目录
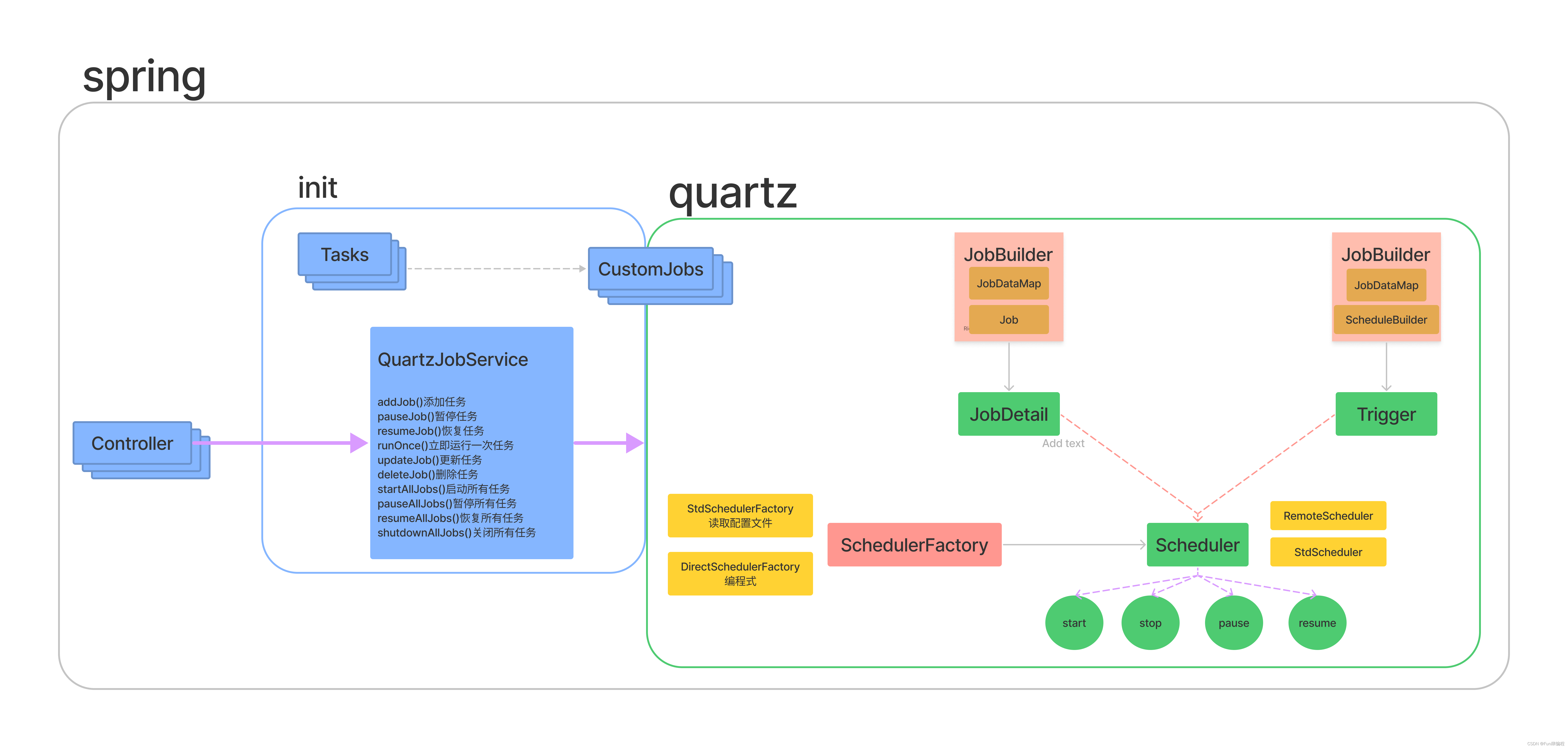
我们的各个服务需要改造支持集群,现在的授权、日程使用的是基于内存的spring scheduler定时任务,如果部署多个节点,那么到了时间点,多个节点都会开始执行定时任务从而可能引起业务和性能上的问题。
服务中的定时任务比较轻量,为了避免引入redis、zookeeper、单独的定时任务程序,所以建议选用quartz这种基于数据库的分布式定时任务调度框架,无需引用多余中间件。
原则上是尽量与quartz的耦合降至最低,针对我们的业务场景并不需要太多的调度操作(即图上的controller),只需要程序启动的时候初始化好指定的定时任务就行了,所以先这样搞,如果有更好的设计欢迎一起交流。
下载之后解压,进入src\org\quartz\impl\jdbcjobstore找到22种数据库11张表的初始化sql文件,我们使用的数据库主要为pg系,所以需要使用tables_postgres.sql(达梦为Oracle系,需要使用tables_oracle.sql)
11张表的功能说明:
| 表名 | 功能 |
|---|---|
| qrtz_job_details | 存储每一个已配置的 Job 的详细信息 |
| qrtz_triggers | 存储已配置的 Trigger 的信息 |
| qrtz_simple_triggers | 存储简单的 Trigger,包括重复次数,间隔,以及已触的次数 |
| qrtz_cron_triggers | 存储 Cron Trigger,包括 Cron 表达式和时区信息 |
| qrtz_simprop_triggers | 存储简单的 Trigger,包括重复次数,间隔,以及已触的次数 |
| qrtz_blob_triggers | Trigger 作为 Blob 类型存储(用于 Quartz 用户用 JDBC 创建他们自己定制的 Trigger 类型,JobStore 并不知道如何存储实例的时候) |
| qrtz_calendars | 以 Blob 类型存储 Quartz 的 Calendar 信息 |
| qrtz_paused_trigger_grps | 存储已暂停的 Trigger 组的信息 |
| qrtz_fired_triggers | 存储与已触发的 Trigger 相关的状态信息,以及相联 Job 的执行信息 |
| qrtz_scheduler_state | 存储少量的有关 Scheduler 的状态信息,和别的 Scheduler 实例(假如是用于一个集群中) |
| qrtz_locks | 存储程序的悲观锁的信息(假如使用了悲观锁) |
引入依赖
<!--quartz依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
springboot集成quartz核心配置类
– 初始化quartz:QuartzConfigure.java
@Configuration
public class QuartzConfigure {
/**
* quartz配置文件路径
*/
private static final String QUARTZ_CONFIG = "/quartz.properties";
/**
* JobFactory与schedulerFactoryBean中的JobFactory相互依赖,注意bean的名称
* 在这里为JobFactory注入了Spring上下文
*
* @param applicationContext
* @return
*/
@Bean
public JobFactory customJobFactory(ApplicationContext applicationContext) {
QuartzJobFactory jobFactory = new QuartzJobFactory();
jobFactory.setApplicationContext(applicationContext);
return jobFactory;
}
@Bean
public SchedulerFactoryBean schedulerFactoryBean(JobFactory customJobFactory, DataSource dataSource) throws IOException {
// 创建SchedulerFactoryBean
SchedulerFactoryBean factory = new SchedulerFactoryBean();
factory.setQuartzProperties(quartzProperties());
// 支持在JOB实例中注入其他的业务对象
factory.setJobFactory(customJobFactory);
factory.setApplicationContextSchedulerContextKey("applicationContextKey");
// 这样当spring关闭时,会等待所有已经启动的quartz job结束后spring才能完全shutdown。
factory.setWaitForJobsToCompleteOnShutdown(true);
// 是否覆盖己存在的Job
factory.setOverwriteExistingJobs(false);
// QuartzScheduler 延时启动,应用启动完后 QuartzScheduler 再启动
factory.setStartupDelay(10);
// 注入spring维护的DataSource
factory.setDataSource(dataSource);
return factory;
}
/**
* 从quartz.properties文件中读取Quartz配置属性
*
* @return
* @throws IOException
*/
@Bean
public Properties quartzProperties() throws IOException {
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource(QUARTZ_CONFIG));
propertiesFactoryBean.afterPropertiesSet();
return propertiesFactoryBean.getObject();
}
/**
* 通过SchedulerFactoryBean获取Scheduler的实例
*
* @return
* @throws IOException
*/
@Bean(name = "scheduler")
public Scheduler scheduler(JobFactory customJobFactory, DataSource dataSource) throws IOException {
return schedulerFactoryBean(customJobFactory, dataSource).getScheduler();
}
}
– 注入SpringBean:QuartzJobFactory.java
/**
* 为JobFactory注入SpringBean,否则Job无法使用Spring创建的bean
*
* @author Ric
*/
@Component
public class QuartzJobFactory extends AdaptableJobFactory implements ApplicationContextAware {
@Autowired
private AutowireCapableBeanFactory capableBeanFactory;
@Override
@NonNull
protected Object createJobInstance(@NonNull TriggerFiredBundle bundle) throws Exception {
// 调用父类的方法
Object jobInstance = super.createJobInstance(bundle);
// 进行注入
capableBeanFactory.autowireBean(jobInstance);
return jobInstance;
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
capableBeanFactory = applicationContext.getAutowireCapableBeanFactory();
}
}
– 具体的定时任务:CustomJob.java
/**
* @DisallowConcurrentExecution : 此标记用在实现Job的类上面,意思是不允许并发执行.
* 注org.quartz.threadPool.threadCount的数量有多个的情况,@DisallowConcurrentExecution才生效
*/
@DisallowConcurrentExecution
public class CustomJob implements Job{
private static final Logger logger = LoggerFactory.getLogger(CustomJob.class);
/**
* 核心方法,Quartz Job真正的执行逻辑.
* @param context 中封装有Quartz运行所需要的所有信息
* @throws JobExecutionException execute()方法只允许抛出JobExecutionException异常
*/
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
logger.info("--------------定时任务执行逻辑---------------------");
}
}
– 定义操作任务的统一接口:QuartzJobService.java
public interface QuartzJobService {
/**
* 添加任务可以传参数
*
* @param clazzName 继承自Job的类,例如:work.lichong.quartzdemo.solution.one.job.CustomJob
* @param jobName 任务名称
* @param groupName 任务组
* @param cronExp cron表达式
* @param param JobDataMap的参数
*/
void addJob(String clazzName, String jobName, String groupName, String cronExp, Map<String, Object> param);
/**
* 暂停任务
*
* @param jobName 任务名称
* @param groupName 任务组
*/
void pauseJob(String jobName, String groupName);
/**
* 恢复任务
*
* @param jobName 任务名称
* @param groupName 任务组
*/
void resumeJob(String jobName, String groupName);
/**
* 立即运行一次定时任务
*
* @param jobName 任务名称
* @param groupName 任务组
*/
void runOnce(String jobName, String groupName);
/**
* 更新任务
*
* @param jobName 任务名称
* @param groupName 任务组
* @param cronExp cron表达式
* @param param JobDataMap的参数
*/
void updateJob(String jobName, String groupName, String cronExp, Map<String, Object> param);
/**
* 删除任务
*
* @param jobName 任务名称
* @param groupName 任务组
*/
void deleteJob(String jobName, String groupName);
/**
* 启动所有任务
*/
void startAllJobs();
/**
* 暂停所有任务
*/
void pauseAllJobs();
/**
* 恢复所有任务
*/
void resumeAllJobs();
/**
* 关闭所有任务
*/
void shutdownAllJobs();
}
– 具体实现:QuartzJobServiceImpl.java
@Service
@Slf4j
public class QuartzJobServiceImpl implements QuartzJobService {
@Autowired
private Scheduler scheduler;
@Override
public void addJob(String clazzName, String jobName, String groupName, String cronExp, Map<String, Object> param) {
try {
// 启动调度器,默认初始化的时候已经启动
// scheduler.start();
// 构建job信息
Class<? extends Job> jobClass = (Class<? extends Job>) Class.forName(clazzName);
JobDetail jobDetail = JobBuilder.newJob(jobClass).withIdentity(jobName, groupName).build();
// 表达式调度构建器(即任务执行的时间)
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule(cronExp);
// 按新的cronExpression表达式构建一个新的trigger
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity(jobName, groupName).withSchedule(scheduleBuilder).build();
// 获得JobDataMap,写入数据
if (param != null) {
trigger.getJobDataMap().putAll(param);
}
scheduler.scheduleJob(jobDetail, trigger);
} catch (ObjectAlreadyExistsException e) {
log.warn("{}组下的{}任务已存在,创建失败", groupName, jobName);
} catch (Exception e) {
log.error("创建任务失败", e);
}
}
@Override
public void pauseJob(String jobName, String groupName) {
try {
scheduler.pauseJob(JobKey.jobKey(jobName, groupName));
} catch (SchedulerException e) {
log.error("暂停任务失败", e);
}
}
@Override
public void resumeJob(String jobName, String groupName) {
try {
scheduler.resumeJob(JobKey.jobKey(jobName, groupName));
} catch (SchedulerException e) {
