一个接口可以理解为一个业务逻辑,一个业务逻辑可以由1~n个SQL组成。一个优质的接口,应该是通用的接口,一旦需求变了,给过来的参数有变化,那我尽量做到接口不变,你多给我一个参数或者某个参数变化一下,我就可以给出你要的结果。
后端提供给前端的接口,要尽量少。最好我给你一个接口,你可以用这一个接口做很多事,拿很多数据。这样对前端开发人员比较友好。后端开发人员对自己也要好一点,自己的mapper也要尽量通用,service层封装方法,几个service给出的方法,最好都是一个mapper或者几个mapper的组合。
写接口的时候,要考虑到接口的服役期,不要写一个简单的接口,临时使用。
举个例子,企业账户充值的页面,除了充值的功能外,原型上还有一个简单的充值记录查询功能,只是查找当前企业的充值记录。如果你的接口里面,没有将企业ID作为搜索条件传入,那么恭喜你,你可以准备好修改了。因为虽然短时期内,前端可以调你这个接口取得数据,但是今后原型上增加了【充值记录查询】这个功能,用户可以输入企业ID作为搜索条件,你就要改接口了。你要改成一个复杂一些的接口,在充值页面中使用,也在充值记录查询这个页面中使用,前端人员还得修改充值页面中调用的接口。这是典型的先甜后苦的情况。
为了前端和后端可以并行开发,后端开发人员应该先在RAP中定义接口并告知前端,前端开发人员就可以根据接口URL和参数,绑定到页面的触发函数中。
并行开发带来效率的提升的,但是难点是要预先筹划好接口,并且在后来的开发过程中尽量保证不变,特别是数组之类的数据结构不要修改,否则前端遍历处理的修改将会很麻烦。
要做到这样,就需要一些后端接口开发的经验,而且提前计划总是比较困难的,就像敏捷开发中的 Sprint Planning 总是比较难完成。但是坚持这么做,对自己的能力也是一种激励和提升,因此推荐这么做。
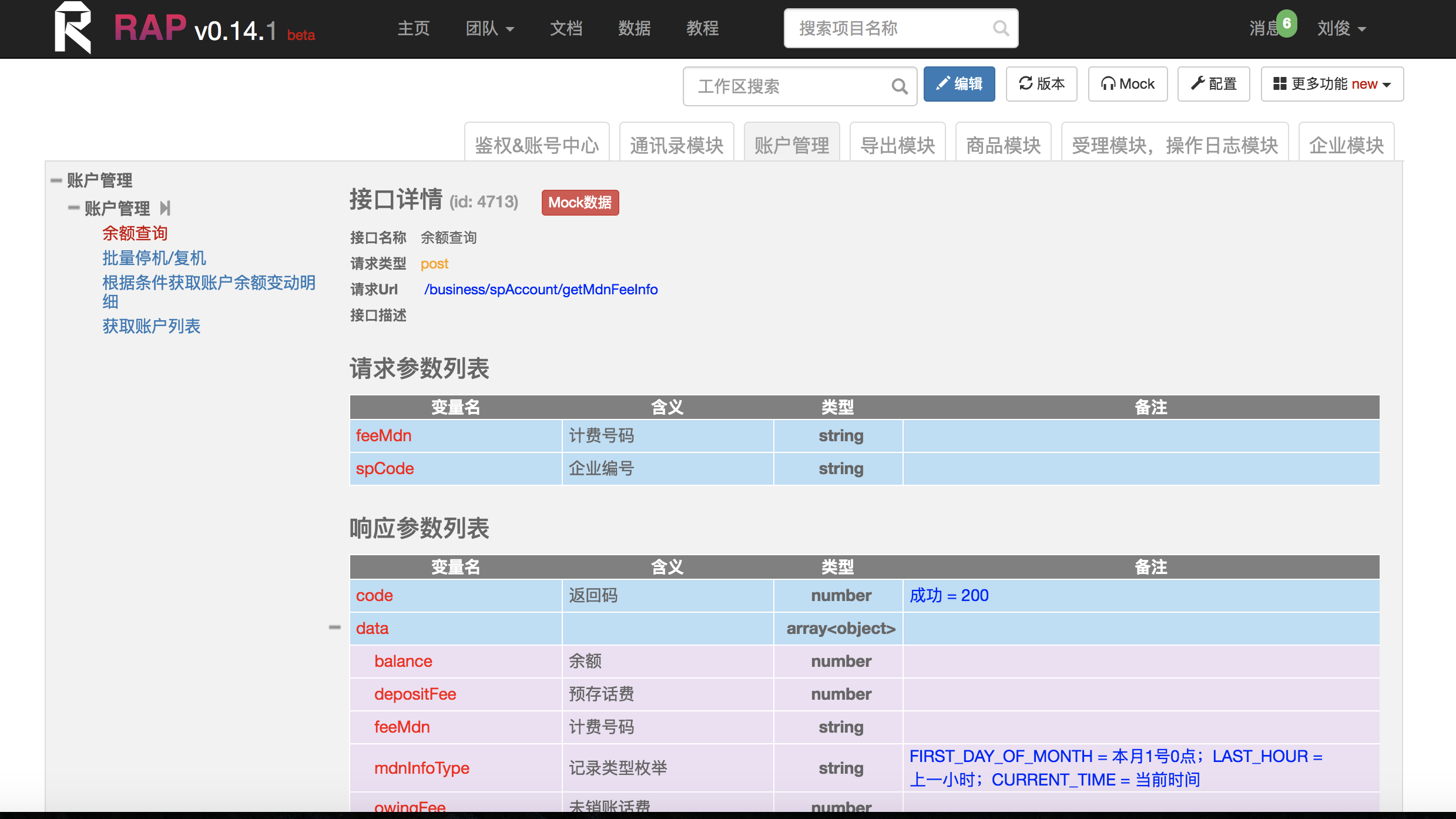
返回给前端的数据,需要有Response类/ResponsePages类封装,也就是要带有返回码,返回消息和返回体。如果要求给出分页信息,那么ResponsePages类中,还需要有Page类,其中至少包括当前页数,每页显示条数和总条数信息。分页使用github的pagehelper工具类来完成。
返回码不可以使用http状态码,因为http状态码是有限的,而且提示信息很模糊,不足以定义丰富的业务错误,因此要定义自己的业务返回码。同样,也要成对定义业务返回消息,用于描述业务错误。业务分配的错误编码表,需要由研发部门统筹给出。如果是服务之间调用的,应当透传返回码和返回消息。
http返回对象:
{
code: code,
msg: msg,
pageInfo: { // 分页信息
curPage: 1,
pageLimit: 10,
page: 1,
total: 10
}
data: {data}
}服务和服务之间调用,通过RPC接口,一般分为【api模块】和【provider模块】。服务的治理采用微服务框架。服务有服务名称,服务组别和服务的版本号。 RPC的框架,2017年使用的是阿里的HSF框架,也就是Pandora容器。2018年10月开始,逐步转成帜讯RPC框架这是一种封装了Dubbo的RPC框架。目前正在进行架构改造。 微服务的架构下,服务部署在不同的服务器中,它们所对应的数据库也是不同的。有的时候,数据需要联查才可以组装,这就要考虑网络通信的代价。一般的做法,一次性从他处拿到数据,组装成map或者mapList,然后再与本地的数据做匹配。注意map或者mapList要尽量小。
HSF框架,服务的提供者具有@HSFProvider注解,服务的消费者具有@HSFConsumer注解,两者都会注册到【EDAS Config Center】注册中心,该注册中心负责服务的注册与发现,以及配置中心。每个服务都有Group,DataId和Version。如果在同一网段有两个Group、DataId和Version都相同的服务同时启动,那么注册中心就会进行随机调度。
帜讯RPC框架是封装了Dubbo的RPC框架,支持服务治理的框架参数化传入,可以是dubbo,也可以是市场上的任何一种RPC框架。目前默认是Dubbo。 具体来说,服务的提供者使用【@FlaginfoProvider】注解,服务的消费者使用【@FlaginfoConsumer】注解,服务组,服务名和版本号暂时不需要传入。注意,如果要标记提供者,不可以同时使用【@FlaginfoProvider】和【@Service】标签,否则会出现寻找实例化bean超过一个的错误。
我们来看一下RPC服务的代码结构,分为【api】和【provider】,简单来说,【api】中定义了暴露给其他服务的接口,【provider】中的内容是接口的实现。团队协作开发的时候,当你提交新的接口,而接口jar包版本又不升级的时候,需要记得把接口实现的代码一并提交。如果接口实现负责,一时间无法完成,那么可以先提交一个空的实现。如果你不这么做,那么当团队其他成员尝试发布RPC服务的时候,就会报【接口没有实现】的编译错误,影响发布。
RAP一定要好好使用。在写接口之前,最好先定义好RAP,包括URL,入参和返回,这样前端开发人员就可以根据RAP去写前端页面,而同时后端人员可以实现这个接口。后端开发过程中,注意RAP上定义好的内容尽量不要变更。

此份文档详细记录了千道面试题与详解;
!
私信我回复【03】即可免费获取
很多人感叹“学习无用”,实际上之所以产生无用论,
是因为自己想要的与自己所学的匹配不上,这也就意味着自己学得远远不够。无论是学习还是工作,
都应该有主动性,所以如果拥有大厂梦,那么就要自己努力去实现它。
以上学习资料均免费放送,最后祝愿各位顺利拿到心仪的offer
关于枚举类,推荐使用Enum类来处理,好处是一次定义,多处使用,缺点是代码量增加,而且前端后端转换过程中要注意处理空值的情况。
一般,前端发起一个POST请求,传过来的参数是JSON格式的,后端使用Spring的【@RequestBody】注解将其转换成Java类,一般是一个VO。后端使用service处理以后,返回的是【@ResponseBody】类型的数据,这样前端拿到后自动会解析成JSON格式的数据。 以上是最基本的数据类型和标签使用,还有例如【@RestController】【@PostMapping】等,可以参看【Spring RESTful接口常用注解】。
后端和前端的交互,一般都是要从数据库中取出数据,然后在前端页面渲染。因此,后端写接口,很重要的一点,就是去数据库中取数据。帜讯使用的ORM框架是轻量级的MyBatis,DTO,mapper interface和xml文件,通过 MyBatis Generator自动生成。
下面来说说 MyBatis 的 xml文件。该文件可以接收VO,这样就可以直接接收前端传过来的参数。xml文件返回的一般是DTO,一般是DTO的List,注意调interface后要用一个List来组装。xml文件的核心是SQL语句,用于从数据库中取出数据。如果没有把握,可以将SQL语句在Navicat中执行一遍,看看输出的结果。
我的认知中,简单地把【RESTFul接口/调用方式】理解为前端可以调用的,后端也可以通过httpClient的方式向其他服务的URL发送请求,获取数据;【RPC接口/调用方式】是服务之间的相互调用,前端无法直接使用。 前者通过Controller暴露出接口,前端访问URL,同时带上参数,如此来使用后端的服务;后者分api和provider,api暴露出接口,消费者引用提供者的api来调用。

小伙伴们有兴趣想了解内容和更多相关学习资料的请点赞收藏+评论转发+关注我,后面会有很多干货。如果在阅读过程中有疑问,请留言讨论
作者: gkmeteor
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub