俗话说”麻雀虽小,五脏俱全“,有人说想看开源源码却不知道什么好,事实上,那些流行多年,广受好评的开源工程都是很值得一读的。今天我们介绍Apollo配置中心的基本情况,之所以介绍这个,主要是因为公司里用的配置中心就是这个,最近要做一次技术分享, 所以就调研了一下发现很多设计非常简介高效,值得学习,这里整理几个最重要的内容。
目录
Apollo(阿波罗)是携程框架部研发并开源的一款生产级的配置中心产品,它能够集中管理应用在不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
Apollo目前在国内开发者社区比较热,在Github上有超过5k颗星,在国内众多互联网公司有落地案例,可以说Apollo是目前配置中心产品领域Number1的产品,其成熟度和企业级特性要远远强于Spring Cloud体系中的Spring Cloud Config产品。
Apollo的整体流程如下:
用户在配置中心对配置进行修改并发布
配置中心通知Apollo客户端有配置更新
Apollo客户端从配置中心拉取最新的配置、更新本地配置并通知到应用
如果不考虑分布式微服务架构中的服务发现问题,Apollo的最简架构如下图所示:
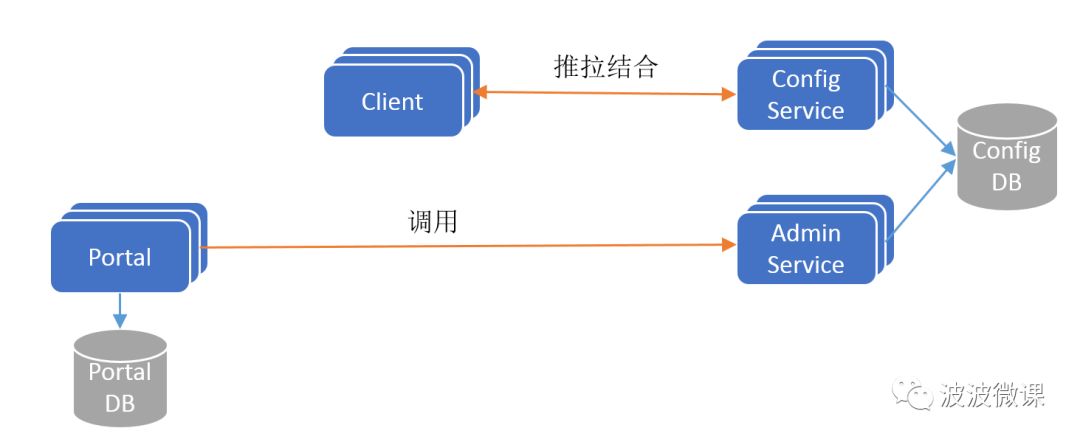
Apollo V1架构
要点:
ConfigService是一个独立的微服务,服务于Client进行配置获取。
Client和ConfigService保持长连接,通过一种推拉结合(push & pull)的模式,在实现配置实时更新的同时,保证配置更新不丢失。
AdminService是一个独立的微服务,服务于Portal进行配置管理。Portal通过调用AdminService进行配置管理和发布。
