鲲鹏生态
什么是鲲鹏,芯片。
围绕鲲鹏处理器(主要就是计算)延伸出来各种基于鲲鹏处理器的行业。
鲲鹏计算产业是基于鲲鹏处理器构建的全栈IT基础设施、行业应用及服务、包括PC服务存储 操作系统 中简介 虚拟化 数据库 云服务 行业应用以及咨询管理服务。
鲲鹏计算产业生态产业链
芯片能力积累到 芯片技术创新 芯片架构创新
华为云鲲鹏云服务典型应用场景:
大数据 :
分布式存储:把一个文件分开放,不同文件,不同硬盘,不同PC
数据库 :分布式数据库 与分布式存储密切相关
原生应用:借助与云原生,云上编写,部署。
云服务:原生算力。
初始云服务:
云计算是一种模型,他可以实现随时随地,便捷的,随需应变地从可配置计算资源共享池中获取所需的资源(例如 网络、服务器
、存储、应用、及服务)。资源能够快速供应并释放。是管理资源的工作量和与服务提供商的交互减小最低限度
云计算的五大基本特征
按需自主服务:定制服务 ,订制资源。 广泛网络接入方式:支持手机接入也可以PC 资源池化:池化,弹性伸缩, 快速弹性伸缩: 可计量服务:
云计算发展阶段:
云计算和云服务: 云计算是为了云服务而存在,有了计算才有了服务。
私有云:企业利用自用自由或租用的基础设施资源自建的云。
共有云:为特地给社区或行业所构建的共享基础设施的云
混合云:有两种或两种以上部署模式组成的云 (公司有一定实力,具有私有云的安全性技术,)。
鲲鹏云服务重点云迁移技术优势:
应用和数据的多样性需要新的计算架构。 数据量越来越大,维度越来越广, 以前是PC机,服务器。现在各种电子设备都需要进行计算。数据倒逼硬件的改变。
整形计算 文本处理 大数据分析。 浮点计算 科学计算 视频处理。
对这些的要求越来越高,计算能力也要求越来越多。倒退到底层的优化。
目前超过百分之九十的移动端用的ARM架构处理器IOT AI 和业务云化的发展,华为鲲鹏处理器基于ARM架构。

ARM优点并行数据的能力。大数据要求更多的并发能力。开放的授权策略,众多供应商。
鲲鹏计算产业优势
以中国市场孵化和完善行业应用,与全球产业形成良性循环 和ARM共享优势生态,协同加速发展。
在5g大数据 鲲鹏云计算采用轻核众核 64个内核 适合大数据的处理,分部署存储,有了大数据,颠覆了数据的存储方式。数据库: 存储特性:
鲲鹏计算产业:围绕鲲鹏算力,推出了一系列处理器产品。
算、存、传(集群处理能力)、管、智(AI 大数据的最终应用就是AI)
云迁移核心技术
计算技术栈与程序执行过程 ,迁移的主要原因。(了解之后,更容易理解迁移。)
软硬件技术栈。
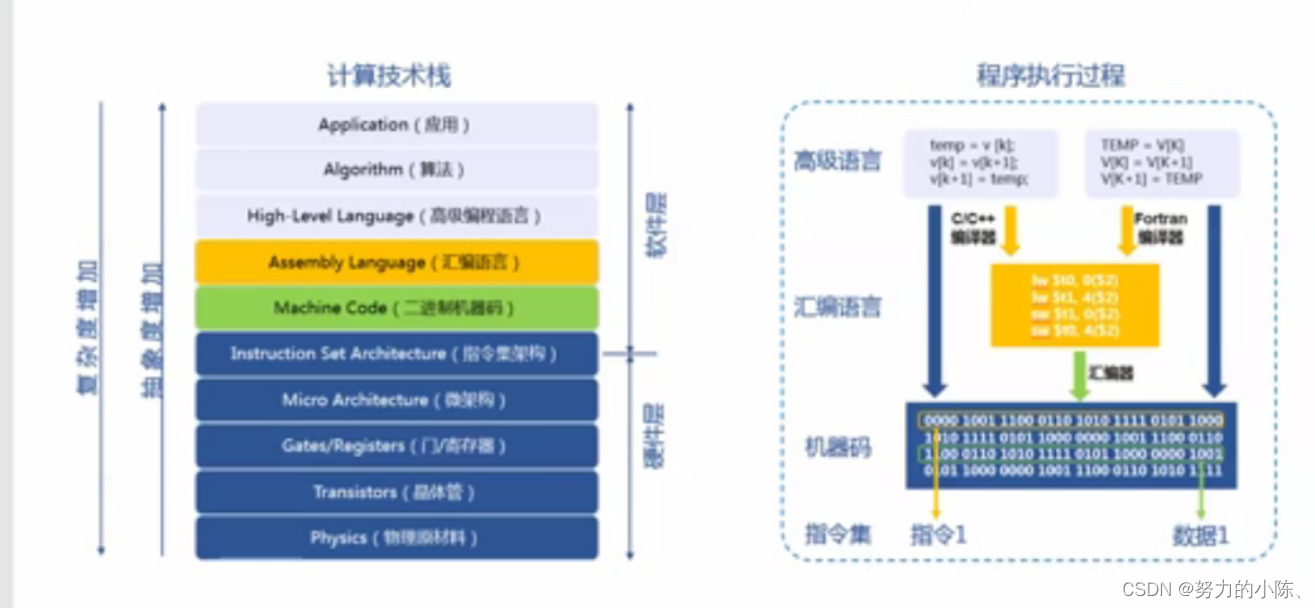
半导 硅,利用光刻机 刻出最小的单元构成电路。一切计算机的基础。
之后是门电路和寄存器: 非与或门 累加器 。
门电路和寄存器再度整合形成架构(V架构,每一个架构设计都不会是相同的,如果相同,那么一定是一方在抄袭对方。)V架构之上让人类和计算机都能读懂的语言,指令集架构。 指令集架构因为V架构的不同而不同。
二进制机器码
汇编语言
Java 和 Python解释性语言
高级语言 C语言操作很多硬件, java和Python要调用库和中间件才能对硬件控制。
不同的CPU架构,指令集架构就不一样。要移植那他的CPU架构不同,指令集架构也就不一样。之上的所有都要进行改变。
形成一定
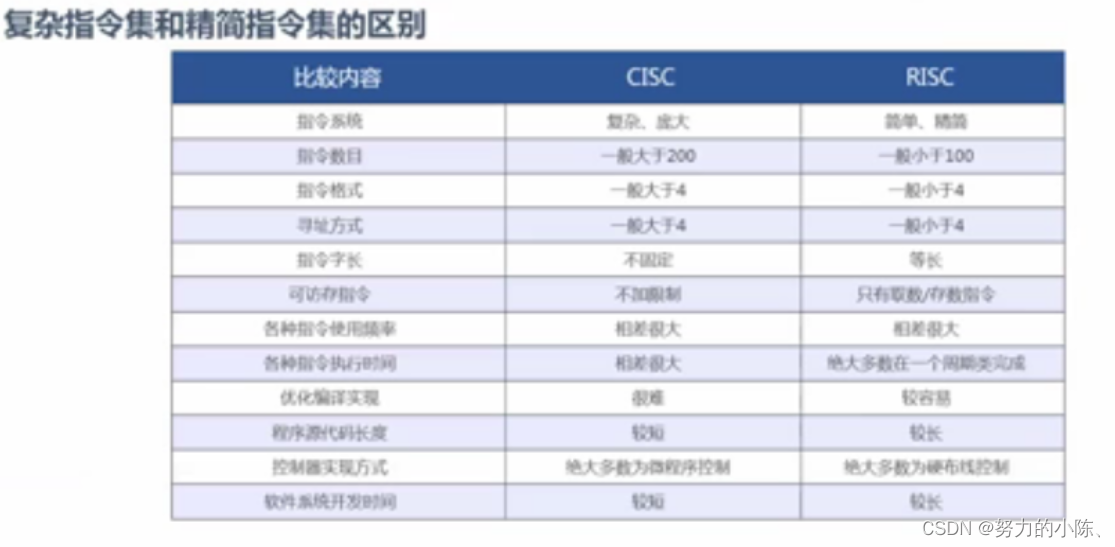
鲲鹏处理去与X86处理器的指令差异:
什么是指令集:CPU中用来计算和控制计算机系统的一套指令的集合,每一种新型的CPU在设计时就规定了一系列与卡硬件电路相配合的指令系统。
鲲鹏架构指令集 V8
与X86处理器的指令差异:
复杂指令集CISC, 按顺序特定执行 Intel
和精简指令集RISC。
CISC要多一步判断指令集的长度
复杂指令集: 按顺序执行 ,执行数据要
复杂指令集的缺点:
二八定律: 写的代码 八十的代码 执行的时候占有
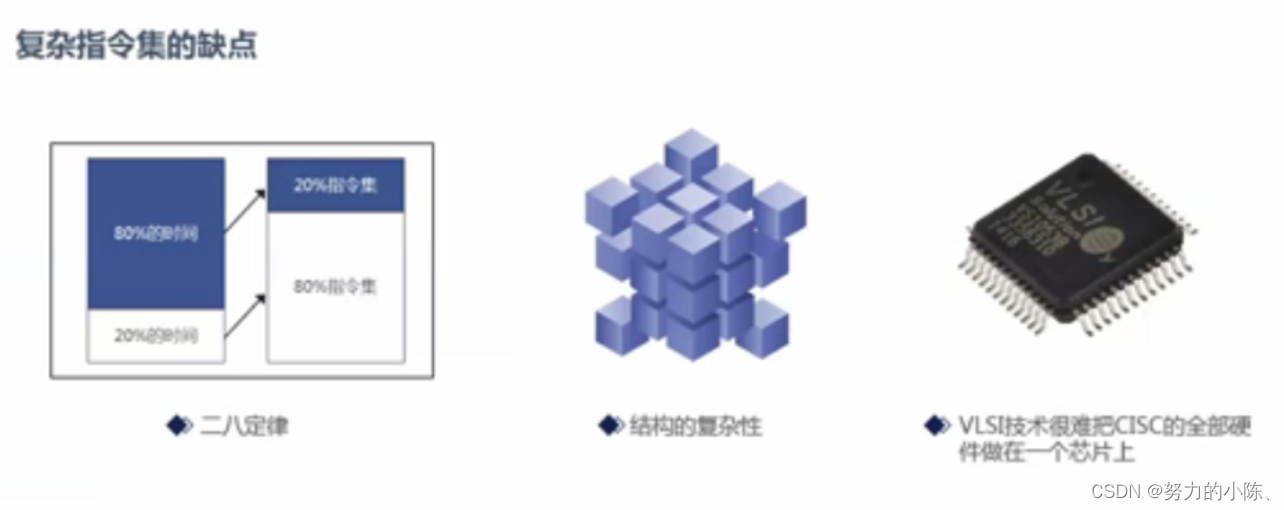
精简指令集:微处理器
流水线: 产品加工流水线(分担工作,吞吐量增加,效率更高,复杂程序拆分。)
性价比最好的拆分

各有优缺
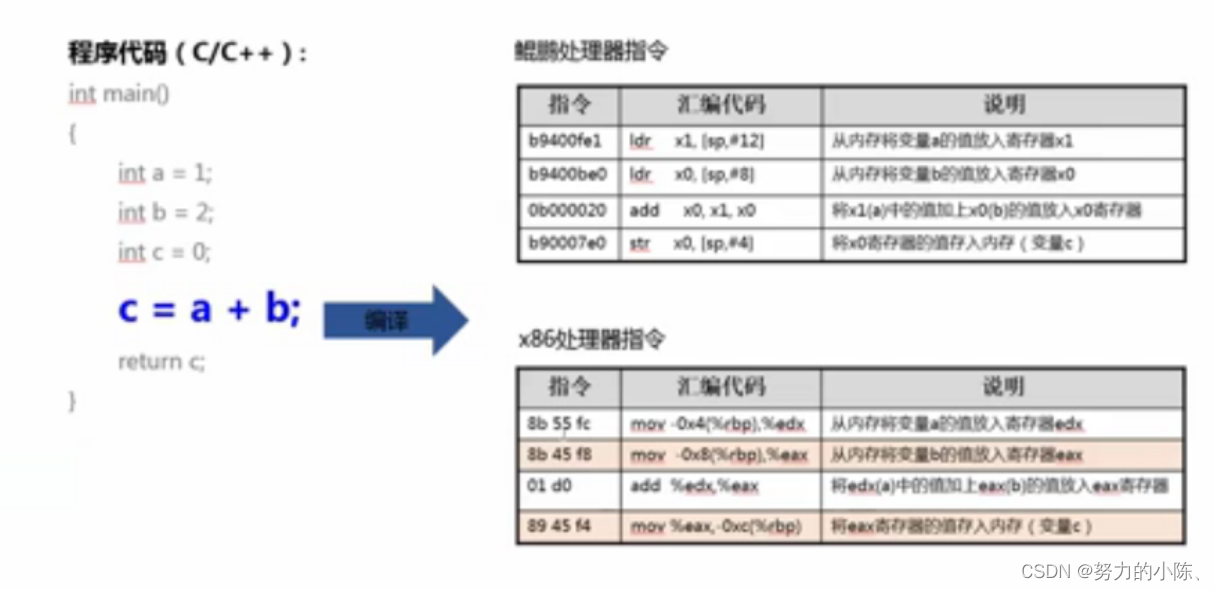
鲲鹏长度固定,ARM汇编语言。(编译原理) 黑客程序 特别精通汇编语言
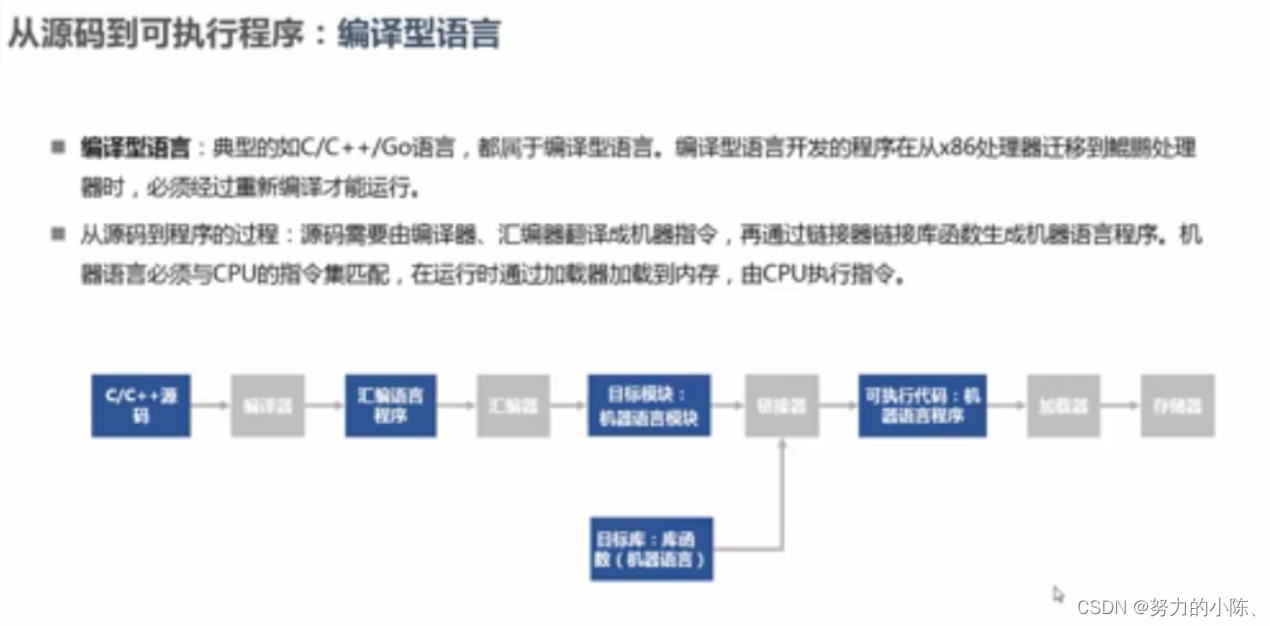
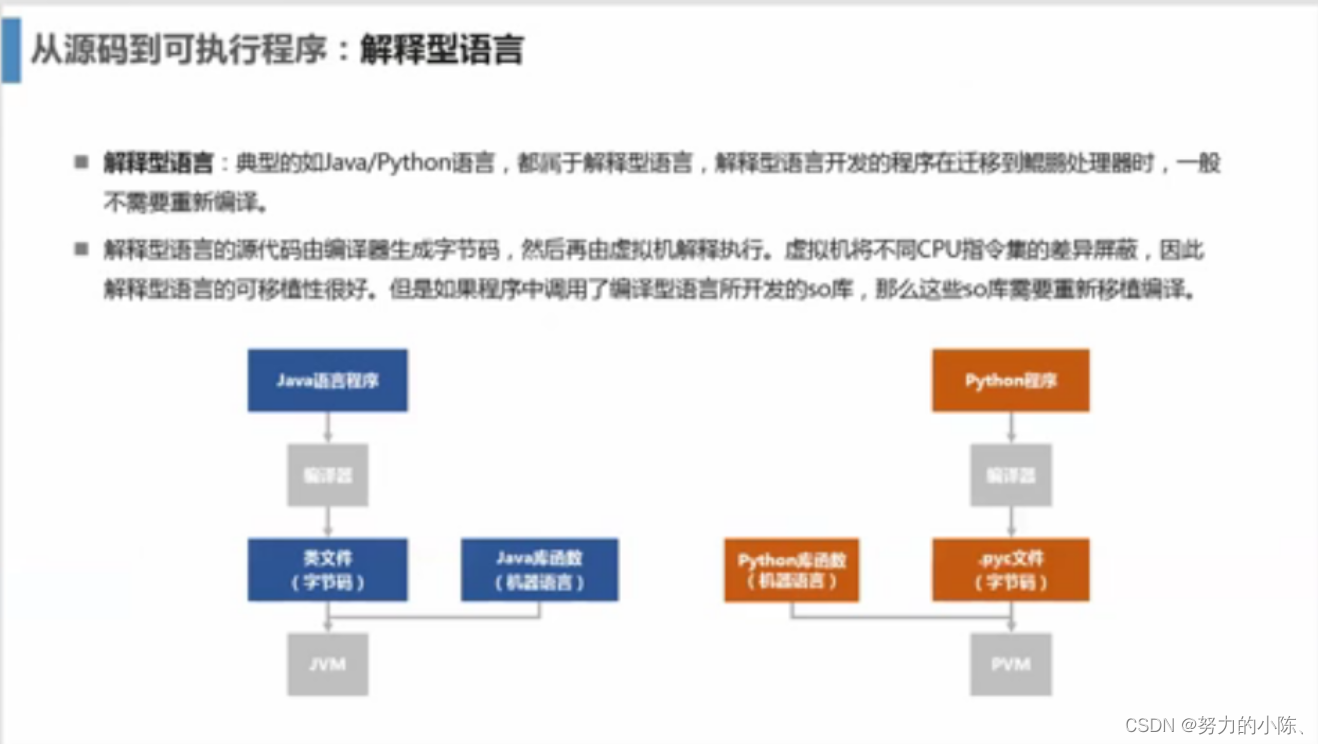
从源码到可执行程序:编译型语言和解释性语言
程序控制权不同: 解释型语言解释器上,编译型语言在程序中。
运行速度不同:编译型语言多一个编译,就是在运行的过程中要进行编译,所以要
移植性不同:解释性语言一致性够高,环境搭好就可以运行。编译性语言:不存在移植的问题
迁移策略的选择
X86平台把项目迁移到鲲鹏平台:
你的项目应用程序是以什么语言编写的(自己写的) 用到第三方软件,有没有适配鲲鹏的第三方的编程软件。
第一个维度 自己重构,自己写的代码。考虑是编译性语言还是解释性语言(是否有编译性语言的库呢?有的话是有源代码)。迁移工具,来做移植。
第二个维度 商用的闭源软件,不适用鲲鹏平台,不可以移植。
第三度维度 是LInux还是Windows,如果是Linux支持,Windows目前还不是很支持。 (未来适配性还会越来越好,)
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
如何正确创建Rails迁移,以便将表更改为MySQL中的MyISAM?目前是InnoDB。运行原始执行语句会更改表,但它不会更新db/schema.rb,因此当在测试环境中重新创建表时,它会返回到InnoDB并且我的全文搜索失败。我如何着手更改/添加迁移,以便将现有表修改为MyISAM并更新schema.rb,以便我的数据库和相应的测试数据库得到相应更新? 最佳答案 我没有找到执行此操作的好方法。您可以像有人建议的那样更改您的schema.rb,然后运行:rakedb:schema:load,但是,这将覆盖您的数据。我的做法是(假设
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------