就会给一条数据给客户端,客户端库函数会有缓存数据;如果是将数据查全了再返回,会显得MySQL很慢,同时一次性给太多,会加载很多数据页到内存中再返回给客户端,占用内存。
可通过命令,来查看某条sql执行的时候MySQL底层执行的线程的具体工作情况,时间都花在哪的。
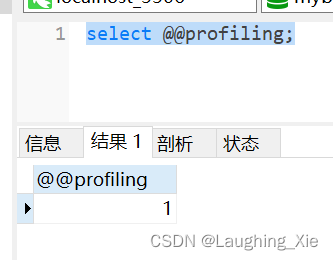
select @@profiling;
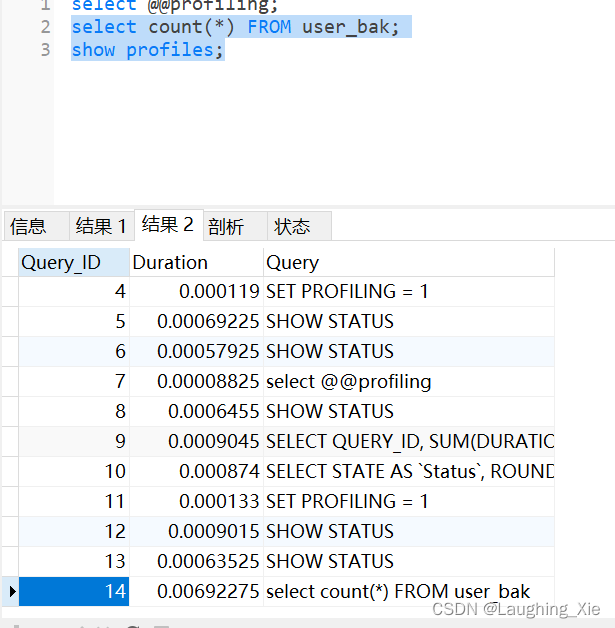
select count(*) FROM user_bak;
show profiles;
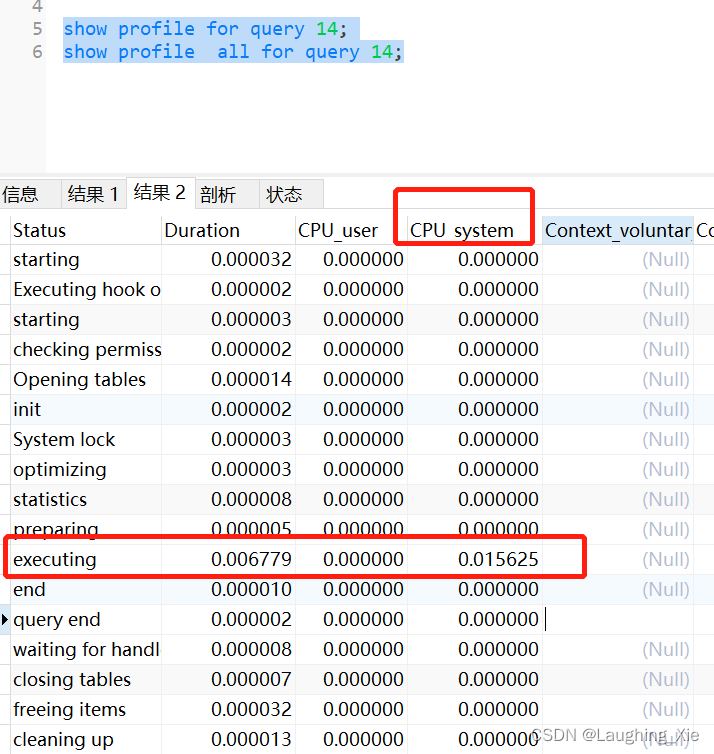
show profile for query 14;
show profile all for query 14;Select @@have_profiling;查看是否支持profile功能
如果是关闭状态,可以 Set profiling =1 ; 自行打开。
执行sql语句,并show profiles,看看这条sql执行的编号是多少?
再去查找这条sql的相应的内部线程执行情况。
Show profile for query 14; 执行这条sql的时候各个线程(阶段)花费的时间是多少
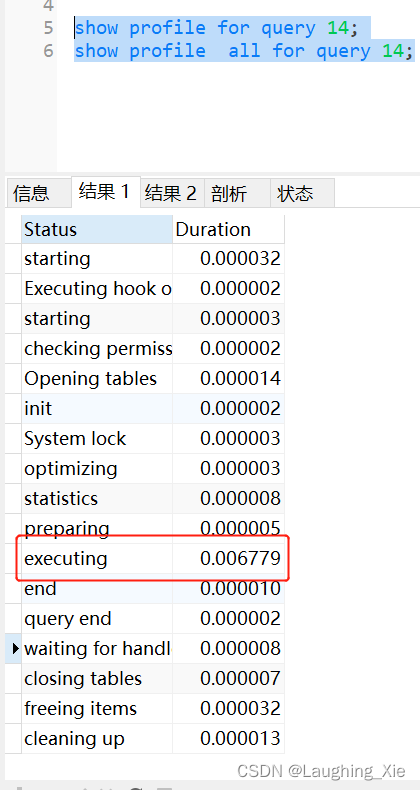
show profile all for query 55,显示更加详细的花费时间记录,这个线程大部分时间花在哪里了?包括cpu的时间
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我需要检查DateTime是否采用有效的ISO8601格式。喜欢:#iso8601?我检查了ruby是否有特定方法,但没有找到。目前我正在使用date.iso8601==date来检查这个。有什么好的方法吗?编辑解释我的环境,并改变问题的范围。因此,我的项目将使用jsapiFullCalendar,这就是我需要iso8601字符串格式的原因。我想知道更好或正确的方法是什么,以正确的格式将日期保存在数据库中,或者让ActiveRecord完成它们的工作并在我需要时间信息时对其进行操作。 最佳答案 我不太明白你的问题。我假设您想检查
我在用Ruby执行简单任务时遇到了一件奇怪的事情。我只想用每个方法迭代字母表,但迭代在执行中先进行:alfawit=("a".."z")puts"That'sanalphabet:\n\n#{alfawit.each{|litera|putslitera}}"这段代码的结果是:(缩写)abc⋮xyzThat'sanalphabet:a..z知道为什么它会这样工作或者我做错了什么吗?提前致谢。 最佳答案 因为您的each调用被插入到在固定字符串之前执行的字符串文字中。此外,each返回一个Enumerable,实际上您甚至打印它。试试
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co