ConfigService和AdminService共享ConfigDB,ConfigDB中存放项目在某个环境中的配置信息。ConfigService/AdminService/ConfigDB三者在每个环境(DEV/FAT/UAT/PRO)中都要部署一份。
Protal有一个独立的PortalDB,存放用户权限、项目和配置的元数据信息。Protal只需部署一份,它可以管理多套环境。
为了保证高可用,ConfigService和AdminService都是无状态以集群方式部署的,这个时候就存在一个服务发现问题:Client怎么找到ConfigService?Portal怎么找到AdminService?为了解决这个问题,Apollo在其架构中引入了Eureka服务注册中心组件,实现微服务间的服务注册和发现,更新后的架构如下图所示:
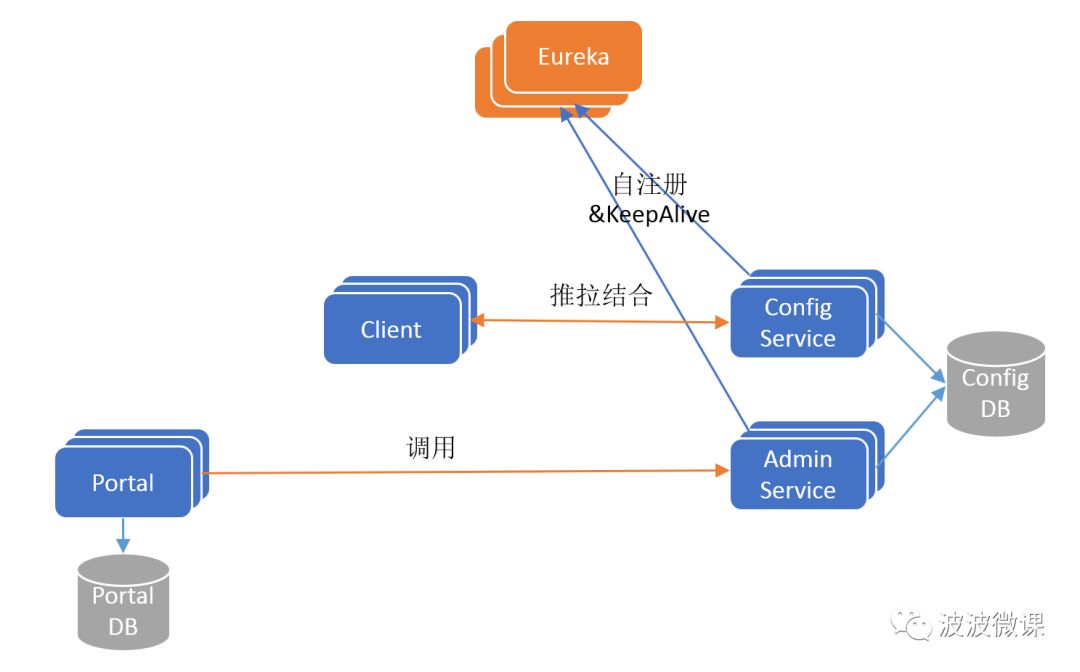
要点:
Config/AdminService启动后都会注册到Eureka服务注册中心,并定期发送保活心跳。
Eureka采用集群方式部署,使用分布式一致性协议保证每个实例的状态最终一致。
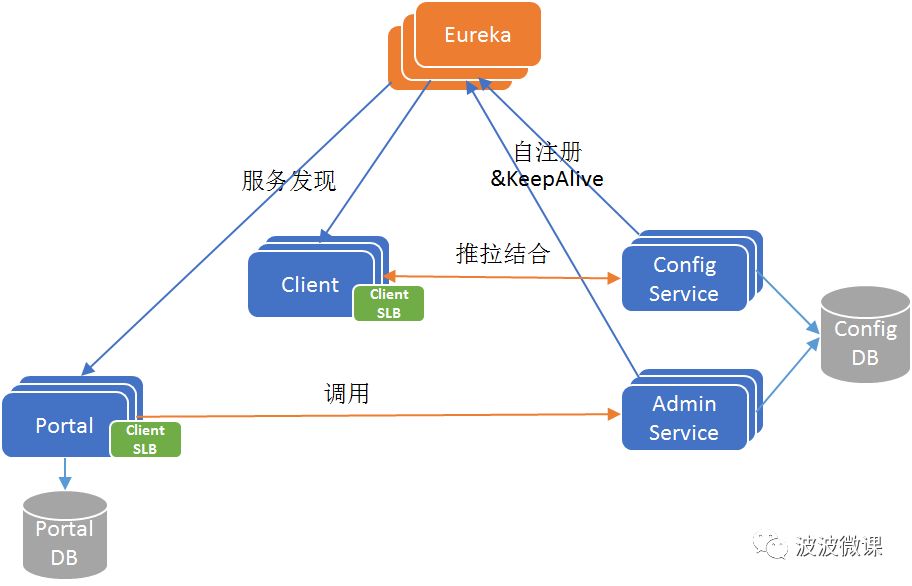
我们知道Eureka是自带服务发现的Java客户端的,如果Apollo只支持Java客户端接入,不支持其它语言客户端接入的话,那么Client和Portal只需要引入Eureka的Java客户端,就可以实现服务发现功能。发现目标服务后,通过客户端软负载(SLB,例如Ribbon)就可以路由到目标服务实例。这是一个经典的微服务架构,基于Eureka实现服务注册发现+客户端Ribbon配合实现软路由,如下图所示:
在携程,应用场景不仅有Java,还有很多遗留的.Net应用。Apollo的作者也考虑到开源到社区以后,很多客户应用是非Java的。但是Eureka(包括Ribbon软负载)原生仅支持Java客户端,如果要为多语言开发Eureka/Ribbon客户端,这个工作量很大也不可控。为此,Apollo的作者引入了MetaServer这个角色,它其实是一个Eureka的Proxy,将Eureka的服务发现接口以更简单明确的HTTP接口的形式暴露出来,方便Client/Protal通过简单的HTTPClient就可以查询到Config/AdminService的地址列表。获取到服务实例地址列表之后,再以简单的客户端软负载(Client SLB)策略路由定位到目标实例,并发起调用。
现在还有一个问题,MetaServer本身也是无状态以集群方式部署的,那么Client/Protal该如何发现MetaServer呢?一种传统的做法是借助硬件或者软件负载均衡器,例如在携程采用的是扩展后的NginxLB(也称Software Load Balancer),由运维为MetaServer集群配置一个域名,指向NginxLB集群,NginxLB再对MetaServer进行负载均衡和流量转发。Client/Portal通过域名+NginxLB间接访问MetaServer集群。
引入MetaServer和NginxLB之后的架构如下图所示:
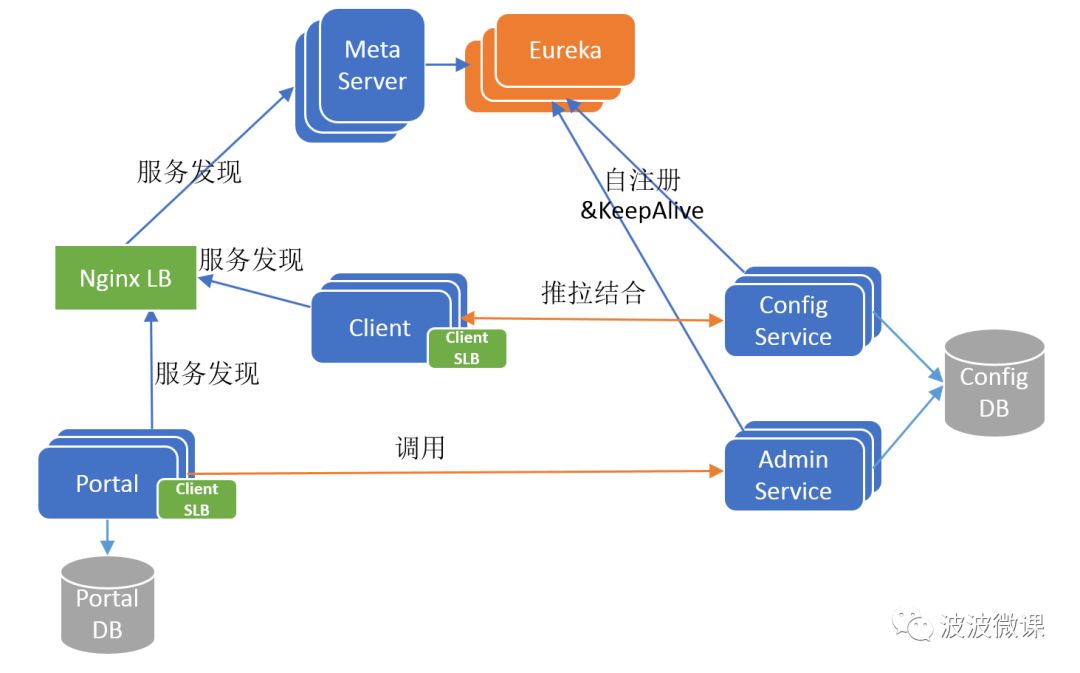
V4版本已经是比较完整的Apollo架构全貌,现在还剩下最后一个环节:Portal也是无状态以集群方式部署的,用户如何发现和访问Portal?答案也是简单的传统做法,用户通过域名+NginxLB间接访问Portal集群。
所以V5版本是包括用户端的最终的Apollo架构全貌,如下图所示:
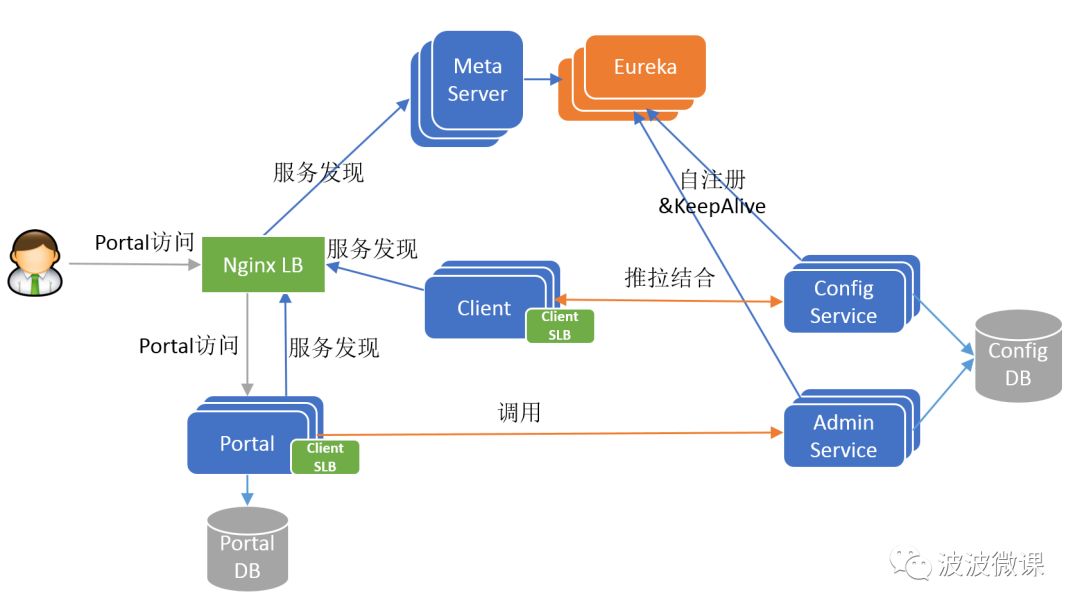
下面是Apollo的七个模块,其中四个模块是和功能相关的核心模块,另外三个模块是辅助服务发现的模块:
ConfigService
提供配置获取接口
提供配置推送接口
