💧学了海王算法会变成海王吗,它又能解决什么样的问题呢?💧
🌷 仰望天空,妳我亦是行人.✨
🦄 个人主页——微风撞见云的博客🎐
🐳 数据结构与算法专栏的文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺
🪁 希望本文能够给读者带来一定的帮助🌸文章粗浅,敬请批评指正!🐥
文章目录
💧海王算法又叫 匈牙利算法 \color{#00BFFF}{匈牙利算法} 匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。匈牙利算法是基于Hall定理中充分性证明的思想,它是 部图匹配 \color{#00BFFF}{部图匹配} 部图匹配最常见的算法,该算法的核心就是 寻找增广路径 \color{#00BFFF}{寻找增广路径} 寻找增广路径,它是一种用增广路径 求二分图最大匹配 \color{#00BFFF}{求二分图最大匹配} 求二分图最大匹配的算法。
🍊我个人很喜欢
章若楠
\color{#FF1493}{章若楠}
章若楠和
许光汉
\color{#FF1493}{许光汉}
许光汉两位明星,那么,今天我就要来当个媒婆,干啥事儿呢?我要撮合他们,尽量让他们在一起。
🍊由于我只提到了上面两位明星,那么我就用他们不同的照片来分别作为男一号、男二号、男三号、男四号,女一号、女二号、女三号、女四号,可能有点不太好,但是,我目前觉得还挺好,嘿嘿,就这样吧!
🍊今天,我是一名伟大的媒婆!我要把男主们和女主们尽最大努力撮合在一起!既然是两个人在一起,那还是得先遵循他们自己的意愿吧。下图中的连线就表示两人相互有好感,也就是说可以尝试在一起一下,我们用个小本本记录一下,看看有哪些连线。(海王算法嘛,当然有海王咯,海王们一般都不专一,一次性喜欢多个人虽然很下头,但还是比较合理的。狗头保命 )

🐲 这个时候,天色骤变,海面上出现了一个 巨大的怪兽 \color{#00BFFF}{巨大的怪兽} 巨大的怪兽🦕🌊🌊🌊,它咆哮着说:“我就是万恶的 海王 \color{#00BFFF}{海王} 海王(呜~~~),今天这桩事必须听我的,让我来给他们分配对象,否则我就…”。
🏄♂️好吧那我们就听它的,看看它能玩出什么花样。
🐲海王说:“第一步:我先试着给男一号找对象。”
🏄♂️我给海王说:“我这里有个小本子,上面有他们彼此之间的暧昧关系💗。”
🐲海王一看:“好家伙,到底谁是海王? 这样吧,男一号和女一号都还没确定关系,那我们就先给他们俩搓一对儿吧”。就这样,男一号和女一号暂时牵手成功了💘。(这里用粉紫色的双向箭头替换原来的连线,表示他们双向奔赴,在一起了。)
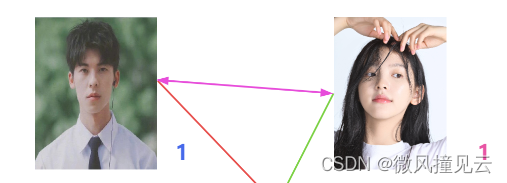
🏄♂️紧接着,海王发现男二号和女二号也都没有对象,于是给他们俩也安排上了。男二女二暂时牵手成功💘。
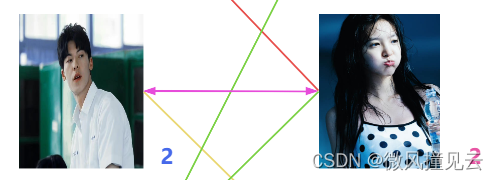
🏄♂️接下来是男三号,海王发现与男二号有好感的女一号和女二号都已经名花有主了。这可咋办呢?
🐲海王发话了:“男三号喜欢女一号是吧,那就先把女一号和男一号拆开,重新分配一下。”(用灰色的先表示分手。)
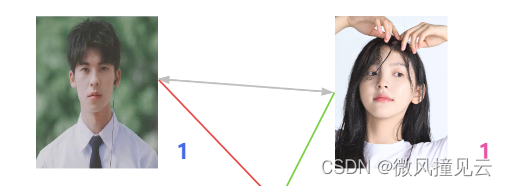
🏄♂️绝了,什么操作啊?人家手还没牵热乎呢!真不愧是海王,什么事都做得出来!”
🐲海王:“你少废话,信不信我把你…”
🏄♂️于是我眼睁睁看着男一号和女一号分开了。男三号和女一号在一起了。那男一号咋办呢?

🐲海王:“男一号不是还喜欢女二号吗,让他们俩试试。”
🏄♂️于是男二号和女二号分开了,男一号和女二号在一起了。那男二号咋办呢?
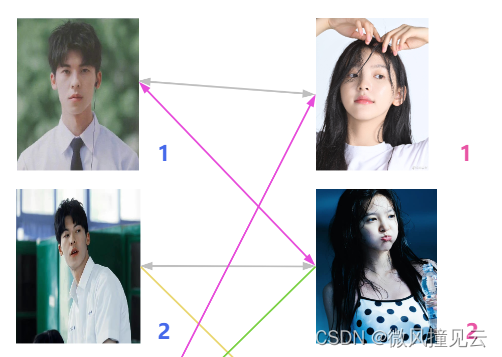
🐲海王:“男二号不是还喜欢女三号吗,让他们俩试试。”

🏄♂️于是男二号和女三号在一起了。诶嘿,你别说,你还真别说,虽然海王这样的做法很下头,但是确实多撮合了一对儿出来,还算有点东西。那我们的男四号呢?
🐲海王看了看小本子说:“这最后一个男生,我按照刚才的转移大法,也不能给他腾个女生出来,毕竟如果我满足了他,那前面的男生总会有一个分手,既然不能多撮合一对儿,那我就省省功力了,放弃这个男生吧。年轻人,我就一个要求,不要做海王,别来和我抢饭碗。后会有期!🦕🌊🌊🌊”
🏄♂️随着海王的离开,天空也明亮了,太阳格外耀眼,因为我在海王的帮助下,成功撮合了三对暧昧情侣!
💧怎么样?看完海王这一顿操作,你悟出了什么道理?没错,有机会要上,别要怂,没机会也要创造机会,尽量撮合更多的暧昧情侣。
💧回顾海王的操作,我发现转移大法的精髓就是分配和递归寻找:
💧我们需要用以下变量来维护这些操作,它们分别是:
boolean[][] line = new boolean[N][N];//邻接矩阵建立连线
int[] girl = new int[N];//存储每个女生被分配给了哪个男生 girl[1] = 2 --> 1号女生分配给了2号男生
boolean[] used;//这里标记过的意思是这次查找曾试图改变过该妹子的归属问题,但是没有成功,所以就不用瞎费工夫了
private static boolean find(int x) {
for (int j = 1; j <= m; j++) {//枚举每个女主
if (line[x][j] && !used[j]) {//如果有暧昧并且还没有标记过
used[j] = true;
if (girl[j] == 0 || find(girl[j])) {//名花无主 或者 能腾出个位置来【递归实现】
girl[j] = x;
return true;
}
}
}
return false;
}
//看看能否给男生i分配一个女生
for (int i = 1; i <= n; i++) {
used = new boolean[N];//每次都给他new个新的,目的就是重置状态
if (find(i)) ans++;
}
public class 暧昧情侣 {
static int N = (int) 1e4 + 10;
static boolean[][] line = new boolean[N][N];//邻接矩阵建立连线
static int[] girl = new int[N];//存储每个女生被分配给了哪个男生 girl[1] = 2 --> 1号女生分配给了2号男生
static boolean[] used;//这里标记过的意思是这次查找曾试图改变过该妹子的归属问题,但是没有成功,所以就不用瞎费工夫了
static int n, m, ans;
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
public static void main(String[] args) throws IOException {
in.nextToken();
n = (int) in.nval;//男
in.nextToken();
m = (int) in.nval;//女
in.nextToken();
int k = (int) in.nval;//k条记录,表示男女之间彼此之间有好感
int temp;
while (k-- > 0) {
in.nextToken();
temp = (int) in.nval;
in.nextToken();
line[temp][(int) in.nval] = true;
}
//看看能否给男生i分配一个女生
for (int i = 1; i <= n; i++) {
used = new boolean[N];
if (find(i)) ans++;
}
System.out.println(ans);
}
private static boolean find(int x) {
for (int j = 1; j <= m; j++) {//枚举每个妹子
if (line[x][j] && !used[j]) {//如果有暧昧并且还没有标记过
used[j] = true;
if (girl[j] == 0 || find(girl[j])) {//名花无主 或者 能腾出个位置来【递归实现】
girl[j] = x;
return true;
}
}
}
return false;
}
}
相关解释:
/**
*find(3), x=3, j=1, girl[j]=1(女士1已暂时被许配给了男士1)->find(girl[j])(进入递归,看能不能给男士1>再找个对象,把女士1让出来给男士3),
*find(1), used[1]=1,所以跳过j=1,进入j=2(男士1也很欣赏女士2),girl[j]=2(但女士2已暂时被许配给了男>士2) ->
*-> find(girl[j])(进入递归,看能不能给男士2再找个对象,把女士2让出来给男士1),
*find(2), used[2]=true,跳过j=1,j=2,进入j=3(男士2也很欣赏女士3),girl[j]=0(女士3单身), 正好,>girl[j]=2(女士3许配给男士2),return true,
*此时回溯到上一步find(1)这里面,既然find(girl[j])=True(给男士2重新找了个对象女士3)了,>girl[j]=1(女士2恢复单身了,和男士1在一起了),return true
*此时再回溯到上上一步find(3)这里面,既然find(girl[j])=True(给男士1找到了新对象女士2),girl[j]=3>(女士1恢复单身了,和男士3在一起了),return true
*
*至此由男士3单身引起的一系列递归和回溯结束了,并凑成了三对情侣。
*再回到大循环下,继续向下执行就好了
*/
import java.io.*;
import java.util.Arrays;
public class Main {
static int N = 210;
static boolean[][] line = new boolean[N][N];
static int[] match = new int[N];
static boolean[] vis = new boolean[N];
static int n, m;
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
public static void main(String[] args) throws IOException {
in.nextToken();
n = (int) in.nval;//牛
in.nextToken();
m = (int) in.nval;//棚
for (int i = 1; i <= n; i++) {
int count;
in.nextToken();
count = (int) in.nval;
while (count-- > 0) {
in.nextToken();
line[i][(int) in.nval] = true;
}
}
int res = 0;
for (int i = 1; i <= n; i++) {
Arrays.fill(vis, false);
if (find(i)) res++;
}
System.out.println(res);
}
private static boolean find(int x) {
for (int i = 1; i <= m; i++) {
if (!vis[i] && line[x][i]) {
vis[i] = true;
if (match[i] == 0 || find(match[i])) {
match[i] = x;
return true;
}
}
}
return false;
}
}
import java.io.*;
import java.util.Arrays;
public class Main {
static int N = 210, M = N * N;//注意:最多有N * N条边
static int[] match = new int[N];
static boolean[] vis = new boolean[N];
static int n, m;
static int total;//第n条边,从1开始
static int[] head = new int[M], next = new int[M], ends = new int[M];//这里不需要考虑边权
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static void add(int start, int end) {
ends[++total] = end;
next[total] = head[start];
head[start] = total;
}
public static void main(String[] args) throws IOException {
in.nextToken();
n = (int) in.nval;//牛
in.nextToken();
m = (int) in.nval;//棚
Arrays.fill(head, -1);
for (int i = 1; i <= n; i++) {
in.nextToken();
int count = (int) in.nval;
while (count-- > 0) {
in.nextToken();
add(i, (int) in.nval);
}
}
int res = 0;
for (int i = 1; i <= n; i++) {
Arrays.fill(vis, false);
if (find(i)) res++;
}
System.out.println(res);
}
private static boolean find(int x) {
for (int i = head[x]; i != -1; i = next[i]) {
int j = ends[i];
if (!vis[j]) {
vis[j] = true;
if (match[j] == 0 || find(match[j])) {
match[j] = x;
return true;
}
}
}
return false;
}
}

🐬初学一门技术时,总有些许的疑惑,别怕,它们是我们学习路上的点点繁星,帮助我们不断成长。
🐟文章粗浅,希望对大家有帮助!
🦄参考文章:趣写算法系列之–匈牙利算法
设置:狂欢ruby1.9.2高线(1.6.13)描述:我已经相当习惯在其他一些项目中使用highline,但已经有几个月没有使用它了。现在,在Ruby1.9.2上全新安装时,它似乎不允许在同一行回答提示。所以以前我会看到类似的东西:require"highline/import"ask"Whatisyourfavoritecolor?"并得到:Whatisyourfavoritecolor?|现在我看到类似的东西:Whatisyourfavoritecolor?|竖线(|)符号是我的终端光标。知道为什么会发生这种变化吗? 最佳答案
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我遇到了一个非常奇怪的问题,我很难解决。在我看来,我有一个与data-remote="true"和data-method="delete"的链接。当我单击该链接时,我可以看到对我的Rails服务器的DELETE请求。返回的JS代码会更改此链接的属性,其中包括href和data-method。再次单击此链接后,我的服务器收到了对新href的请求,但使用的是旧的data-method,即使我已将其从DELETE到POST(它仍然发送一个DELETE请求)。但是,如果我刷新页面,HTML与"new"HTML相同(随返回的JS发生变化),但它实际上发送了正确的请求类型。这就是这个问题令我困惑的
我有可变数量的表格和可变数量的行,我想让它们一个接一个地显示,但如果表格不适合当前页面,请将其放在下一页,然后继续。我已将表格放入事务中,以便我可以回滚然后打印它(如果高度适合当前页面),但我如何获得表格高度?我现在有这段代码pdf.transactiondopdf.table@data,:font_size=>12,:border_style=>:grid,:horizontal_padding=>10,:vertical_padding=>3,:border_width=>2,:position=>:left,:row_colors=>["FFFFFF","DDDDDD"]pdf.
我有一个Ruby文件,我将它作为rubyfile.rb"parameters"运行。我更喜欢将它作为regtask参数运行,而不必每次都包含ruby和文件名。我希望它与ls处于同一级别。我将如何做到这一点? 最佳答案 编辑你的文件,确保这是第一行,这样你的系统就知道如何执行你的文件:#!/usr/bin/envruby接下来,更改文件的权限以使其可执行:chmoda+xfile.rb最后,重命名并将其移动到将要执行的位置,而无需编写其完整路径:mkdir-p~/binmvfile.rb~/bin/regtask(如果~/bin存在,
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti