我认为,IP地址和MAC地址可以类比生活中寄快递的过程。
在整个网络中数据被封装成数据报文进行发送,就像我们生活中寄快递时将物品放进包裹中。而数据在路由器之间的跳转也可以看作是不同地区快递小哥对物流的交接。
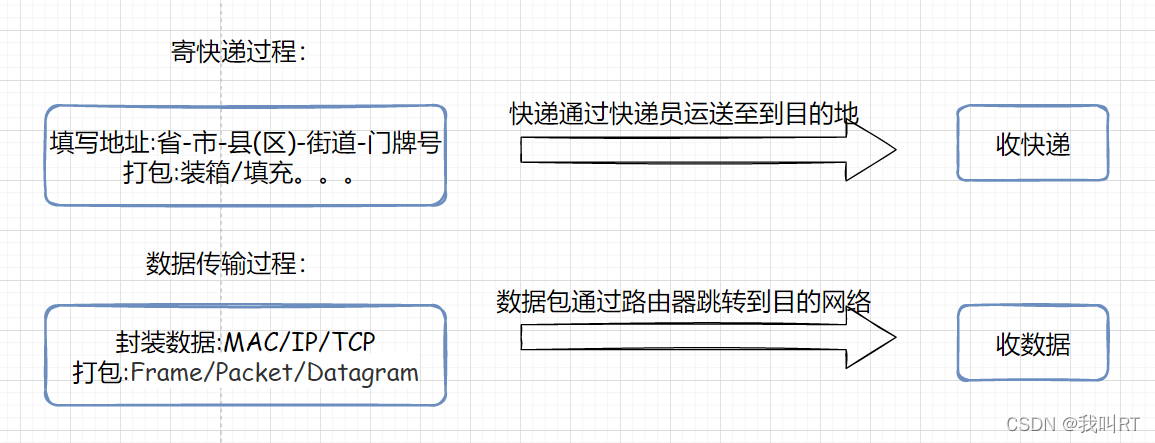
ip地址等价于快递包裹上的收件人地址。
快递员通过收件人地址将包裹在出发地到目的地之间连出一条线,然后通过不同地区之间的物流中转最后将包裹送到收件人的手中。
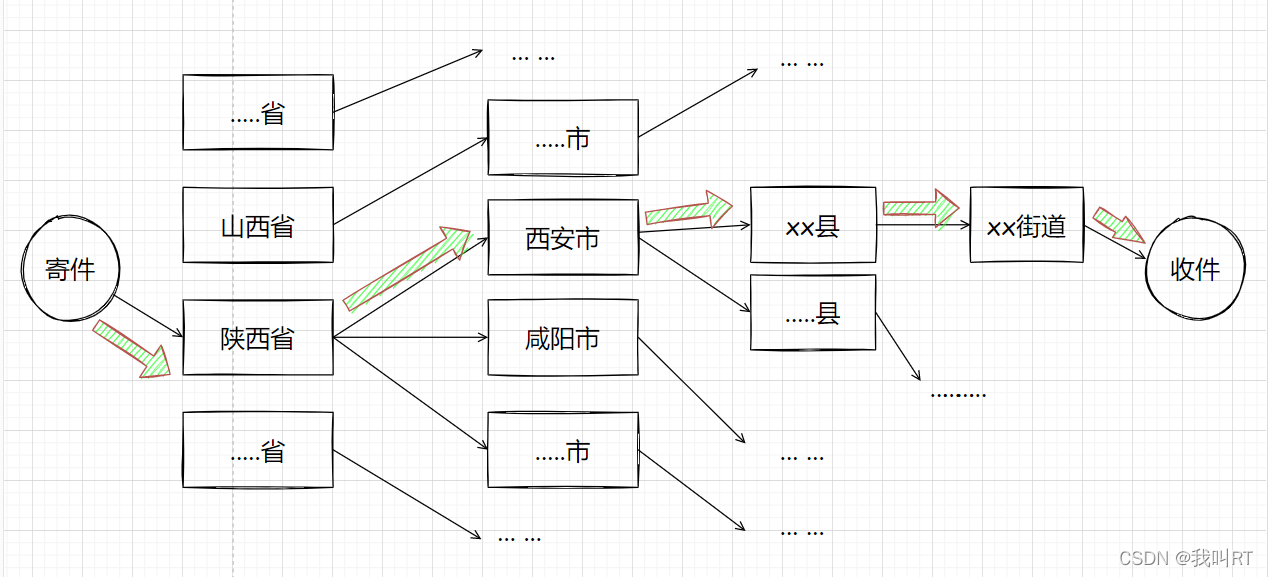
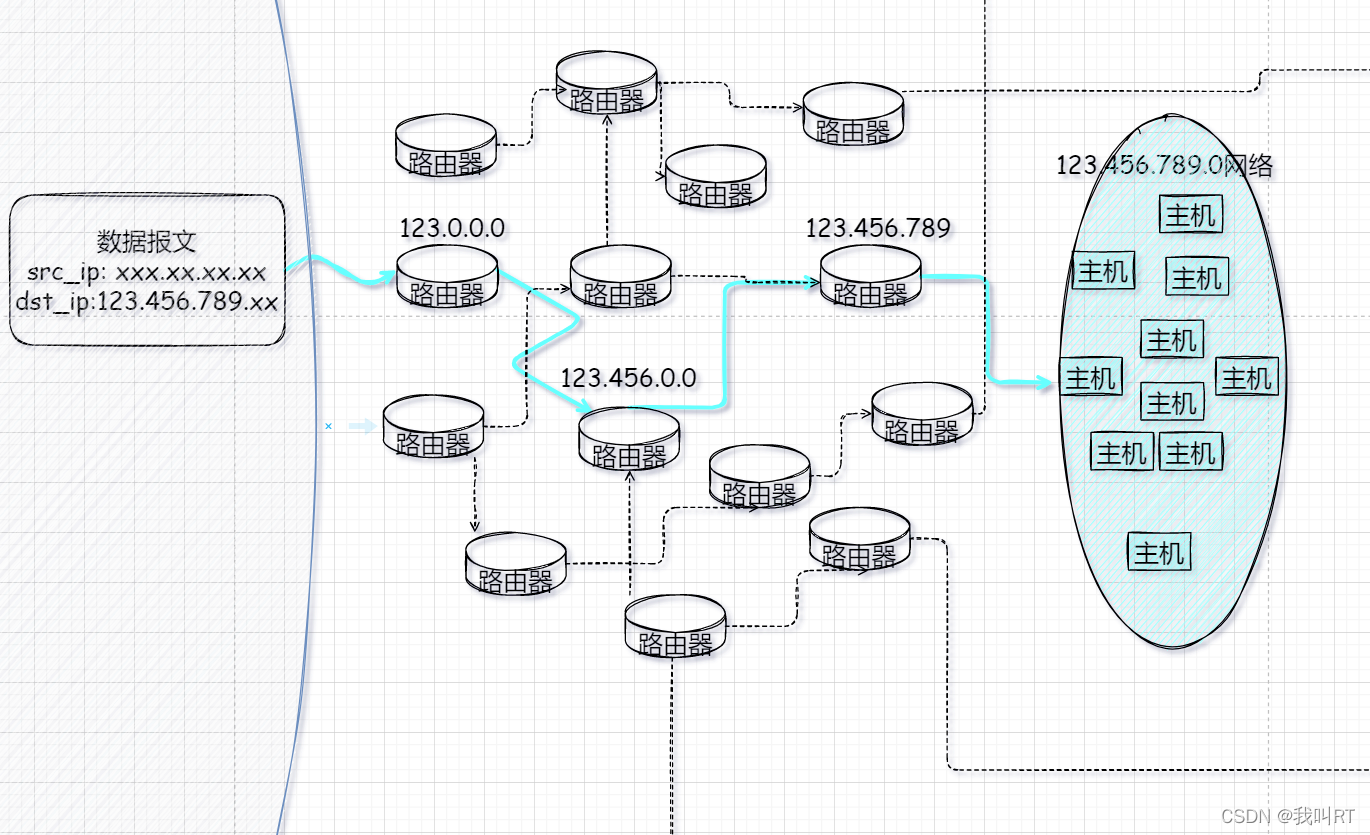
从上图的粗箭头所描述的路径便可达到目的地址,陕西省-西安市-xx县-xx街道-…。
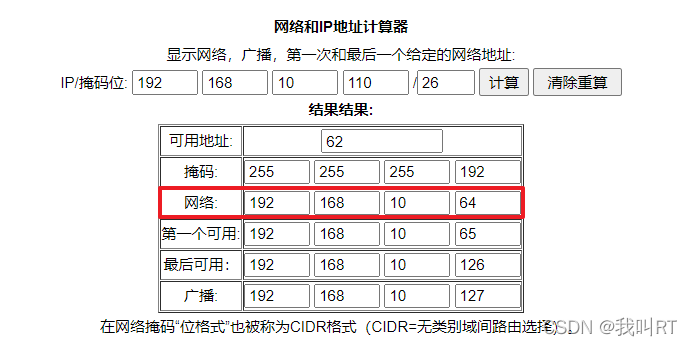
同理,ip地址也具备此功能,通过IP地址的网络位可以确定某个主机所在网络的位置,从而明确一条数据传送的路径。例如目的地址为192.168.10.110/26,则该地址所在的网络为192.168.10.64
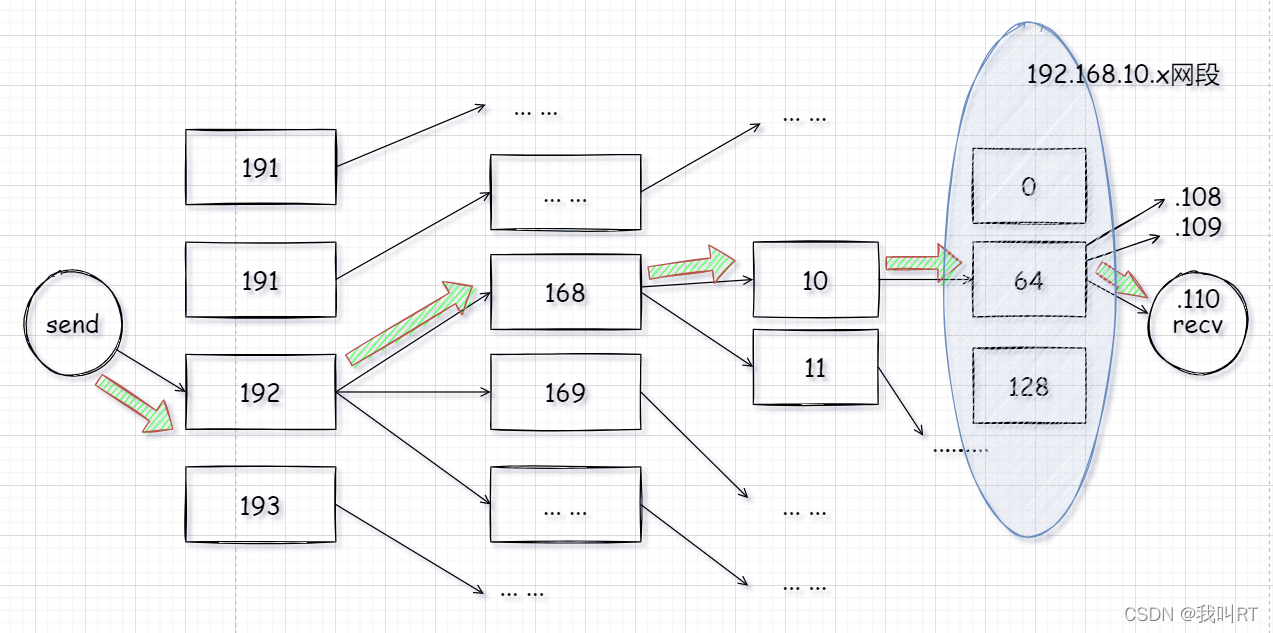
用之前图示地址的寻址方式,我们可以模拟这一过程
那么,还是那个问题,为什么还要MAC地址呢?
MAC地址等价于快递包裹上的收件人姓名。
MAC地址更多是用于确认对方信息而存在的。就如同快递跨越几个城市来到你面前,快递员需要和你确认以下收件人是否正确,才会把包裹交给你一样。

这里我们模拟一个场景,比如在学校里同一个班级的学生大家互相都认识,互相交流就不需要借助学号(这里抽象成ip地址),直接喊名字即可。“喂,那个谁,把你作业让我抄一下”。
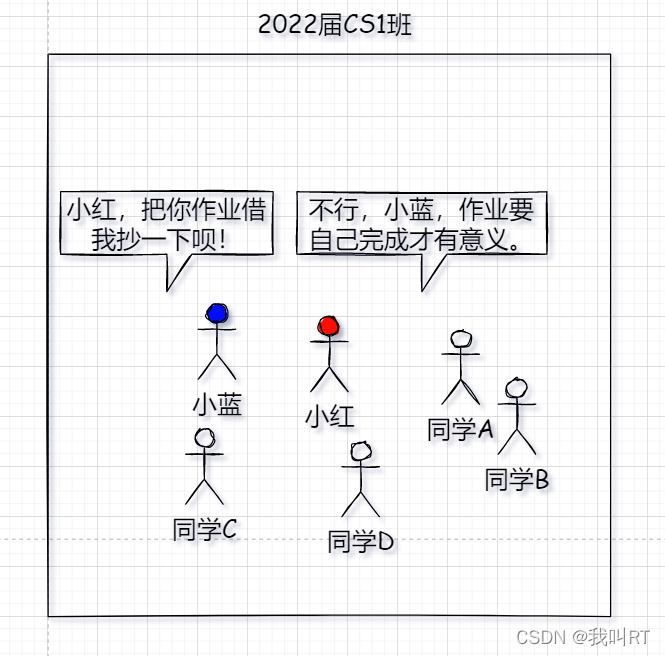
这个过程可对应网络中同一个交换机或集线器连接的局域网通信。在局域网中通信需要通过MAC地址进行通信。将数据封装成帧时会插入源mac地址和目的mac地址(如果不知到对方mac地址会发送arp广播报文获取对方mac地址)。以太网帧结构:
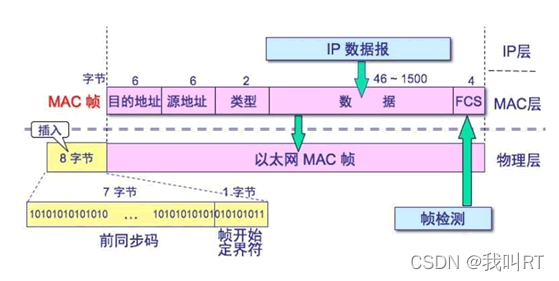
(———图来自网络,侵删)
而后,帧结构再次添加IP头部信息。
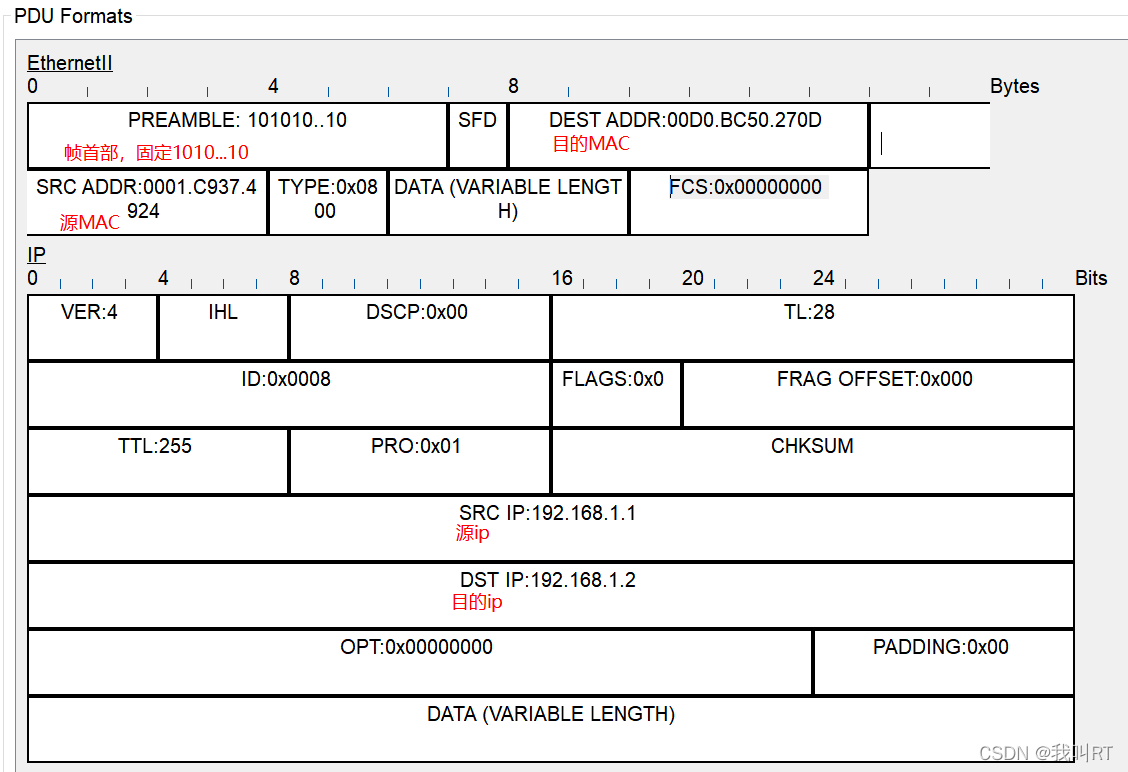
虽然这里有ip地址,但是它在局域网中不起作用,因为arp是用于网络中寻址的,而在局域网中所有主机互相可见。(除此之外,局域网中ip地址最多是在arp广播时,作为收到包的主机解包时判定的依据,判定自己是否为目的主机,从而选择是否回应arp应答)。

而IP地址的使用条件,是在跨网络之后。两个网络之间想要进行通信需要通过一个媒介,因为在网络内部的主机定位不到网络外的某个主机,即使他们只隔了一个网段也是一样。而跨网段的媒介就是路由器,只要把ip地址告诉它,他就能找到对方所在的网络。
这就像是我是2020届计算机科学专业1班学生xx(学号202015162,15代指专业计算机科学专业,62代指“我”在本班的学号),我现在想找2022届学弟yy(学号2022…)。我们之间不认识,但是我可以找一个中间人,帮我送信。
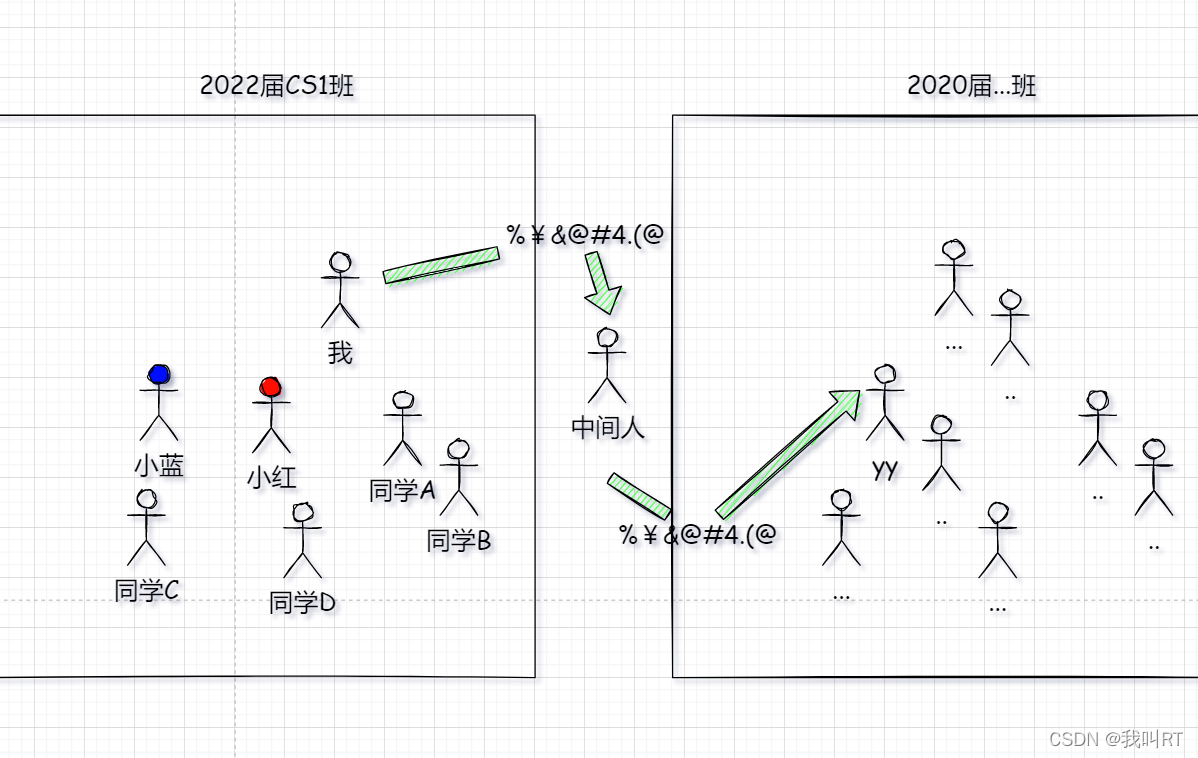
这个中间人是局域网网关,是路由器。他们的功能是,转述我的消息,并且按照目的ip地址将它发给下一个“中间人”,最后送到“yy”手中。
以下内容有借鉴到文章:闪客sun(低并发编程):如果让你来设计网络
首先我们需要明确的是,MAC地址的诞生早于IP地址。在计算机设计之初,设备之间使用MAC地址互相确认身份,因为当时的网络拓扑并不大,我们完全可以让两台计算机之间两两互相发送数据。如果有5个主机需要互通的话,那么它的拓扑结构可能是这样:
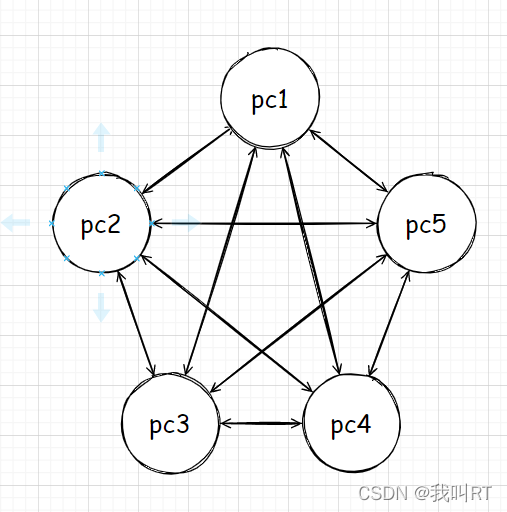
如果是这样的话,我们其实无需MAC地址,因为每个网卡明确对应一台主机。而实际是,一台计算机要配置这么多网卡的需要耗费更多的money,你也不想买一台计算机后还需要额外再买十几个网卡把。
因此我们可以采用集线器的方式将所有计算机通过网线聚集在一起会更加方便。
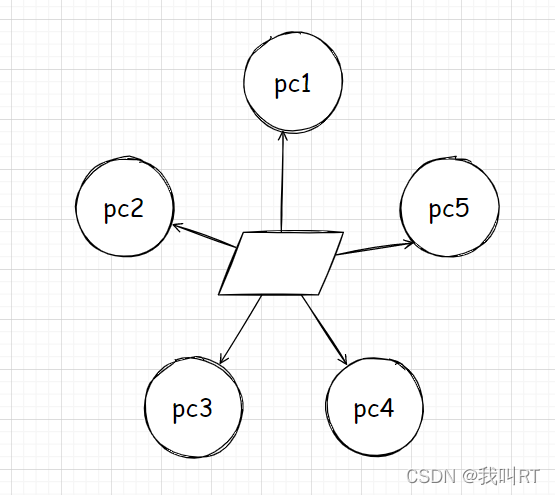
每台主机发送数据前需要携带自己和对方的目的MAC地址,因为hub集线器只是将所有数据从其他接口发送出去,它将数据的是否接收留给了主机自己判断。
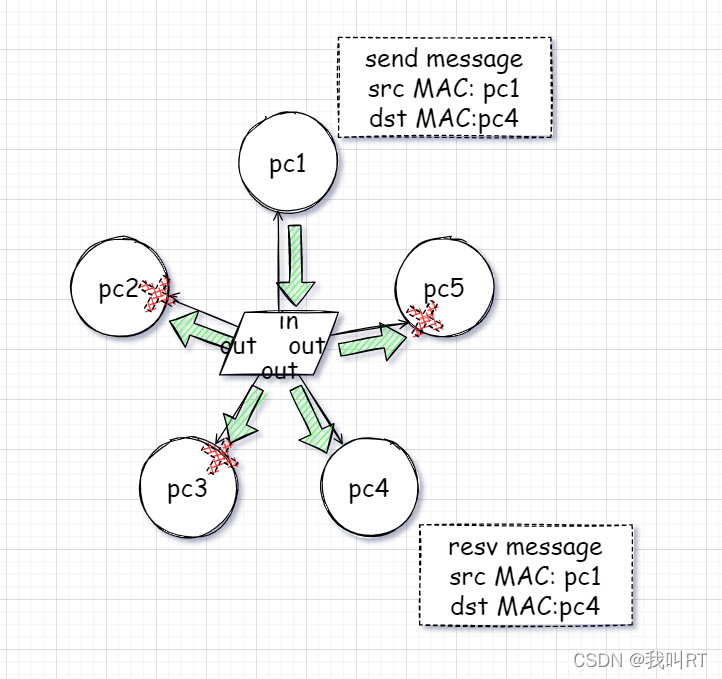
集线器只是无脑的做数据发送,因此我们认为它是数据链路层的设备。
集线器太笨了,它将每一通信都发给所有主机,在各主机之间交流频繁时会造成网络的拥堵乃至瘫痪,因此我们进行了升级,使用交换机设备。
交换机内部维护一张 MAC 地址表,记录MAC地址与交换机各端口之间的关系,这样就无需将所有数据发送的局域网中。通过思科的Cisco packet tracer仿真软件可以看到交换机的MAC地址表。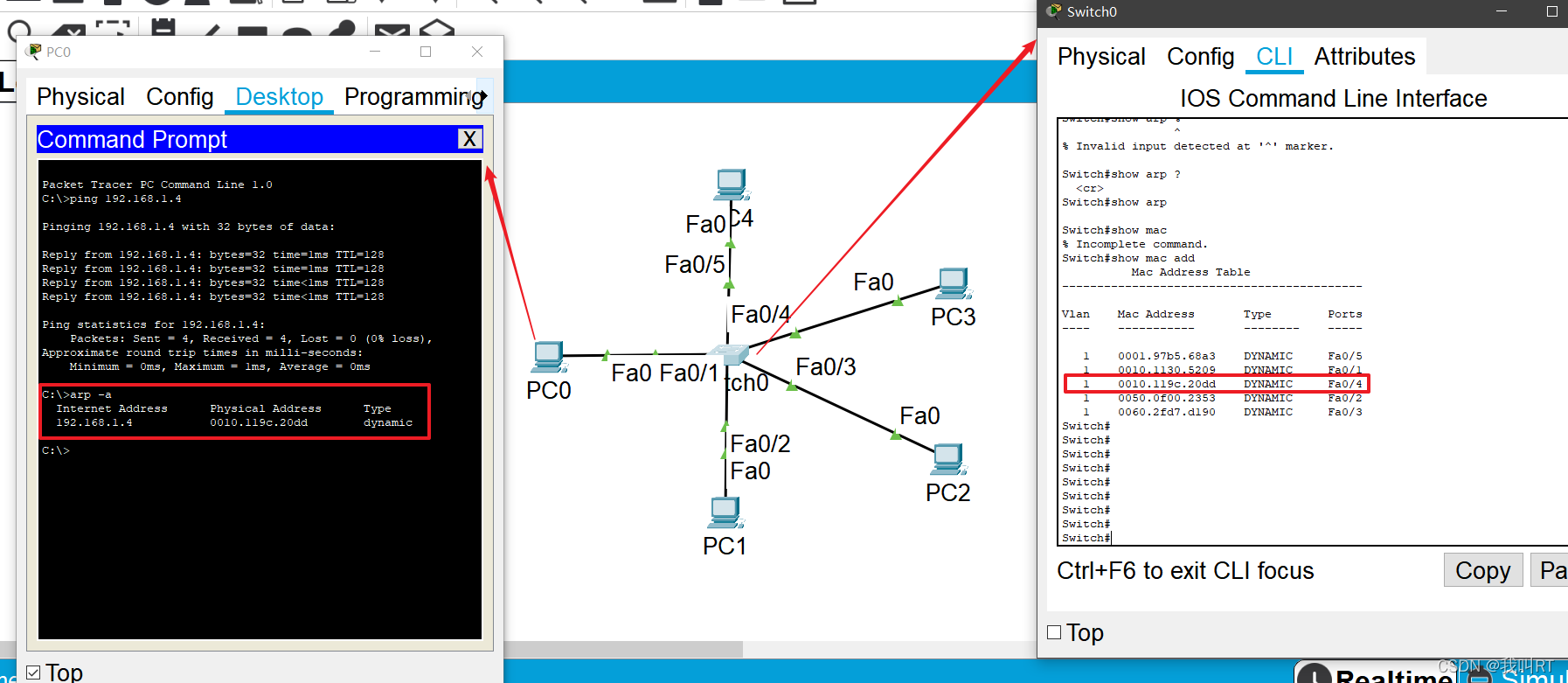
这样,当pc0(192.168.1)ping pc3(192.168.4)时,交换机查自己的mac表,发现自己的以太网fa0/4接口的出口对应的就是目的主机mac地址,则交换机将自己该数据报文转发从fa0/4接口转发出去。同时pc3收到了来自pc0的数据报文。
交换机相对集线器,拥有决定数据从交换机的哪个端口转发出去的功能,因此我们认为交换机在数据链路层(决定数据转发至哪一条链路上)。
以上集线器和交换机都是局域网的通行,无需IP地址参与。而随着网络的扩大,局域网规则已经不再适合了。
许多个类似上述的局域网组成一个大的互联网。它们彼此相连互相通信。
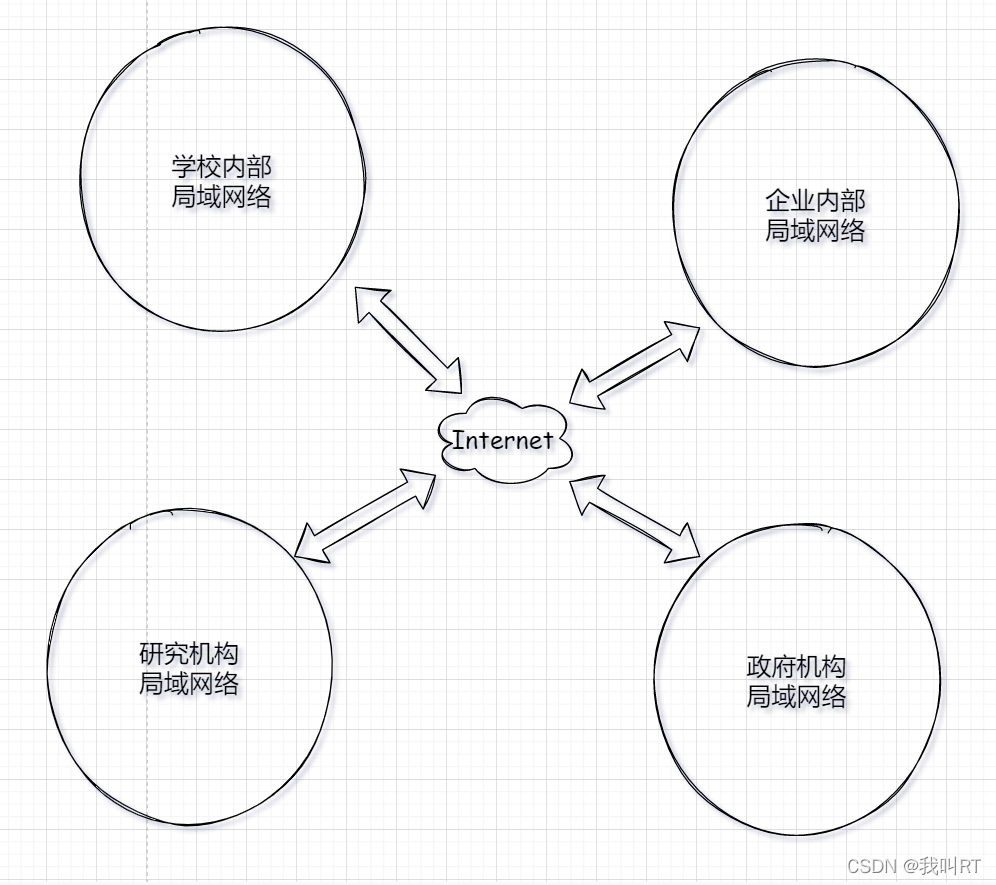
如果在学校网络内部向访问某个研究机构共享的资料,这就是跨网络访问了。此时IP地址才派上用场。ip地址给出一段段具备层级关系的数字地址,它就像思维导图一样可以通过给定地址高效的找出我们想要的那一项。
当有网络连接上互联网时,给它分配一个ip地址,这样就能通过这些ip地址确定对方网络(或设备)在互联网络中的位置,从而进行访问。
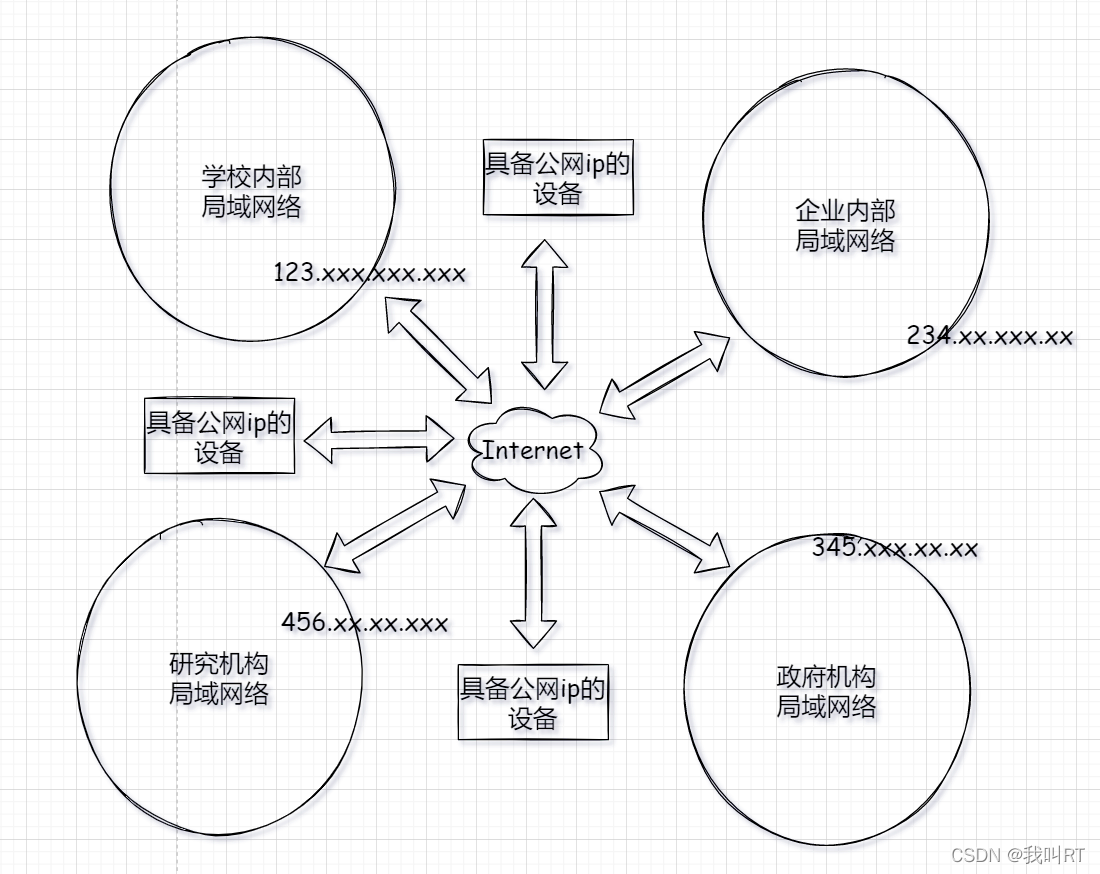
连接在互联网上的具有ip的可以是一个单个的设备,比如某个服务器、某个网络摄像头等,也可以是某个局域网,如学校的校园网,公司内部网络等(局域网与公网通信使用NAT、PAT等方式,或内网穿透等技术)。
为了实现在网络中,跨网段的访问,因此诞生出新的设备叫路由器。它可以根据内置的路由条目决定将数据包转发到哪个网络中,最终可以到达目的网络。
需要注意的是,路由器是多个网络的中间人,它有很多端口分别处于不同的网络中(路由器的每一个端口,都有独立的 MAC 地址和IP地址),这样它就可以把“来自A网络的信息转发至B网络,因为路由器的接口同时连接这这几个网络”。
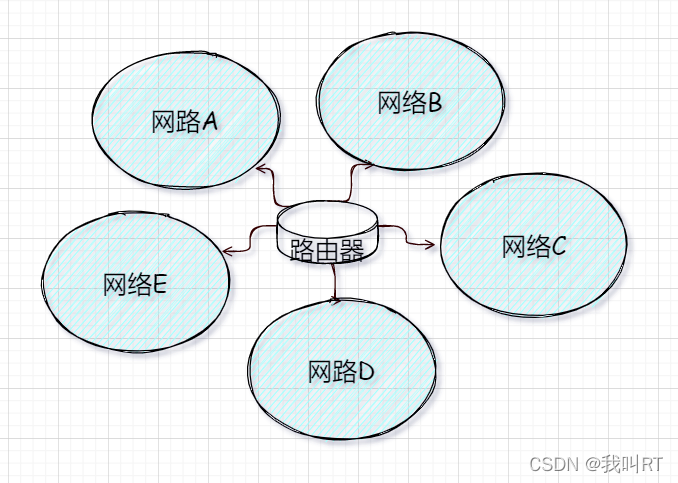
路由器可以让数据在网络中跨网络的通信,因此我们认为路由器是网络层的设备。
终于,我们理清楚了整个IP与MAC的关系。总结一下:
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or