RabbiMQ 是用 Erlang 开发的, 集群非常方便, 因为 Erlang 天生就是一门分布式语言, 但其本身并不支持负载均衡。
RabbitMQ 集群中节点包括内存节点(RAM)、 磁盘节点(Disk, 消息持久化), 集群中至少有一个 Disk 节点。
对于普通模式, 集群中各节点有相同的队列结构, 但消息只会存在于集群中的一个节点。 对于消费者来说, 若消息进入 A 节点的 Queue 中, 当从 B 节点拉取时, RabbitMQ 会将消息从 A 中取出, 并经过 B 发送给消费者。
应用场景: 该模式各适合于消息无需持久化的场合, 如日志队列。 当队列非持久化, 且创建该队列的节点宕机, 客户端才可以重连集群其他节点, 并重新创建队列。 若为持久化,只能等故障节点恢复。
与普通模式不同之处是消息实体会主动在镜像节点间同步, 而不是在取数据时临时拉取, 高可用; 该模式下, mirror queue 有一套选举算法, 即 1 个 master、 n 个 slaver, 生产者、 消费者的请求都会转至 master。
应用场景: 可靠性要求较高场合, 如下单、 库存队列。
缺点: 若镜像队列过多, 且消息体量大, 集群内部网络带宽将会被此种同步通讯所消耗。
(1) 镜像集群也是基于普通集群, 即只有先搭建普通集群, 然后才能设置镜像队列。
(2) 若消费过程中, master 挂掉, 则选举新 master, 若未来得及确认, 则可能会重复消费。
#创建rabbitmq用于存放rabbitmq集群映射信息
mkdir /mydata/rabbitmq
#分别创建各集群映射目录
cd rabbitmq/
mkdir rabbitmq01 rabbitmq02 rabbitmq03
rabbitmq01
docker run -d --hostname rabbitmq01 --name rabbitmq01 -v /mydata/rabbitmq/rabbitmq01:/var/lib/rabbitmq -p 15673:15672 -p 5673:5672 -e RABBITMQ_ERLANG_COOKIE='zr' rabbitmq:3.8.2-management
rabbitmq02
docker run -d --hostname rabbitmq02 --name rabbitmq02 -v/mydata/rabbitmq/rabbitmq02:/var/lib/rabbitmq -p 15674:15672 -p 5674:5672 -e RABBITMQ_ERLANG_COOKIE='zr' --link rabbitmq01:rabbitmq01 rabbitmq:3.8.2-management
rabbitmq03
docker run -d --hostname rabbitmq03 --name rabbitmq03 -v /mydata/rabbitmq/rabbitmq03:/var/lib/rabbitmq -p 15675:15672 -p 5675:5672 -e RABBITMQ_ERLANG_COOKIE='zr' --link rabbitmq01:rabbitmq01 --link rabbitmq02:rabbitmq02 rabbitmq:3.8.2-management
注意事项:
–hostname 设置容器的主机名
RABBITMQ_ERLANG_COOKIE节点认证作用, 部署集成时 需要同步该值RABBITMQ_ERLANG_COOKIE 为rabbitmq多节点之间通信所用到的cookie,rabbitmq集群就是利用这一特性实现的
启动成功后
http://192.168.157.128:15673/#/
http://192.168.157.128:15674/#/
http://192.168.157.128:15675/#/
账号:guest
密码:guest
登录查看一下,目前都是单节点

设置rabbitmq01为主节点
docker exec -it rabbitmq01 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
Exit

如果出现以下情况说明rabbitmq版本太高了,新拉一个镜像3.8.2(老师对应的),当然也可以按照高版本的配置
docker pull rabbitmq:3.8.2

将rabbitmq02加入rabbitmq01
docker exec -it rabbitmq02 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq01
rabbitmqctl start_app
exit

将rabbitmq02加入rabbitmq01
docker exec -it rabbitmq03 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq01
rabbitmqctl start_app
exit
最后能看到其他节点信息也就成功了(普通模式)
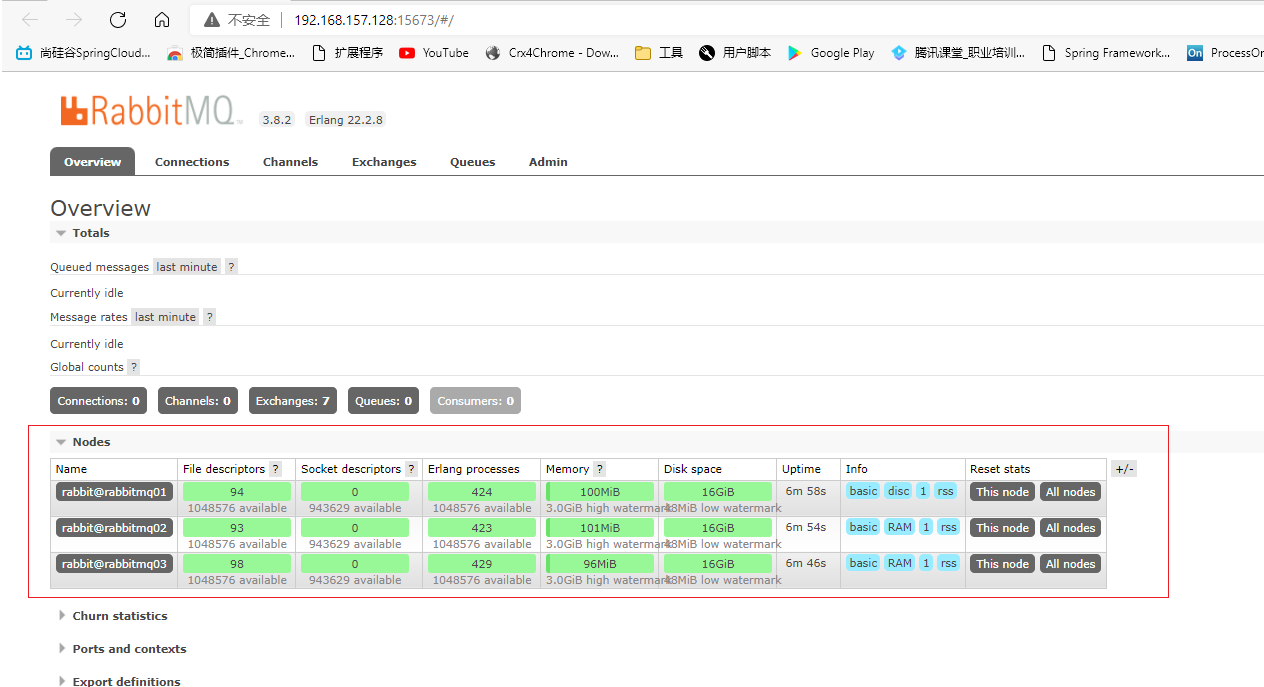
说明一下端口15673为rabbitmq01 ,15674为rabbitmq02,15675为rabbitmq03
在rabbitmq01新建test队列

在rabbitmq01新建test交换机,并绑定关系


同时发现rabbitmq02,rabbitmq03中也创建了相同的交换机,队列,绑定关系

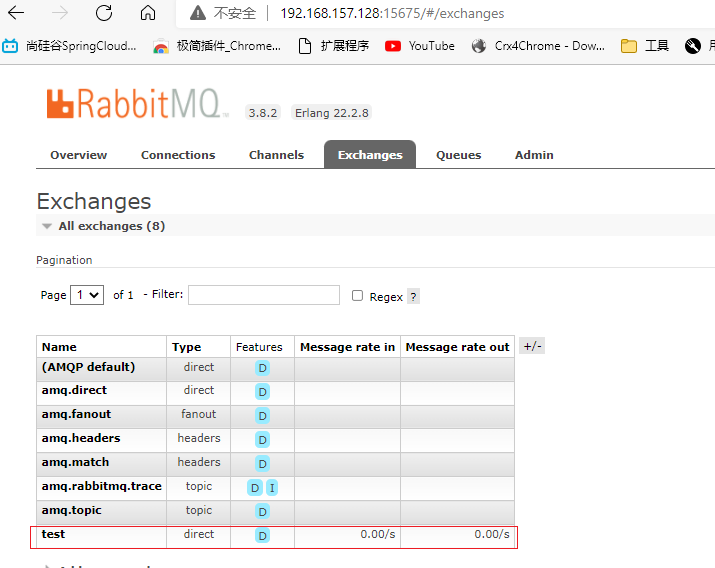
向rabbitmq01的交换机发送消息

在rabbitmq02 rabbitmq03中也能拿到消息
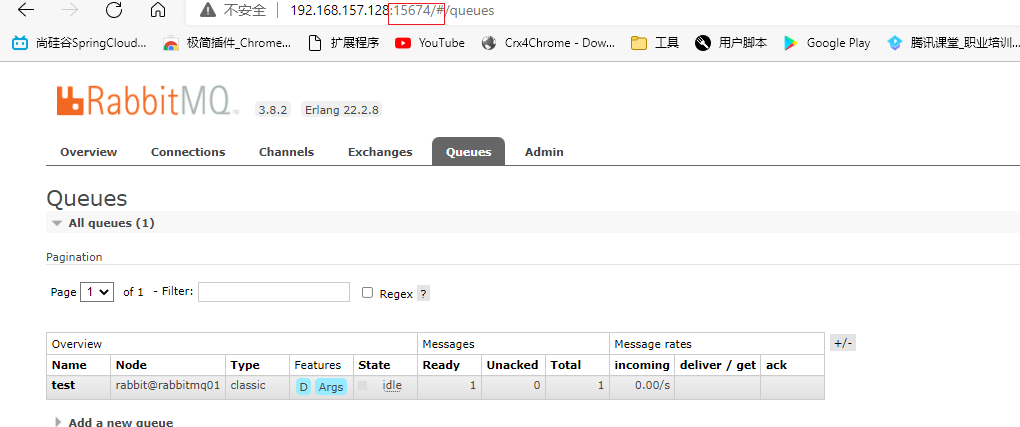

在一个节点中消费了该消息,其他节点中将不会存在该消息
在普通模式集群的条件下才能搭建镜像集群,并且需要选择一个主节点,此处我们选择rabbitmq01为主节点
#进入rabbitmq01容器
docker exec -it rabbitmq01 bash
首先查看此时的策略什么,发现为空,默认普通模式
rabbitmqctl list_policies -p /

增加镜像模式策略
策略模式 all 即复制到所有节点, 包含新增节点,
策略正则表达式为 “^” 表示所有匹配所有队列名称。
“^hello”表示只匹配名为 hello 开始的队列
rabbitmqctl set_policy -p / ha "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
查看此时的策略

管理页面查看

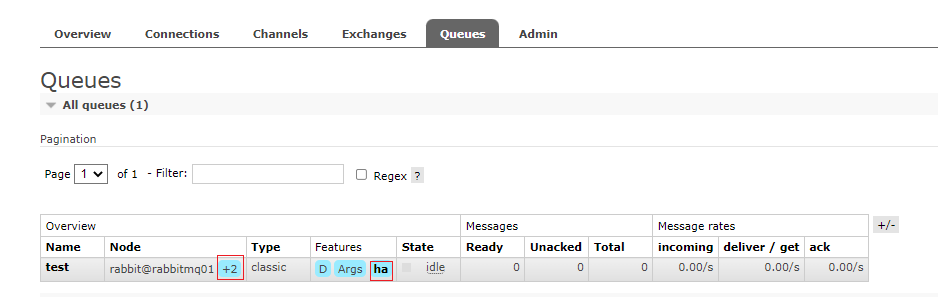
再次向rabbitma01的test交换机发送信息,正常情况与普通模式一致
当我向rabbitma01发送消息后,宕机了,普通模式由于本质是其他节点比如rabbitma02去拿rabbitma01的消息再转交给我,所以当rabbitma01宕机后就拿不到消息了.
镜像模式由于是同步的,当rabbitma01宕机后客户端是直接可以向其他节点拿到消息的
(个人理解普通模式就是代理,源头断了也就什么都没有了;镜像模式就是复制cv,一个地方断掉了,但是还可以从其他地方还能拿到)
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
绝对详细的RabbitMQ实践操作手册,看完本系列就够了。一、什么是MQ?1、MQ的概念2、理解消息队列二、MQ的优势和劣势1、优势和作用2、劣势三、MQ的应用场景四、AMQP五、工作原理一、什么是MQ?1、MQ的概念MQ全称MessageQueue(消息队列),是在消息的传输过程中保存消息的容器。多用于系统之间的异步通信。下面用图来理解异步通信,并阐明与同步通信的区别。同步通信:甲乙两人面对面交流,你一句我一句必须同步进行,两人除此之外不做任何事情异步通信:异步通信相当于通过第三方转述对话,可能有消息的延迟,但不需要二人时刻保持联系,消息传给第三方后,两人可以做其他自己想做的事情,当需要获取
目录一、下载Elasticsearch1.选择你要下载的Elasticsearch版本二、采用通用搭建集群的方法三、配置三台es1.上传压缩包到任意一台虚拟机中2.解压并修改配置文件(配置单台es)3.配置三台es集群4.设置后台启动和开机自启(可选)一、下载Elasticsearch1.选择你要下载的Elasticsearch版本es下载地址这里我下载的是二、采用通用搭建集群的方法集群搭建方法三、配置三台es1.上传压缩包到任意一台虚拟机中上传方式有两种第一种:使用xftp上传直接拖动过去就可以了。第二种:使用lrzsz先安装yum-yinstalllrzsz切换到要上传的位置cd/opt/
文章目录一.k8s集群修改config1.1备份当前k8s集群配置文件1.2删除当前k8s集群的apiserver的cert和key1.3生成新的apiserver的cert和key1.4刷新admin.conf1.5重启apiserver1.6刷新.kube/config二.安装kubectl2.1下载kubectl2.2配置kubectl三.使用kubernetes-client操作k8s集群3.1依赖3.2注意(可忽略)3.3创建StatefulSet3.4运行shell命令3.5删除StatefulSet3.6线上运行注意一.k8s集群修改config因为默认的是内网IP,复制出来后,
十一、ES集群的相关概念上一篇文章《ElasticSearch-聚合查询》集群(cluster)一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜整合应用索功能。一个集群由一个唯一的名字标识,这个名字默认就是elasticsearch。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群节点(node)一个节点是集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引节点和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点索引(Index)一组
一、安装ElasticSearch使用docker直接获取es镜像,执行命令dockerpullelasticsearch:7.7.0执行完成后,执行dockerimages即可看到上一步拉取的镜像。二、创建数据挂在目录,以及配置ElasticSearch集群配置文件,调高JVM线程数限制数量1.创建数据文件挂载目录,然后直接关闭防火墙mkdir-p/home/soft/ESmkdir-p/home/soft/ES/configcd/home/soft/ES创建挂载目录mkdirdata1data2data3进入config文件里面创建es配置文件cdES/config/查询防火墙状态syst
我想用自定义图像更改谷歌地图聚类。但是,它不会改变我提供的任何内容。这个initMap函数是https://developers.google.com/maps/documentation/javascript/marker-clustering然后我尝试用来自谷歌的一些随机图像来更改集群图像。但是,它不呈现任何内容。集群不支持自定义集群镜像??functioninitMap(){varmap=newgoogle.maps.Map(document.getElementById('map'),{zoom:3,center:{lat:-28.024,lng:140.887}});//Cr