mysql> show create table t_1\G
*************************** 1. row ***************************
Table: t_1
Create Table: CREATE TABLE `t_1` (
`w_id` int(11) DEFAULT NULL,
`w_name` varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
mysql> show create table t_2\G
*************************** 1. row ***************************
Table: t_2
Create Table: CREATE TABLE `t_2` (
`i_id` int(11) NOT NULL,
`i_name` varchar(24) DEFAULT NULL,
`i_price` decimal(5,2) DEFAULT NULL,
`i_data` varchar(50) DEFAULT NULL,
`i_im_id` int(11) NOT NULL,
PRIMARY KEY (`i_im_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
mysql> show create table t_3\G
*************************** 1. row ***************************
Table: t_3
Create Table: CREATE TABLE `t_3` (
`s_w_id` int(11) NOT NULL,
`s_i_id` int(11) NOT NULL,
`s_quantity` int(11) DEFAULT NULL,
`s_ytd` int(11) DEFAULT NULL,
`s_order_cnt` int(11) DEFAULT NULL,
`s_remote_cnt` int(11) DEFAULT NULL,
`s_data` varchar(50) DEFAULT NULL,
`s_dist_01` char(24) DEFAULT NULL,
`s_dist_02` char(24) DEFAULT NULL,
`s_dist_03` char(24) DEFAULT NULL,
`s_dist_04` char(24) DEFAULT NULL,
`s_dist_05` char(24) DEFAULT NULL,
`s_dist_06` char(24) DEFAULT NULL,
`s_dist_07` char(24) DEFAULT NULL,
`s_dist_08` char(24) DEFAULT NULL,
`s_dist_09` char(24) DEFAULT NULL,
`s_dist_10` char(24) DEFAULT NULL,
`t_2_id` int(11) DEFAULT NULL,
`t_1_id` int(11) DEFAULT NULL,
PRIMARY KEY (`s_w_id`,`s_i_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
Create Table: CREATE TABLE `t_4` (
`w_name` varchar(10) DEFAULT NULL,
`s_i_id` int(11) NOT NULL,
`s_quantity` int(11) DEFAULT NULL,
`s_ytd` int(11) DEFAULT NULL,
`s_order_cnt` int(11) DEFAULT NULL,
`s_remote_cnt` int(11) DEFAULT NULL,
`s_data` varchar(50) DEFAULT NULL,
`t_2_id` int(11) DEFAULT NULL,
`i_name` varchar(24) DEFAULT NULL,
`i_price` decimal(5,2) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4insert into t_4
SELECT
c.w_name,
a.s_i_id,
a.s_quantity,
a.s_ytd,
a.s_order_cnt,
a.s_remote_cnt,
a.s_data,
a.t_2_id,
b.i_name,
b.i_price
FROM
t_3 a,
t_2 b,
t_1 c
WHERE
a.t_2_id = b.i_id
and a.t_1_id = c.w_id
and a.s_ytd = 0;mysql> alter table t_3 add key(t_1_id,t_2_id);
Query OK, 0 rows affected (28.35 sec)
Records: 0 Duplicates: 0 Warnings: 0 可以看出优化器并没有选择走索引,依然是使用BNL优化策略,进行全表扫描,为什么不走索引呢?应该是优化器认为索引扫描的成本高于全表扫描的成本,因为这条语句最终结果要返回大表的90%以上的数据,走索引后回表代价是很高的。这一点我们是不认同优化器的,怎么着2500次全表扫描也比每次通过索引范围扫描的代价要高呀,好吧,既然不认同,那么使用force index来干涉优化器决策,让它使用索引。执行计划如下图所示:
可以看出优化器并没有选择走索引,依然是使用BNL优化策略,进行全表扫描,为什么不走索引呢?应该是优化器认为索引扫描的成本高于全表扫描的成本,因为这条语句最终结果要返回大表的90%以上的数据,走索引后回表代价是很高的。这一点我们是不认同优化器的,怎么着2500次全表扫描也比每次通过索引范围扫描的代价要高呀,好吧,既然不认同,那么使用force index来干涉优化器决策,让它使用索引。执行计划如下图所示: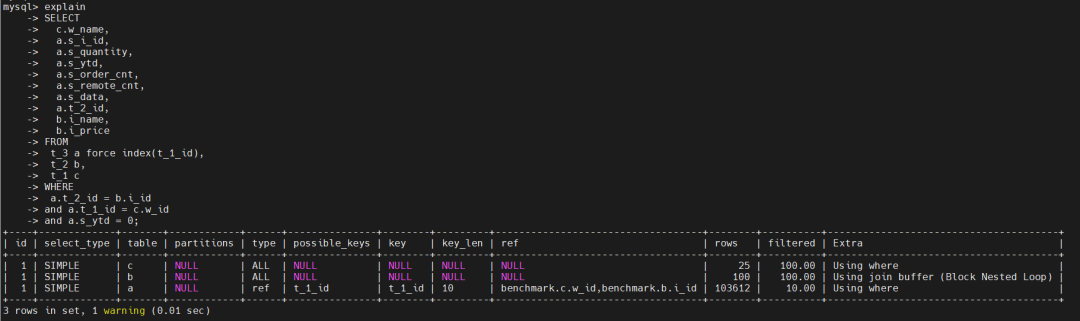 执行计划中显示索引用上了,那实际执行效果如何呢?
执行计划中显示索引用上了,那实际执行效果如何呢?mysql> insert into t_4
-> SELECT
-> c.w_name,
-> a.s_i_id,
-> a.s_quantity,
-> a.s_ytd,
-> a.s_order_cnt,
-> a.s_remote_cnt,
-> a.s_data,
-> a.t_2_id,
-> b.i_name,
-> b.i_price
-> FROM
-> t_3 a force index(t_1_id),
-> t_2 b,
-> t_1 c
-> WHERE
-> a.t_2_id = b.i_id
-> and a.t_1_id = c.w_id
-> and a.s_ytd = 0;
Query OK, 4800000 rows affected (4 min 43.57 sec)
Records: 4800000 Duplicates: 0 Warnings: 0mysql> alter table t_2 add key(i_id);
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table t_1 add key(w_id);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0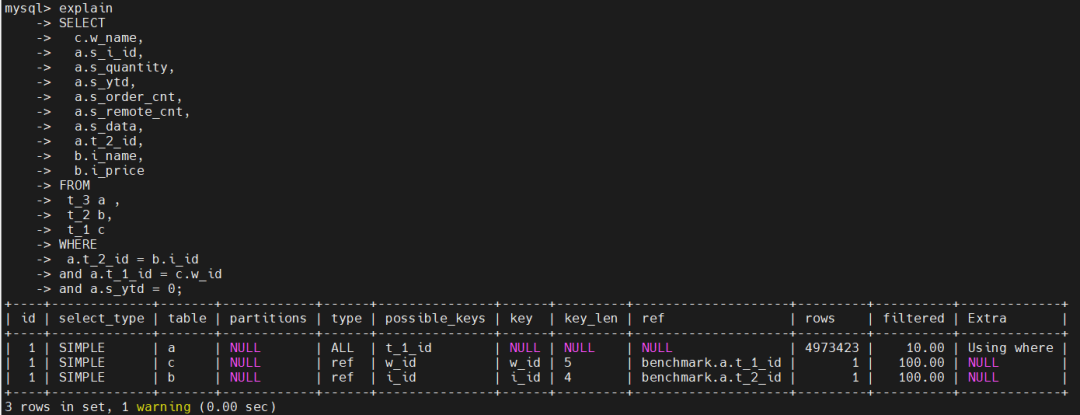 上图的执行计划显示,优化器选择了对大表全表扫描,大表做驱动表,驱动两个小表。那这样的实际效果如何呢?
上图的执行计划显示,优化器选择了对大表全表扫描,大表做驱动表,驱动两个小表。那这样的实际效果如何呢?mysql> insert into t_4
-> SELECT
-> c.w_name,
-> a.s_i_id,
-> a.s_quantity,
-> a.s_ytd,
-> a.s_order_cnt,
-> a.s_remote_cnt,
-> a.s_data,
-> a.t_2_id,
-> b.i_name,
-> b.i_price
-> FROM
-> t_3 a,
-> t_2 b,
-> t_1 c
-> WHERE
-> a.t_2_id = b.i_id
-> and a.t_1_id = c.w_id
-> and a.s_ytd = 0;
Query OK, 4800000 rows affected (1 min 59.06 sec)
Records: 4800000 Duplicates: 0 Warnings: 0mysql> alter table t_1 drop key w_id;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table t_2 drop key i_id;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table t_2 add key(i_id,i_name,i_price);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table t_1 add key(w_id,w_name);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> insert into t_4
-> SELECT
-> c.w_name,
-> a.s_i_id,
-> a.s_quantity,
-> a.s_ytd,
-> a.s_order_cnt,
-> a.s_remote_cnt,
-> a.s_data,
-> a.t_2_id,
-> b.i_name,
-> b.i_price
-> FROM
-> t_3 a,
-> t_2 b,
-> t_1 c
-> WHERE
-> a.t_2_id = b.i_id
-> and a.t_1_id = c.w_id
-> and a.s_ytd = 0;
Query OK, 4800000 rows affected (1 min 38.99 sec)
Records: 4800000 Duplicates: 0 Warnings: 0有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
在前面两节的例子中,主界面窗口的尺寸和标签控件显示的矩形区域等,都是用C++代码编写的。窗口和控件的尺寸都是预估的,控件如果多起来,那就不好估计每个控件合适的位置和大小了。用C++代码编写图形界面的问题就是不直观,因此Qt项目开发了专门的可视化图形界面编辑器——QtDesigner(Qt设计师)。通过QtDesigner就可以很方便地创建图形界面文件*.ui,然后将ui文件应用到源代码里面,做到“所见即所得”,大大方便了图形界面的设计。本节就演示一下QtDesigner的简单使用,学习拖拽控件和设置控件属性,并将ui文件应用到Qt程序代码里。使用QtDesigner设计界面在开始菜单中找到「Q
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
我找到了这样的东西:Rails:Howtolistdatabasetables/objectsusingtheRailsconsole?这一行没问题:ActiveRecord::Base.connection.tables并返回所有表但是ActiveRecord::Base.connection.table_structure("users")产生错误:ActiveRecord::Base.connection.table_structure("projects")我认为table_structure不是Postgres方法。如何列出Postgres数据库的Rails控制台中表中的所有