大家好,我是三友,我又来了~~
最近仍然畅游在RocketMQ的源码中,这几天刚好翻到了消费者的源码,发现RocketMQ的对于push消费方式的实现简直太聪明了,所以趁着我脑子里还有点印象的时候,赶紧来写一篇文章,来掰扯一下,防止过两天就忘得一干二净了。
消费方式就是指消费者如何从MQ中获取到消息,分为两种方式,push(推方式)和pull(拉方式)。
push,顾名思义,就是推的意思。就是当MQ收到生产者产生的消息的时候,会主动将消息推送到消费者进行消费,这种模式就叫push,也就是MQ将消息推给到消费者的意思。
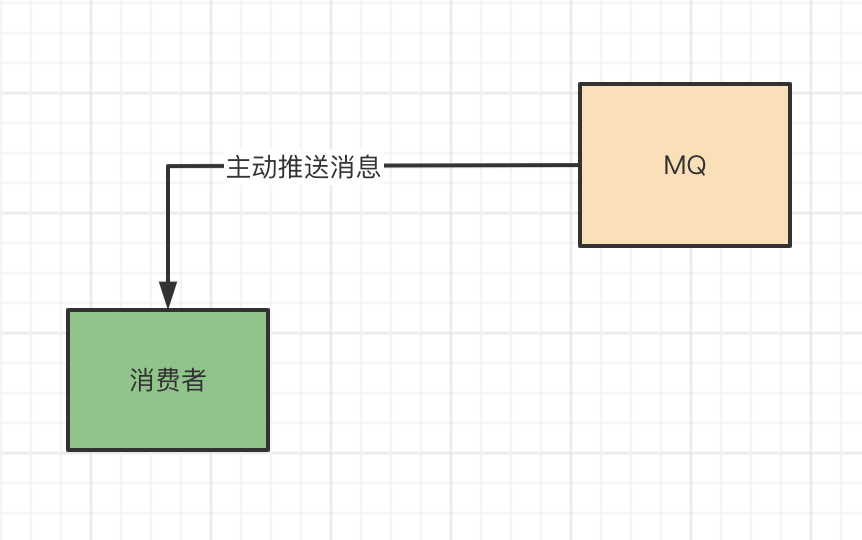 push模式
push模式
push这种模式的好处就是响应快,消息的实时性比较高,一旦消息MQ收到消息,那么就能立马将消息推送给消费者,消费者也就能立马收到消息进行消费。
但是这种push的模式,有个缺点就是一旦消息量比较大时,对消费者性能要求比较高,因为是消费者无法控制MQ消息的推送速度,一旦消息量大,那么消费者消费消息的压力就比较大。
push是MQ主动给消费者推消息,那么pull呢?刚好跟push相反,就是消费者主动去MQ中拉取消息。
