 大家好,我是二哥。最近一直在研究 eBPF ,随着研究的深入,我发现之前写的这篇文章有点问题,所以重新修改了一下。图也重新画了,并添加了一些与 sidecar-less 相关的额外内容。下面是正文。
大家好,我是二哥。最近一直在研究 eBPF ,随着研究的深入,我发现之前写的这篇文章有点问题,所以重新修改了一下。图也重新画了,并添加了一些与 sidecar-less 相关的额外内容。下面是正文。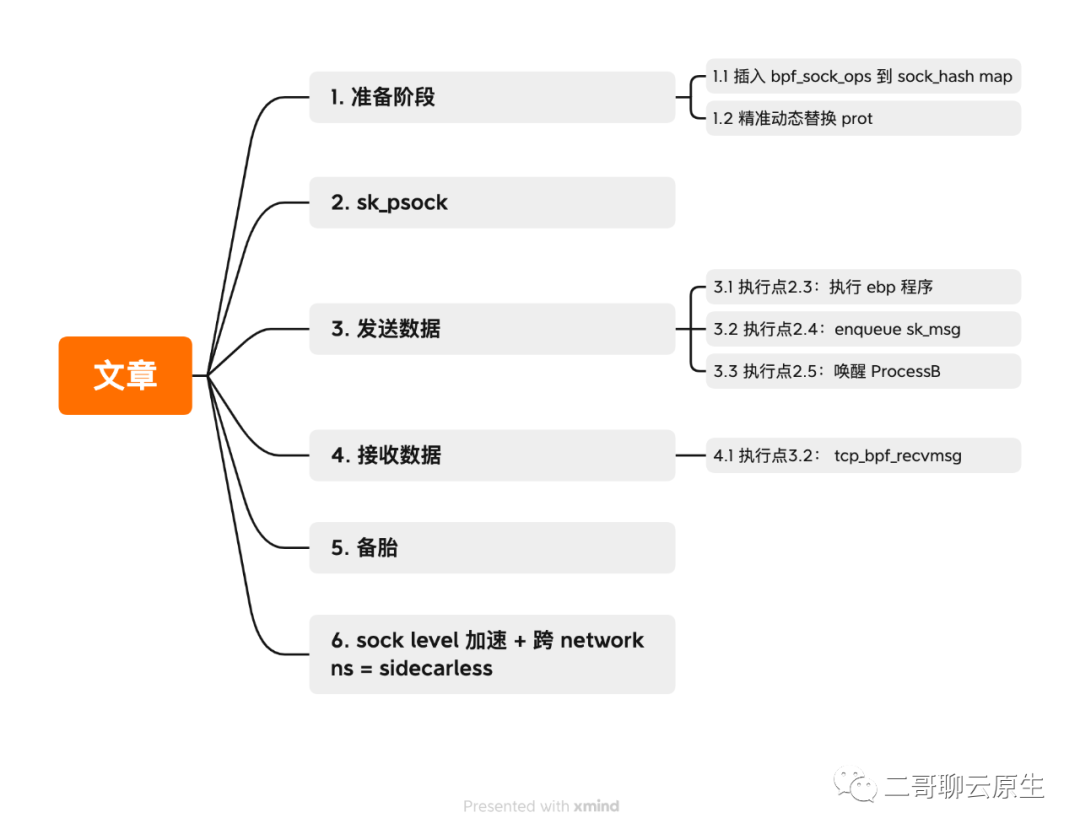 上一篇《利用eBPF实现socket level重定向》,二哥从整体上介绍了 eBPF 的一个应用场景 socket level redirect:如果一台机器上有两个进程需要通过 loopback 设备相互收发数据,我们可以利用 ebpf 在发送进程端将需要发送的数据跳过本机的底层 TCP/IP 协议栈,直接交给目的进程的 socket,从而缩短数据在内核的处理路径和时间。这个流程如图 1 所示。本篇我们来详细看下图 1 右侧在内核里的实现细节。
上一篇《利用eBPF实现socket level重定向》,二哥从整体上介绍了 eBPF 的一个应用场景 socket level redirect:如果一台机器上有两个进程需要通过 loopback 设备相互收发数据,我们可以利用 ebpf 在发送进程端将需要发送的数据跳过本机的底层 TCP/IP 协议栈,直接交给目的进程的 socket,从而缩短数据在内核的处理路径和时间。这个流程如图 1 所示。本篇我们来详细看下图 1 右侧在内核里的实现细节。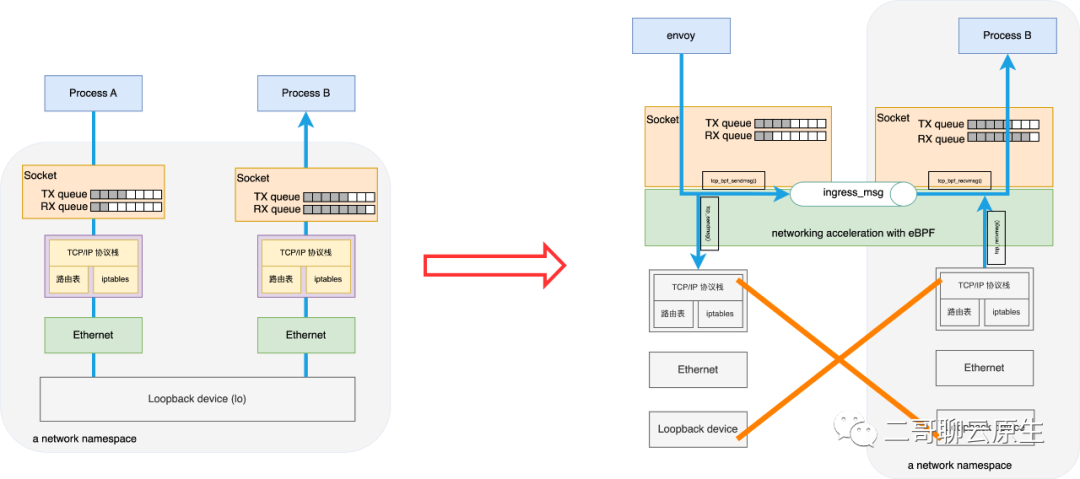 图 1:利用 ebpf 进行 socket level redirect,从而跳过 TCP/IP 协议栈和 lo 设备先来一张全局图,我们再依次剖析这张图上面的关键知识点。
图 1:利用 ebpf 进行 socket level redirect,从而跳过 TCP/IP 协议栈和 lo 设备先来一张全局图,我们再依次剖析这张图上面的关键知识点。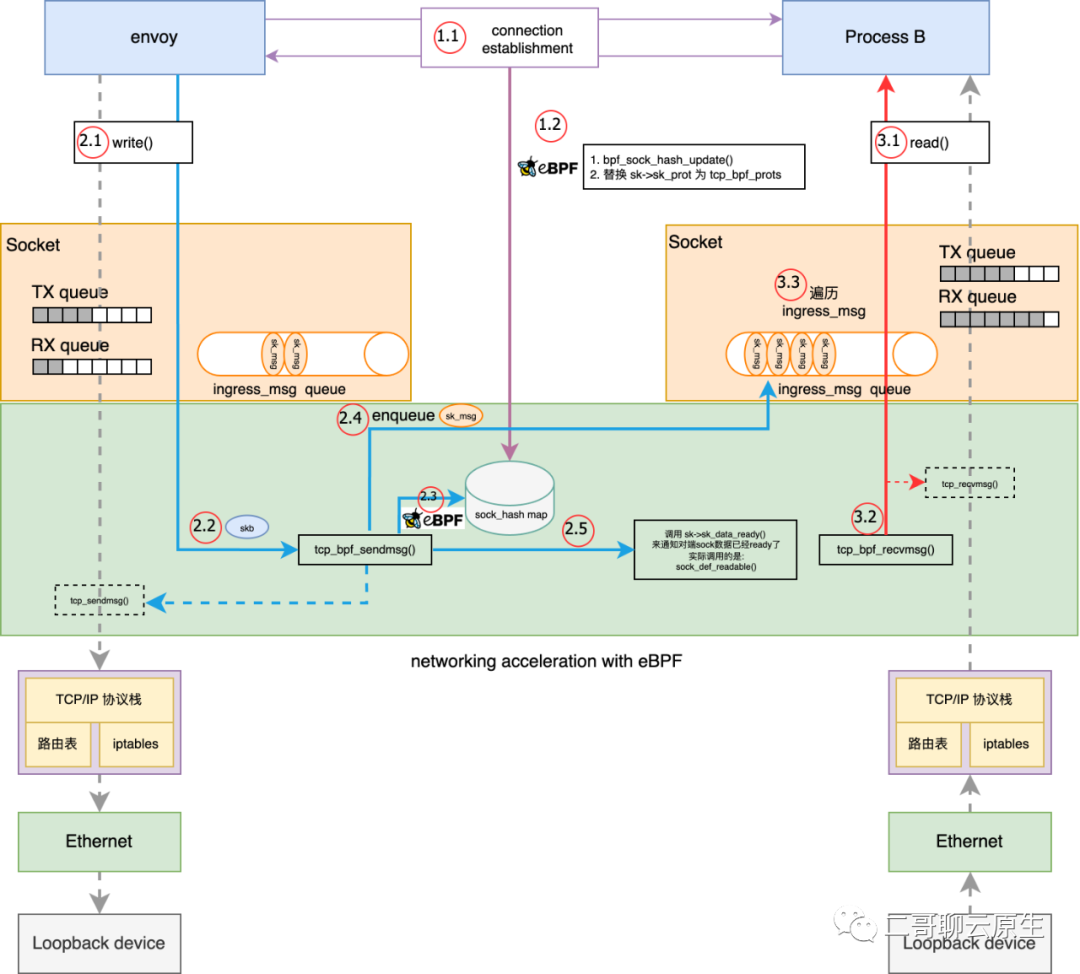 图 2:利用 ebpf 进行 socket level redirect 全局细节图
图 2:利用 ebpf 进行 socket level redirect 全局细节图static inline
void bpf_sock_ops_ipv4(struct bpf_sock_ops *skops)
{
struct sock_key key = {};
int ret;
extract_key4_from_ops(skops, &key);
ret = sock_hash_update(skops, &sock_ops_map, &key, BPF_NOEXIST);
if (ret != 0) {
printk("sock_hash_update() failed, ret: %d\n", ret);
}
printk("sockmap: op %d, port %d --> %d\n",
skops->op, skops->local_port, bpf_ntohl(skops->remote_port));
}
__section("sockops")
int bpf_sockmap(struct bpf_sock_ops *skops)
{
switch (skops->op) {
case BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB:
case BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB:
if (skops->family == 2) { //AF_INET
bpf_sock_ops_ipv4(skops);
}
break;
default:
break;
}
return 0;
}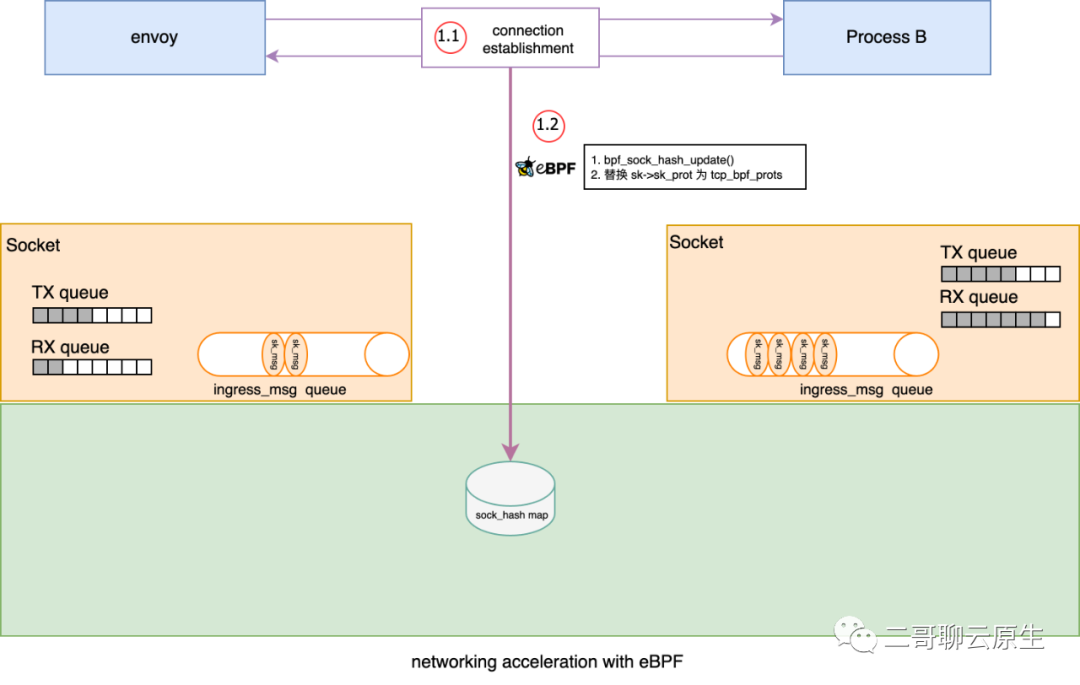 图 3:插入 sock 到 sock_hash map
图 3:插入 sock 到 sock_hash map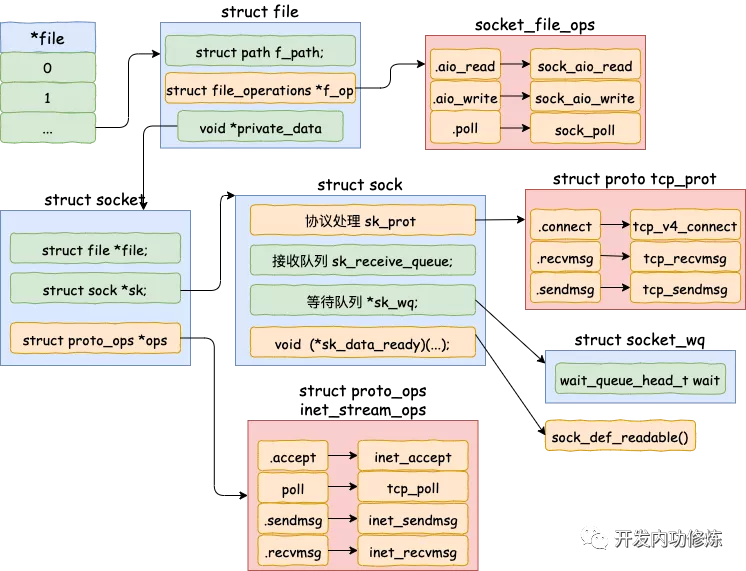 图 4:file / socket / sock / operations(图片来源:开发内功修炼公众号)那 ebpf 在这里面干了啥事呢?非常的巧妙,它把 struct proto 里面的 recvmsg / sendmsg 等函数动态替换掉了。比如把
recvmsg 由原来的 tcp_recvmsg 替换成了 tcp_bpf_recvmsg ,而把 tcp_sendmsg 替换为
tcp_bpf_sendmsg 。
图 4:file / socket / sock / operations(图片来源:开发内功修炼公众号)那 ebpf 在这里面干了啥事呢?非常的巧妙,它把 struct proto 里面的 recvmsg / sendmsg 等函数动态替换掉了。比如把
recvmsg 由原来的 tcp_recvmsg 替换成了 tcp_bpf_recvmsg ,而把 tcp_sendmsg 替换为
tcp_bpf_sendmsg 。static void tcp_bpf_rebuild_protos(struct proto prot[TCP_BPF_NUM_CFGS], struct proto *base)
{
prot[TCP_BPF_BASE] = *base;
prot[TCP_BPF_BASE].close = sock_map_close;
prot[TCP_BPF_BASE].recvmsg = tcp_bpf_recvmsg;
prot[TCP_BPF_BASE].sock_is_readable = sk_msg_is_readable;
prot[TCP_BPF_TX] = prot[TCP_BPF_BASE];
prot[TCP_BPF_TX].sendmsg = tcp_bpf_sendmsg;
prot[TCP_BPF_TX].sendpage = tcp_bpf_sendpage;
prot[TCP_BPF_RX] = prot[TCP_BPF_BASE];
prot[TCP_BPF_RX].recvmsg = tcp_bpf_recvmsg_parser;
prot[TCP_BPF_TXRX] = prot[TCP_BPF_TX];
prot[TCP_BPF_TXRX].recvmsg = tcp_bpf_recvmsg_parser;
}
static int __init tcp_bpf_v4_build_proto(void)
{
tcp_bpf_rebuild_protos(tcp_bpf_prots[TCP_BPF_IPV4], &tcp_prot);
return 0;
}
late_initcall(tcp_bpf_v4_build_proto);
int tcp_bpf_update_proto(struct sock *sk, struct sk_psock *psock, bool restore)
{
// ...
/* Pairs with lockless read in sk_clone_lock() */
WRITE_ONCE(sk->sk_prot, &tcp_bpf_prots[family][config]);
return 0;
}struct sk_psock {
struct sock *sk; // 当前 sock
struct sock *sk_redir; // 通信对端 sock,也即 redirect target
u32 apply_bytes;
u32 cork_bytes;
u32 eval;
struct sk_msg *cork;
struct sk_psock_progs progs;
#if IS_ENABLED(CONFIG_BPF_STREAM_PARSER)
struct strparser strp;
#endif
struct sk_buff_head ingress_skb;
struct list_head ingress_msg;
spinlock_t ingress_lock;
unsigned long state;
struct list_head link;
spinlock_t link_lock;
refcount_t refcnt;
void (*saved_unhash)(struct sock *sk);
void (*saved_close)(struct sock *sk, long timeout);
void (*saved_write_space)(struct sock *sk);
void (*saved_data_ready)(struct sock *sk);
int (*psock_update_sk_prot)(struct sock *sk, struct sk_psock *psock, bool restore);
struct proto *sk_proto;
struct mutex work_mutex;
struct sk_psock_work_state work_state;
struct work_struct work;
struct rcu_work rwork;
}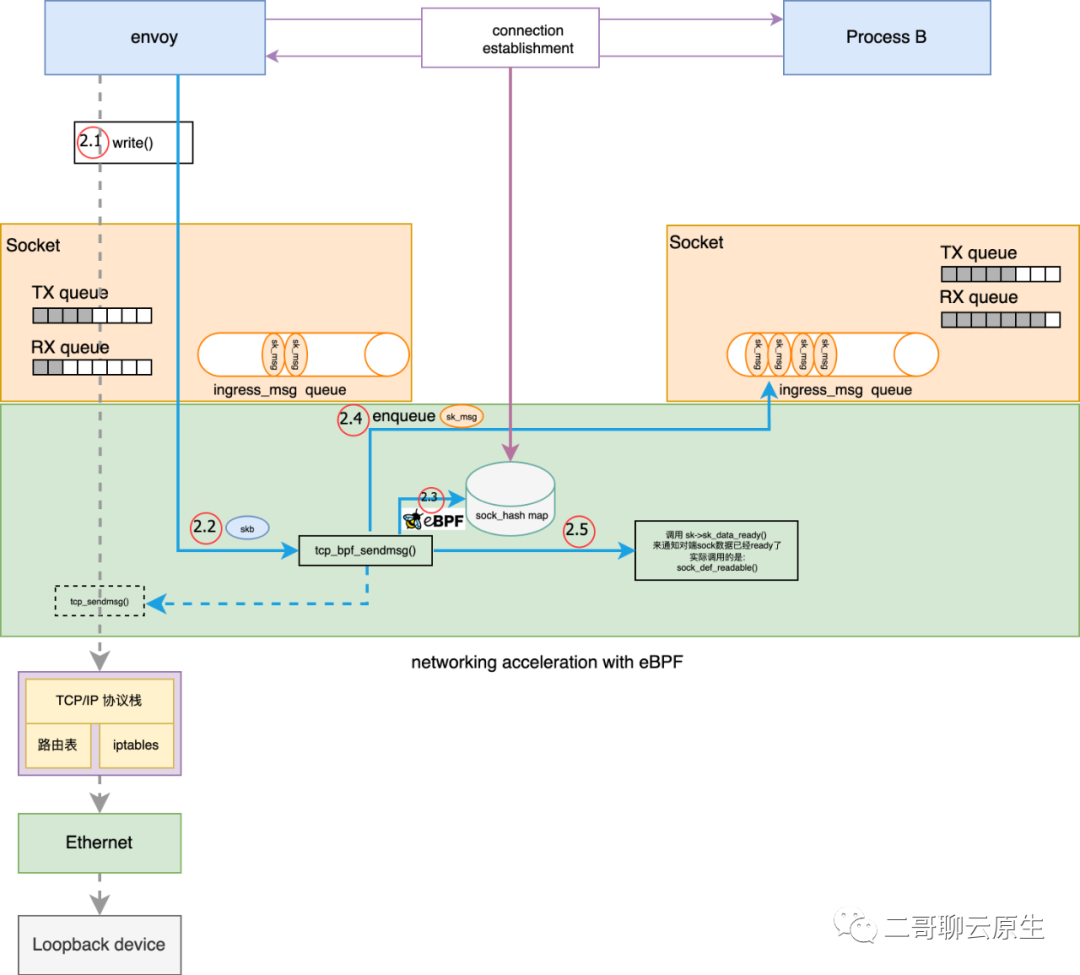 图 5:发送数据流程我在图 5 中画出了 tcp_bpf_sendmsg() 所干的几件重要的事情。
图 5:发送数据流程我在图 5 中画出了 tcp_bpf_sendmsg() 所干的几件重要的事情。static inline
void extract_key4_from_msg(struct sk_msg_md *msg, struct sock_key *key)
{
key->sip4 = msg->remote_ip4;
key->dip4 = msg->local_ip4;
key->family = 1;
key->dport = (bpf_htonl(msg->local_port) >> 16);
key->sport = FORCE_READ(msg->remote_port) >> 16;
}
__section("sk_msg")
int bpf_redir(struct sk_msg_md *msg)
{
struct sock_key key = {};
extract_key4_from_msg(msg, &key);
msg_redirect_hash(msg, &sock_ops_map, &key, BPF_F_INGRESS);
return SK_PASS;
}BPF_CALL_4(bpf_msg_redirect_hash, struct sk_msg *, msg, struct bpf_map *, map, void *, key, u64, flags)
{
struct sock *sk;
if (unlikely(flags & ~(BPF_F_INGRESS)))
return SK_DROP;
sk = __sock_hash_lookup_elem(map, key);
if (unlikely(!sk || !sock_map_redirect_allowed(sk)))
return SK_DROP;
msg->flags = flags;
msg->sk_redir = sk;
return SK_PASS;
}tcp_bpf_sendmsg() -> tcp_bpf_send_verdict() -> tcp_bpf_sendmsg_redir(psock->sk_redir) -> bpf_tcp_ingress() -> sk_psock_queue_msg()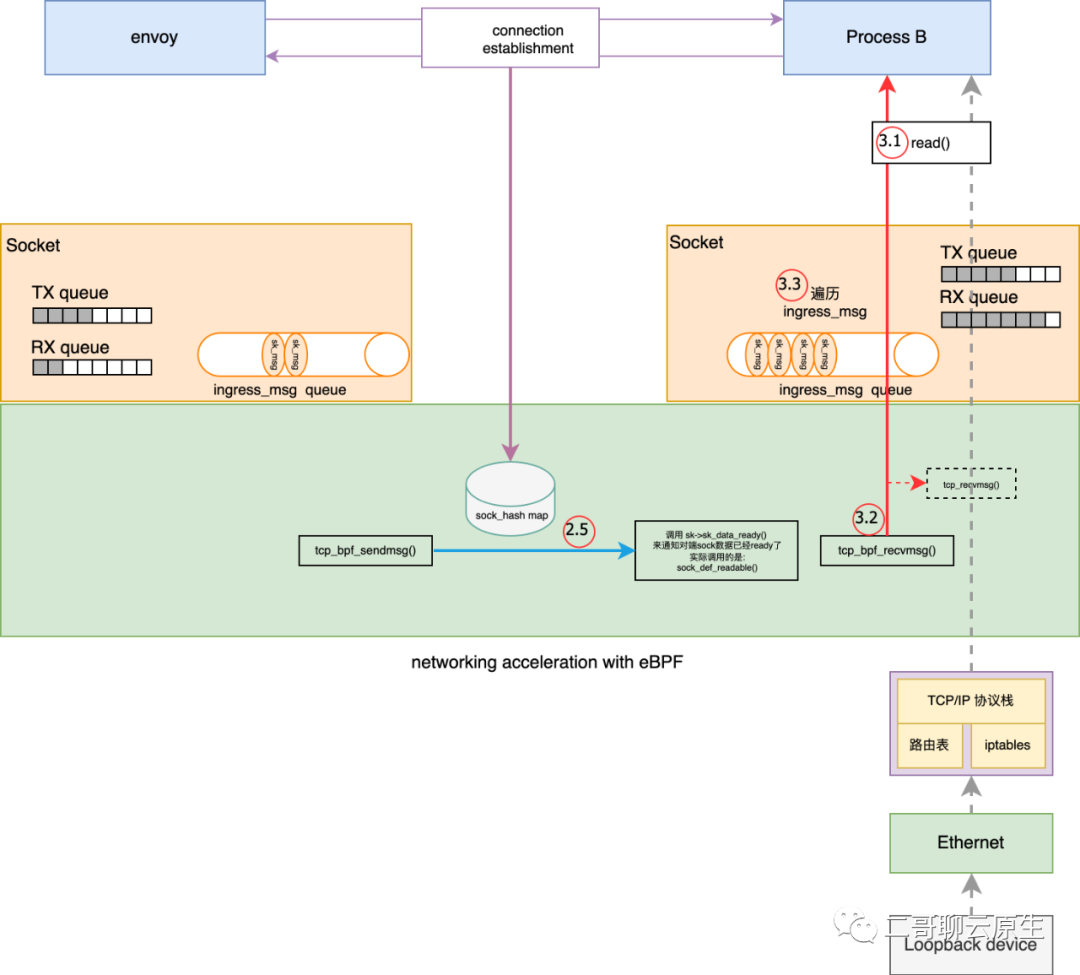 图 6:接收数据流程
图 6:接收数据流程static int tcp_bpf_recvmsg(struct sock *sk, struct msghdr *msg, size_t len,
int nonblock, int flags, int *addr_len)
{
// ...
psock = sk_psock_get(sk);
if (unlikely(!psock))
return tcp_recvmsg(sk, msg, len, nonblock, flags, addr_len);
}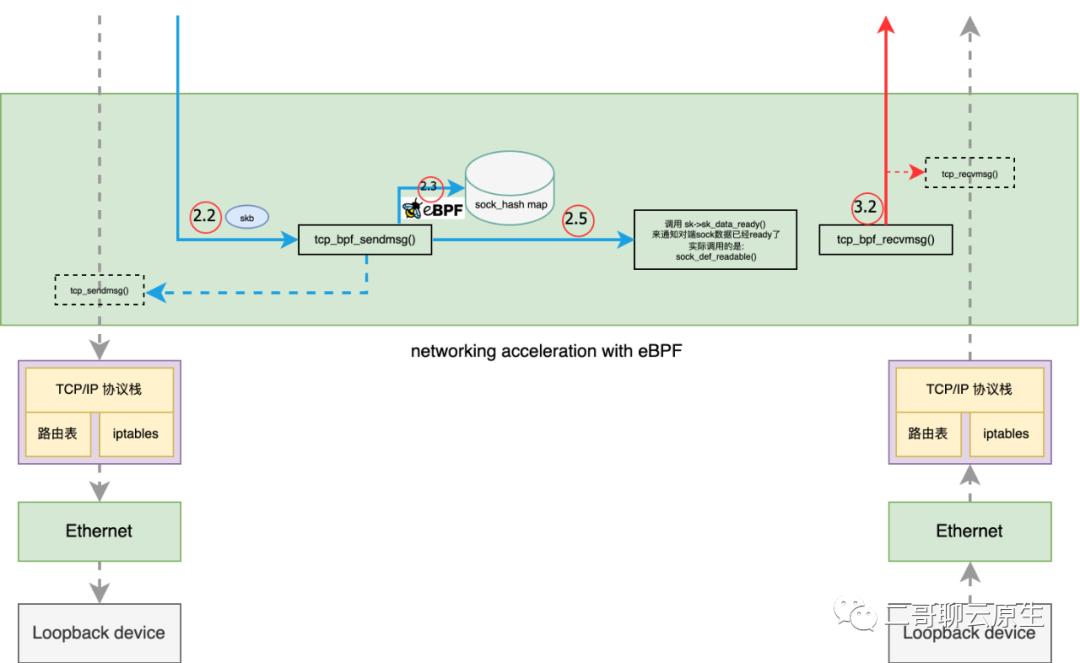 图 7:备胎 tcp_sendmsg() 和 tcp_recvmsg()
图 7:备胎 tcp_sendmsg() 和 tcp_recvmsg()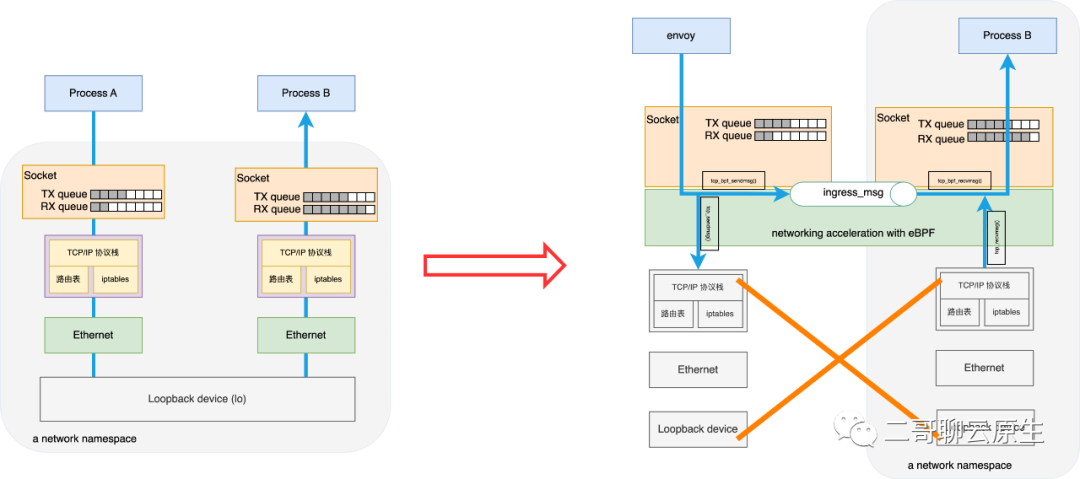 图 8:socket level acceleration讲到这里,我们再来看下本篇所描述的对象:socket level redirection。网络包直接通过一个新的 queue 就发送到对端去了,中间没有经过复杂的 TCP 协议栈,更没有使用到 IP 层的路由表、iptables
等耗时费力的组件。这样做带来了一个非常简单直接和粗暴的好处:socket level acceleration 。也就是说同一个主机上,进程间通信可以通过 socket
level redirection 来使性能得到大幅提升。如果你熟悉基于 sidecar 的 Service Mesh 的话,一定知道一个 Pod 内部存在基于 loopback
的进程间通信。我们也聊过即使通信双方是走的 Loopback 这个虚拟的设备,从而省去了与真实网络设备相关的排队(Queue
Descipline)等待时间,也省去了网络包离开本机后的网络延迟,但网络包在 TCP/IP 协议栈上该走的路可一步都少不了,万一路由表和 iptables
设置得比较复杂,那依旧需要在路由和 net filter 上面花去很多时间。socket level acceleration 的出现可以说完美解决了 sidecar 所面临的网络刚性开销难题。它带来的好处仅仅如此吗?不!socket level acceleration 还有一个厉害的地方:它可以跨 network namespace
传递网络包。这表示假如图 8 里面 envoy 和 Process B 分别处于各自的 network ns 里面,也能充分利用 socket level
acceleration 来完成高性能通信。为了突出这一点,图 8 右侧我把 Process B 所属的 network ns
单独画在了一个灰色框里面。高性能 + 跨 network ns,多么美丽的组合。Cilum 基于它打造出了 sidecarless 的 Service Mesh 。如图 9
所示。注意看哦,图中 Layer 7 的 Proxy 是独立于每个 Pod 的,也是被这个 Work Node 上所有的 Pod 所共享的。
图 8:socket level acceleration讲到这里,我们再来看下本篇所描述的对象:socket level redirection。网络包直接通过一个新的 queue 就发送到对端去了,中间没有经过复杂的 TCP 协议栈,更没有使用到 IP 层的路由表、iptables
等耗时费力的组件。这样做带来了一个非常简单直接和粗暴的好处:socket level acceleration 。也就是说同一个主机上,进程间通信可以通过 socket
level redirection 来使性能得到大幅提升。如果你熟悉基于 sidecar 的 Service Mesh 的话,一定知道一个 Pod 内部存在基于 loopback
的进程间通信。我们也聊过即使通信双方是走的 Loopback 这个虚拟的设备,从而省去了与真实网络设备相关的排队(Queue
Descipline)等待时间,也省去了网络包离开本机后的网络延迟,但网络包在 TCP/IP 协议栈上该走的路可一步都少不了,万一路由表和 iptables
设置得比较复杂,那依旧需要在路由和 net filter 上面花去很多时间。socket level acceleration 的出现可以说完美解决了 sidecar 所面临的网络刚性开销难题。它带来的好处仅仅如此吗?不!socket level acceleration 还有一个厉害的地方:它可以跨 network namespace
传递网络包。这表示假如图 8 里面 envoy 和 Process B 分别处于各自的 network ns 里面,也能充分利用 socket level
acceleration 来完成高性能通信。为了突出这一点,图 8 右侧我把 Process B 所属的 network ns
单独画在了一个灰色框里面。高性能 + 跨 network ns,多么美丽的组合。Cilum 基于它打造出了 sidecarless 的 Service Mesh 。如图 9
所示。注意看哦,图中 Layer 7 的 Proxy 是独立于每个 Pod 的,也是被这个 Work Node 上所有的 Pod 所共享的。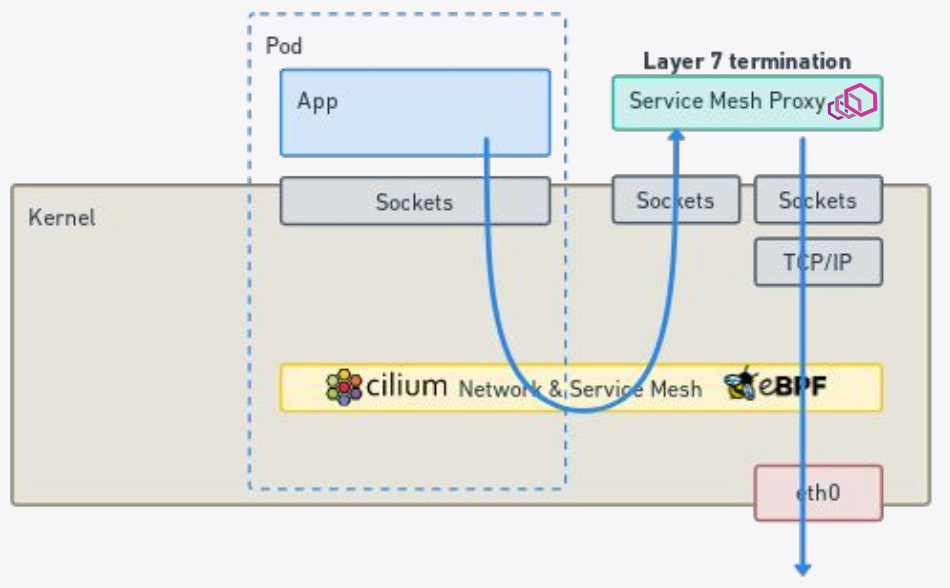 图 9:基于 socket level redirection 所实现的 sidecarless Service Mesh
图 9:基于 socket level redirection 所实现的 sidecarless Service Mesh 我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我想使用spawn(针对多个并发子进程)在Ruby中执行一个外部进程,并将标准输出或标准错误收集到一个字符串中,其方式类似于使用Python的子进程Popen.communicate()可以完成的操作。我尝试将:out/:err重定向到一个新的StringIO对象,但这会生成一个ArgumentError,并且临时重新定义$stdxxx会混淆子进程的输出。 最佳答案 如果你不喜欢popen,这是我的方法:r,w=IO.pipepid=Process.spawn(command,:out=>w,:err=>[:child,:out])
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我目前有一个reddit克隆类型的网站。我正在尝试根据我的用户之前喜欢的帖子推荐帖子。看起来K最近邻或k均值是执行此操作的最佳方法。我似乎无法理解如何实际实现它。我看过一些数学公式(例如k表示维基百科页面),但它们对我来说并没有真正意义。有人可以推荐一些伪代码,或者可以查看的地方,以便我更好地了解如何执行此操作吗? 最佳答案 K最近邻(又名KNN)是一种分类算法。基本上,您采用包含N个项目的训练组并对它们进行分类。如何对它们进行分类完全取决于您的数据,以及您认为该数据的重要分类特征是什么。在您的示例中,这可能是帖子类别、谁发布了该项
我查看了Stripedocumentationonerrors,但我仍然无法正确处理/重定向这些错误。基本上无论发生什么,我都希望他们返回到edit操作(通过edit_profile_path)并向他们显示一条消息(无论成功与否)。我在edit操作上有一个表单,它可以POST到update操作。使用有效的信用卡可以正常工作(费用在Stripe仪表板中)。我正在使用Stripe.js。classExtrasController5000,#amountincents:currency=>"usd",:card=>token,:description=>current_user.email)