最近看书看到的伪共享问题,直接触碰到知识盲区了,之前确实没听说过这个东西,打开百度就像吃饭一样自然。
虽然面经上出现的次数不多,不过我觉得还是很重要的一个问题,而且不难,花个五分钟就能弄清楚~
老规矩,背诵版在文末。公众号【飞天小牛肉】定期更新大厂面试题,提供背诵版和详解版
众所周知,为了缓解内存和 CPU 之间速度不匹配的矛盾,引入了高速缓存这个东西,它的容量比内存小很多,但是交换速度却比内存要快得多。
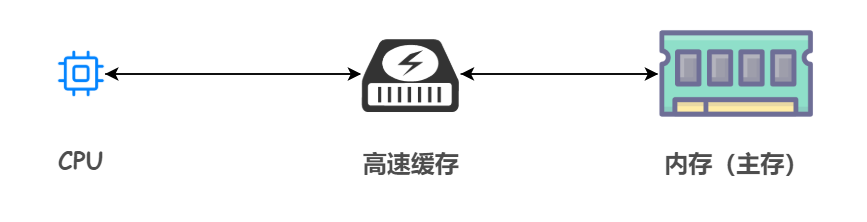
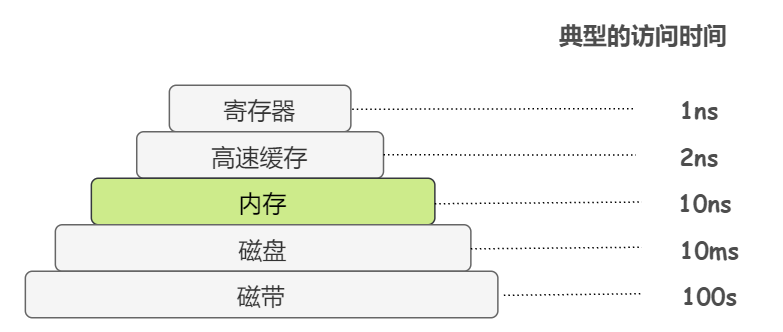
之前我们画过这样的分级存储体系结构:
事实上,高速缓存仍然存在细分,也称为三级缓存结构:一级(L1)缓存、二级(L2)缓存、三级(L3)缓存
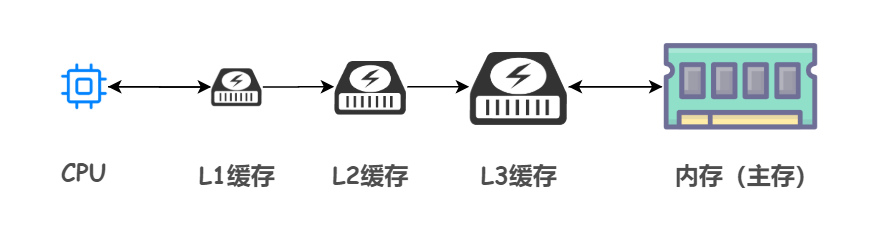
越靠近 CPU 的缓存,速度越快,容量也越小。所以 L1 缓存容量最小但是速度最快;L3 缓存容量最大同时速度也最慢
当 CPU 执行运算的时候,它会先去 L1 缓存查找所需的数据、如果没有找到的话就再去 L2 缓存、然后是 L3 缓存,如果最后这三级缓存中都没有命中,那么 CPU 就要去访问内存了。
显然,CPU 走得越远,运算耗费的时间就越长。所以尽量确保数据存在 L1 缓存中能够提升大计算量情况下的运行速度。
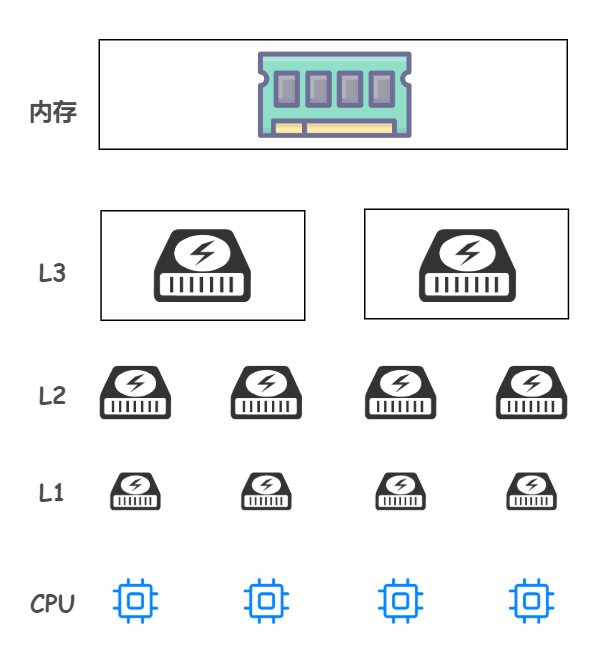
需要注意的是,CPU 和三级缓存以及内存的对应使用关系:
如下图所示:
另外,这三级缓存空间中的数据是如何组织起来的呢?换句话说,数据在这三级缓存中的存储形式是什么样的呢?
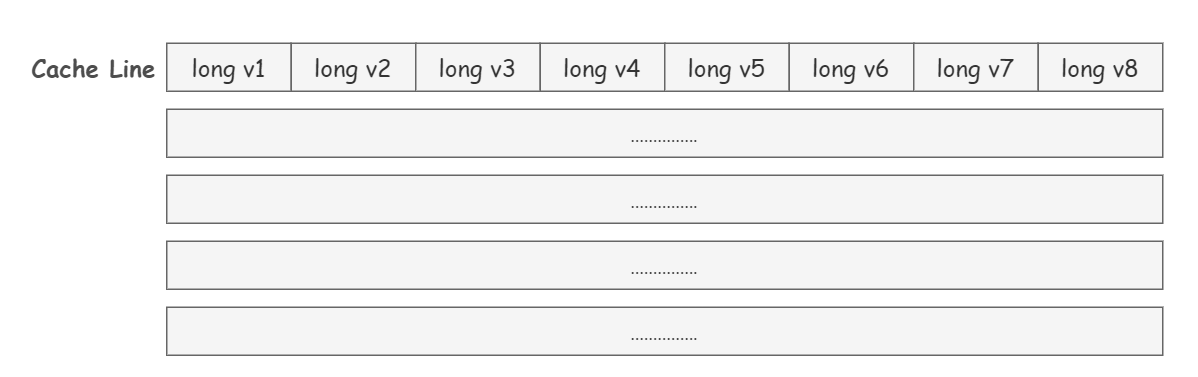
Cache Line(缓存行)!
缓存中的基本存储单元就是 Cache Line。
每个 Cache Line 通常是 64 字节,也就是说,一个 Java 的 long 类型变量是 8 字节,一个 Cache Line 中可以存 8 个 long 类型的变量。
所以小伙伴们看出来了吗~ 缓存中的数据并不是按照一个一个单独的变量这样存储组织起来的,而是多个变量会放到一行中。
说了这么多似乎还并未触及伪共享问题,别急,我们离真相已经很近~
在程序运行的过程中,由于缓存的基本单元 Cache Line 是 64 字节,所以缓存每次更新都会从内存中加载连续的 64 个字节。
如果访问的是一个 long 类型数组的话,当数组中的一个值比如 v1 被加载到缓存中时,接下来地址相邻的 7 个元素也会被加载到缓存中。(这也能解释为啥我们数组总是能够这么快,像链表这种离散存储的数据结构,就无法享受到这种红利)。
But,这波红利很可能带来无妄之灾。
举个例子,如果我们定义了两个 long 类型的变量 a 和 b,他们在内存中的地址是紧挨着的,会出现什么问题?
如果我们想要访问 a 的话,那么 b 也会被存储到缓存中来。
懵了懵了,这有什么问题吗,看起来似乎没有什么毛病,多么 nice 的特性啊
来来来,直接上个例子
回想下上文提到的 CPU 和三级缓存以及内存的对应使用关系,设想这种情况,如果一个 CPU 核心的线程 T1 在对 a 进行修改,另一个 CPU 核心的线程 T2 却在对 b 进行读取。
当 T1 修改 a 的时候,除了把 a 加载到 Cache Line,还会享受一波红利,把 b 同时也加载到 T1 所处 CPU 核心的 Cache Line 中来,对吧。
根据 MESI 缓存一致性协议,修改完 a 后这个 Cache Line 的状态就是 M(Modify,已修改),而其它所有包含 a 的 Cache Line 中的 a 就都不是最新值了,所以都将变为 I 状态(Invalid,无效状态)
这样,当 T2 来读取 b 时,诶,发现他所处的 CPU 核心对应的这个 Cache Line 已经失效了,mmp,它就需要花费比较长的时间从内存中重新加载了。
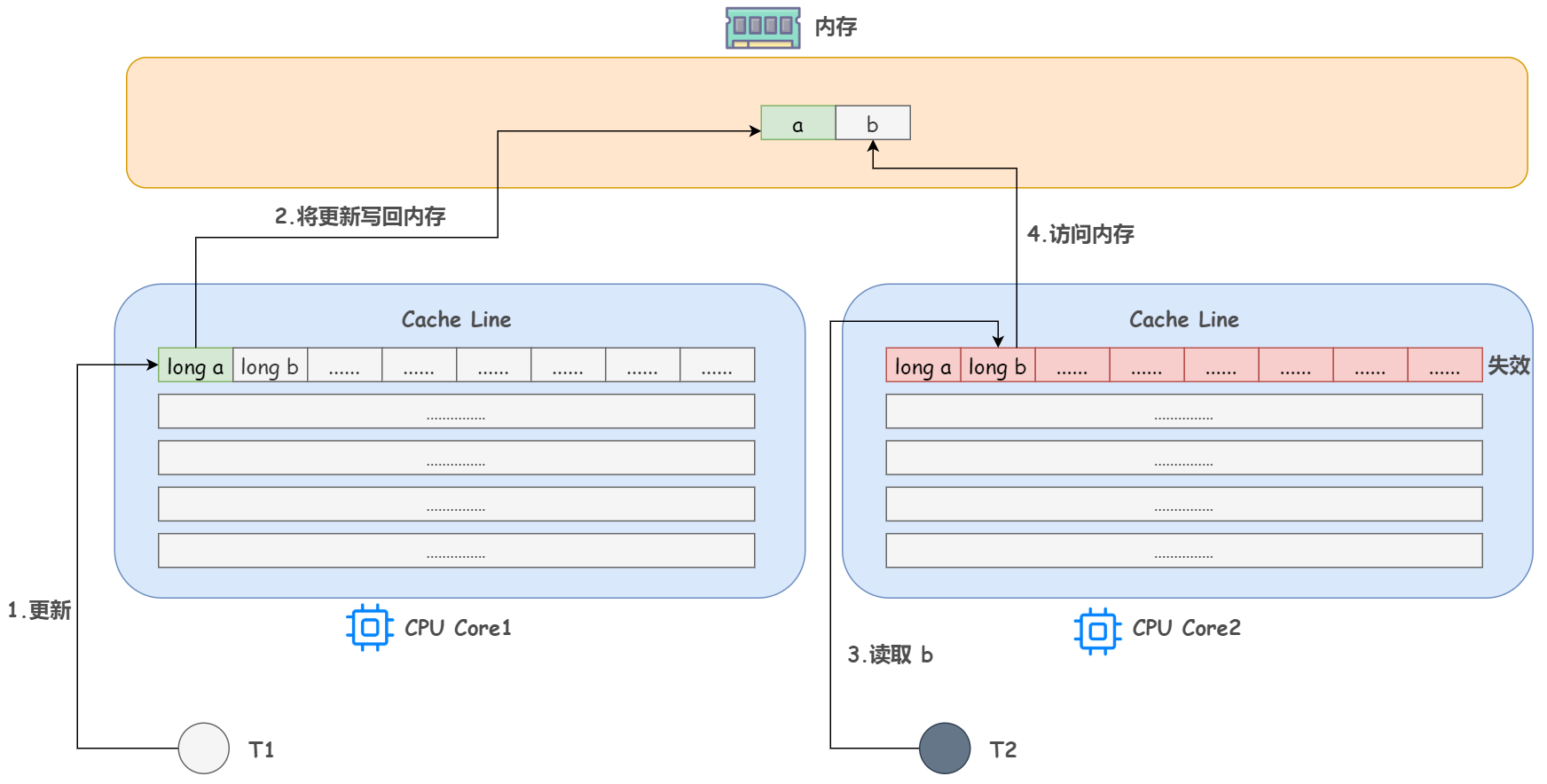
问题已经显而易见了,b 和 a 没有任何关系,每次却要因为 a 的更新导致他需要从内存中重新读取,拖慢了速度。这就是伪共享
表面上 a 和 b 都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
用更书面的解释来定义伪共享:当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,导致无法充分利用缓存行特性,这就是伪共享。
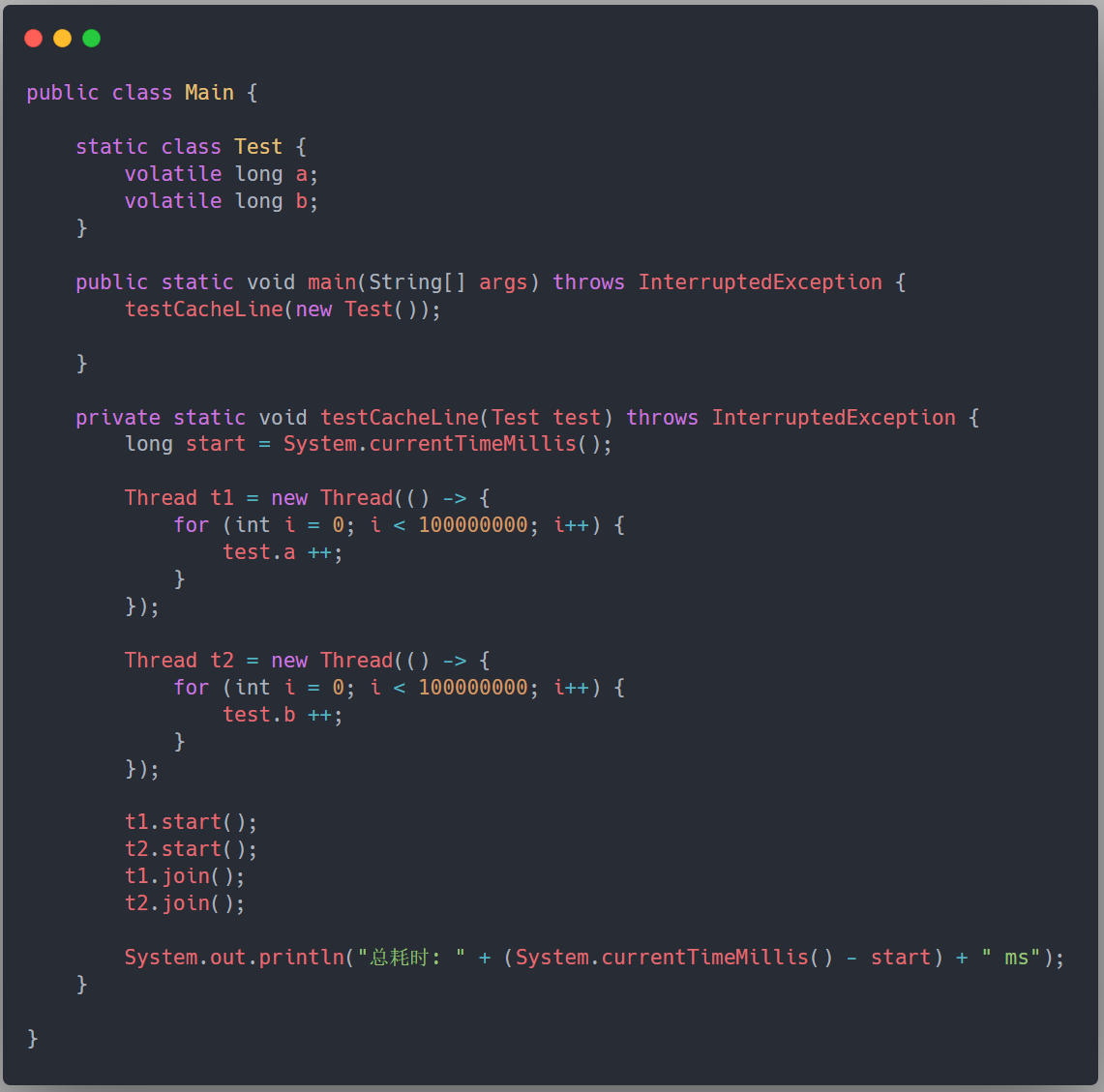
我们先来举个例子看看一段伪共享代码的耗时,如下所示,我们定义一个 Test 类,它包含两个 long 的变量,分别用两个线程对这两个变量进行自增 1 亿次,这段代码耗时 5625ms
对于伪共享,一般有两种方法,其实思想都是一样的:
1)padding:就是增大数组元素之间的间隔,使得不同线程存取的元素位于不同的缓存行上,以空间换时间
上面提到过,一个 64 字节的 Cache Line 中可以存 8 个 long 类型的变量,我们在 a 和 b 这两个 long 类型的变量之间再加 7 个 long 类型,使得 a 和 b 处在不同的 Cache Line 上面:
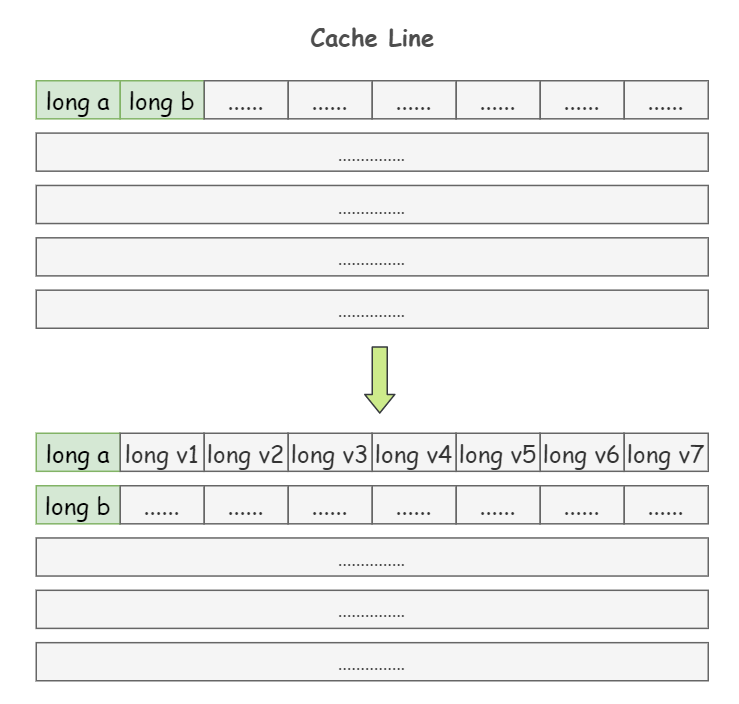
class Pointer {
volatile long a;
long v1, v2, v3, v4, v5, v6, v7;
volatile long b;
}
再次运行程序,会发现输出时间神奇的缩短为了 955ms
2)JDK1.8 提供了 @Contended 注解:就是把我们手动 padding 的操作封装到这个注解里面了,这个注解可以放在类上也可以放在字段上,这里就不多做说明了
class Test {
@Contended
volatile long a; // 填充 a
volatile long b;
}
需要注意的是,默认使用这个注解是无效的,需要在 JVM 启动参数加上 XX:-RestrictContended 才会生效
最后放上这道题的背诵版:
? 面试官:讲一下伪共享问题
? 小牛肉:伪共享问题其实是由于高速缓存的特性引起的,三级高速缓存中的数据并不是一个变量一个变量单独存放的,它的基本存储单元是 Cache Line,一般一个 Cache Line 的大小是 64 字节,也就是说,一个 Cache Line 中可以存下 8 个 8 字节的 long 类型变量
那由于高速缓存的基本单元是 64 字节的 Cache Line,所以呢,缓存从内存中一次读取的数据就是 64 字节。换句话说,如果 cpu 要读取一个 long 类型的数组,读取其中一个元素的同时也会把接下来的其他相邻地址的七个元素也加载到 Cache Line 中来。
这就会导致一个问题,举个例子,我们定义了两个
long类型的变量 a 和 b,他们没有关系,但是他们在内存中的地址是紧挨着的,如果一个 CPU 核心的线程 T1 在对 a 进行修改,另一个 CPU 核心的线程 T2 却在对 b 进行读取。那么当 T1 修改 a 的时候,除了把 a 加载到 Cache Line,还会把 b 同时也加载到 T1 所处 CPU 核心的 Cache Line 中来,对吧。
根据 MESI 缓存一致性协议,修改完 a 后这个 Cache Line 的状态就是 M(Modify,已修改),而其它所有包含 a 的 Cache Line 中的 a 就都不是最新值了,所以都将变为 I 状态(Invalid,无效状态)
这样,当 T2 来读取 b 时,他就会发现,他所处的 CPU 核心对应的这个 Cache Line 已经失效了,这样他就需要花费比较长的时间从内存中重新加载了。
也就是说,b 和 a 没有任何关系,每次却要因为 a 的更新导致他需要从内存中重新读取,拖慢了速度。这就是伪共享
对于伪共享,一般有两种方法,其实思想都是一样的:
1)padding:就是增大数组元素之间的间隔,使得不同线程存取的元素位于不同的缓存行上,以空间换时间。比如在 a 和 b 之间再定义 7 个 long 类型的变量,使得 a 和 b 不在一个 Cache Line 上,这样当修改 a 的时候 b 所处的 Cache Line 就不会受到影响了
2)JDK 1.8 提供了
@Contended注解,就是把我们手动 padding 的操作封装到这个注解里面了,把这个注解加在字段 a 或者 b 的上面就可以了
大家好,我是小牛肉~ 如果觉得这篇文章有用的话请一键三连呀,我的公众号【飞天小牛肉】定期更新大厂面试题,提供背诵版和详解版
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
在许多ruby类之间共享记录器实例的最佳(正确)方法是什么?现在我只是将记录器创建为全局$logger=Logger.new变量,但我觉得有更好的方法可以在不使用全局变量的情况下执行此操作。如果我有以下内容:moduleFooclassAclassBclassC...classZend在所有类之间共享记录器实例的最佳方式是什么?我是以某种方式在Foo模块中声明/创建记录器还是只是使用全局$logger没问题? 最佳答案 在模块中添加常量:moduleFooLogger=Logger.newclassAclassBclassC..
在我的路线文件中我有:match'graphs/(:id(/:action))'=>'graphs#(:action)'如果是GET请求(工作)或POST请求(不工作),我想匹配它我知道我可以使用以下方法在资源中声明POST请求:post'/'=>:show,:on=>:member但是我怎样才能为比赛做到这一点呢?谢谢。 最佳答案 如果你同时想要POST和GETmatch'graphs/(:id(/:action))'=>'graphs#(:action)',:via=>[:get,:post]编辑默认值可以设置如下match'g
我有一个功能“从外部网站导入文章”。在我的第一个场景中,我测试从外部网站导入链接列表。Feature:ImportingarticlesfromexternalwebsiteScenario:Searchingarticlesonexample.comandreturnthelinksGiventhereisanImporterAnditsURLis"http://example.com"Whenwesearchfor"demo"ThentheImportershouldreturn25linksAndoneofthelinksshouldbe"http://example.com/d
假设我有:get'/'do$random=Random.rand()response.body=$randomend如果我每秒有数千个请求到达/,$random是否会被共享并“泄漏”到上下文之外,或者它会像getblock的“本地”变量一样?我想如果它是在get'/'do的上下文之外定义的,它确实会被共享,但我想知道在ruby中是否有我不知道的$机制。 最佳答案 ThispartoftheSinatraREADMEaboutscopeisalwayshelpfultoread但是,如果您只需要为请求保留变量,那么我认为我建议使用
我想从不同线程调用一个公共(public)枚举器。当我执行以下操作时,enum=(0..1000).to_enumt1=Thread.newdopenum.nextsleep(1)endt2=Thread.newdopenum.nextsleep(1)endt1.joint2.join它引发了一个错误:Fibercalledacrossthreads.当enum在从t1调用一次后从t2调用时。为什么Ruby设计为不允许跨线程调用枚举器(或纤程),以及是否有其他方法可以提供类似的功能?我猜测枚举器/纤程上的操作的原子性在这里是相关的,但我不完全确定。如果这是问题所在,那么在使用时独占锁定
当我打电话时:require'retryable'这两个gem冲突:https://github.com/robertsosinski/retryablehttps://github.com/carlo/retryable因为他们都有一个“可重试”文件,所以他们要求用户要求。我对使用第一个gem很感兴趣,但这并不总是会发生。这段代码作为我自己的gem的一部分执行,它必须对所有用户都是可靠的。有没有办法从gem中专门要求(因为gem名称当然不同)?如何解决这个命名冲突?编辑:澄清一下,这是官方仓库,gem名称实际上是不同的(“retryable-rb”和“carlo-retryable”