log.error("恢复任务失败", e);
}
}
@Override
public void runOnce(String jobName, String groupName) {
try {
scheduler.triggerJob(JobKey.jobKey(jobName, groupName));
} catch (SchedulerException e) {
log.error("立即运行一次定时任务失败", e);
}
}
@Override
public void updateJob(String jobName, String groupName, String cronExp, Map<String, Object> param) {
try {
TriggerKey triggerKey = TriggerKey.triggerKey(jobName, groupName);
CronTrigger trigger = (CronTrigger) scheduler.getTrigger(triggerKey);
if (cronExp != null) {
// 表达式调度构建器
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule(cronExp);
// 按新的cronExpression表达式重新构建trigger
trigger = trigger.getTriggerBuilder().withIdentity(triggerKey).withSchedule(scheduleBuilder).build();
}
// 修改map
if (param != null) {
trigger.getJobDataMap().putAll(param);
}
// 按新的trigger重新设置job执行
scheduler.rescheduleJob(triggerKey, trigger);
} catch (Exception e) {
log.error("更新任务失败", e);
}
}
@Override
public void deleteJob(String jobName, String groupName) {
try {
// 暂停、移除、删除
scheduler.pauseTrigger(TriggerKey.triggerKey(jobName, groupName));
scheduler.unscheduleJob(TriggerKey.triggerKey(jobName, groupName));
scheduler.deleteJob(JobKey.jobKey(jobName, groupName));
} catch (Exception e) {
log.error("删除任务失败", e);
}
}
@Override
public void startAllJobs() {
try {
scheduler.start();
} catch (Exception e) {
log.error("开启所有的任务失败", e);
}
}
@Override
public void pauseAllJobs() {
try {
scheduler.pauseAll();
} catch (Exception e) {
log.error("暂停所有任务失败", e);
}
}
@Override
public void resumeAllJobs() {
try {
scheduler.resumeAll();
} catch (Exception e) {
log.error("恢复所有任务失败", e);
}
}
@Override
public void shutdownAllJobs() {
try {
if (!scheduler.isShutdown()) {
// 需谨慎操作关闭scheduler容器
// scheduler生命周期结束,无法再 start() 启动scheduler
scheduler.shutdown(true);
}
} catch (Exception e) {
log.error("关闭所有的任务失败", e);
}
}
}
– quartz的配置文件
#===================================================================
# 配置JobStore
#===================================================================
# 数据保存方式为数据库持久化
org.quartz.jobStore.class=org.springframework.scheduling.quartz.LocalDataSourceJobStore
# 数据库代理类,一般org.quartz.impl.jdbcjobstore.StdJDBCDelegate可以满足大部分数据库,建议pg系使用PostgreSQLDelegate,oracle系使用OracleDelegate
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.PostgreSQLDelegate
# 表的前缀,默认QRTZ_
org.quartz.jobStore.tablePrefix=QRTZ_
# 是否加入集群
org.quartz.jobStore.isClustered=true
# 信息保存时间 默认值60秒 单位:ms
org.quartz.jobStore.misfireThreshold=25000
# 调度实例失效的检查时间间隔 ms
org.quartz.jobStore.clusterCheckinInterval = 5000
# JobDataMaps是否都为String类型,默认false
org.quartz.jobStore.useProperties=false
# 当设置为“true”时,此属性告诉Quartz 在非托管JDBC连接上调用setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED)。
org.quartz.jobStore.txIsolationLevelReadCommitted = true
#===================================================================
# Scheduler 调度器属性配置
#===================================================================
# 调度标识名 集群中每一个实例都必须使用相同的名称
org.quartz.scheduler.instanceName=DefaultTapClusterScheduler
# ID设置为自动获取 每一个必须不同
org.quartz.scheduler.instanceId=AUTO
# 是否开启守护线程
org.quartz.scheduler.makeSchedulerThreadDaemon=true
#===================================================================
# 配置ThreadPool
#===================================================================
# 线程池的实现类(一般使用SimpleThreadPool即可满足需求)
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
# 指定在线程池里面创建的线程是否是守护线程
org.quartz.threadPool.makeThreadsDaemons=true
# 指定线程数,至少为1(无默认值),一般设置为1-100直接的整数,根据系统资源配置
org.quartz.threadPool.threadCount=5
# 设置线程的优先级(最大为java.lang.Thread.MAX_PRIORITY 10,最小为Thread.MIN_PRIORITY 1,默认为5)
org.quartz.threadPool.threadPriority=5
在CustomJob等Job中写自己的定时任务业务逻辑,可以把这部分业务代码再抽象出来就和quartz解耦了
配置太麻烦,有一点学习成本,还有一种无脑的ShedLock方案可以研究一下
文章中的源码链接:https://github.com/lichong-a/quartzClusterDemo
文章已收录至https://lichong.work,转载请注明原文链接。
ps:欢迎关注公众号“Fun肆编程”或添加我的私人微信交流经验🤝
【前端-开发环境】使用NVM实现不同nodejs版本的自由切换(NVM完整安装使用手册)
【前端-NPM私服】内网使用verdaccio搭建私有npm服务器
【前端-IE兼容】Win10和Win11使用Edge调试前端兼容IE6、IE7、IE8、IE9、IE10、IE11问题
【工具-Shell脚本】java程序产品包模板-linux和windows通用shell启动停止脚本(无需系统安装Java运行环境)
【工具-Nginx】从入门安装到高可用集群搭建
【工具-Nginx】Nginx高性能通用配置文件-注释版-支持防刷限流、可控高并发、HTTP2、防XSS、Gzip、OCSP Stapling、负载、SSL
【工具-WireShark】网络HTTP抓包使用教程
【后端-maven打包】通过profile标签解决同时打jar包 war包需求
【后端-SpringCache】基于Spring Cache封装一个能够批量操作的Redis缓存记录下踩坑历程(pipeline或mget封装)
【后端-SkyWalking】SkyWalking前后端开发环境搭建详细教程步骤-6.x/7.x/8.x版本通用-插件二次开发利器(一)
✨欢迎为耿直少年点赞、关注、收藏!!!
👇👇👇
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我在我的项目中有一个用户和一个管理员角色。我使用Devise创建了身份验证。在我的管理员角色中,我没有任何确认。在我的用户模型中,我有以下内容:devise:database_authenticatable,:confirmable,:recoverable,:rememberable,:trackable,:validatable,:timeoutable,:registerable#Setupaccessible(orprotected)attributesforyourmodelattr_accessible:email,:username,:prename,:surname,:
我正在尝试创建密码规则来设计可恢复的密码更改。我通过passwords_controller.rb做了一个父类(superclass),但我需要在应用规则之前检查用户角色,但我所拥有的只是reset_password_token。 最佳答案 假设您的模型是用户:User.with_reset_password_token(your_token_here)Source 关于ruby-on-rails-设计通过reset_password_token获取用户,我们在StackOverflow
我已经使用Apartment设置了一个Rails5应用程序(1.2.0)和Devise(4.2.0)。由于某些DDNS问题,应用只能在app.myapp.com下访问(请注意子域app)。myapp.com重定向到app.myapp.com。我的用例是每个注册该应用的用户(租户)都应该通过他们的子域(例如tenant.myapp.com)访问他们的特定数据。用户不应限定在其子域内。基本上应该可以从任何子域登录。重定向到租户的正确子域由ApplicationController处理。根据Devise标准,登录页面位于app.myapp.com/users/sign_in。这就是问题开始的
我在关注RyanbatesRailsCast的devise和omniauth(第235集-devise-and-omniauth-revised)。当我尝试使用Twitter登录时,标题中不断出现错误。defself.new_with_session(params,session)ifsession["devise.user_attributes"]new(session["devise.user_attributes"],without_protection:true)do|user|user.attributes=paramsuser.valid?end完整跟踪:C:/Ruby20
我为Devise用户和管理员提供了不同的模型。我也在使用Basecamp风格的子域。除了我需要能够以用户或管理员身份进行身份验证的一些Controller和操作外,一切都运行良好。目前我有authenticate_user!在我的application_controller.rb中设置,对于那些只有管理员才能访问的Controller和操作,我使用skip_before_filter跳过它。不幸的是,我不能简单地指定每个Controller的身份验证要求,因为我仍然需要一些Controller和操作才能被用户或管理员访问。我尝试了一些方法都无济于事。看来,如果我移动authentica
我在我的Rails应用程序中使用设计。我在租户庄园中配置了它,其中帐户/session的范围限定为子域。例如:http://subdomain1.example.com/http://subdomain2.example.com/...这很好用,但我想为“super管理员”添加一个子域,允许这些用户导航到所有其他子域而无需重新验证。这将是这样的:http://admin.example.com/是否可以自定义仅在管理子域上生成的cookie,以便它在所有其他子域上都有效? 最佳答案 Cookie域的定义越不具体,它们的包容性就越大,