网上已具有大量卷积神经网络的讲解,故本文不在对此赘述,这篇文章针对已了解CNN基础结构和原理者,以一个例子搭建一个简单的卷积神经网络,作为正式迈入深度学习的第一步。
我们以深度学习最经典的案例——手写数字的识别,和一种经典的CNN——LeNet进行本次学习。
Matlab的功能十分强大,其自带的深度学习工具箱可以使我们免于编写底层算法,迅速地搭建出一个卷积神经网络,同时,其自带手写数字图片以供学习,地址如下,笔者使用的是Matlab2022a。

我们将DigitDataset拷贝到当前编写代码的文件夹下,并删除其中包含两个Excel即可得到下列图片。
第一步,加载手写数字样本图片,代码如下:
clear
clc
% 第一步:加载手写数字样本
imds = imageDatastore( ...
'DigitDataset', ...
'IncludeSubfolders',true, ...
'LabelSource','foldernames');'IncludeSubfolders',true:包含每个文件夹中的所有文件和子文件夹;
'LabelSource','foldernames':根据文件夹名称分配标签并储存在Labels属性中。
第二步,将样本划分为训练集和测试集,并统计分类数量,代码如下:
% 第二步:
% 将样本划分为训练集与测试集
[imdsTrain,imdsValidation] = splitEachLabel(imds,0.7);
% 统计训练集中分类标签的数量
numClasses = numel(categories(imdsTrain.Labels));
imdsTrain为训练样本数据,imdsValidation为验证样本数据,0.7为训练样本的比例。
第三步,构建LeNet并进行可视化分析,代码如下:
% 第三步:构建LeNET卷积网络并进行分析
% 构建LeNET卷积网络
LeNET= [
imageInputLayer([60 20 1],'Name','input','Normalization','zscore')
convolution2dLayer([5 5],6,'Padding','same','Name','Conv1')
maxPooling2dLayer(2,'Stride',2,'Name','Pool1')
convolution2dLayer([5 5],16,'Padding','same','Name','Conv2')
maxPooling2dLayer(2,'Stride',2,'Name','Pool2')
convolution2dLayer([5 5],120,'Padding','same','Name','Conv3')
fullyConnectedLayer(84,'Name','fc1')
fullyConnectedLayer(numClasses,'Name','fc2')
softmaxLayer( 'Name','softmax')
classificationLayer('Name','output')
];
% 对构建的网络进行可视化分析
lgraph = layerGraph(LeNET);
analyzeNetwork(lgraph)由于手写数字图片大小为60*20*1,故需调整输入层大小;
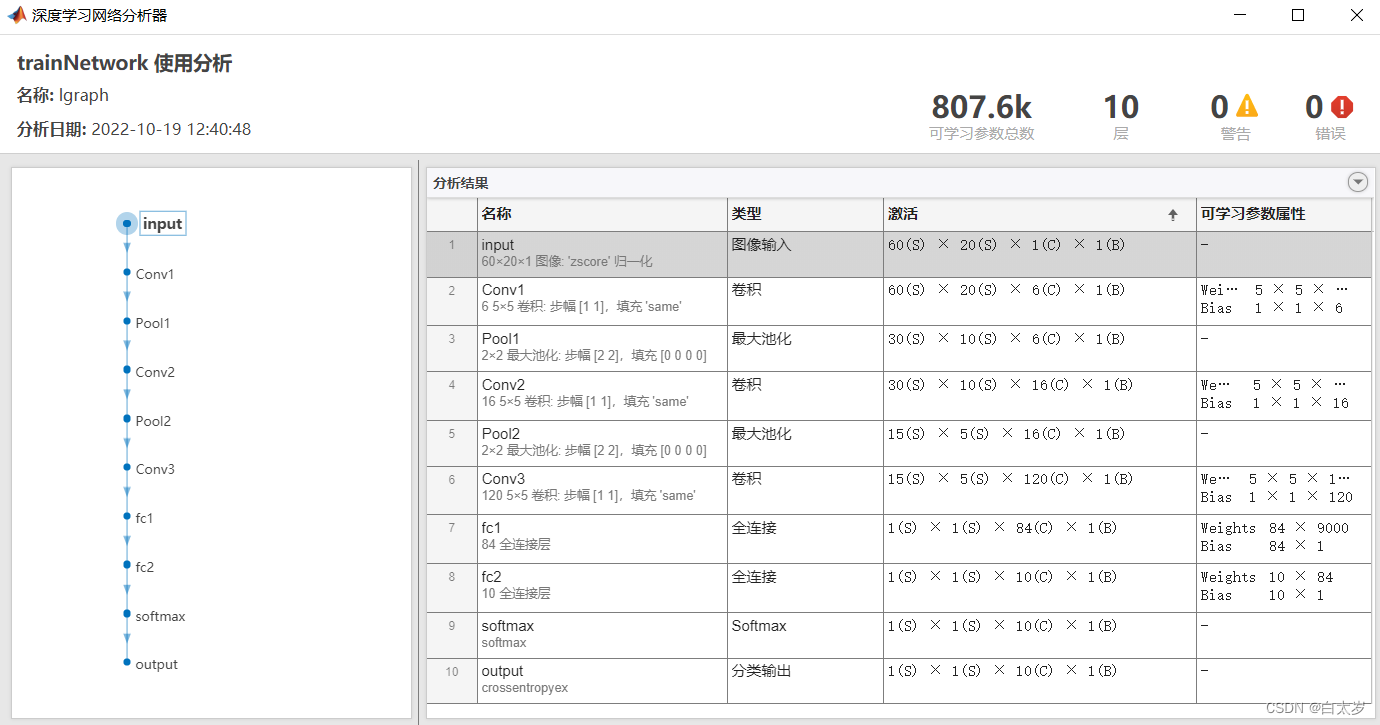
LeNet结构如下:
第一个卷积层:卷积核大小为5,数量为6,卷积方式为0填充;
第一个池化层:二维最大池化,区域为2,步长为2;
第二个卷积层:卷积核大小为5,数量为16,卷积方式为0填充;
第二个池化层:二维最大池化,区域为2,步长为2;
第三个卷积层:卷积核大小为5,数量为12,卷积方式为0填充;
第一个全连接层:输出大小为84;
第二个全连接层:输出大小为numClasses;
softmax层:得出全连接层每一个输出的概率;
classfication层:根据概率确定类别。
analyzeNetwork可以使我们对网络进行可视化分析,该代码运行结果如下图:
第四步,调整训练集和输入集的图像大小使其与LeNet输入层相同,代码如下:
% 第四步:将训练集与验证集中图像的大小调整成与LeNet输入层的大小相同
inputSize = [60 20 1];
augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain);
augimdsValidation = augmentedImageDatastore(inputSize(1:2),imdsValidation);该步骤在此例中可以省略。
第五步:配置训练选项并对网络进行训练,代码如下:
% 第五步:配置训练选项并对网络进行训练
% 配置训练选项
options = trainingOptions('sgdm', ...
'InitialLearnRate',0.001, ...
'MaxEpochs',3, ...
'Shuffle','every-epoch', ...
'ValidationData',augimdsValidation, ...
'ValidationFrequency',30, ...
'Verbose',true, ...
'Plots','training-progress');
% 对网络进行训练
net = trainNetwork(augimdsTrain,LeNET,options); 训练选项如下:
训练方法为sgdm;
初始学习率为0.001;
最大轮数为3;
'Shuffle','every-epoch': 在每一轮训练前打乱数据;
训练期间所用数据为augimdsValidation;
验证频率为30次/轮;
设置打开命令窗口输出;
设置打开训练进度图。
我们可以看到训练进度如下图:

第六步:将训练好的网络用于对新的输入图像进行分类,并计算准确率
% 第六步:将训练好的网络用于对新的输入图像进行分类,并计算准确率
YPred = classify(net,augimdsValidation);
YValidation = imdsValidation.Labels;
accuracy = sum(YPred == YValidation)/numel(YValidation)
figure
confusionchart(YValidation,YPred)confusionchart可以产生混淆矩阵,以便我们更直观的看出LeNet验证的结果。
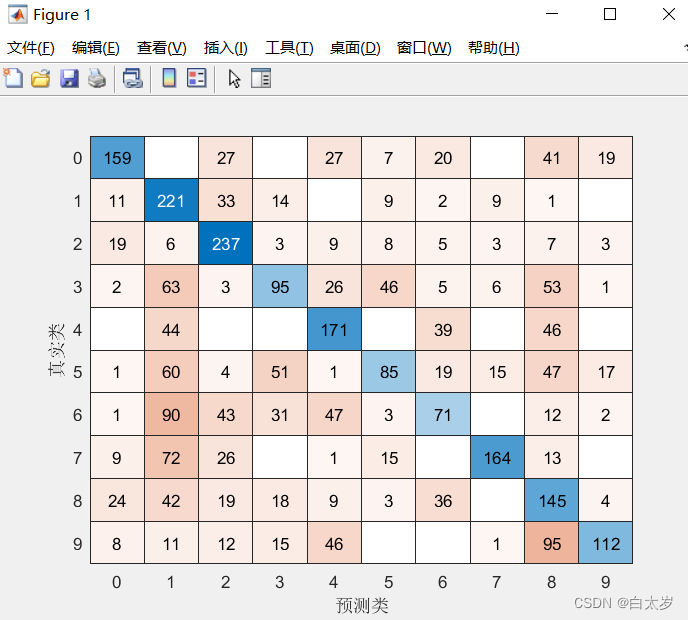
可以看到预测结果准确度比较低,对此我们可以对LeNet进行改进,增加卷积,池化层或者使用更高级的AlexNet等神经网络进行训练,本例全部代码如下:
clear
clc
% 第一步:加载手写数字样本
imds = imageDatastore( ...
'DigitDataset', ...
'IncludeSubfolders',true, ...
'LabelSource','foldernames');
% 第二步:
% 将样本划分为训练集与测试集
[imdsTrain,imdsValidation] = splitEachLabel(imds,0.7);
% 统计训练集中分类标签的数量
numClasses = numel(categories(imdsTrain.Labels));
% 第三步:构建LeNET卷积网络并进行分析
% 构建LeNET卷积网络
LeNET= [
imageInputLayer([60 20 1],'Name','input','Normalization','zscore')
convolution2dLayer([5 5],6,'Padding','same','Name','Conv1')
maxPooling2dLayer(2,'Stride',2,'Name','Pool1')
convolution2dLayer([5 5],16,'Padding','same','Name','Conv2')
maxPooling2dLayer(2,'Stride',2,'Name','Pool2')
convolution2dLayer([5 5],120,'Padding','same','Name','Conv3')
fullyConnectedLayer(84,'Name','fc1')
fullyConnectedLayer(numClasses,'Name','fc2')
softmaxLayer('Name','softmax')
classificationLayer('Name','output')
];
% 对构建的网络进行可视化分析
lgraph = layerGraph(LeNET);
analyzeNetwork(lgraph)
% 第四步:将训练集与验证集中图像的大小调整成与LeNet输入层的大小相同
inputSize = [60 20 1];
augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain);
augimdsValidation = augmentedImageDatastore(inputSize(1:2),imdsValidation);
% 第五步:配置训练选项并对网络进行训练
% 配置训练选项
options = trainingOptions( ...
'sgdm', ...
'InitialLearnRate',0.001, ...
'MaxEpochs',3, ...
'Shuffle','every-epoch', ...
'ValidationData',augimdsValidation, ...
'ValidationFrequency',30, ...
'Verbose',true, ...
'Plots','training-progress');
% 对网络进行训练
net = trainNetwork(augimdsTrain,LeNET,options);
% 第六步:将训练好的网络用于对新的输入图像进行分类,并计算准确率
YPred = classify(net,augimdsValidation);
YValidation = imdsValidation.Labels;
accuracy = sum(YPred == YValidation)/numel(YValidation)
figure
confusionchart(YValidation,YPred)
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我正在处理旧代码的一部分。beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)endRubocop错误如下:Avoidstubbingusing'allow_any_instance_of'我读到了RuboCop::RSpec:AnyInstance我试着像下面那样改变它。由此beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)end对此:let(:sport_
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur