
✨博客主页: 心荣~
✨系列专栏:【Java实现数据结构】
✨一句短话: 难在坚持,贵在坚持,成在坚持!
文章目录
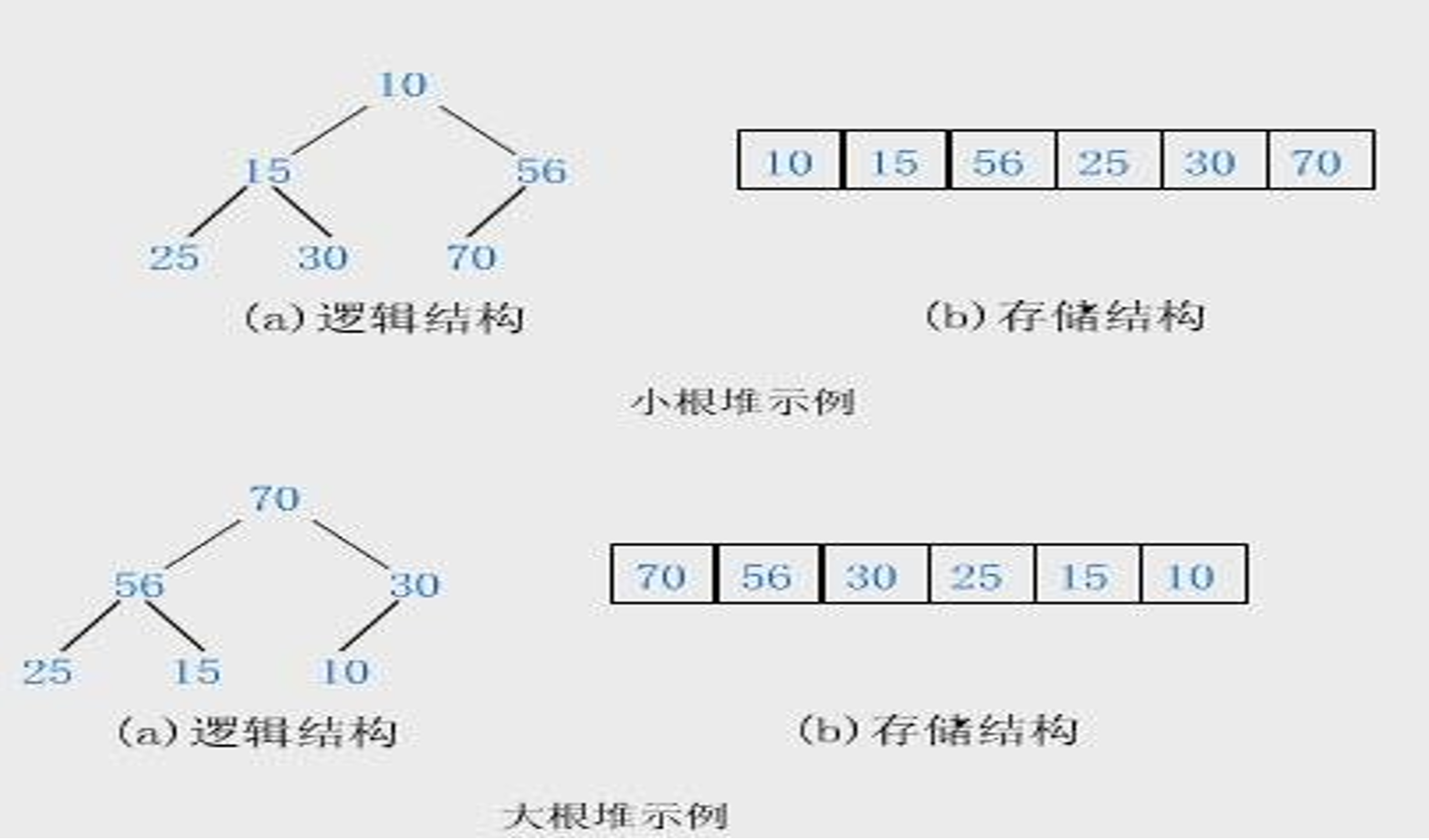
如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储 在一 个一维数组中,并满足:Ki <= K2i+1 且 Ki<= K2i+2 (Ki >= K2i+1 且 Ki >= K2i+2) i = 0,1,2…,则称为 小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆的性质:
从堆的概念可知,堆是一棵完全二叉树,因此可以层序的规则采用顺序的方式来高效存储,
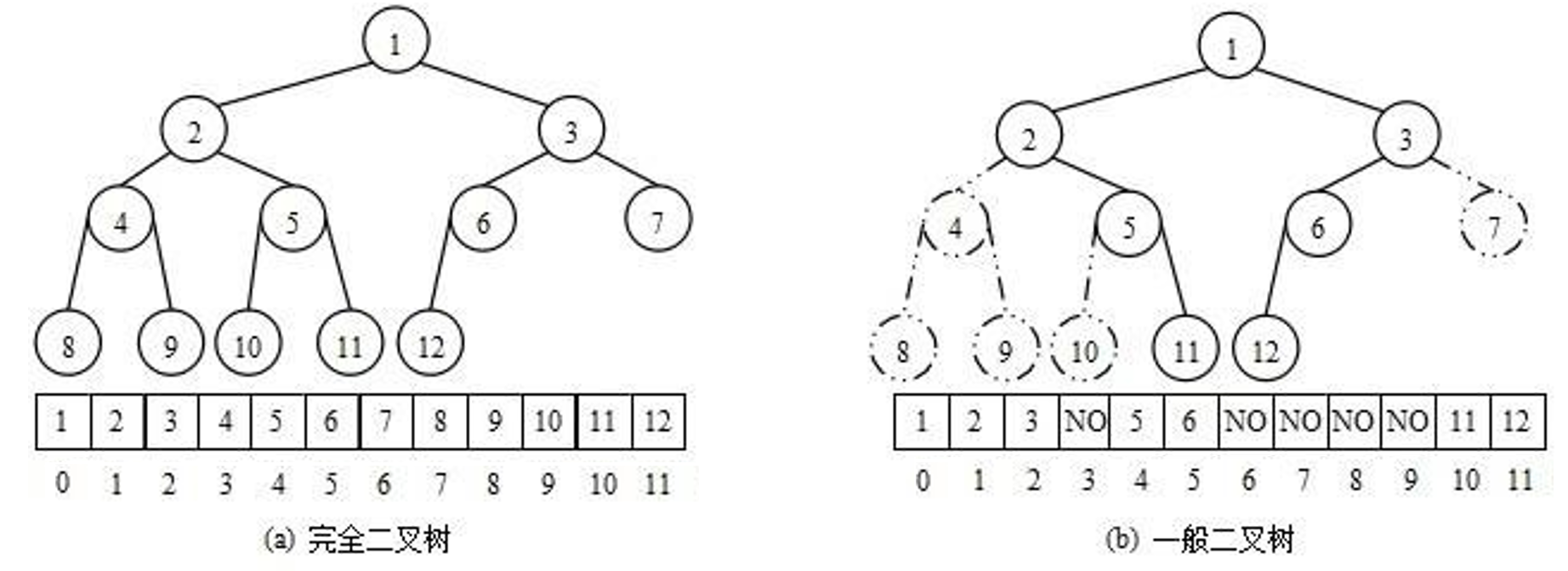 注意:对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。
注意:对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。
假设i为节点在数组中的下标,则有:
