在根据四叉树节点创建了1365个地形分块网格并保存到本地后,我们接下来要在游戏运行的过程中动态地显示所需的网格,这是最关键的一步。
如何根据摄像机位置动态地选择地形块?这其中体现了由整体到局部,从简单到复杂的原则。
0、 我们首先创建三个缓存列表。
1、 我们先将索引为0的地形分块(即最高LOD等级)的分块放入BufferA;
2、 然后遍历BufferA,判断BufferA中的每一个元素是否符合“无需更加详细”的条件,如果是,将它放入BufferFinal,否则放入BufferB;
3、 在遍历完BufferA中的元素后,清空BufferA,将BufferB的元素全部复制到BufferA中,清空BufferB;
4、 重复2-3步骤的操作,直到BufferA、BufferB列表均空。
此时BufferFinal中存储的索引即是我们最终所需要的地形网格分块的索引。
我们把以上的操作封装成函数,在游戏开始运行时调用一次。这一部分的代码如下:
private void TerrainGen() // 生成(更新)地形网格
{
// 使用了子物体网格的方法,而不是网格合并的方法
// 因此需要首先清除所有子物体
for (int i = 0; i < transform.childCount; i++)
{
Destroy(transform.GetChild(i).gameObject);
}
// 四叉树计算
// 三个buffer计算方法
List<int> BufferA = new List<int>();
List<int> BufferB = new List<int>();
List<int> FinalBuffer = new List<int>();
Vector3 ppos = player.transform.position;
// 迭代计算
BufferA.Add(0); // bufferA初始化,加入根节点
while (BufferA.Count != 0) // 当bufferA不为空时
{
while (BufferA.Count != 0) // 遍历buffera每个值
{
int i = BufferA[0];
float dist = Mathf.Sqrt(Mathf.Pow((qTree[i].begin_Pos.x + 64 * qTree[i].interval) * 5 - ppos.z, 2) + Mathf.Pow((qTree[i].begin_Pos.y + 64 * qTree[i].interval) * 5 - ppos.x, 2)); // 计算瓦片中心距离玩家位置的水平距离
BufferA.Remove(i);
if (dist >= 0.8 * 128 * qTree[i].interval * 5) // 1表示1倍瓦片边长;128表示瓦片行列数;5时xzbias(此处其实应该参数化)
{
// 那么这张瓦片距离玩家太远,可以直接使用当前lod,不用细化
FinalBuffer.Add(i);
}
else
{
// 否则这张瓦片距离玩家很近,如果有更小的lod,应该细化;
if(qTree[i].LodLeval == 0) // 如果已经是最细节的瓦片了,那没办法了,直接显示
{
FinalBuffer.Add(i);
}
else // 否则把它的四个更细节的子节点加入到待计算的b buffer
{
for(int j = 1; j <= 4; j++)
{
BufferB.Add(i * 4 + j);
}
}
}
}
// 将ab buffer交换
foreach(int i in BufferB)
{
BufferA.Add(i);
}
BufferB.Clear();
}
Mesh[] tiles = new Mesh[FinalBuffer.Count];
Material mat = GetComponent<Renderer>().material;
for (int i = 0; i < FinalBuffer.Count; i++)
{
tiles[i] = new Mesh();
tiles[i].indexFormat = UnityEngine.Rendering.IndexFormat.UInt32;
string path = @"Assets\LodMeshes\LodMesh_" + FinalBuffer[i].ToString() + ".asset";
tiles[i] = (Mesh)AssetDatabase.LoadAssetAtPath(path, typeof(Mesh));
GameObject theTile = new GameObject();
theTile.transform.parent = this.transform;
theTile.name = "lod_" + i.ToString();
theTile.AddComponent<MeshFilter>();
theTile.AddComponent<MeshRenderer>();
theTile.AddComponent<Renderer>();
theTile.GetComponent<MeshFilter>().mesh = new Mesh();
theTile.GetComponent<MeshFilter>().mesh = tiles[i];
theTile.GetComponent<Renderer>().material = mat;
}
}
这一部分我选择将需要的网格实例化到子对象中而没有合并,如果需要优化的话,应该将网格合并成一个,可以减少DrawCall的数量。
同时要注意的是:网格的实例化与显示并非在每一帧进行,可以维护一个数对来表示玩家摄像机所在的区域,如果玩家摄像机离开了原本的区域进入到新的区域中,那我们便执行一此地形网格更新操作:
void Update()
{
if((int)player.transform.position.x / (64 * 5) != x_area || (int)player.transform.position.z / (64 * 5) != z_area) // 玩家区域改变
{
TerrainGen();
x_area = (int)player.transform.position.x / (64 * 5);
z_area = (int)player.transform.position.z / (64 * 5);
}
}补充一点,在此之前我们可以从本地读取,在上一节生成网格时保存的四叉树信息,这部分代码很简单,如下所示:
private void ReadQTree()
{
using(StreamReader RawTerrainData = new StreamReader(@"E:\Unity\MyProjects\Desert_01\Assets\TerrainTree\MyQTree.txt"))
{
string line;
for (int i = 0; i < qTree.Length; i++) // 读取所有顶点 并且给原始uv数据赋值
{
line = RawTerrainData.ReadLine();
string[] stringdata = line.Split(' ');
// 读取并写入
float.TryParse(stringdata[0], out qTree[i].begin_Pos.x);
float.TryParse(stringdata[1], out qTree[i].begin_Pos.y);
int.TryParse(stringdata[2], out qTree[i].interval);
int.TryParse(stringdata[3], out qTree[i].LodLeval);
float.TryParse(stringdata[4], out qTree[i].Center.x);
float.TryParse(stringdata[5], out qTree[i].Center.y);
}
}
}最终的效果如下:
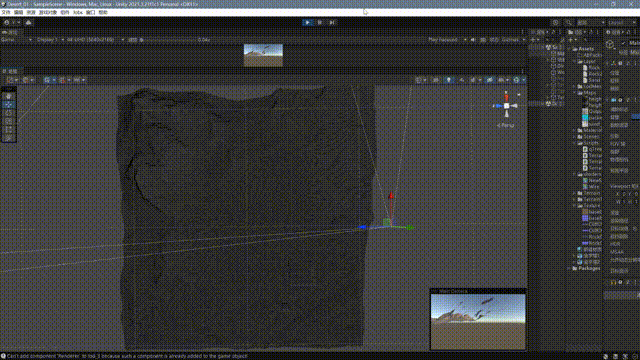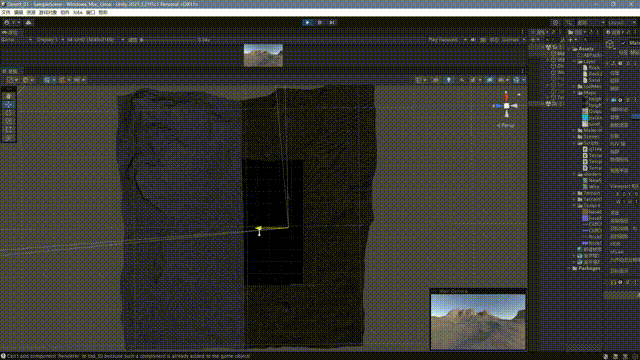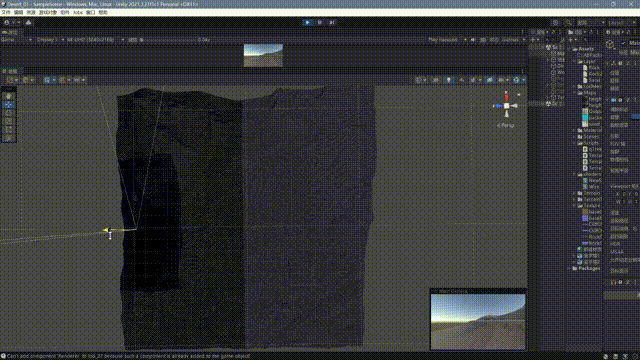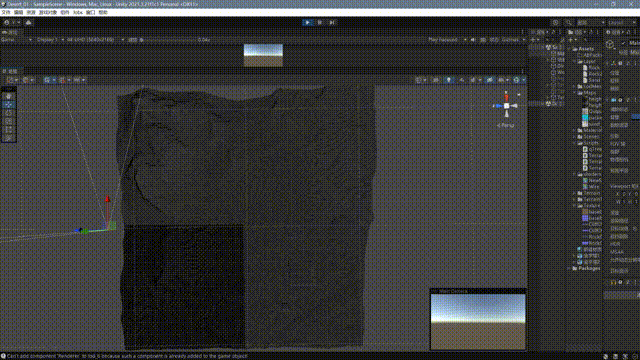
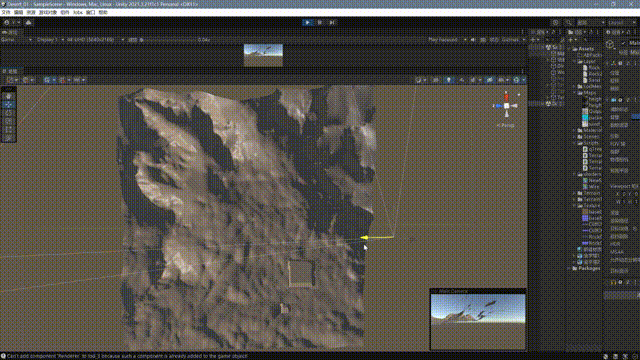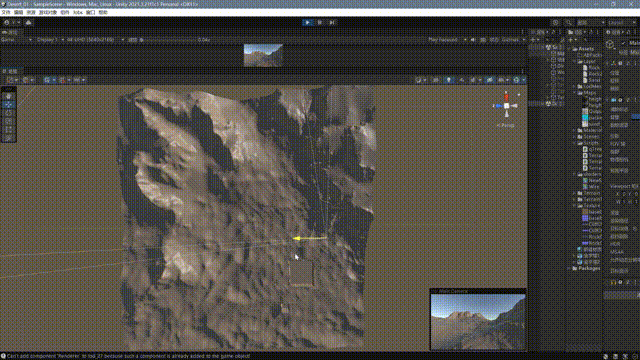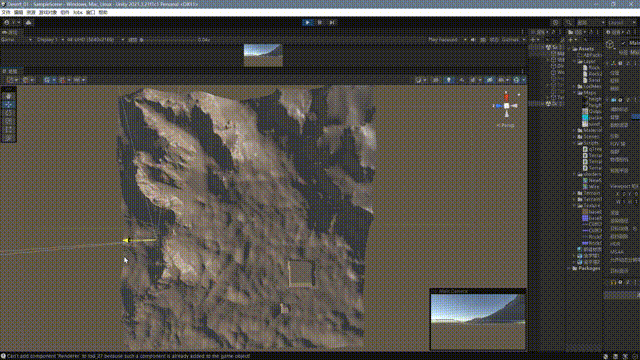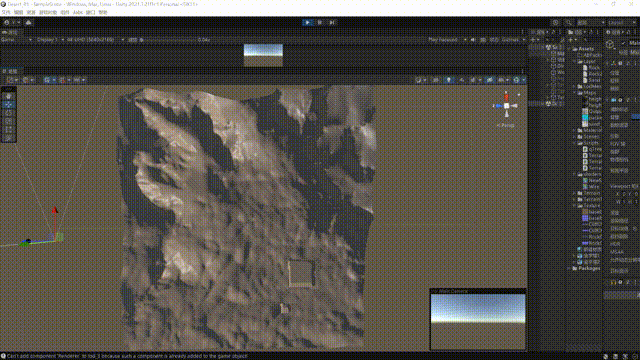
至此,我们大致完成了一个非常基础的一个四叉树网格地形系统,这其中还有很多问题,我大致思考了一下改进的方向:
性能优化方面的问题问题,比如显示的网格应该合并成一个而非保持多个对象;明显超出视线范围的地形网格分块应该直接剔除掉而非继续显示等;
代码复用性的方面的问题,有许多数据直接写死在代码里面,导致耦合度过高。在改进的时候,应该将这些数据参数化,将算法更优化,来降低耦合度,增强代码对不同大小的地形的复用能力;
效果实现方面的问题,没有考虑不同LOD等级的地块的连接处的露缝问题,应该在后续中改进
这里我仅仅实现了最基本的网格动态显示,没有考虑渲染,在以后的改进中,我会尝试在地形渲染方面做出更多改进。
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象