作者 | 营火
微服务能力大提升,更新增 Job、PHP 等场景,延展 Serverless 新边界
企业的数字化随着互联网的普及发展越来越快,技术架构也是几经更迭。尤其是在线业务部分,从最初的单体应用到分布式应用再到云原生应用,出现了进阶式的变化。但带来便利的同时,也给企业带来了一定的复杂度:新技术上手门槛高,容器和微服务就是两个典型的拦路虎。即便微服务化和容器化后,企业依然需要关注服务器配置和运维、容量评估,还要面临高性能和稳定性的挑战,无法享受云带来的最大价值。
Serverless 应用引擎 SAE 凭借着天然技术优势,已经帮助成千上万家企业实现容器和微服务技术转型。近日,SAE不仅进一步提供了全套微服务能力,更为传统 Job 和 PHP 用户提供了全新的,更高效、更经济且可平滑迁移的解决方案。
直播发布会回顾:
关注 Severless 公众号后台回复 511 即可获得阿里云 SAE 发布会直播 PPT!
Serverless 应用引擎 SAE 是一款全托管、免运维、高弹性 的通用 PaaS 平台。支持开源微服务 / 开源定时任务框架 / Web 应用的全托管,提供开源增强 & 企业级特性。可以说 SAE 覆盖了应用上云的完整场景,是应用上云的最佳选择。
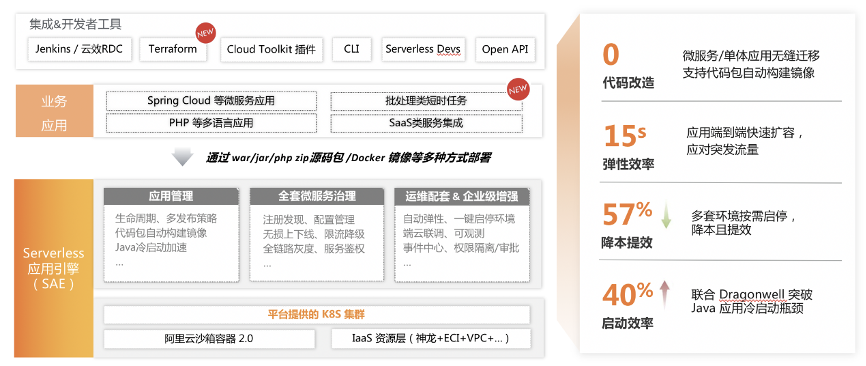
SAE Job 作为 SAE 一种新的运完即停的负载类型,聚焦任务场景。根据业务数据处理需求,能够在短时间内快速创建大量计算任务,任务完成后快速释放计算资源。具备单机、广播、并行计算、分片运行的特性、定时、失败自动重试、监控报警特性,提供了全托管免运维的用户体验。
区别于传统任务框架,SAE Job 使用起来更方便(对代码无侵入)、更节省(任务运行完立即释放资源)、更稳定(和在线业务独立、且任务失败能自动重试)、更透明(可视化监控报警)、更省心(无需关注底层资源)。更重要的是 SAE Job 能深度融合微服务生态,兼容开源 K8s。
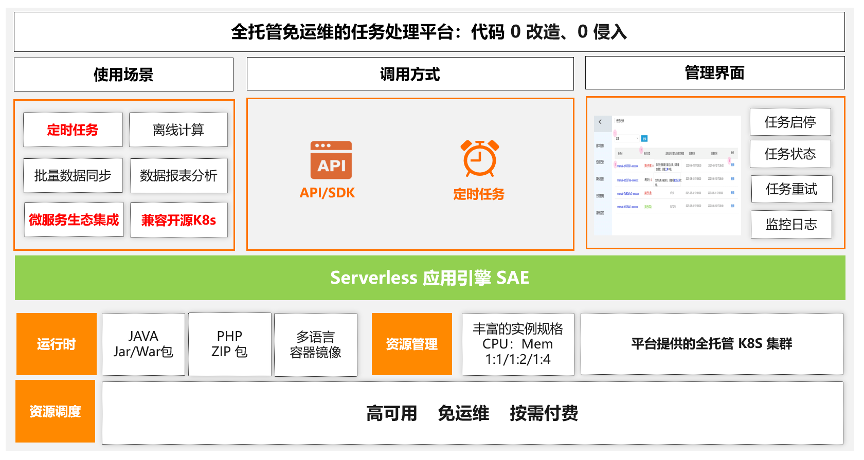
SAE Job 主打场景包括定时任务、数据批处理、异步执行、离线计算等,同时支持传统框架 XXL Job 零改造迁移,微服务生态集成,借助构建镜像能力完善 CI/CD 流程。
相较于传统分布式任务框架,SAE Job 提供三大核心价值:
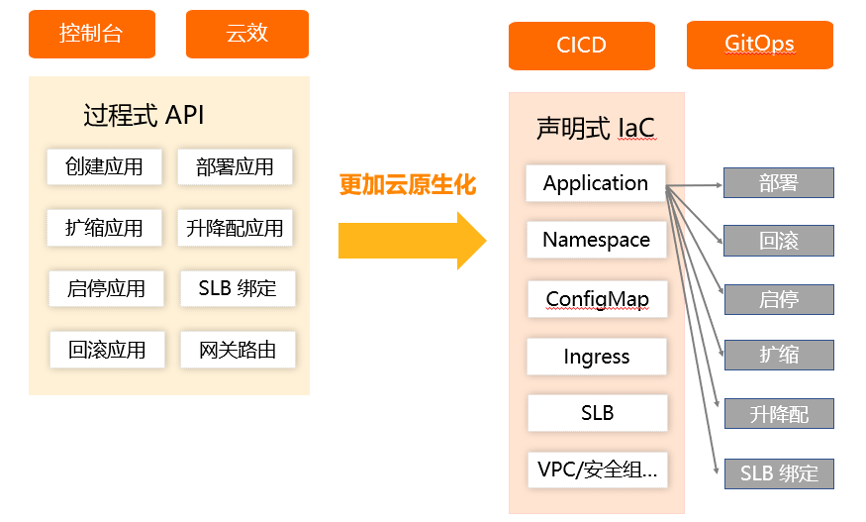
作为国内外大客户首选的云上工具,Terraform 的价值在于基础设施即代码,能够自动配置基础设施,帮助企业更高速、更低风险、更低成本实现云应用程序的开发、部署与扩展。极大提高自动化运维效率。SAE 接入Terraform 之后,开发人员无需理解每个 API,提供声明式 IaC,操作SAE的资源更加安全,对接 CICD / GitOps 也更加简单。更重要的是提供了资源编排能力,能够一键式的部署 SAE 以及依赖的云资源,从 0 到 1 建站效率大幅提升。目前多个互联网客户已经在生产环境中使用。
提到 PHP 运维,大家熟知的是各种商业版的服务器运维面板。但这些面板只支持单机运维、缺少应用侧监控和秒级自动弹性能力,不支持静态文件增量更新,对体量稍大一点的 PHP 应用并不友好。
针对以上痛点,SAE 提供了一个免运维、高弹性、无缝集成 APM 监控的 PHP 应用全托管服务。在框架上,支持 laravel,ThinkPHP,Swoole,wordpress 等流行框架。在运行环境方面,支持在线应用架构 LNMP,默认提供 PHP-FPM + Nginx。支持 Docker 镜像和 PHP zip 包部署,大大降低了用户使用门槛。
PHP 应用托管的功能矩阵相当丰富,有开发调试类的上传下载、内置 Xdebug 等,也有运行时类的弹性伸缩,APM 能力,还能通过 NAS 和 OSS 独立管理静态文件和目录。基于这些能力,非常好的支撑了 PHP 的几个典型使用场景:如静态站点部署,远程调试,多站点部署,存量 ECS/服务器运维面板的应用迁移等。
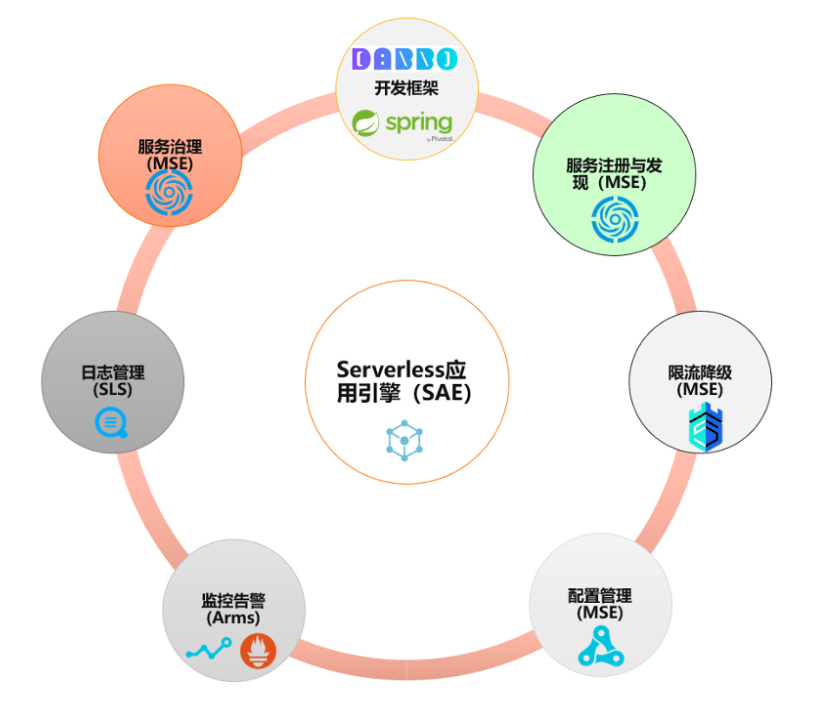
Serverless 微服务 = CI/CD 流水线 + 微服务框架(含注册中心和微服务治理框架)+ Kubernetes/ 容器 + 云运维(含调用链、日志、告警、性能监控等) + 弹性伸缩服务 + 流量治理服务。
Serverless 应用引擎 SAE 深度集成微服务引擎 MSE,将阿里深耕十余年历经双 11 考验的微服务最佳实践产品化,开箱即用。在开源 Spring Cloud/Dubbo 的基础上,提供了更强大的微服务治理能力。
白屏化的 PaaS:降低用户的使用门槛,它的交互符合大多数开发者心中 PaaS 的预期,另外也有 CLI、插件、OpenAPI 等等丰富的被集成能力。这个 PaaS 其实是一个底座,支持微服务应用的生命周期管理,灰度,容器化转型等,如果没有这么一个底座,那可能用户会面对大量的黑屏操作的命令或者 API,上手极其复杂;另外作为一个面向企业级的产品,SAE 也提供了很多企业级特性,比如命名空间隔离,细粒度的权限控制等等
前后端全链路灰度:这个在企业生产过程中是最常见的一类需求,指的是通过指定 cookie、header 甚至公司的内部 ip,灰度到新版实例,SAE打通了 HTTP 请求,网关、consumer、provider,在 Agent 上根据规则进行相关的路由,让用户只需要经过一些白屏化的配置就实现全链路灰度。
端云联调:结合 Cloud Tookit 插件实现的端云联调,微服务架构下应用数量会比单体多很多,那么本地的开发调试就很成问题,借助 Cloud Tookit 提供的 IDEA 以及 Eclipse 等主流 IDE 的插件,开发者可以做到本地只需要启动一个 consumer 或者 provider 就可以和云上的测试环境进行联调,极大的降低微服务在开发阶段的门槛;
可观测能力:微服务架构下,应用数量较多,定位问题困难,可观测能力是必不可少的,SAE 结合阿里云的 ARMS、云监控、SLS、Prometheus 等产品,在 Metrics、Tracing、Logging 等方面都提供了相对完整的解决方案,切实解决开发者在可观测方面的痛点,包括基础监控、调用链、实时日志、事件等等
更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2