【向下调整】
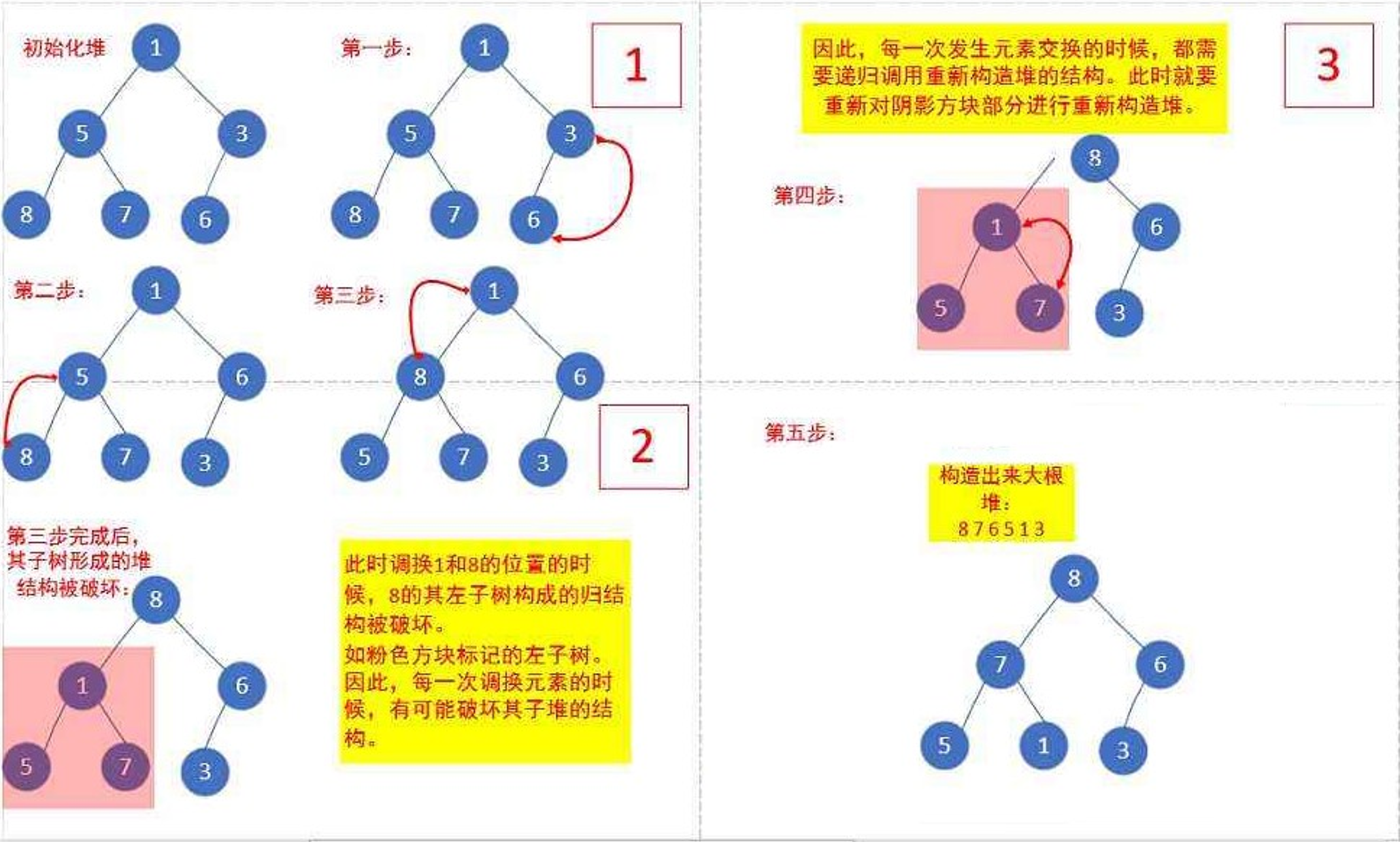
首先我们需要知道堆的特点, 堆的堆顶的元素大于 (或小于) 子堆的元素大小,堆的本质就是一棵完全二叉树,堆采用顺序存储的方式来实现, 所以根据这些特点可以总结出堆的创建过程。
设最后一棵子树根结点所对应数组下标为parent,其左子树根结点为child,堆大小为len,根据二叉树的性质,下标会满足child = 2 ∗ parent + 1 ; parent = (child − 1 ) / 2 ;
最后一个结点下标为len−1,其父结点下标为(len−2) / 2 ; 也就是说 , 最后一棵子树根结点的下标为(len−2) / 2
对于向下调整中,以创建大根堆为例,如果一棵子树右结点存在且大于左结点的值,则child++保证child指向的是左右结点中较大的那一个
下面给出的是堆的基本成员属性,
public class MyHeap {
public int[] elem;
public int usedSize;//记录有效元素个数
public static final int DEFAULT_SIZE = 10;//默认容量
public MyHeap() {
elem = new int[DEFAULT_SIZE];
}
//初始化数组
public void initElem(int[] array) {
for (int i = 0; i < array.length; i++) {
this.elem[i] = array[i];
usedSize++;
}
}
}
代码实现创建大根堆,
//调整数组元素,创建大根堆
public void createHeap() {
//从最后一个双亲节点开始向下调整
for (int parent = (this.usedSize-1-1)/2; parent >= 0; parent--) {
//向下调整
shiftDown(parent, this.usedSize);
}
}
/**
* 向下调整
* @param parent 每棵树的根节点位置
* @param len 用来判断每棵子树调整的结束时机, 位置不能大于len
*/
public void shiftDown(int parent, int len) {
//计算左孩子位置
int child = parent*2+1;
//要判断左孩子是否存在
while(child < len) {
//确定右孩子是否存在,确定最大值
if (child + 1 < len && elem[child] < elem[child+1]) {
child++;
}
//走到这里child指向的一定是左右孩子中较大的
if(elem[parent] < elem[child]) {
int tmp = elem[parent];
elem[parent] = elem[child];
elem[child] = tmp;
parent = child;
child = 2*parent+1;
}else {
break;
}
}
}
【建堆的时间复杂度】
建堆的过程是自下而上的,堆的本质就是一棵完全二叉树,不妨设该二叉树的高度为h,堆元素个数为n,建堆时需要对所有高度大于1的子树进行调整,最坏情况下该堆是一个满堆,设该堆所处层次为x(从1开始),则第x层次的子树需要调整h-x次,有2 ^ (h-1)个结点,由于只调整高度大于1的子树,因此x的范围为[1,h−1]
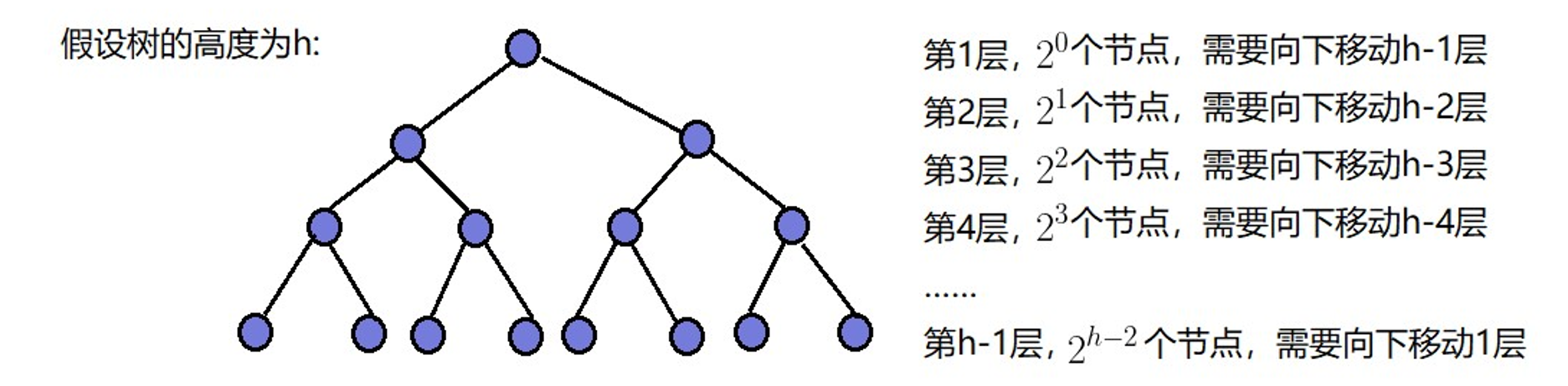
调整的次数为T(n):
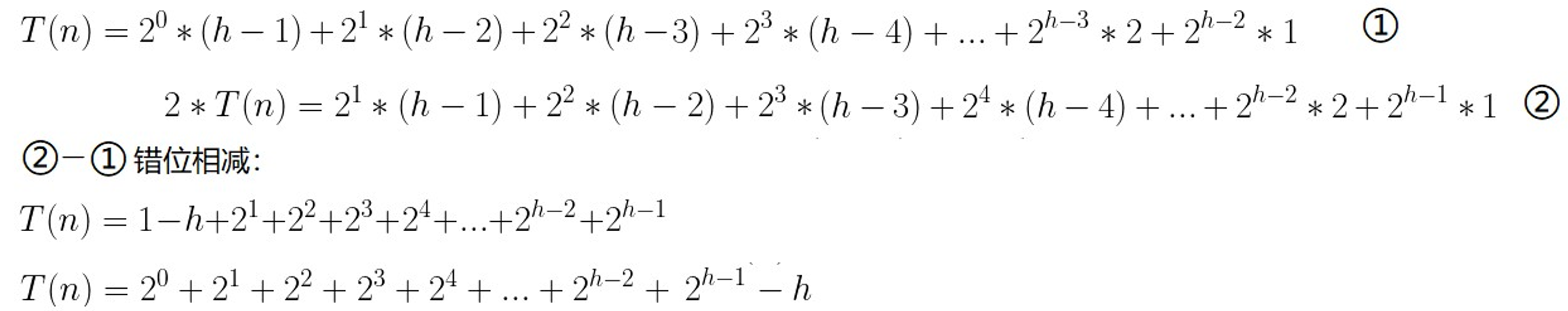
我们发现T(n)为等比数列和减去h再加上1,等比数列求和公式为Sn=a1(1−qn)/(1−q)
T(n)=2∗(1−2h−1)/(−1)−h+1
T(n)=2 ^ h−h−1
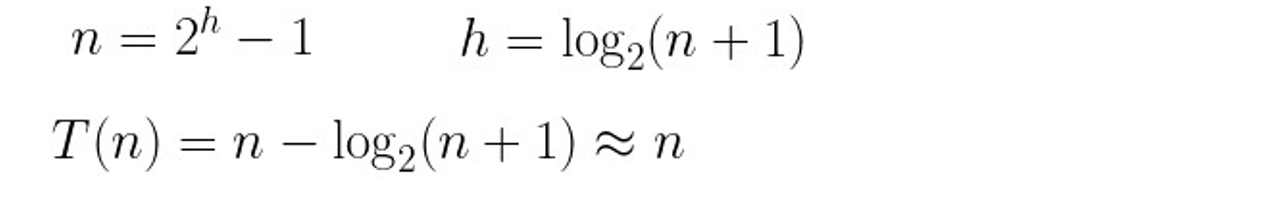
所以,建堆的时间复杂度为O(N)。
按照如下步骤完成元素入堆:
下面是对向上调整的说明:
在数组最后一个位置放入一个元素后,以大根堆为例, 这个元素所在的子树就可能不满足大根堆的条件了, 所以需要对该结点进行向上调整,让这棵子树再次满足大根堆, 如果做出了调整, 就需要一直先向上调整, 直至满足条件 ; 所谓向上调整就是比较 调整结点与父亲结点 值的大小,如果该结点值比较大,则与父亲结点交换值,否则不需调整,该堆已经满足大根堆条件,因为交换后不知道上面的子树是否为大根堆,所以需要对交换路径上所有的结点进行相同的向上调整,直到调整完堆顶,过程中出现父亲结点比较大则结束调整; 同样的如果是小根堆,思路是一样的, 只需要把把 调整结点与父亲结点 的比较方式改变一下即可.
下面的实现代码以大根堆为例:
public void offer(int val) {
//判断空间是不是满了
if(isFull()) {
elem = Arrays.copyOf(elem, 2*elem.length);
}
elem[usedSize] = val;
usedSize++;
//向上调整
shiftUp(usedSize-1);
}
public boolean isFull() {
return usedSize == elem.length;
}
public void shiftUp(int child) {
int parent = (child-1)/2;
while(child > 0) {
if (elem[parent] < elem[child]) {
int tmp = elem[parent];
elem[parent] = elem[child];
elem[child] = tmp;
child = parent;
parent = (child-1)/2;
}else{
break;
}
}
}
注意:出堆的元素一定是堆顶元素
按照如下步骤完成元素出堆:
下面的实现代码以大根堆为例:
//堆的删除
public int pop() {
if(isEmpty()) {
throw new EmptyHeapException("当前堆为空");
}
int tmp = elem[0];
elem[0] = elem[usedSize-1];
elem[usedSize-1] = tmp;
usedSize--;
shiftDown(0, usedSize);
return tmp;
}
//判断堆是否为空
public boolean isEmpty() {
return usedSize == 0;
}
//获取堆中元素
public int peek() {
if(isEmpty()) {
throw new EmptyHeapException();
}
return elem[0];
}
//清空
public void clear() {
usedSize = 0;
}
public int size() {
return usedSize;
}
在优先级队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征,通常采用堆数据结构来实现; 比如说一个优先队列是由小根堆实现的,则该队列优先最小的元素出队,反之,优先队列由大根堆实现,则该队列优先最大的元素出队。
关于PriorityQueue的使用要注意:
集合框架中的PriorityQueue底层使用堆结构,因此其内部的元素必须要能够比较大小,PriorityQueue采用了:
Comparble和Comparator两种方式。
// JDK中PriorityQueue的实现:
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
// ...
// 默认容量
private static final int DEFAULT_INITIAL_CAPACITY = 11;
// 内部定义的比较器对象,用来接收用户实例化PriorityQueue对象时提供的比较器对象
private final Comparator<? super E> comparator;
// 用户如果没有提供比较器对象,使用默认的内部比较,将comparator置为null
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
// 如果用户提供了比较器,采用用户提供的比较器进行比较
public PriorityQueue(int initialCapacity, Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
// ...
// 向上调整:
// 如果用户没有提供比较器对象,采用Comparable进行比较
// 否则使用用户提供的比较器对象进行比较
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
// 使用Comparable
@SuppressWarnings("unchecked")
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
// 使用用户提供的比较器对象进行比较
@SuppressWarnings("unchecked")
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
}
下面的代码是定义一个的自定义类型, 要将自定义类型入堆, 自定义类型必须实现Comparble接口; 将第一个元素入堆时不涉及比较, 当第二个元素入堆就会涉及比较了;
class Person implements Comparable<Person>{
int age;
String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public int compareTo(Person o) {
return this.age - o.age;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
public class Test {
public static void main(String[] args) {
PriorityQueue<Person> priorityQueue = new PriorityQueue<>();
priorityQueue.offer(new Person(18,"张三"));
priorityQueue.offer(new Person(20,"李四"));
}
}
| 构造器 | 功能介绍 |
|---|---|
| PriorityQueue() | 创建一个空的优先级队列,默认容量是11 |
| PriorityQueue(int initialCapacity) | 创建一个初始容量为initialCapacity的优先级队列,注意: initialCapacity不能小于1,否则会抛IllegalArgumentException异 常 |
| PriorityQueue(Collection< ? extends E > c) | 用一个集合来创建优先级队列 |
观察这三个构造方法的源码, 其实在底层是又调用了含有两个参数的构造方法public PriorityQueue(int initialCapacity**,** Comparator<? super E> comparator), 除了设置容量的参数外, 另一个参数是一个比较器, 在调用时设置为了null;




构造示例:
static void TestPriorityQueue(){
// 创建一个空的优先级队列,底层默认容量是11
PriorityQueue<Integer> q1 = new PriorityQueue<>();
// 创建一个空的优先级队列,底层的容量为initialCapacity
PriorityQueue<Integer> q2 = new PriorityQueue<>(100);
ArrayList<Integer> list = new ArrayList<>();
list.add(4);
list.add(3);
list.add(2);
list.add(1);
// 用ArrayList对象来构造一个优先级队列的对象
// q3中已经包含了三个元素
PriorityQueue<Integer> q3 = new PriorityQueue<>(list);
System.out.println(q3.size());
System.out.println(q3.peek());
}
注意:默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue1 = new PriorityQueue<>(new IntCmp());
priorityQueue1.offer(1);
priorityQueue1.offer(2);
priorityQueue1.offer(3);
System.out.println(priorityQueue1);
//使用隐藏内部类创建基于大根堆的优先队列
PriorityQueue<Integer> priorityQueue2 = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
priorityQueue2.offer(1);
priorityQueue2.offer(2);
priorityQueue2.offer(3);
System.out.println(priorityQueue1);
//使用lambda表达式创建基于大根堆的优先队列
PriorityQueue<Integer> priorityQueue3 = new PriorityQueue<>((x, y) -> y-x);
priorityQueue3.offer(1);
priorityQueue3.offer(2);
priorityQueue3.offer(3);
System.out.println(priorityQueue1);
}
| 方法名 | 功能介绍 |
|---|---|
| boolean offer(E e) | 插入元素e,插入成功返回true,如果e对象为空,抛出NullPointerException异常,时 间复杂度 O(logN),注意:空间不够时候会进行扩容 |
| E peek() | 获取优先级最高的元素,如果优先级队列为空,返回null |
| E poll() | 移除优先级最高的元素并返回,如果优先级队列为空,返回null |
| int size() | 获取有效元素的个数 |
| void clear() | 清空 |
| boolean isEmpty() | 检测优先级队列是否为空,空返回true |
static void TestPriorityQueue2(){
int[] arr = {4,1,9,2,8,0,7,3,6,5};
// 一般在创建优先级队列对象时,如果知道元素个数,建议就直接将底层容量给好
// 否则在插入时需要不够时要去扩容
// 扩容机制:开辟更大的空间,拷贝元素,这样效率会比较低
PriorityQueue<Integer> q = new PriorityQueue<>(arr.length);
for (int e: arr) {
q.offer(e);
}
System.out.println(q.size()); // 打印优先级队列中有效元素个数
System.out.println(q.peek()); // 获取优先级最高的元素
// 从优先级队列中删除两个元素之和,再次获取优先级最高的元素
q.poll();
q.poll();
System.out.println(q.size()); // 打印优先级队列中有效元素个数
System.out.println(q.peek()); // 获取优先级最高的元素
q.offer(0);
System.out.println(q.peek()); // 获取优先级最高的元素
// 将优先级队列中的有效元素删除掉,检测其是否为空
q.clear();
if(q.isEmpty()){
System.out.println("优先级队列已经为空!!!");
}
else{
System.out.println("优先级队列不为空");
}
}
以下是JDK 1.8中,PriorityQueue的扩容方式:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
TOP-K问题:即求数据集合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
要处理这个问题, 我们能想到的最简单的方式就是排序, 但是如果数据量非常大的话, 就不推荐使用排序了, 因为我们只要拿到几个元素, 数据量很大时使用排序效率就比较低了;
使用堆,如求的是前k个最大的元素,可以创建一个基于大根堆的优先级队列,把所有数据入堆,所有元素都入堆之后再出堆k个元素,这k个元素就是前k个最大的元素。
上面的两种思路有一个缺陷就是, 如果数据量非常大的话, 效率就会很低下; Top-k问题标准解决思路如下:
求的是前k个最大元素, 如果比所建小根堆的堆顶元素大, 则替换堆顶元素
求的是前k个最小元素, 如果比所建大根堆的堆顶元素大, 则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
时间复杂度分析
向上调整建堆的时间复杂度:
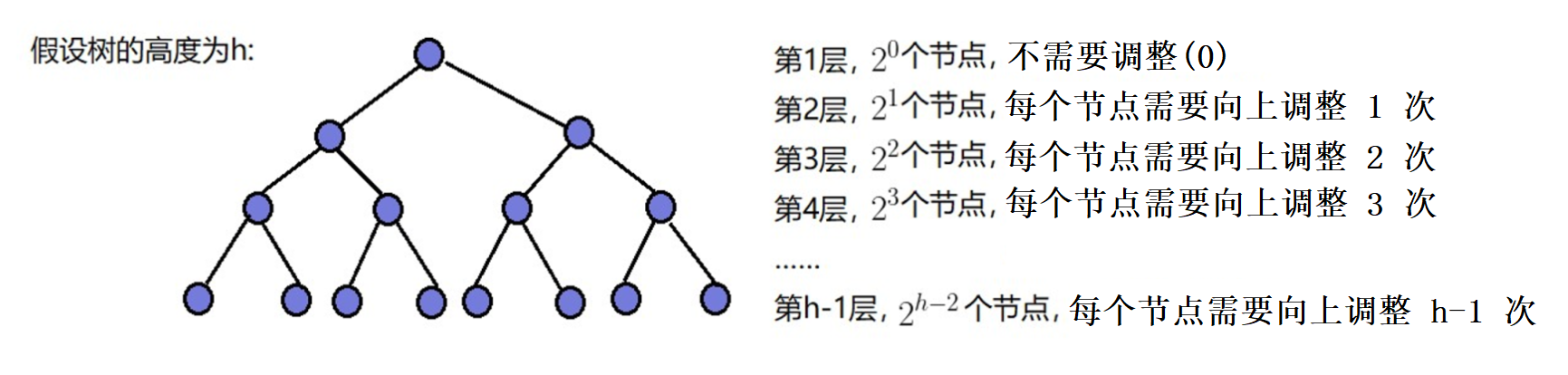

[思路2时间复杂度分析]:
要将N个元素都放入到堆中, 每次入堆都需要向上调整(N*logN);
堆建好后, 将k个元素出堆, 每次出堆都需要向下调整(K*logN)
所以时间复杂度为O(NlogN+KlogN)
[思路3时间复杂度分析]:
建立大小为k的大/小根堆(K*logK)
遍历剩下的N-K个元素每个都和堆顶比较, 最坏的情况下, 每次都需要去调整((N-K)*logK)
所以时间复杂度为O( K*logK+(N-K)logK ) = O(NlogK)
在线OJ:面试题 17.14. 最小K个数
设计一个算法,找出数组中最小的k个数。以任意顺序返回这k个数均可。
示例:
输入: arr = [1,3,5,7,2,4,6,8], k = 4
输出: [1,2,3,4]
提示:
class Solution {
//方法三: 建立一个大小为k的大根堆
public int[] smallestK(int[] arr, int k) {
if(arr == null || k <= 0) {
return new int[0];
}
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(new Comparator<Integer>(){
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
for (int i = 0; i < k; i++) {
maxHeap.offer(arr[i]);
}
for (int i = k; i < arr.length; i++) {
if(arr[i] < maxHeap.peek()) {
maxHeap.poll();
maxHeap.offer(arr[i]);
}
}
int[] tmp = new int[k];
for (int i = 0; i < k; i++) {
tmp[i] = maxHeap.poll();
}
return tmp;
}
//方法二: 将数据全部入堆
/*public int[] smallestK(int[] arr, int k) {
PriorityQueue<Integer> heap = new PriorityQueue<>();
for (int i = 0; i < arr.length; i++) {
heap.offer(arr[i]);
}
int[] tmp = new int[k];
for (int i = 0; i < k; i++) {
tmp[i] = heap.poll();
}
return tmp;
}*/
//方法一: 排序
/*public int[] smallestK(int[] arr, int k) {
Arrays.sort(arr);
int[] tmp = new int[k];
for(int i = 0; i < k; i++) {
tmp[i] = arr[i];
}
return tmp;
}*/
}
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
首先回顾一下拉格朗日定理的内容:函数f(x)是在闭区间[a,b]上连续、开区间(a,b)上可导的函数,那么至少存在一个,使得:通过这个表达式我们可以知道,f(x)是函数的主体,a和b可以看作是主体函数f(x)中所取的两个值。那么可以有, 也就意味着我们可以用来替换 这种替换可以用在求某些多项式差的极限中。方法: 外层函数f(x)是一致的,并且h(x)和g(x)是等价无穷小。此时,利用拉格朗日定理,将原式替换为 ,再进行求解,往往会省去复合函数求极限的很多麻烦。使用要注意:1.要先找到主体函数f(x),即外层函数必须相同。2.f(x)找到后,复合部分是等价无穷小。3.要满足作差的形式。如果是加
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手