背景:物联网平台背景,传感器采集频率干到了1000Hz,分了100多张表出来,还是把mysql干炸了。当前单表数据量在1000来w,从kafka上拉数据异步批量插入,每次插入数据量1500条,测试的时候还没问题,结果上线没多久,kafka服务器直接挂了,赶忙看日志,kafka服务器堆积了几十G的数据,再去看生产环境日志,发现到最后单次批量插入用时固定在10多秒,甚至20多秒,kafka直接把消费端踢出了消费组…从而kafka消息一直没有消费,总重导致kafka数据堆积挂掉了…
在这样的情况下:采取的处理方案无非就分库分表,减少单表数据量,降低数据库压力;提高批量插入效率,提高消费者消费速度。
本文主要把精力放在如何提高批量插入效率上。
使用的mybatisplus的批量插入方法:saveBatch(),之前就看到过网上都在说在jdbc的url路径上加上
rewriteBatchedStatements=true 参数mysql底层才能开启真正的批量插入模式。
保证5.1.13以上版本的驱动,才能实现高性能的批量插入。 MySQL JDBC驱动在默认情况下会无视executeBatch()语句,把我们期望批量执行的一组sql语句拆散,一条一条地发给MySQL数据库,批量插入实际上是单条插入,直接造成较低的性能。只有把rewriteBatchedStatements参数置为true, 驱动才会帮你批量执行SQL。 另外这个选项对INSERT/UPDATE/DELETE都有效。
可是我之前已经添加了,而且数据表目前是没有建立索引的,即使是在1000来w的数据量下进行1500条的批量插入也不可能消耗20来秒吧,于是矛盾转移到saveBatch方法,使用版本:V3.4.3.4
查看源码:
public boolean saveBatch(Collection<T> entityList, int batchSize) {
String sqlStatement = this.getSqlStatement(SqlMethod.INSERT_ONE);
return this.executeBatch(entityList, batchSize, (sqlSession, entity) -> {
sqlSession.insert(sqlStatement, entity);
});
}
protected <E> boolean executeBatch(Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
return SqlHelper.executeBatch(this.entityClass, this.log, list, batchSize, consumer);
}
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
Assert.isFalse(batchSize < 1, "batchSize must not be less than one", new Object[0]);
return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, (sqlSession) -> {
int size = list.size();
int i = 1;
for(Iterator var6 = list.iterator(); var6.hasNext(); ++i) {
E element = var6.next();
consumer.accept(sqlSession, element);
if (i % batchSize == 0 || i == size) {
sqlSession.flushStatements();
}
}
});
}
最终来到了executeBatch()方法,可以看到这很明显是在一条一条循环插入,通过sqlSession.flushStatements()将一个个单条插入的insert语句分批次进行提交,而且是同一个sqlSession,这相比遍历集合循环insert来说有一定的性能提升,但是这并不是sql层面真正的批量插入。
通过查阅相关文档后,发现mybatisPlus提供了sql注入器,我们可以自定义方法来满足业务的实际开发需求。
sql注入器官网
sql注入器官方示例
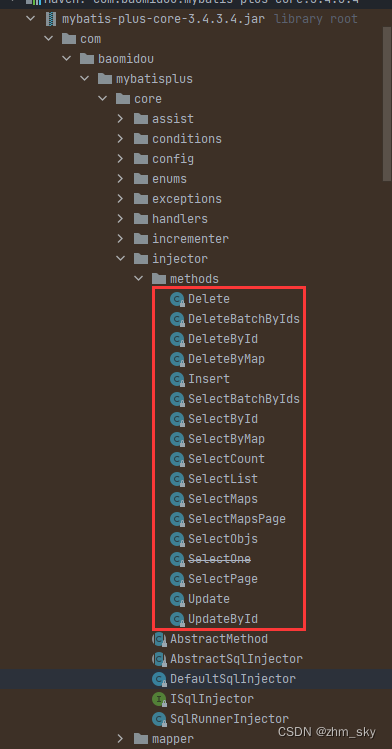
在mybtisPlus的核心包下提供的默认可注入方法有这些:
在扩展包下,mybatisPlus还为我们提供了可扩展的可注入方法:
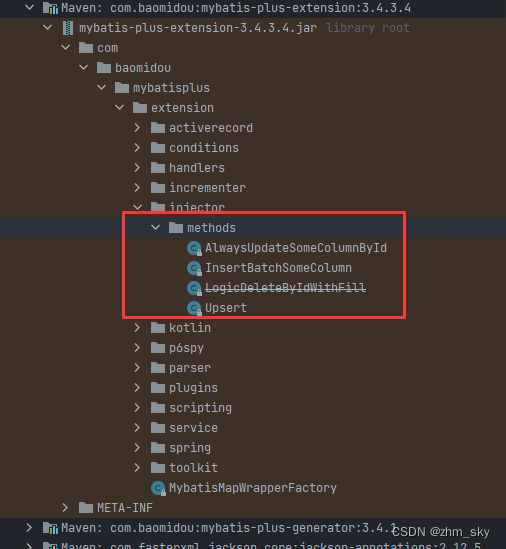
AlwaysUpdateSomeColumnById: 根据Id更新每一个字段,全量更新不忽略null字段,解决mybatis-plus中updateById默认会自动忽略实体中null值字段不去更新的问题;
InsertBatchSomeColumn: 真实批量插入,通过单SQL的insert语句实现批量插入;
Upsert: 更新or插入,根据唯一约束判断是执行更新还是删除,相当于提供insert on duplicate key update支持。
可以发现mybatisPlus已经提供好了InsertBatchSomeColumn的方法,我们只需要把这个方法添加进我们的sql注入器即可。
public MappedStatement injectMappedStatement(Class<?> mapperClass, Class<?> modelClass, TableInfo tableInfo) {
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
SqlMethod sqlMethod = SqlMethod.INSERT_ONE;
List<TableFieldInfo> fieldList = tableInfo.getFieldList();
String insertSqlColumn = tableInfo.getKeyInsertSqlColumn(true, false) + this.filterTableFieldInfo(fieldList, this.predicate, TableFieldInfo::getInsertSqlColumn, "");
//------------------------------------拼接批量插入语句----------------------------------------
String columnScript = "(" + insertSqlColumn.substring(0, insertSqlColumn.length() - 1) + ")";
String insertSqlProperty = tableInfo.getKeyInsertSqlProperty(true, "et.", false) + this.filterTableFieldInfo(fieldList, this.predicate, (i) -> {
return i.getInsertSqlProperty("et.");
}, "");
insertSqlProperty = "(" + insertSqlProperty.substring(0, insertSqlProperty.length() - 1) + ")";
String valuesScript = SqlScriptUtils.convertForeach(insertSqlProperty, "list", (String)null, "et", ",");
//------------------------------------------------------------------------------------------
String keyProperty = null;
String keyColumn = null;
if (tableInfo.havePK()) {
if (tableInfo.getIdType() == IdType.AUTO) {
keyGenerator = Jdbc3KeyGenerator.INSTANCE;
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
} else if (null != tableInfo.getKeySequence()) {
keyGenerator = TableInfoHelper.genKeyGenerator(this.getMethod(sqlMethod), tableInfo, this.builderAssistant);
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
}
}
String sql = String.format(sqlMethod.getSql(), tableInfo.getTableName(), columnScript, valuesScript);
SqlSource sqlSource = this.languageDriver.createSqlSource(this.configuration, sql, modelClass);
return this.addInsertMappedStatement(mapperClass, modelClass, this.getMethod(sqlMethod), sqlSource, (KeyGenerator)keyGenerator, keyProperty, keyColumn);
}
public class DefaultSqlInjector extends AbstractSqlInjector {
public DefaultSqlInjector() {
}
public List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo) {
if (tableInfo.havePK()) {
return (List)Stream.of(new Insert(), new Delete(), new DeleteByMap(), new DeleteById(), new DeleteBatchByIds(), new Update(), new UpdateById(), new SelectById(), new SelectBatchByIds(), new SelectByMap(), new SelectCount(), new SelectMaps(), new SelectMapsPage(), new SelectObjs(), new SelectList(), new SelectPage()).collect(Collectors.toList());
} else {
this.logger.warn(String.format("%s ,Not found @TableId annotation, Cannot use Mybatis-Plus 'xxById' Method.", tableInfo.getEntityType()));
return (List)Stream.of(new Insert(), new Delete(), new DeleteByMap(), new Update(), new SelectByMap(), new SelectCount(), new SelectMaps(), new SelectMapsPage(), new SelectObjs(), new SelectList(), new SelectPage()).collect(Collectors.toList());
}
}
}
/**
* @author zhmsky
* @date 2022/8/15 15:13
*/
public class MySqlInjector extends DefaultSqlInjector {
@Override
public List<AbstractMethod> getMethodList(Class<?> mapperClass) {
List<AbstractMethod> methodList = super.getMethodList(mapperClass);
//更新时自动填充的字段,不用插入值
methodList.add(new InsertBatchSomeColumn(i -> i.getFieldFill() != FieldFill.UPDATE));
return methodList;
}
}
/**
* @author zhmsky
* @date 2022/8/15 15:15
*/
@Configuration
public class MybatisPlusConfig {
@Bean
public MySqlInjector sqlInjector() {
return new MySqlInjector();
}
}
/**
* @author zhmsky
* @date 2022/8/15 15:17
*/
public interface CommonMapper<T> extends BaseMapper<T> {
/**
* 真正的批量插入
* @param entityList
* @return
*/
int insertBatchSomeColumn(List<T> entityList);
}
* @author zhmsky
* @since 2021-12-01
*/
@Mapper
public interface UserMapper extends CommonMapper<User> {
}
最后直接调用UserMapper的insertBatchSomeColumn()方法即可实现真正的批量插入。
@Test
void contextLoads() {
for (int i = 0; i < 5; i++) {
User user = new User();
user.setAge(10);
user.setUsername("zhmsky");
user.setEmail("21575559@qq.com");
userList.add(user);
}
long l = System.currentTimeMillis();
userMapper.insertBatchSomeColumn(userList);
long l1 = System.currentTimeMillis();
System.out.println("-------------------:"+(l1-l));
userList.clear();
}
查看日志输出信息,观察执行的sql语句,
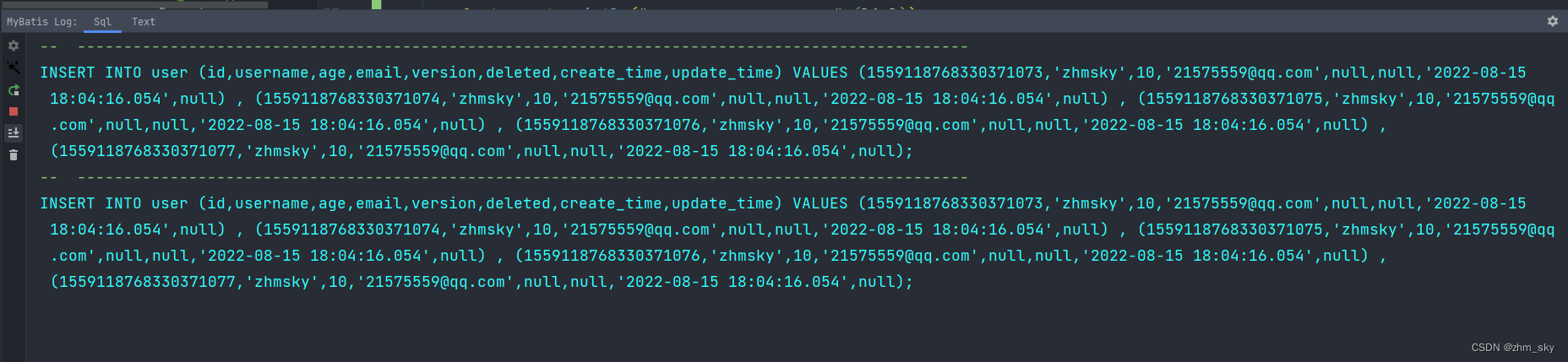
发现这才是真正意义上的sql层面的批量插入。
但是,到这里并没有结束,mybatisPlus官方提供的insertBatchSomeColumn方法不支持分批插入,也就是有多少直接全部一次性插入,这就可能会导致最后的sql拼接语句特别长,超出了mysql的限制,于是我们还要实现一个类似于saveBatch的分批的批量插入方法。
模仿原来的saveBatch方法:
* @author zhmsky
* @since 2021-12-01
*/
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
@Override
@Transactional(rollbackFor = {Exception.class})
public boolean saveBatch(Collection<User> entityList, int batchSize) {
try {
int size = entityList.size();
int idxLimit = Math.min(batchSize, size);
int i = 1;
//保存单批提交的数据集合
List<User> oneBatchList = new ArrayList<>();
for (Iterator<User> var7 = entityList.iterator(); var7.hasNext(); ++i) {
User element = var7.next();
oneBatchList.add(element);
if (i == idxLimit) {
baseMapper.insertBatchSomeColumn(oneBatchList);
//每次提交后需要清空集合数据
oneBatchList.clear();
idxLimit = Math.min(idxLimit + batchSize, size);
}
}
} catch (Exception e) {
log.error("saveBatch fail", e);
return false;
}
return true;
}
}
测试:
@Test
void contextLoads() {
for (int i = 0; i < 20; i++) {
User user = new User();
user.setAge(10);
user.setUsername("zhmsky");
user.setEmail("21575559@qq.com");
userList.add(user);
}
long l = System.currentTimeMillis();
userService.saveBatch(userList,10);
long l1 = System.currentTimeMillis();
System.out.println("-------------------:"+(l1-l));
userList.clear();
}
输出结果:
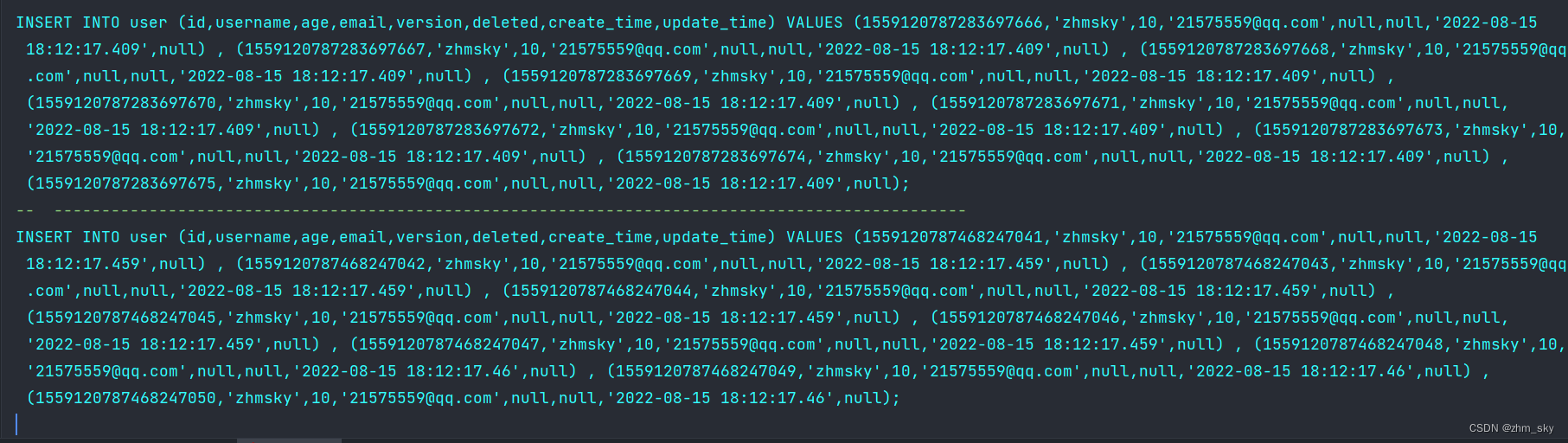
分批插入已满足,到此收工结束了。
当前数据表的数据量在100w多条,在此基础上分别拿原始的saveBatch(假的批量插入)和 insertBatchSomeColumn(真正的批量插入)进行性能对比----(jdbc均开启rewriteBatchedStatements):
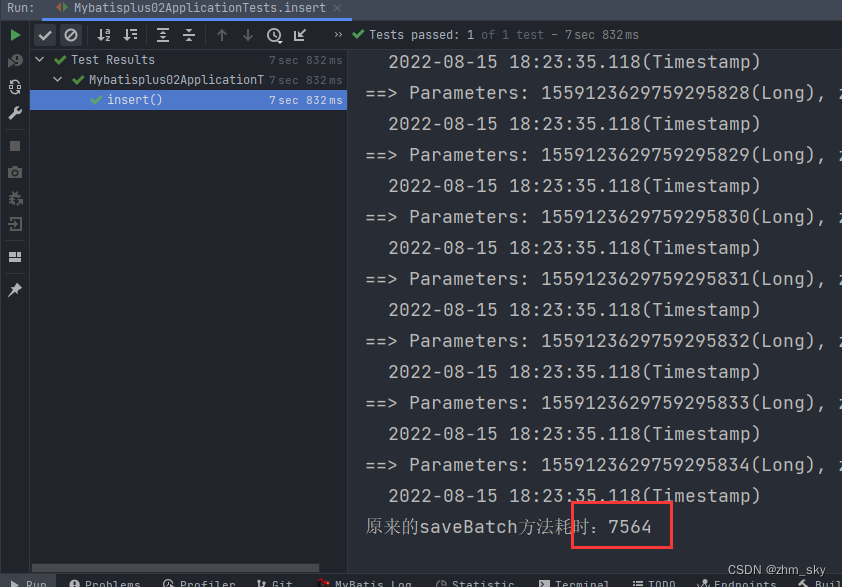
原来的假的批量插入:
@Test
void insert(){
for (int i = 0; i < 50000; i++) {
User user = new User();
user.setAge(10);
user.setUsername("zhmsky");
user.setEmail("21575559@qq.com");
userList.add(user);
}
long l = System.currentTimeMillis();
userService.saveBatch(userList,1000);
long l1 = System.currentTimeMillis();
System.out.println("原来的saveBatch方法耗时:"+(l1-l));
}
自定义的insertBatchSomeColumn:
@Test
void contextLoads() {
for (int i = 0; i < 50000; i++) {
User user = new User();
user.setAge(10);
user.setUsername("zhmsky");
user.setEmail("21575559@qq.com");
userList.add(user);
}
long l = System.currentTimeMillis();
userService.saveBatch(userList,1000);
long l1 = System.currentTimeMillis();
System.out.println("自定义的insertBatchSomeColumn方法耗时:"+(l1-l));
userList.clear();
}
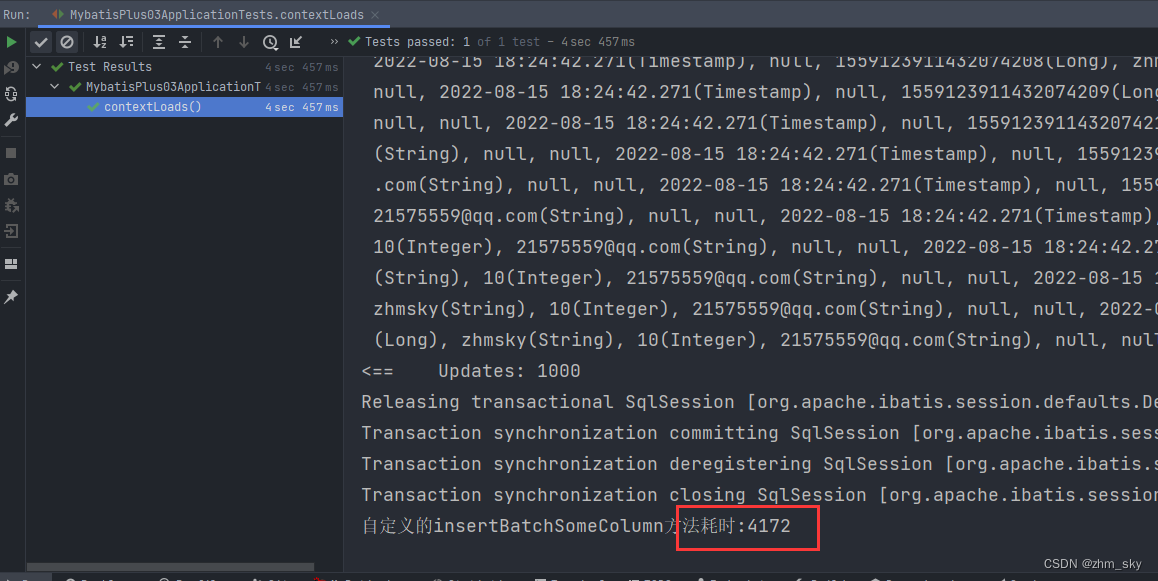
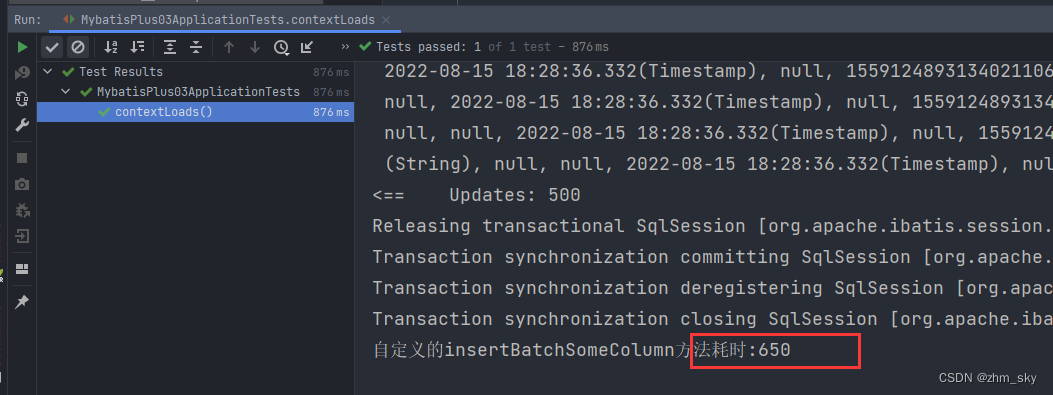
分批插入5w条数据,自定义的真正意义上的批量插入耗时减少了3秒左右,用insertBatchSomeColum分批插入1500条数据耗时650毫秒,这速度已经挺快了
我正在尝试创建一个带有项目符号字符的Ruby1.9.3字符串。str="•"+"helloworld"但是,当我输入它时,我收到有关非ASCII字符的语法错误。我该怎么做? 最佳答案 你可以把Unicode字符放在那里。str="\u2022"+"helloworld" 关于ruby-如何在Ruby字符串中插入项目符号字符?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1195
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我想知道是否可以通过自动创建数组来插入数组,如果数组不存在的话,就像在PHP中一样:$toto[]='titi';如果尚未定义$toto,它将创建数组并将“titi”压入。如果已经存在,它只会推送。在Ruby中我必须这样做:toto||=[]toto.push('titi')可以一行完成吗?因为如果我有一个循环,它会测试“||=”,除了第一次:Person.all.eachdo|person|toto||=[]#with1billionofperson,thislineisuseless999999999times...toto.push(person.name)你有更好的解决方案吗?
在我的用户模型中,我有一堆属性,例如is_foos_admin和is_bars_admin,它们决定允许用户编辑哪些类型的记录。我想干掉我的编辑链接,目前看起来像这样:'edit'ifcurrent_user.is_foos_admin?%>...'edit'ifcurrent_user.is_bars_admin?%>我想做一个帮助程序,让我传入一个foo或bar并返回一个链接来编辑它,就像这样:助手可能看起来像这样(这不起作用):defedit_link_for(thing)ifcurrent_user.is_things_admin?link_to'Edit',edit_poly
我有以下现有的Dog对象数组,它们按age属性排序:classDogattr_accessor:agedefinitialize(age)@age=ageendenddogs=[Dog.new(1),Dog.new(4),Dog.new(10)]我现在想插入一条新的狗记录,并将它放在数组中的正确位置。假设我想插入这个对象:another_dog=Dog.new(8)我想把它插入到数组中,让它成为数组中的第三项。这是一个人为的示例,旨在演示我特别想如何将一个项目插入到现有的有序数组中。我意识到我可以创建一个全新的数组并重新对所有对象进行排序,但这不是我的目标。谢谢!
在字符串连接中,是否可以直接在语句中包含条件?在下面的示例中,我希望仅当dear列表不为空时才连接"mydear"。dear=""string="hello"+"mydear"unlessdear.empty?+",goodmorning!"但是结果报错:undefinedmethod'+'fortrue我知道另一种方法是在这条语句之前定义一个额外的变量,但我想避免这种情况。 最佳答案 使用插值而不是连接更容易和更具可读性:dear=""string="hello#{'mydear'unlessdear.empty?},goodmo
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
我想使用Ruby检查数千对文件中的每对文件是否包含相同的信息。有人能指出我正确的方向吗? 最佳答案 require'fileutils'FileUtils.compare_file('file1','file2')当且仅当文件file1和file2相同时返回true。 关于ruby-如何批量检查文件内容是否相同,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/33769865/