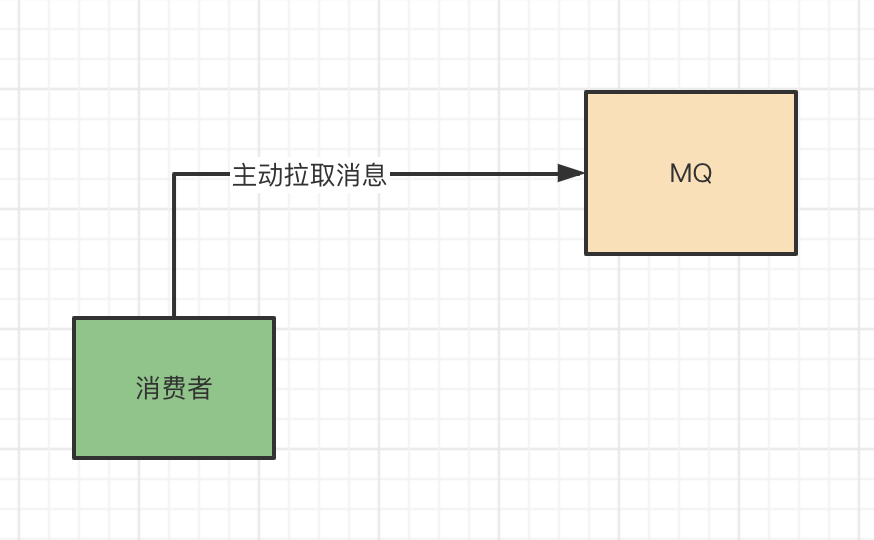 pull模式
pull模式
那么pull的优缺点自然也就跟push刚好相反。因为是消费者主动去MQ中拉取消息,那么消费者可根据自身消费的情况,决定何时去拉取消息,主动权在自己手上,这样消费者的压力就会相对小点;但是缺点也很明显,那么就会实时性相对于push方式会低一些,因为你得决定拉的时间间隔。
其实想想,消费方式就跟拿快递一样,快递就是一个消息,我自己就是消费者,快递要么快递小哥主动送(push)到家,要么我自己去快递站拿(pull)。
上一节说了消费消息的两种方式push和pull,或者说算一种理念。尚大的周阳老师有一句经常说的话我比较赞同,那就是“天上飞的理念,必然有落地的实现”。所以push或者pull到底如何落地,得看具体的MQ的产品了。
而RocketMQ作为阿里开源的一款高性能、功能丰富的MQ,自然同时实现了push和pull的两种消费方式,用户可以选择在项目中使用push还是pull。
 push模式的实现
push模式的实现 pull模式的实现
pull模式的实现
但是一般情况下,项目中都是使用push的方式来消费,因为pull除了时实性差外,pull方式还得让开发人员主动去维护消息消费进度,增加额外的操作。
所以接下来就着重讲一下RocketMQ是如何实现push的逻辑。
上文说到push模式的优点是时实性好,但是缺点就是消费者压力会比较大,所以,难道实现push模式,只能舍弃压力的控制么?
就在这时,RocketMQ大喊了一声

是的,RocketMQ对于push模式做到了实时和压力的平衡,这主要是因为RocketMQ的push模式其实算是一个“伪push”模式,真正底层的实现还是基于pull。
到这里可能有的小伙伴比较迷糊,怎么push变成“伪push”了,还是用pull实现的,到底是push还是pull?

前面我说过,push和pull只是一种理论,具体的实现看MQ。
所以RocketMQ为了兼顾两者,就选择通过消费者主动拉消息来实现push的效果,这也是为什么我称为“伪push”的原因,RocketMQ都给封装好了,让你用起来感觉是MQ主动push消息给你的。
既然底层是pull,那么RokcetMQ在实现消费者的逻辑的时候,就可以很容易实现控制压力的效果,毕竟这是“拉”方式天然自带的buff;但是如何通过pull实现push的时实的优点呢?毕竟鱼和熊掌我RokcetMQ偏要兼得。
这时这就不得不提到一种叫“长轮询”的机制。
轮询与长轮询都属于pull的实现,都是由客户端主动给服务端发送请求,拉取数据。套到MQ中,就是都是消费者主动去MQ拉消息。
轮询是指不管服务端数据有无更新,客户端每隔定长时间请求拉取一次数据,可能有更新数据返回,也可能什么都没有。

再拿快递举例子,轮询就好比,小明买的iphone 13 pro max快递到了,显示正在派送中,但是小明等不及了,于是就去快递站拿,但是快递还没放到快递站,但是小明的心里急啊,他忍受不了相思之苦,于是小明每隔5分钟就往快递站跑一次,问一下快递到了没,到了就拿回来。这就是轮询的意思,也就是不论有没有数据,客户端都会每隔一定时间去请求一次服务端。
来分析一下拿快递的例子的问题:
从而对应到程序中,就是会产生如下问题
说长轮询概念之前,先来救救小明吧,毕竟小明可不想狗带。
既然原先小明每隔5分钟跑一次,那么是不是可以换种思路,当快递还没到的时候,让小明不要回来,直接在快递站待着,当快递到的时候,才让小明拿着快递回家。这下小明就喜死了,既可以有时间刷刷某音,逛逛某东,还可以在第一时间拿到13 pro max。

所以这种可以在快递站等待的机制,就叫长轮询。
长轮询也是客户端请求服务端,如果服务端有数据,那么就立马返回,客户端再次请求;当服务端不存在数据的时候,服务端并不会给客户端响应,而是将请求给hold住,当服务端有数据的时候才会给客户端响应,返回数据。
所以长轮询可以解决如下问题
但是长轮询也会带来服务端代码实现逻辑复杂的问题,当然相比于优点来说,都不太重要。
理论都讲完了,接下来就到了show me the code的时间了,来看看RocketMQ的是如何通过长轮询机制来实现压力和时实的平衡。
这里我画了一张push模式下消费者消费流程图。
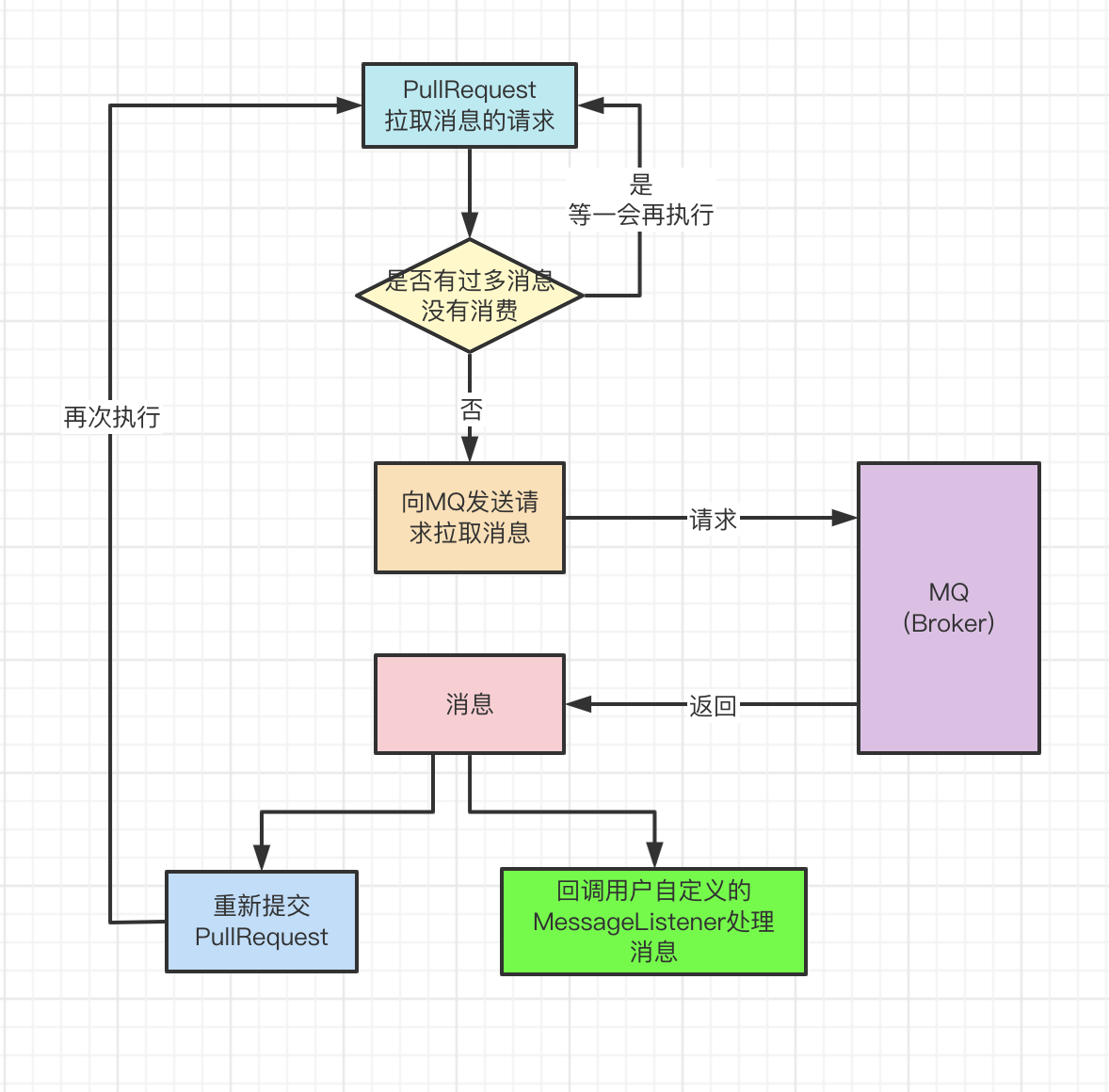 消费者拉取消息的逻辑
消费者拉取消息的逻辑
当消费者准备去拉消息的时候,会先去判断当前消费者消费的压力再决定是否去拉取消息。
RocketMQ提供了两种判断消费压力逻辑,一种是基于还未消费的消息的数量的大小,还有一种是基于还未消费的消息所占内存的大小。
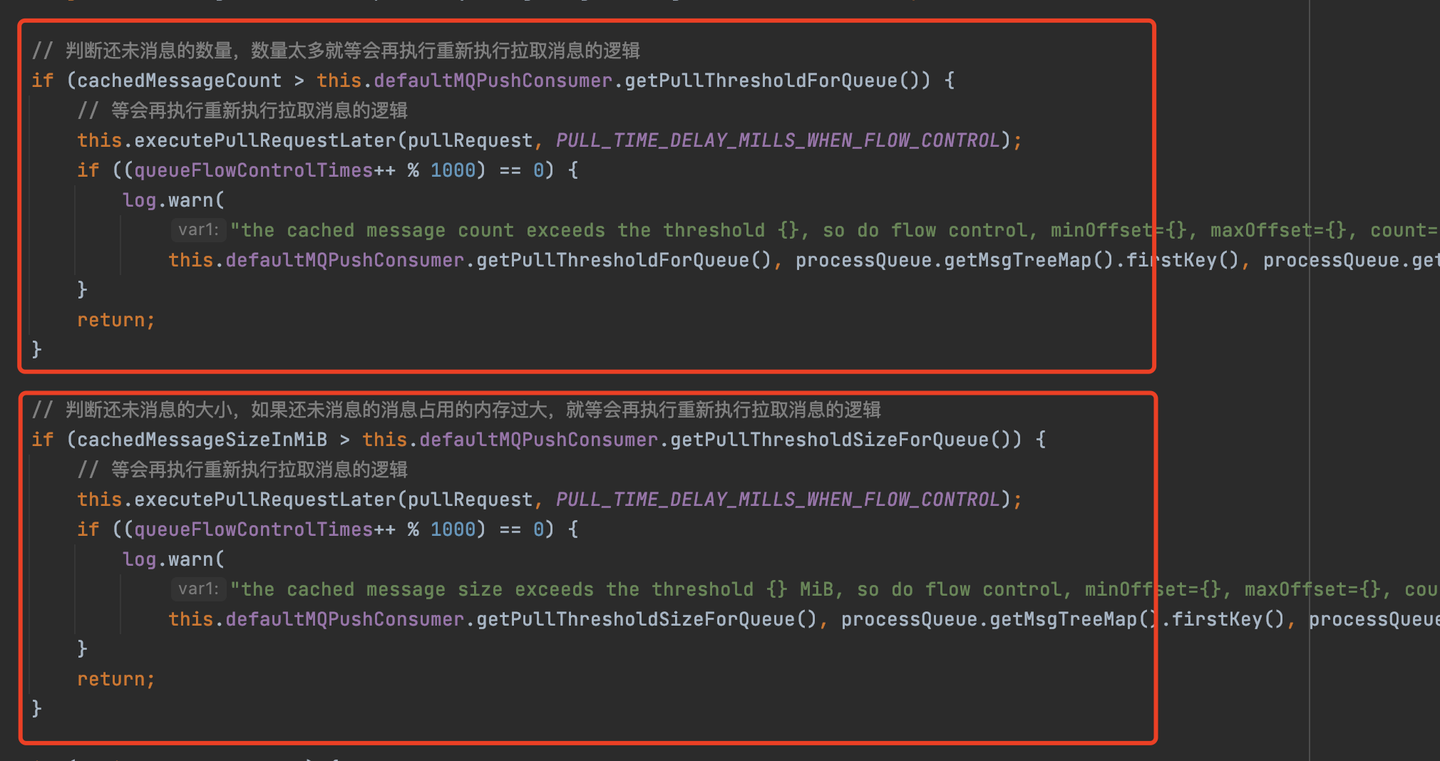 控制压力源码
控制压力源码
总的一句话就是,当消费者消费的压力过大时,就不会去拉取消息,而是等待一定的时间再去执行拉取消息的逻辑,如果压力还是很大,就还继续等,如此循环,直到消费者的消费压力小于阈值的时候,才会真正的发送请求到MQ中拉取消息。
当服务端未找到消息时,就将请求进行挂起,存起来
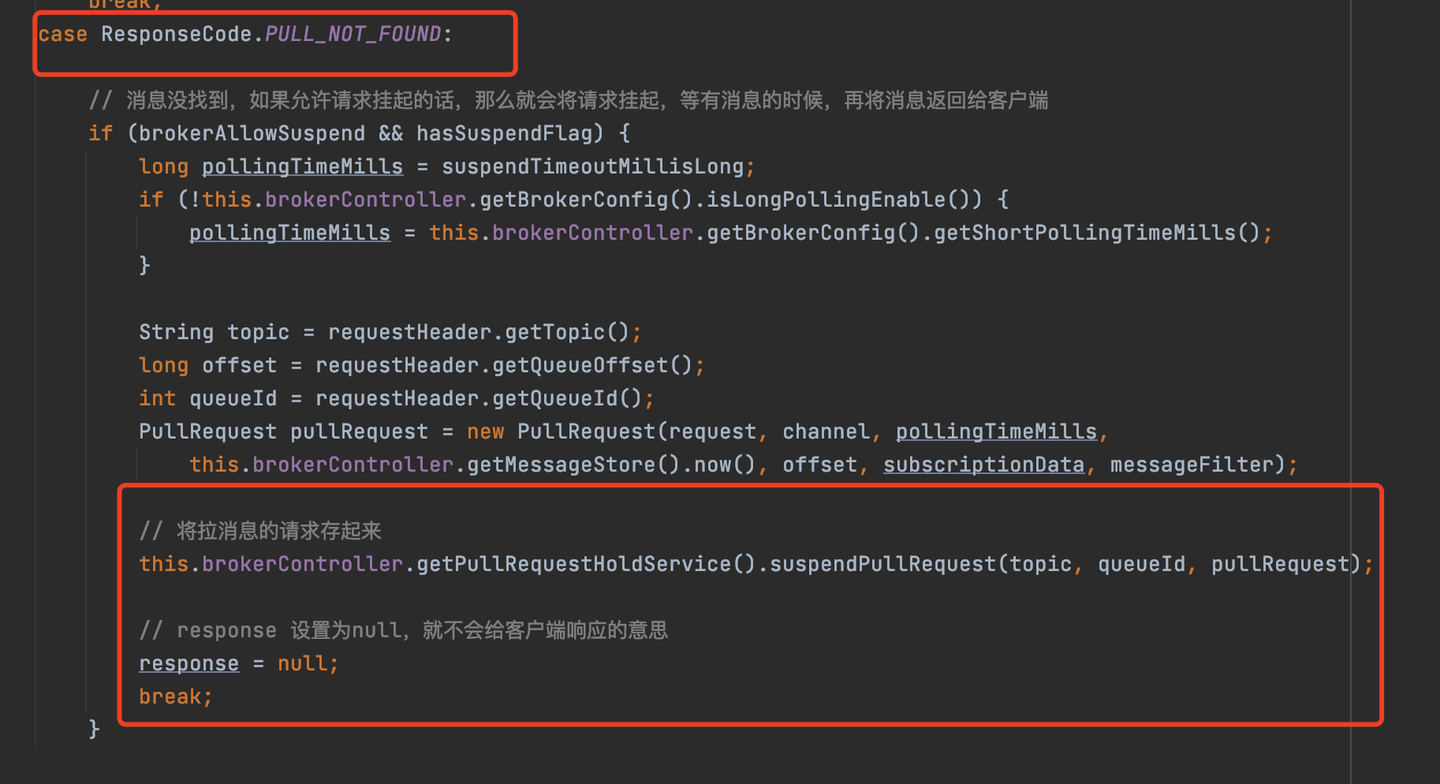 请求hold住源码
请求hold住源码
拉取不到消息时,会调用PullRequestHoldService的suspendPullRequest方法讲请求存储起来。PullRequestHoldService是用来存储拉取请求的类。
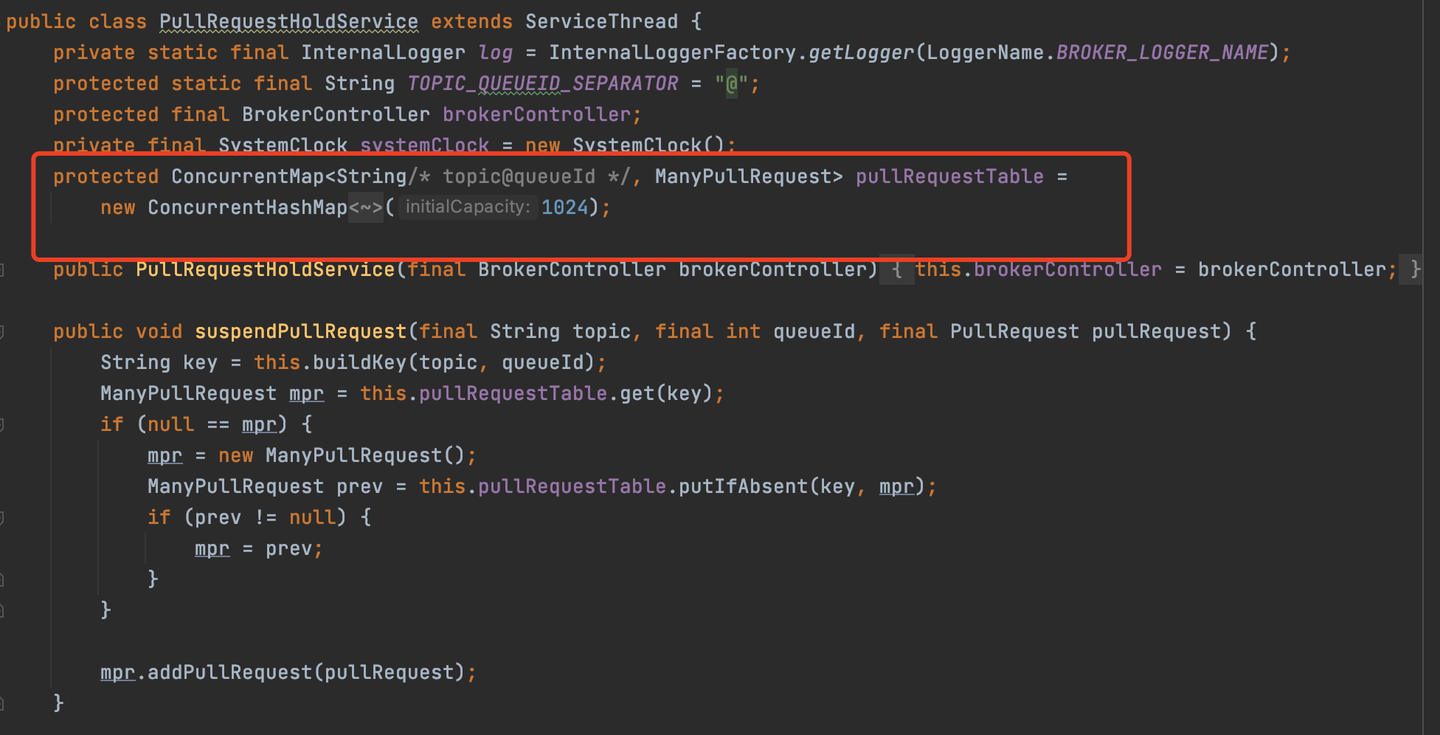 PullRequestHoldService
PullRequestHoldService
suspendPullRequest方法会将请求分类,放到ManyPullRequest里,然后用一个ConcurrentHashMap进行存储
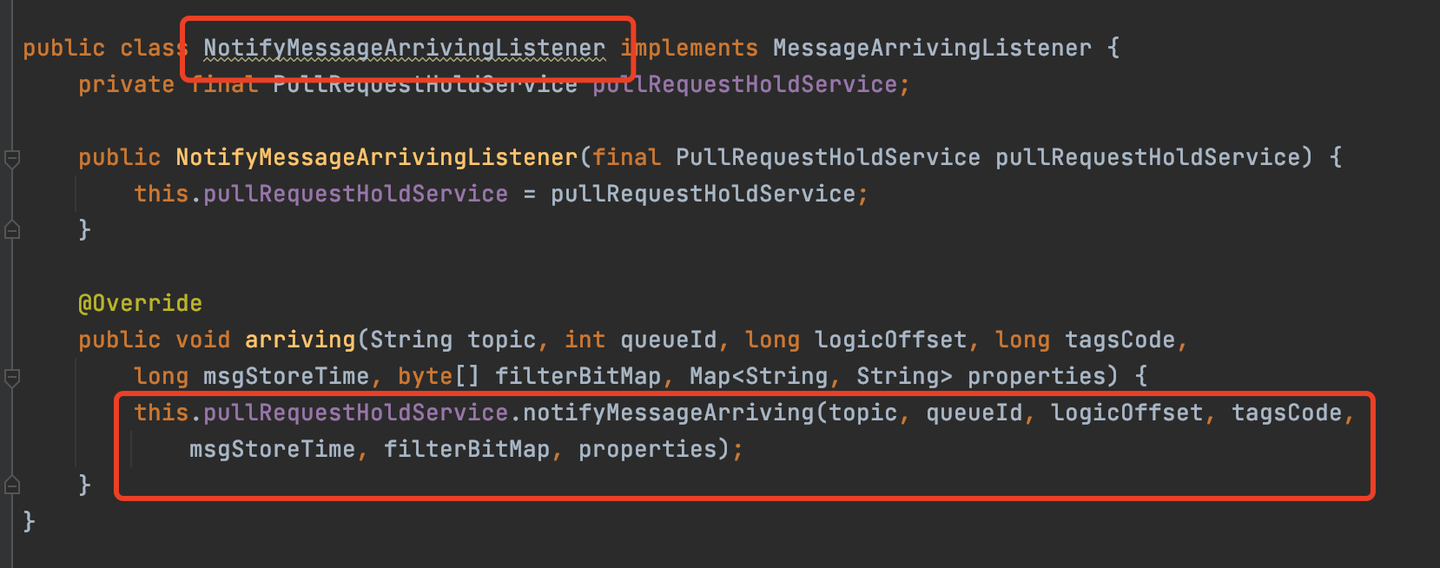 NotifyMessageArrivingListener
NotifyMessageArrivingListener
当生产者发送的消息达到MQ的时候,MQ会回调NotifyMessageArrivingListener的arriving方法,之后就会调用PullRequestHoldService的notifyMessageArriving方法,MQ会重新处理拉取消息的逻辑,此时就能找到最新来的那条消息,从而将最新的消息通过网络返回给消费者。
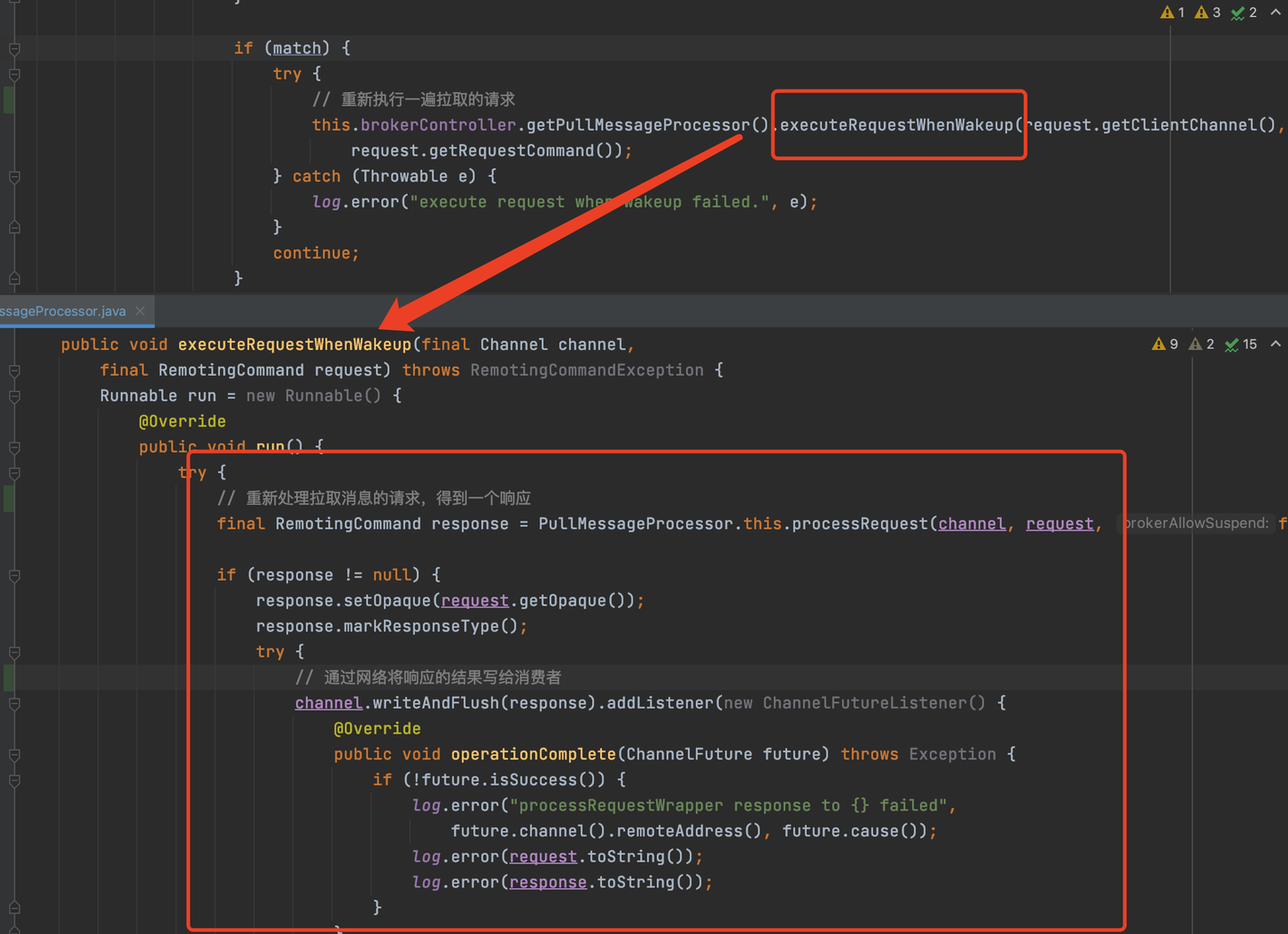 notifyMessageArriving和返回消息逻辑
notifyMessageArriving和返回消息逻辑
所以从以上的分析可以看出,RocketMQ对于push的消费方式的实现是基于长轮询机制来实现的,同时平衡了时实和压力,这其实就很nice了。
最后我想说一句,其实不论是pull还是push,又或是轮询和长轮询,其实都是一种理论或者说是一种思想,不单单是MQ的东西,就比如在Nacos中,也使用了push和长轮询机制。但是这些理论在不同产品的具体实现,实现方式可能不太一样,但都是大同小异,所以当你懂了这些思想,再看其它框架的源码,其实就很容易了。
最后的最后,我再说一句,终于***发年终奖了。。
本文如果对你有点帮助,还请帮忙点赞、在看、转发、非常感谢。
往期热门文章推荐
扫码或者搜索关注公众号 三友的java日记 ,及时干货不错过,公众号致力于通过画图加上通俗易懂的语言讲解技术,让技术更加容易学习,回复 面试 即可获得一套面试真题。

我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
question的一些答案关于redirect_to让我想到了其他一些问题。基本上,我正在使用Rails2.1编写博客应用程序。我一直在尝试自己完成大部分工作(因为我对Rails有所了解),但在需要时会引用Internet上的教程和引用资料。我设法让一个简单的博客正常运行,然后我尝试添加评论。靠我自己,我设法让它进入了可以从script/console添加评论的阶段,但我无法让表单正常工作。我遵循的其中一个教程建议在帖子Controller中创建一个“评论”操作,以添加评论。我的问题是:这是“标准”方式吗?我的另一个问题的答案之一似乎暗示应该有一个CommentsController参
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复