1.在yolov5上增加小目标检测层link
2.在yolov5上增加注意力机制
CBAM
SElayer
…
3.考虑在yolov5中加入旋转角度的目标检测机制。
reference:
[1]https://zhuanlan.zhihu.com/p/358441134
[2]https://github.com/onehahaha756/yolov5_rotation
4.结合BiPFN,将yolov5中的PANet层改为efficientDet中的BiFPN。
5.训练baseline,同时使用加权框融合WBF进行后处理/预处理。
6.AF-FPN替换金字塔模块。利用自适应注意力机制(AAM)和特征增强模块(FEM)来减少特征图生成过程中的信息丢失并增强表示能力的特征金字塔。将yolov5中原有的特征金字塔网络替换为AF-FPN。来解决模型大小和识别精度不兼容的问题,提高了识别多尺度目标的能力,并在识别速度和准确率之间做出有效的权衡。
7.从数据增强角度,用主动学习策略(active learning)来替换原有的mosaic augmentation。
11/22更~~
乌龙事件,事实证明,不是所有的tricks都有效,甚至精度大幅下降让人怀疑人生。
在yolov5融合注意力机制SElayer之后,mAP下降的特别厉害的问题。
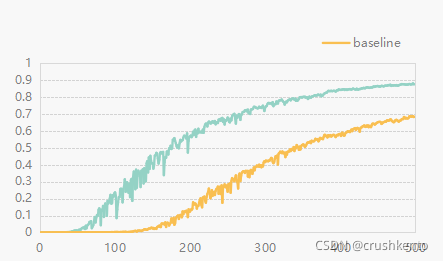
基模型和改进策略同时5x模型,300个epoch训练,基模型的效果在0.49mAP,500个epoch训练,可以到0.87mAP。再康康300epoch的yolov5_se_model的结果。啊哈哈哈。原理理论可行不是对每个数据集都有效的。
11/27号更~~
既然有小朋友问怎么融合的注意力机制,大概写一下。。
主要是改三个地方,common.py yolo.py和对应预训练模型的yaml。
1.在common.py添加SElayer或CBAM的类。关于这个模块的定义去参考注意力机制的代码。大部分的注意力机制都是结合通道和空间去做文章。
2.在yolo.py开头的import环节添加common.py写好的注意力机制Module。
3.在对应预训练模型的yaml文件,backbone中嵌入你的注意力机制。
救命,但是我的效果很差,需要把conf-thres调到很小才有不错的检测效果,单看指标的话,可能是我的数据的问题,没分析数据噪声啊,分布规律这些,不确定这样单纯的添加tricks起到了什么作用。
最后,记录下今天的实验结果,还不戳的亚子~~
12/7更~~
偶然又看到两篇文章,思路如下:
1.yolov5结合BiFPN,现在的neck用的是PANet,在EfficientDet论文中提出了BiFPN结构,还有更加不错的性能,所以就尝试将yolov5中的PANet层改为BiFPN。
2.训练yolov5的baseline,同时使用加权框融合(WBF)进行后处理/预处理。
下面是WBF的学习记录:
WBF已经成为优化目标检测的SOTA了。
如果你熟悉目标检测的工作原理,你可能知道总有一个主干CNN来提取特征。还有一个阶段是,生成区域建议(region proposal)–可能的建议框,或者是过滤已经提出的建议区域。这里的主要问题是,要么物体检测任务出现一物多框,要么生成的边框不够,最终导致平均精度较低的原因。目前其实已经提出了一些算法来解决这个问题。比如我们常见的NMS–非极大抑制。
但是其实,对于遮挡问题较为严重的检测任务,在一些目标密集的区域,可能包含多个标签,这意味着将出现一框多物的现象,如果使用非极大抑制NMS这类策略,它是通过iou来过滤框的,因此,很难确定一个较好的阈值,所以这类策略可能会删除有用的检测框。
另外还有soft-NMS,它试图通过一种更soft的方法来解决NMS的主要问题。它不会完全移除那些iou高于阈值的框,而是根据iou的值来降低它们的置信度分数。它是NMS的优化,相比于NMS会过滤掉过更少的框。
加权框融合(WBF)的工作原理与NMS不同。首先,它将所有的边界框按照置信度分数的递减顺序进行排序,然后生成一个可能的框来融合列表,并检查这些融合是否与原始框匹配。这里也会给定一个iou的阈值来判断匹配效果,它通过检查iou是否大于指定阈值来实现。
然后,通过一系列公式来调整坐标和框列表中所有框的置信度分数。新的置信度仅仅是它被融合的所有框的平均置信度。新坐标以类似的方式融合(平均),除了坐标是加权的,既然是加权的,意味着不是每个框在最终的融合的框中都具有相同的贡献。这个权重的值是由置信度来决定的,但较低的置信度可能表明预测错误。
除此之外,还有第四种方法,非最大加权融合,它的工作机制和WBF类似,但性能不如WBF,因为它不会改变框的置信度,而是使用iou值来衡量方框,而不是更精确的度量。其实表现也相当接近。
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
我正在尝试将以下SQL查询转换为ActiveRecord,它正在融化我的大脑。deletefromtablewhereid有什么想法吗?我想做的是限制表中的行数。所以,我想删除少于最近10个条目的所有内容。编辑:通过结合以下几个答案找到了解决方案。Temperature.where('id这给我留下了最新的10个条目。 最佳答案 从您的SQL来看,您似乎想要从表中删除前10条记录。我相信到目前为止的大多数答案都会如此。这里有两个额外的选择:基于MurifoX的版本:Table.where(:id=>Table.order(:id).
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我想找到在某些文本中找到一些(让它是两个)句子的好方法。什么会更好-使用正则表达式或拆分方法?你的想法?应JeremyStein的要求-有一些例子示例:输入:ThefirstthingtodoistocreatetheCommentmodel.We’llcreatethisinthenormalway,butwithonesmalldifference.IfwewerejustcreatingcommentsforanArticlewe’dhaveanintegerfieldcalledarticle_idinthemodeltostoretheforeignkey,butinthis
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
在许多ruby类之间共享记录器实例的最佳(正确)方法是什么?现在我只是将记录器创建为全局$logger=Logger.new变量,但我觉得有更好的方法可以在不使用全局变量的情况下执行此操作。如果我有以下内容:moduleFooclassAclassBclassC...classZend在所有类之间共享记录器实例的最佳方式是什么?我是以某种方式在Foo模块中声明/创建记录器还是只是使用全局$logger没问题? 最佳答案 在模块中添加常量:moduleFooLogger=Logger.newclassAclassBclassC..