服务于Apollo客户端
AdminService
提供配置管理接口
提供配置修改发布接口
服务于管理界面Portal
Client
为应用获取配置,支持实时更新
通过MetaServer获取ConfigService的服务列表
使用客户端软负载SLB方式调用ConfigService
Portal
配置管理界面
通过MetaServer获取AdminService的服务列表
使用客户端软负载SLB方式调用AdminService
基于Angular做的
Eureka
用于服务发现和注册
Config/AdminService注册实例并定期报心跳
和ConfigService住在一起部署
MetaServer
主要用于跨语言支持
Portal通过域名访问MetaServer获取AdminService的地址列表
Client通过域名访问MetaServer获取ConfigService的地址列表
逻辑角色,和ConfigService住在一起部署
NginxLB
也主要针对跨语言支持的
和域名系统配合,协助Portal访问MetaServer获取AdminService地址列表
和域名系统配合,协助Client访问MetaServer获取ConfigService地址列表
和域名系统配合,协助用户访问Portal进行配置管理
官网有比较明确的说明,详细参考Apollo
核心是:Portal通过域名访问Meta Server获取Admin Service服务列表(IP+Port),而后直接通过IP+Port访问服务,同时在Portal侧会做load balance、错误重试。
在配置中心中,最重要的功能就是配置发布后实时推送到客户端。下面我们简要看一下这块是怎么设计实现的。
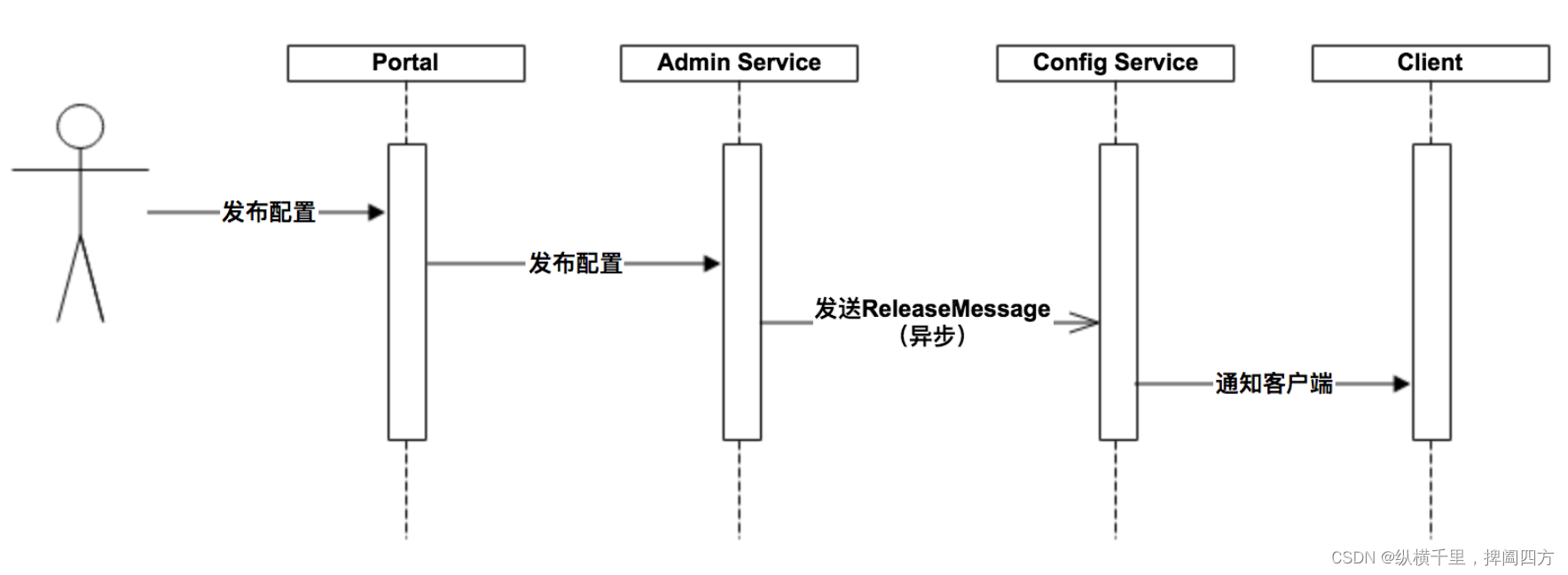
上图简要描述了配置发布的大致过程:
用户在Portal操作配置发布
Portal调用Admin Service的接口操作发布
Admin Service发布配置后,发送ReleaseMessage给各个Config Service
Config Service收到ReleaseMessage后,通知对应的客户端
Admin Service在配置发布后,需要通知所有的Config Service有配置发布,从而Config Service可以通知对应的客户端来拉取最新的配置。
从概念上来看,这是一个典型的消息使用场景,Admin Service作为producer发出消息,各个Config Service作为consumer消费消息。通过一个消息组件(Message Queue)就能很好的实现Admin Service和Config Service的解耦。
在实现上,考虑到Apollo的实际使用场景,以及为了尽可能减少外部依赖,没有采用外部的消息中间件,而是通过数据库实现了一个简单的消息队列。
这个工作过程就是一侧负责插入数据到DB,然后几个客户端定时扫描表,如果找到自己要处理的类型,就启动执行。具体实现方式如下:

Admin Service在配置发布后会往ReleaseMessage表插入一条消息记录,消息内容就是配置发布的AppId+Cluster+Namespace,参见DatabaseMessageSender
Config Service有一个线程会每秒扫描一次ReleaseMessage表,看看是否有新的消息记录,参见ReleaseMessageScanner。
Config Service如果发现有新的消息记录,那么就会通知到所有的消息监听器ReleaseMessageListener,例如NotificationControllerV2,消息监听器的注册过程参见ConfigServiceAutoConfiguration
NotificationControllerV2得到配置发布的AppId+Cluster+Namespace后,会通知对应的客户端。
上一节中简要描述了NotificationControllerV2是如何得知有配置发布的,那NotificationControllerV2在得知有配置发布后是如何通知到客户端的呢?
实现方式如下:
客户端会发起一个Http请求到NotificationControllerV2
NotificationControllerV2不会立即返回结果,而是通过Spring DeferredResult把请求挂起。
如果在60秒内没有该客户端关心的配置发布,那么会返回Http状态码304给客户端。
如果有该客户端关心的配置发布,NotificationControllerV2会调用DeferredResult的setResult方法,传入有配置变化的namespace信息,同时该请求会立即返回。客户端从返回的结果中获取到配置变化的namespace后,会立即请求Config Service获取该namespace的最新配置。
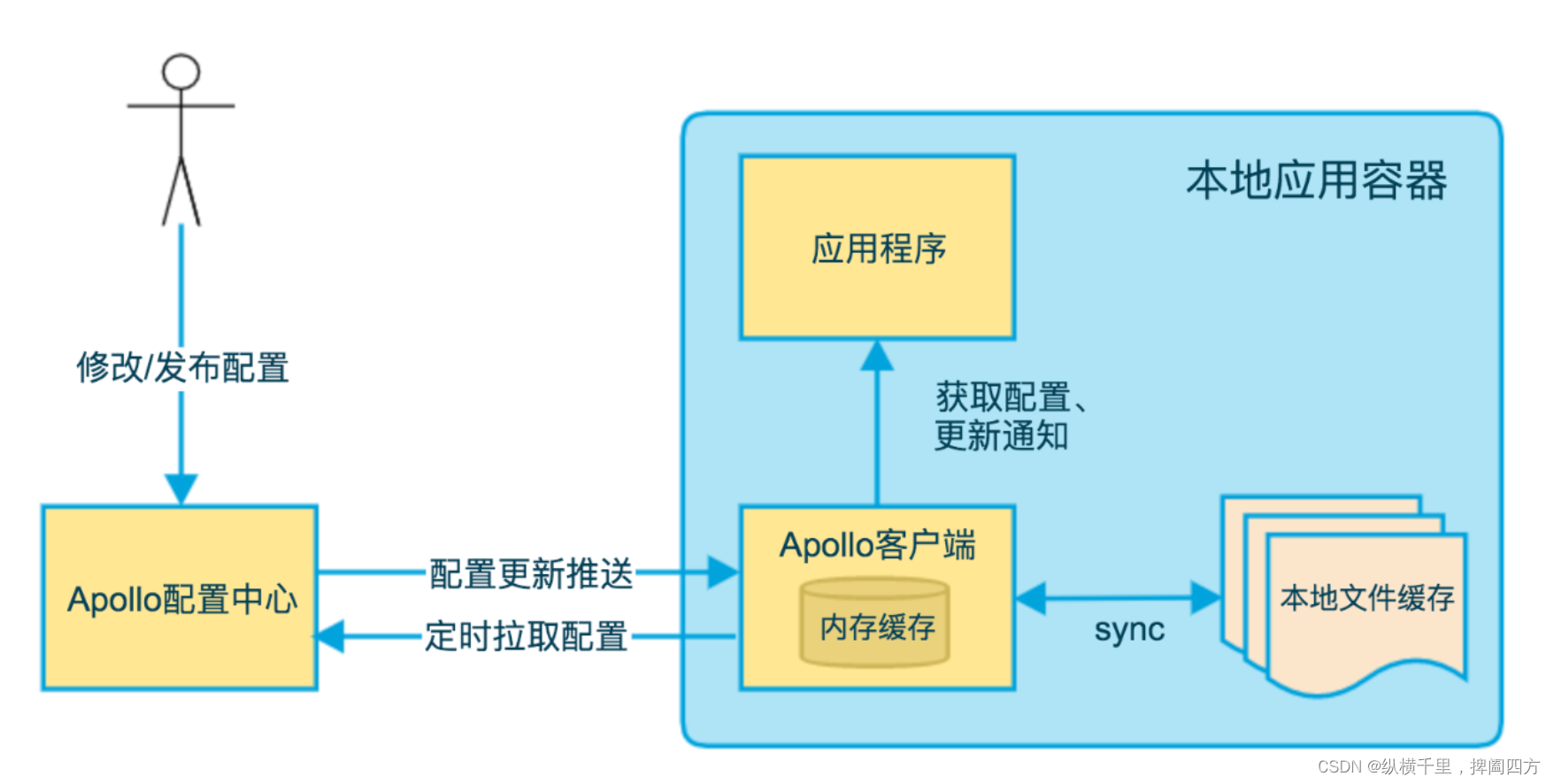
上图简要描述了Apollo客户端的实现原理:
客户端和服务端保持了一个长连接,从而能第一时间获得配置更新的推送。(通过Http Long Polling实现)
客户端还会定时从Apollo配置中心服务端拉取应用的最新配置。
这是一个fallback机制,为了防止推送机制失效导致配置不更新
客户端定时拉取会上报本地版本,所以一般情况下,对于定时拉取的操作,服务端都会返回304 - Not Modified
定时频率默认为每5分钟拉取一次,客户端也可以通过在运行时指定System Property: apollo.refreshInterval来覆盖,单位为分钟。
客户端从Apollo配置中心服务端获取到应用的最新配置后,会保存在内存中
客户端会把从服务端获取到的配置在本地文件系统缓存一份。在遇到服务不可用,或网络不通的时候,依然能从本地恢复配置
应用程序可以从Apollo客户端获取最新的配置、订阅配置更新通知
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我是ruby的新手,正在配置IRB。我喜欢pretty-print(需要'pp'),但总是输入pp来漂亮地打印它似乎很麻烦。我想做的是默认情况下让它漂亮地打印出来,所以如果我有一个var,比如说,'myvar',然后键入myvar,它会自动调用pretty_inspect而不是常规检查。我从哪里开始?理想情况下,我将能够向我的.irbrc文件添加一个自动调用的方法。有什么想法吗?谢谢! 最佳答案 irb中默认pretty-print对象正是hirb被迫去做。Theseposts解释hirb如何将几乎所有内容转换为ascii表。虽
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
我正在使用Ruby/Mechanize编写一个“自动填写表格”应用程序。它几乎可以工作。我可以使用精彩CharlesWeb代理以查看服务器和我的Firefox浏览器之间的交换。现在我想使用Charles查看服务器和我的应用程序之间的交换。Charles在端口8888上代理。假设服务器位于https://my.host.com。.一件不起作用的事情是:@agent||=Mechanize.newdo|agent|agent.set_proxy("my.host.com",8888)end这会导致Net::HTTP::Persistent::Error:...lib/net/http/pe
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails