1. SpringBoot不是一个全新的框架,而是对Spring框架的一个封装。所以,以前Spring可以做的事情,现在用SpringBoot都可以做。
2. SpringBoot整合了很多优秀的框架,用来简化Spring应用搭建和开发过程,不用我们自己手动去写一堆xml进行Spring Bean配置。
3. 一般情况下,一个SpringBoot应用 = 一个微服务 = 一个模块 。
1. 独立运行:SpringBoot开发的应用可以以JRA包的形式独立运行,运行一个SpringBoot应用只需通过 java –jar xxxx.jar 来运行;
2. 内嵌容器:SpringBoot内嵌了多个WEB容器,如:Tomcat、Jetty、Undertow,所以可以使用非WAR包形式进行项目部署;
3. 自动starter依赖:SpringBoot提供了一系列的starter来简化Maven的依赖加载。starter是一组方便的依赖关系描述符,它将常用的依赖分组并将其合并到一个依赖中,这样就可以一次性将相关依赖添加到Maven或Gradle中;
4. 自动配置及按需加载:SpringBoot会根据在类路径中的JAR包和类,自动将类注入到SpringBoot的上下文中,极大地减少配置的使用;
5. 应用监控:SpringBoot提供基于http、ssh、telnet的监控方式,对运行时的项目提供生产级别的服务监控和健康检测;
6. 无代码生成/无需编写XML配置:SpringBoot不是借助于代码生成来实现的,而是通过条件注解来实现的,这是 Spring 4.x 提供的新特性。Spring4.x提倡使用Java配置和注解组合,无需编写任何xml配置即可实现Spring的所有配置功能;
(原文链接:https://blog.csdn.net/goodjava2007/article/details/122859472)
1. Spring Cloud就是微服务系统架构的一站式解决方案,是各个微服务架构落地技术的集合体,俗称微服务全家桶。
2. 在平时我们构建微服务的过程中需要做如服务发现注册、配置中心、负载均衡、断路器、数据监控等操作,而Spring Cloud 为我们提供了一套简易的编程模型,使我们能在 Spring Boot 的基础上轻松地实现微服务项目的构建。
1. 关系:SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架。
2. 区别: SpringBoot可以离开SpringCloud独立使用开发项目,但是SpringCloud离不开SpringBoot,属于依赖的关系。
1. 简单来说微服务就是很小的服务,小到一个服务只对应一个单一的功能,只做一件事。
2. 将一个大的项目,按照需求(业务服务)模块拆解成一个个独立小模块(微小服务),然后独立部署,它们之间独立又相互调用。
3. 将子系统拆成一个一个的jar包运行就是微服务。
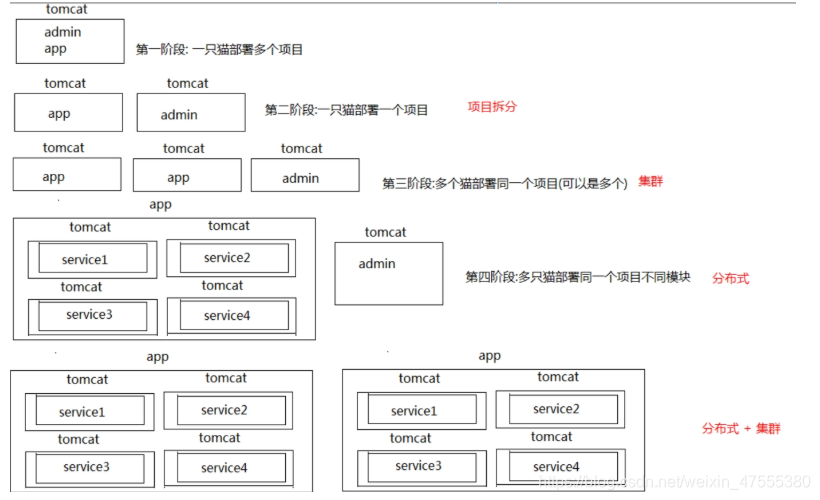
1. 将各个组件分开部署,某个组件占一个服务器,互相独立,互相调用,可以将组件的功能发挥强大。
2. 一个业务分拆多个子业务,部署在不同的服务器上(不同的服务器,运行不同的代码,为了同一个目的)。
优点:
1. 模块之间独立,各做各的事,便于扩展,复用性高。
2. 高吞吐量。某个任务需要一个机器运行20个小时,将该任务用10台机器的分布式跑(将这个任务拆分成10个小任务),可能2个小时就跑完了。
1. 同一个业务,部署在多个服务器上(不同的服务器运行同样的代码,干同一件事)
优点:
1. 通过多台计算机完成同一个工作,达到更高的效率。
2. 两机或多机内容、工作过程等完全一样。如果一台死机,另一台可以起作用。
1. 集群:多个服务器部署同一个项目。
2. 分布式: 多个服务器部署一个项目的不同模块。
3. 集群和分布式并不冲突,可以有分布式集群。
(原文链接: http://t.csdn.cn/TfPsQ)
目标:创建两个Spring Boot项目(例:spring-cloud-a、spring-cloud-b),利用SpringCloud(例:spring-cloud-eureka)来将两个服务关联起来,使其可以互相调用。
SpringCloud采用的是Eureka来做服务的注册中心,类似于dubbo采用的是zookeeper作为注册中心一样。
(1)创建一个新的springboot项目,名称为spring-cloud-eureka,端口为8003
(2)pom.xml里添加:
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.3.7.RELEASE</spring-boot.version>
<spring-cloud.version>Hoxton.SR9</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.3.7.RELEASE</version>
<configuration>
<mainClass>com.dxz.eurekaserver.EurekaServerApplication</mainClass>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
(3)在resources下创建配置文件application.properties(或 application.yml),如果是application.properties则里面添加如下内容:
spring.application.name=my
server.port=8003
#自我保护默认关闭
eureka.server.enable-self-preservation: false
#不向注册中心注册自己
eureka.client.register-with-eureka=false
#不需要检索服务
eureka.client.fetch-registry=false
#eureka的注册中心地址
eureka.client.serviceUrl.defaultZone=http://localhost:8003/eureka/如果是application.yml则里面添加内容为:
spring:
application:
name: my
server:
port: 8003
#自我保护默认关闭
eureka:
server:
enable-self-preservation: false
#不向注册中心注册自己
client:
register-with-eureka: false
#不需要检索服务
fetch-registry: false
#eureka的注册中心地址
serviceUrl:
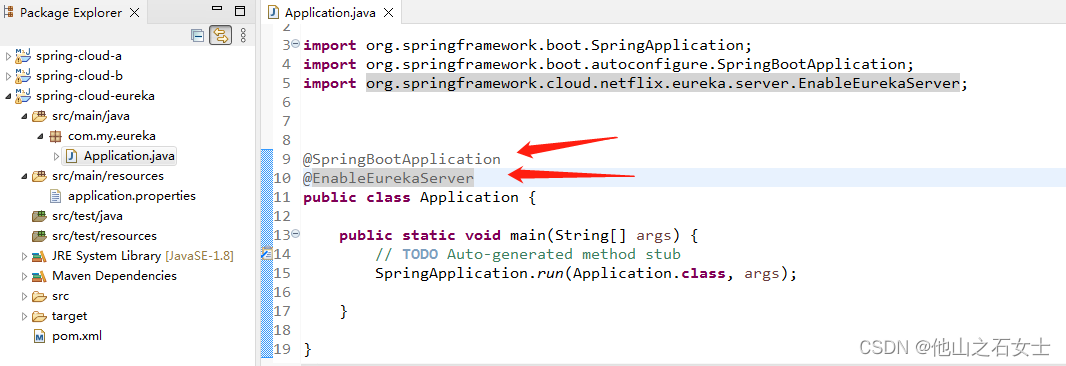
defaultZone: http://localhost:8003/eureka/(4) 在springboot启动的入口类加入一个注解@EnableEurekaServer,即可将该项目作为服务注册中心,加入注解@SpringBootApplication使项目可以被启动。
(5) 运行启动类来启动该项目,浏览器访问http:localhost:8003可以看到Eureka登录页。
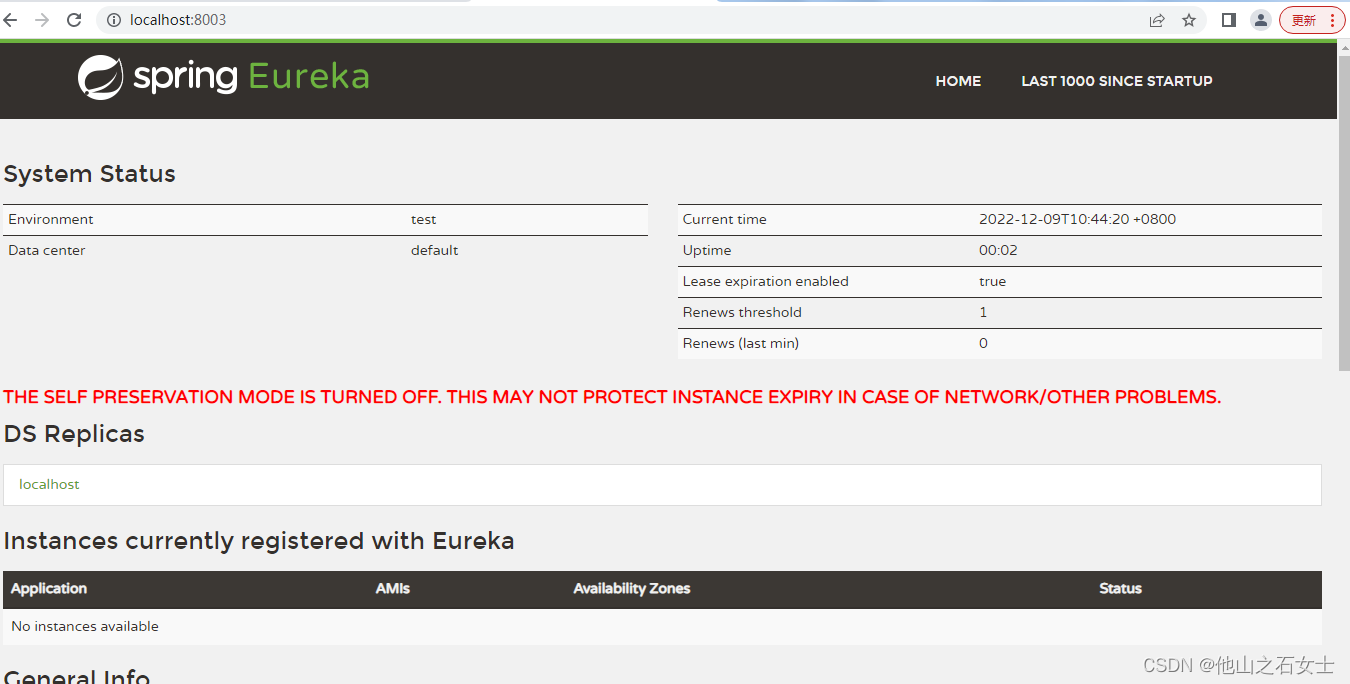
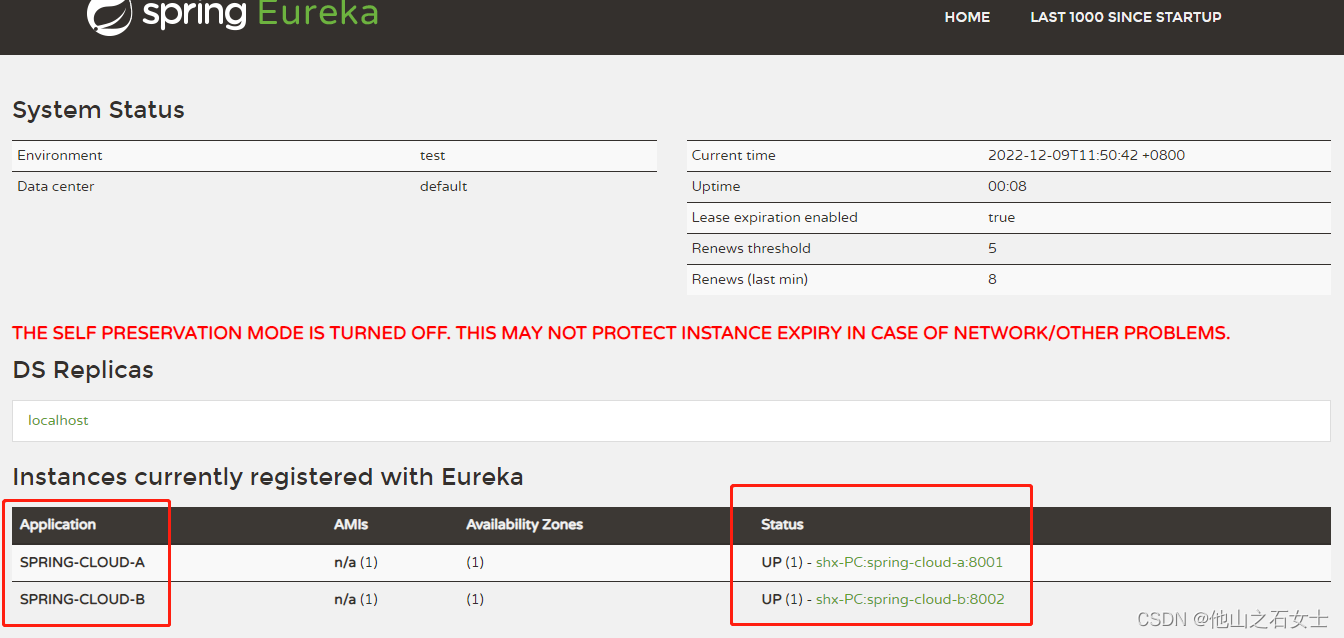
现在注册中心还看不到任何一个应用,需要将spring-cloud-a、spring-cloud-b注册进来。
(1)spring-cloud-a、spring-cloud-b的pom.xml里添加spring-cloud-eureka一样的配置
(2)在spring-cloud-a 的resources下创建配置文件application.properties,里面添加如下内容:
spring.application.name=spring-cloud-a
server.port=8001
#eureka的注册中心地址
eureka.client.serviceUrl.defaultZone=http://localhost:8003/eureka/在spring-cloud-b 的resource下创建配置文件application.properties,里面添加内容如下:
spring.application.name=spring-cloud-b
server.port=8002
#eureka的注册中心地址
eureka.client.serviceUrl.defaultZone=http://localhost:8003/eureka/(3)在springboot启动的入口类加入一个注解@EnableDiscoveryClient,即可完成注册服务。
(4)在本地 spring-cloud-a 、 spring-cloud-b、spring-cloud-eureka都启动的前提下,访问eureka注册中心,能看到新加入的两个服务。
远程调用服务的方式有两种,分别为restTemplate和feign
方式一:restTemplate:主要通过ribbon使客户端做到负载均衡,类似nginx反向代理,需要手动启动(存在问题:a.代码可读性差,编程体验不统一 b. 参数复杂URL难以维护)
方式二:feign:可以简化客户端代码,默认集成了ribbon实现了负载均衡的效果,并和Eureka结合,自动启动(Feign是一个声明式的http客户端,其作用就是帮助我们优雅的实现http请求的发送)
(原文链接: https://blog.csdn.net/m0_54849806/article/details/123838479)
这里我们选取方式二具体举例:
1. 在 spring-cloud-a、spring-cloud-b两个系统的pom.xml里都添加依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>2. 在springboot启动的入口类加入一个注解@EnableFeignClients(在需要调用的系统里添加@EnableFeignClients,这里是我 a系统 调用 b系统 的方法,所以在a系统里添加)
在a系统里添加 调用b系统方法的接口:
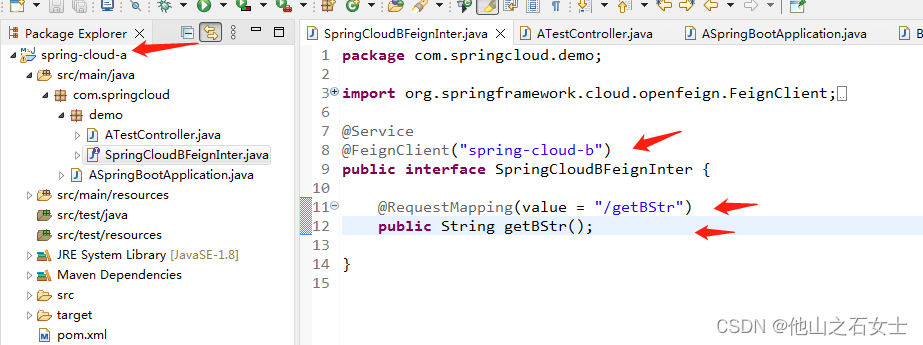
在a系统里添加测试controller (a系统的getStr方法调用b系统的getBStr方法) :

在b系统里添加controller测试类 :
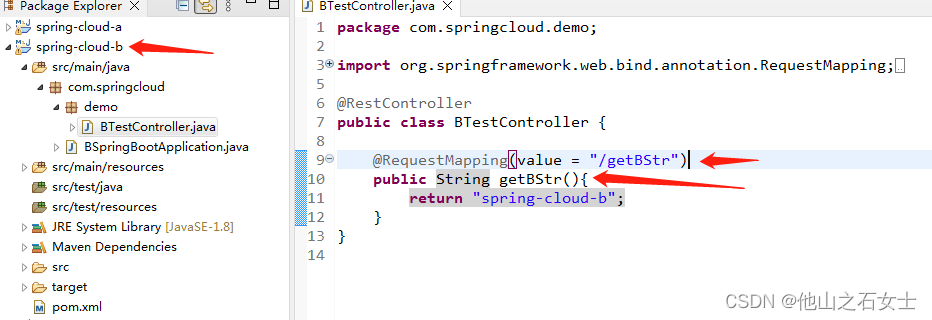
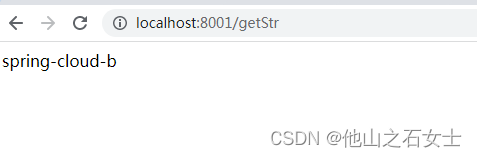
浏览器访问a系统的getStr方法,调用(远程b系统)成功:
我的demo请下载:https://download.csdn.net/download/m0_37951794/87269664
如果spring-cloud-a与spring-cloud-b部署在不同服务器上,需要解决a、b之间跨域问题,请参考:
SpringBoot+SpringCloud微服务搭建全过程(二)_他山之石女士的博客-CSDN博客
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
我已经开始学习Ruby,我已经阅读了一些教程,甚至还买了一本书(“ProgrammingRuby1.9-ThePragmaticProgrammers'Guide”),我遇到了一些以前从未见过的新东西使用我知道的任何其他语言(我是一名PHP网络开发人员)。block和过程。我想我明白它们是什么,但我不明白的是为什么它们如此伟大,以及我应该在何时何地使用它们。我到处都看到他们说block和过程是Ruby中的一个很棒的特性,但我不理解它们。这里有人能给像我这样的Ruby新手一些解释吗? 最佳答案 block有很多好处。电梯演讲:bloc
目录SpringBootStarter是什么?以前传统的做法使用SpringBootStarter之后starter的理念:starter的实现: 创建SpringBootStarter步骤在idea新建一个starter项目、直接执行下一步即可生成项目。 在xml中加入如下配置文件:创建proterties类来保存配置信息创建业务类:创建AutoConfiguration测试如下:SpringBootStarter是什么? SpringBootStarter是在SpringBoot组件中被提出来的一种概念、简化了很多烦琐的配置、通过引入各种SpringBootStarter包可以快速搭建出一
rails中View的解析过程是怎样的?我对View中erb标记中原始html与ruby代码的解析顺序部分感兴趣。我认为这是View代码被解析并最终发送给请求者的顺序:Controller调用ViewView代码从上到下解析当Rails在解析过程中遇到erb标记时:rails解析它并将结果附加到解析的html(这包括erb标签引用助手)一旦整个View被解析,整体结果将发送给请求者这似乎并非如此。看来View代码会扫描任何erb片段并首先解析那些片段(包括对助手的引用)。之后,rails然后从上到下解析所有View代码并将结果发送给请求者。以这个View为例:#_form.html
快速导航(持续更新中…)Cesium源码解析一(terrain文件的加载、解析与渲染全过程梳理)Cesium源码解析二(metadataAvailability的含义)Cesium源码解析三(metadata元数据拓展中行列号的分块规则解析)Cesium源码解析四(Quantized-Mesh(.terrain)格式文件在CesiumJS和UE中加载情况的对比)目录1.前言2.本篇的由来3.terrain文件的加载3.1更新环境3.2更新和执行渲染命令3.3数据优化3.4结束当前帧4.总结1.前言 目前市场上三维比较火的实现方案主要有两种,b/s的方案主要是Cesium,c/s的方案主要是u
如果您希望在Spring中启用定时任务功能,则需要在主类上添加 @EnableScheduling 注解。这样Spring才会扫描 @Scheduled 注解并执行定时任务。在大多数情况下,只需要在主类上添加 @EnableScheduling 注解即可,不需要在Service层或其他类中再次添加。以下是一个示例,演示如何在SpringBoot中启用定时任务功能:@SpringBootApplication@EnableSchedulingpublicclassApplication{publicstaticvoidmain(String[]args){SpringApplication.ru
TCP是面向连接的协议,连接的建立和释放是每一次面向连接的通信中必不可少的过程。TCP连接的管理就是使连接的建立和释放都能正常地进行。三次握手TCP连接的建立—三次握手建立TCP连接①若主机A中运行了一个客户进程,当它需要主机B的服务时,就发起TCP连接请求,并在所发送的分段中用SYN=1表示连接请求,并产生一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x。主机B收到A的连接请求报文,就完成了第一次握手。客户端发送SYN=1表示连接请求客户端发送一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x②主机B如果同意建立连接,则向主机A发送确认报
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
1.依赖导入org.springframework.bootspring-boot-starter-weborg.springframework.bootspring-boot-starter-validation2.validation常用注解@Null被注释的元素必须为null@NotNull被注释的元素不能为null,可以为空字符串@AssertTrue被注释的元素必须为true@AssertFalse被注释的元素必须为false@Min(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值@Max(value)被注释的元素必须是一个数字,其值必须小于等于指定的最大值@D
听说PostgreSQL的可以用Ruby写存储过程但我一直没能找到更多关于它的信息,教人们如何实际去做。有人可以为此推荐好的资源。谢谢 最佳答案 显然,您需要安装PL/Ruby。之后,你可以写:CREATEFUNCTIONruby_max(int4,int4)RETURNSint4AS'ifargs[0].to_i>args[1].to_ireturnargs[0]elsereturnargs[1]end'LANGUAGE'plruby';查看其GitHubrepository安装说明。