链接:141. 环形链表
描述:
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。**注意:pos 不作为参数进行传递 。仅仅 是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例1:
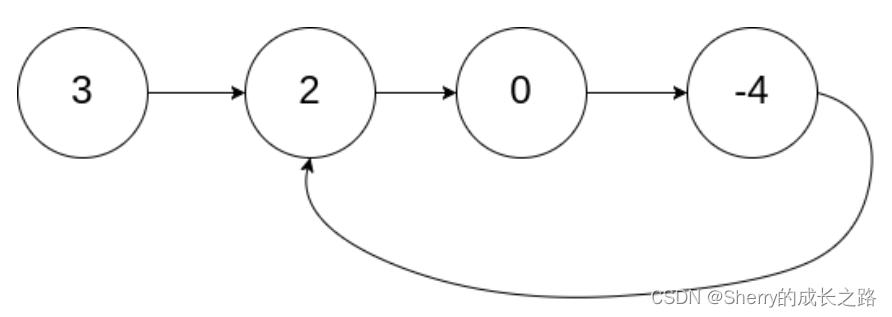
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例2::
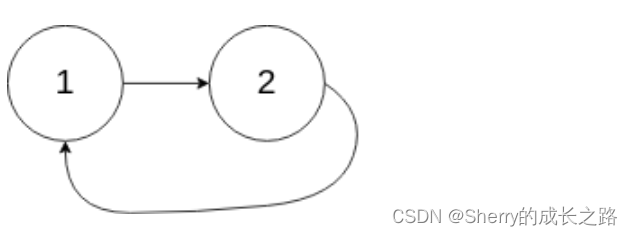
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例3:
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。

提示:
链表中节点的数目范围是 [0, 10^4]
-10^5 <= Node.val <= 105
pos 为 -1 或者链表中的一个 有效索引 。
做这道题目之前我们需要明确一点 不能遍历链表,因为链表带环。
链表带环是指链表的某个节点中存储的地址为这个节点前的某个节点的地址。而导致闭环 ,使遍历链表时无法停止,走不到空,无法停止。
所以我们这道题目采用的方法是快慢指针,好巧,又是快慢指针(bushi)
总体思路是 快指针走两步,慢指针走一步。给定快指针 fast ,慢指针 slow ,初始值为链表的头。设入环前的距离为 x 。当 slow 走了 x/2 时,fast 入环。fast 走了一段路程后,slow 入环,fast 开始追击 slow,最后 fast 和 slow 相遇。
而这里面的走法,和之前的一篇博客中,求链表的中间节点的方法一样。奇数节点走到最后一个节点,偶数节点走到空。如果走到这两个条件,说明链表一定不带环。否则不会走到空,它们一定会相遇,为环形链表。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head)
{
struct ListNode *fast,*slow;
fast=slow=head;
while(fast&&fast->next)
{
slow=slow->next;
fast=fast->next->next;
if(fast==slow)
{
return true;
}
}
return false;
}
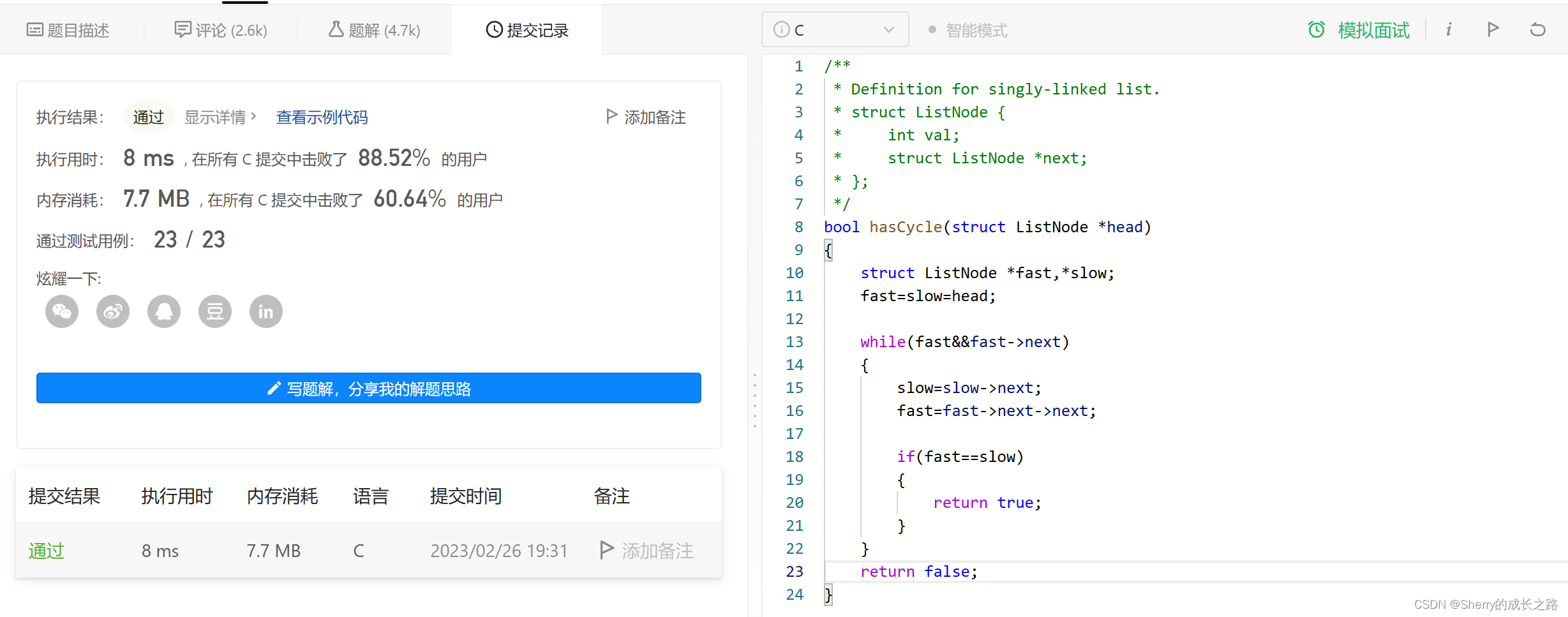
“为什么 slow 和 fast 指针一定会在环中相遇?会不会错过,永远追不上?请证明一下?”
一:slow 和 fast ,fast 一定是先进环。这时 slow 走了入环前距离的一半。
二:随着 slow 进环,fast 已经在环里走了一段了。走了多少跟环的大小有关。
假设 slow 进环时,slow 和 fast 的距离是 N。N 的长度一定小于环。fast 开始追 slow ,slow 每次往前走 1 步,fast 往前走 2 步。每追一次,判断一下是否相遇。
每追 1 次,fast 和 slow 的距离变化:N -> N - 1 -> N - 2 … 1 -> 0.
N
N - 1
N - 2
N - 3
…
1
0
可以追上
每追 1 次,距离减少 1 。它们最后的距离减到 0 时,就是相遇点。
总结 快指针走两步一定会追到慢指针
“为什么 slow 走一步,fast 走两步?能不能 fast 一次走 n 步 (n > 2) ?请证明一下?”
假设我们 slow 走一步,fast 走三步。
它们之间的 距离变化 如下:
N 是偶数 N 是奇数
N N
N - 2 N - 2
N - 4 N - 4
N - 6 N - 6
… …
2 1
0 -1
可以追上 这一次追不上
注意: N 是 fast 和 slow 之间的距离。
如果 fast 走 3 步, slow 走 1 步,一个周期是肯定追不上的。走到最后它们之间的距离变为 -1 ,意味着现在 fast 在 slow 前面一步,它们之间的距离变为 c - 1 。(c 是环的长度)
而长度一旦为 c-1 就有会引申出两种情况,看下图:
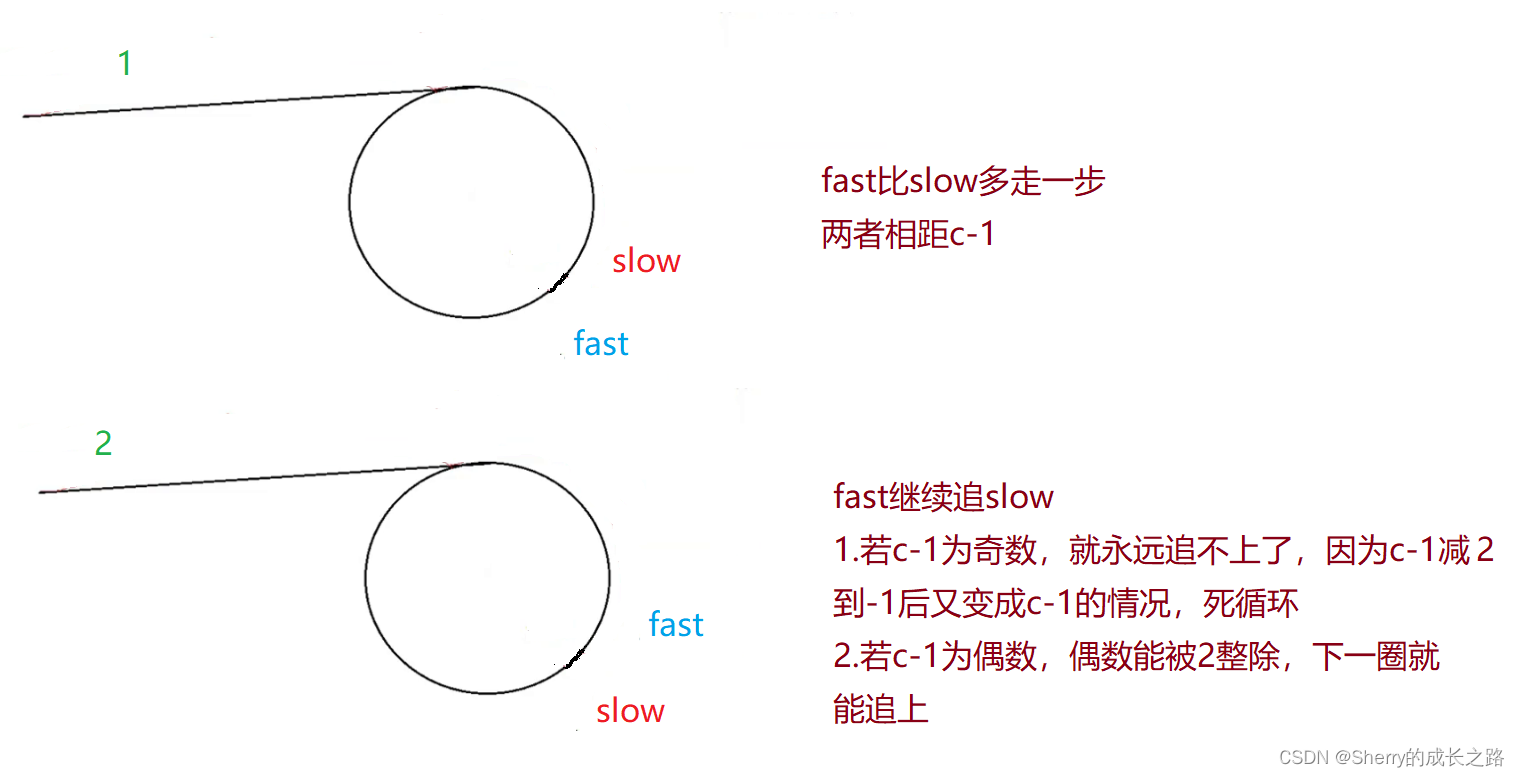
我们这里已经 初步证明 了当 fast 一次走 n(n > 2) 步时,fast 是不一定可以追上 slow 的。
假设 fast 一次走 4 步,slow 一次走 1 步。
N 是 3 的倍数 N 不是 3 的倍数(N是 1 的倍数) N 不是 3 的倍数(N 是 2 的倍数)
N N N
N - 3 N - 3 N - 3
N - 6 N - 6 N - 6
N - 9 N - 9 N - 9
… … …
3 2 1
0 -1 -2
可以追上 这一次追不上 这一次追不上
假设 c 是环的长度。
-1 意味着距离是 c - 1,-2 意味着距离是 c - 2。
如果 c - 1 和 c - 2 是 3 的倍数就可以追上,否则就追不上。
结论:fast 走 2 步,slow 一定可以追上,因为它们的距离逐次减 1 。但是当 n > 2 时,不一定会相遇。
链接:142. 环形链表 II
描述:
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
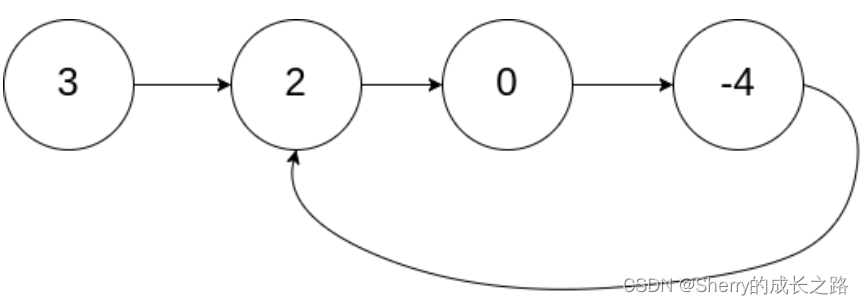
示例1:
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
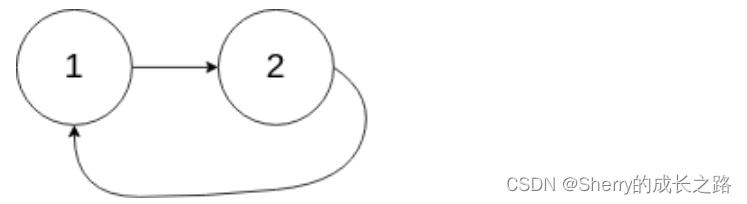
示例2:
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。

示例3:
输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
提示:
链表中节点的数目范围在范围 [0, 10^4] 内
-10^5 <= Node.val <= 10^5
pos 的值为 -1 或者链表中的一个有效索引
既然是要求 链表的入环点,那么用 环形链表 的方法找到 交点 ,在之前的一篇博客里,有个叫做 相交链表 的问题,我把这个 入环的第一个节点 看作是 两个相交链表的尾结点 ,把起始点和相遇点的下一个节点分别作为两链表的头节点,就转换成了链表相交的问题,于是又一次运用了 快慢指针。
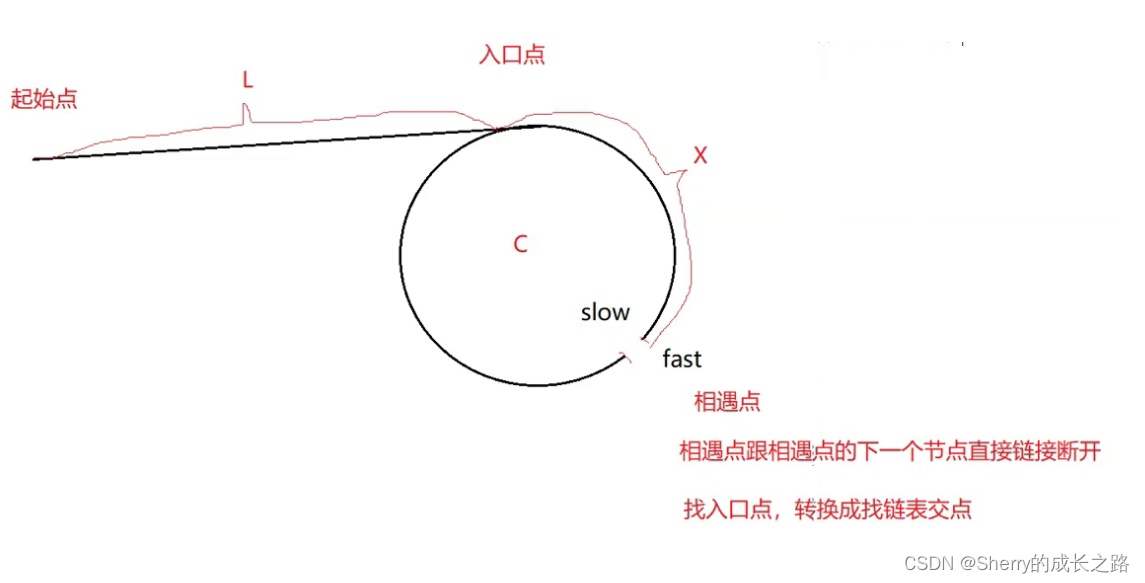
先利用 快慢指针 ,以 环形链表 的解法,找到 fast 和 slow 相交的点。然后将这个 交点 给为 meetnode 。作为两条新链表的尾。那么 meetnode->next 为某条新链表的头。然后 入环点 ,就可以看做是两条链表的交点。然后就是 相交链表 的做法
代码:
struct ListNode *detectCycle(struct ListNode *head)
{
struct ListNode* fast, *slow;
fast = slow = head;
struct ListNode* tail = NULL;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
// 相遇
if (fast == slow)
{
tail = slow;
break;
}
}
// 没有相遇
if (tail == NULL)
{
return NULL;
}
struct ListNode* newHead = tail->next;
int lenH = 1, lenN = 1;
struct ListNode* curH = head, *curN = newHead;
while (curH != tail)
{
lenH++;//L+X
curH = curH->next;
}
while (curN != tail)
{
lenN++;//C
curN = curN->next;
}
struct ListNode* longList = lenH > lenN ? head : newHead;
struct ListNode* shortList = lenH > lenN ? newHead : head;
int gap = abs(lenH - lenN);
while (gap--)//让长的先走相差步数
{
longList = longList->next;
}
while (longList != shortList)
{
longList = longList->next;
shortList = shortList->next;
}
return longList;
}
这个方法的难点在于公式推导的过程,只要推导出了公式,解题就变得十分简单
结论:一个指针从 相遇点 开始走,一个指针从 链表头 开始走,它们会在 环的入口点 相遇。”
接下来推导公式:
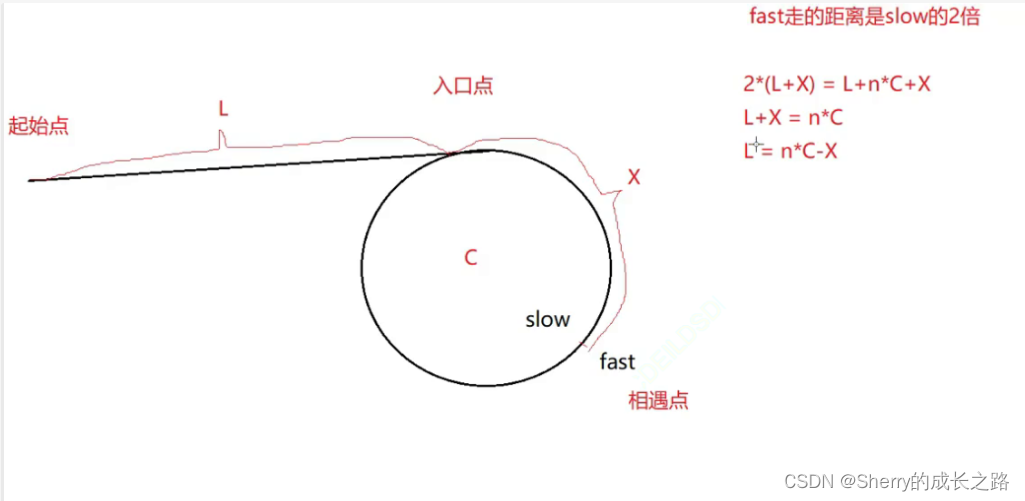
由于 fast 的速度是 slow 的 2 倍。
所以便可以得出这个式子:2 ( L + x ) = L + N * c + x,而这个式子又可以进行推导:
2 ( L + x ) = L + N * c + x
↓
L + x = N * c
↓
L = N * c - x
↓
L = ( N - 1 ) * c + c - x
这里 公式已经推导 完成:L = ( N - 1 ) * c + c - x 。但是这个公式到底是什么意思?
意思是一个指针从起始点开始走,一个指针从相遇点开始走,它们会在环的入口点相遇
根据这个我们也就可以做出这道题目了。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *detectCycle(struct ListNode *head)
{
struct ListNode *fast,*slow;
fast=slow=head;
struct ListNode*tail=NULL;
while(fast&&fast->next)
{
slow=slow->next;
fast=fast->next->next;
if(fast==slow)
{
struct ListNode *meetNode=slow;
while(meetNode!=head)
{
head=head->next;
meetNode=meetNode->next;
}
return meetNode;
}
}
return NULL;
}
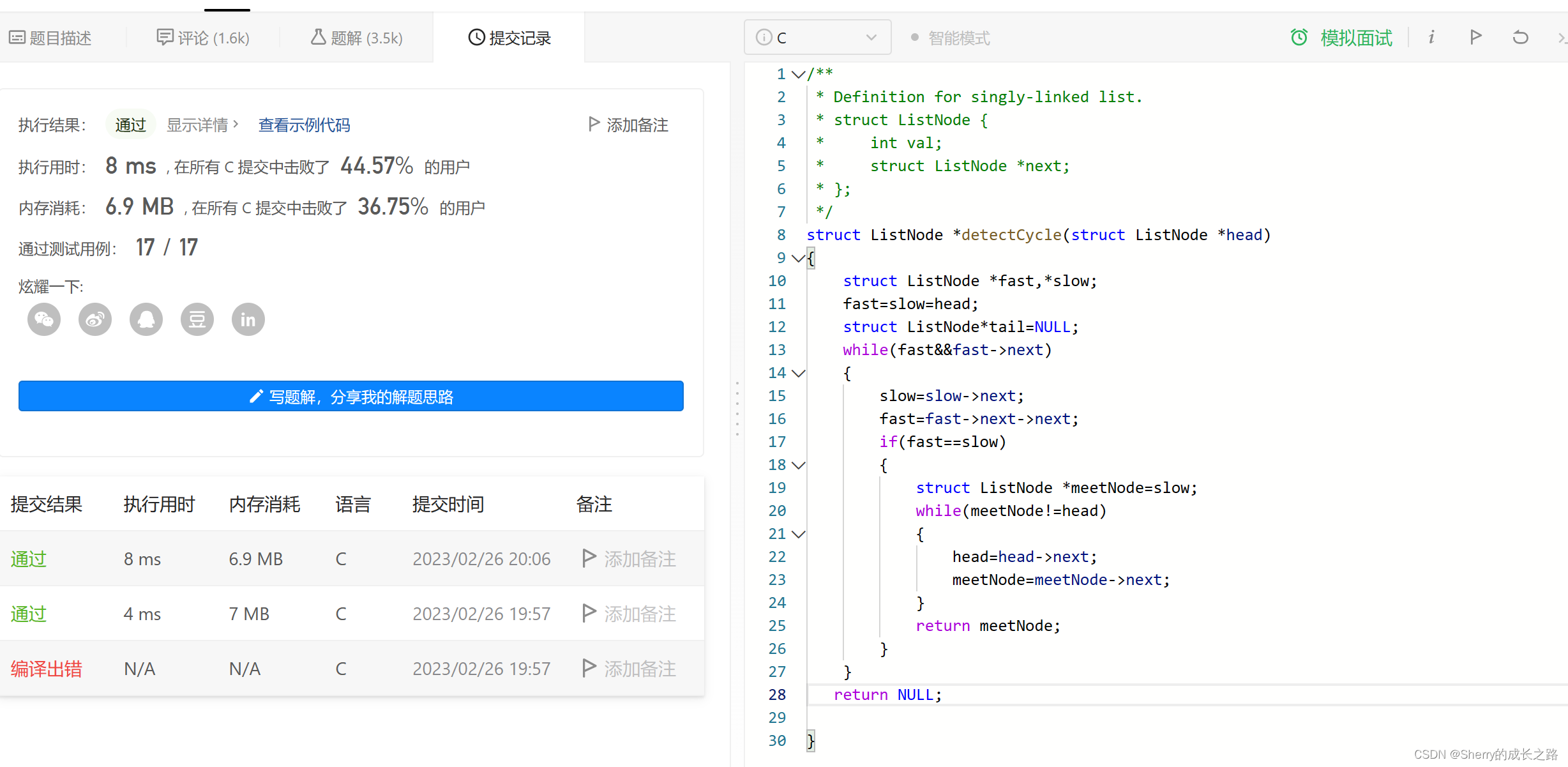
描述:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random -> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random -> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。

示例1:
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例2:
输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例3:
输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000
-10^4 <= Node.val <= 10^4
Node.random 为 null 或指向链表中的节点。
通过分析,这个链表结构应含有 三个成员 :
struct Node
{
int val;
struct Node* next; // 下一个节点的地址
struct Node* random; // 指向随机节点的指针
};
看到复制两字,可能会想:“这不是只要复制原链表的每个节点,将其链接起来不就行了。
但仔细一想 random 呢?这个怎么复制?
题目里说了它是 深拷贝 ,那么就应该完全复刻啊!并且即使知道了原链表中和 random 链接的节点,也不知道 random 和它的相对位置,那应该如何做呢?
可以在原链表中每个节点的后面,复制这个节点,插入到原节点和下一个节点之间; 就相当于我知道 复制的节点是在原节点的后面 ,如果我已经知道原节点的 random 那么我 复制节点的 random 不就是 原节点的random的next节点?再将 复制节点 链接为新链表,和原链表断开链接,恢复原链表就可以了!
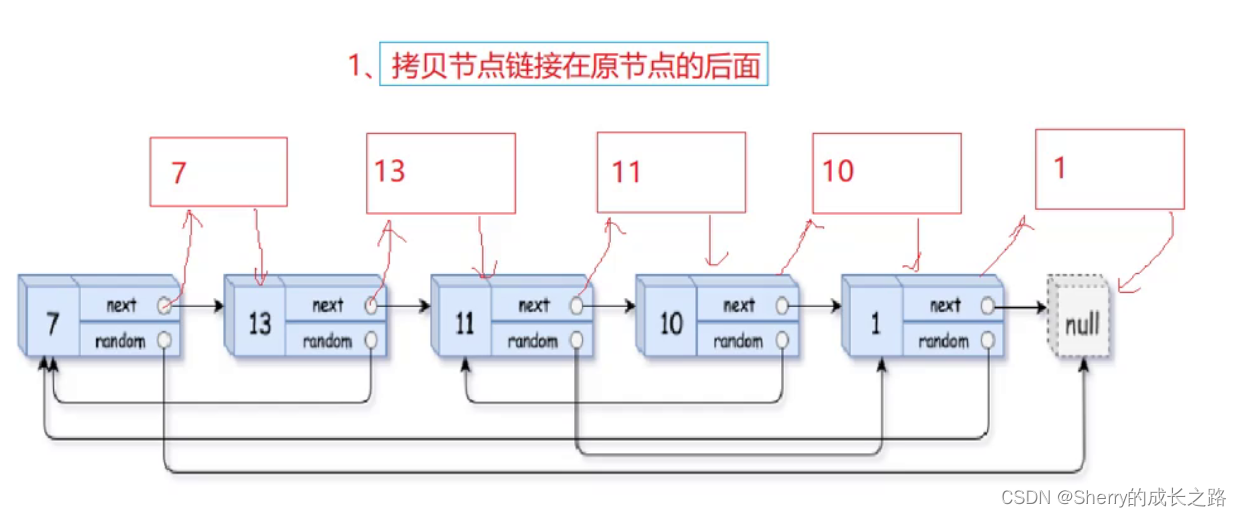
首先,我们给定一个 copy 节点。在原链表每个节点的后面和这个节点的下一个节点之间插入 copy 节点。
这里就对细节有一定的要求。我们就把遍历原链表的节点叫做 cur 吧。
如果 cur 为空,则不进行拷贝。我们插入的 copy 节点是 动态开辟 的。我们需要将 copy 链接到 cur->next ,然后在让 cur->next 给定为 copy 。随后 cur 就需要原节点的后方,也就是当前 copy 节点的 next 。这就考察了 任意插入元素。
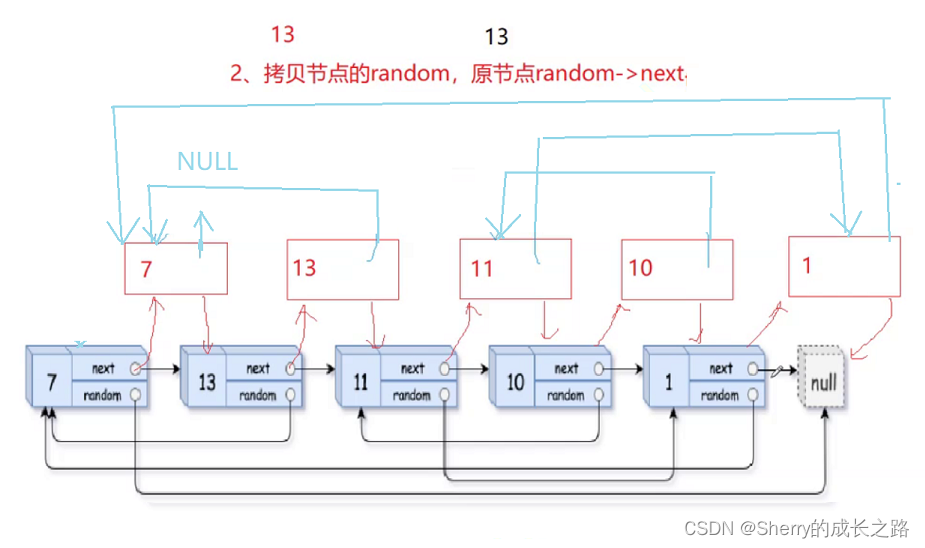
其实我们现在已经将 copy 节点和 原链表建立了联系。
原链表的 random 为 cur->random 、而我们插入的 copy 节点也需要链接。如果我们原链表的当前节点的 random 为 cur->random ,那么我的 copy 节点的 random 节点的相对位置应该和当前节点相同。而我们的当前节点的 random 的后方的 拷贝节点 就是这个 copy 节点的 random 。那么我 copy->random 就等于 cur->random->next 。这样不就链接起来了?
这过程中只要处理好迭代关系就可以了,但是需要注意,当 random 指向为 NULL 时,拷贝处也为 NULL。
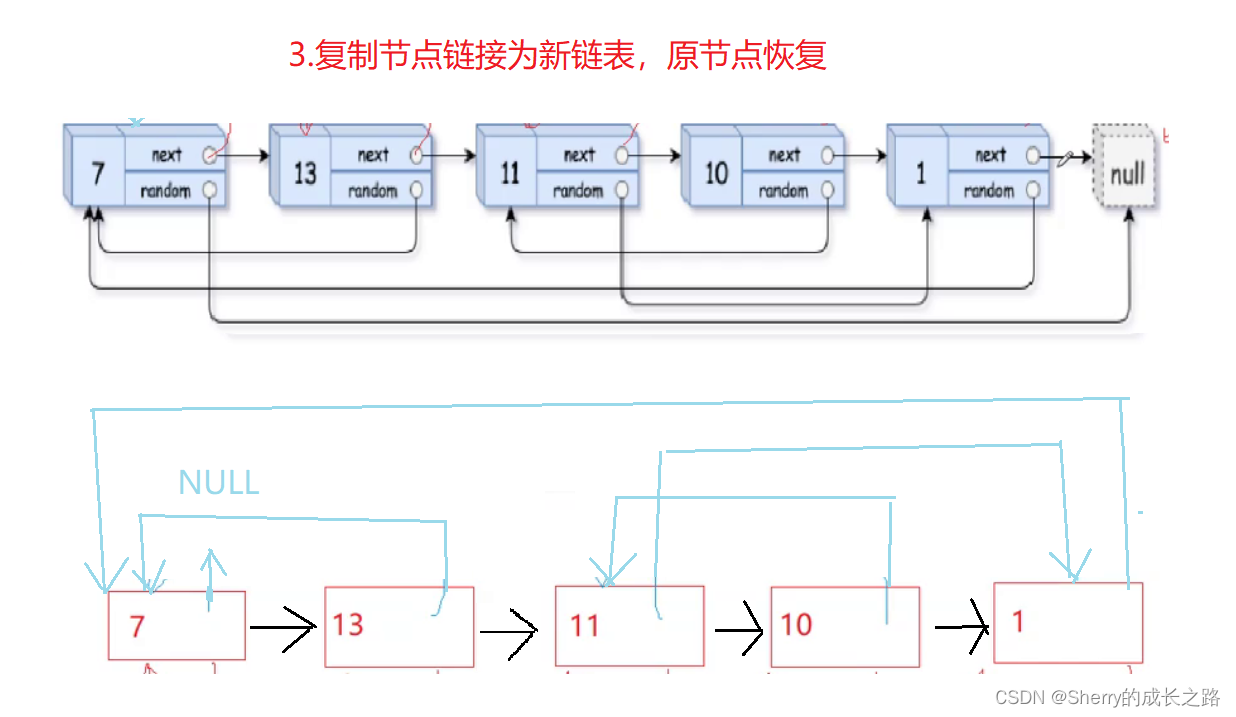
完成这一步,我们需要 copyhead 和 copytail 作为复制链表的头和尾。
而复制节点链接为新链表的过程实际上就是 尾插 。所以要注意一下 空链表尾插 和 正常尾插 的情况。
并且在这过程中,将原链表的链接逐渐恢复。
代码:
/**
* Definition for a Node.
* struct Node {
* int val;
* struct Node *next;
* struct Node *random;
* };
*/
struct Node* copyRandomList(struct Node* head)
{
struct Node* cur = head;
// 1. 在原节点后插入复制节点
while (cur)
{
// 插入复制节点
struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
copy->val = cur->val;
copy->next = cur->next;
cur->next = copy;
// cur往后迭代
cur = copy->next;
}
// 2. 根据原节点的random,处理复制节点的random
cur = head;
while (cur)
{
// copy节点在cur的后面
struct Node* copy = cur->next;
if (cur->random == NULL)
{
copy->random = NULL;
}
else
{
copy->random = cur->random->next;
}
cur = copy->next;
}
// 3. 复制节点链接为新链表,原节点恢复
struct Node* copyHead = NULL, *copyTail = NULL;
cur = head;
while (cur)
{
struct Node* copy = cur->next;
struct Node* next = copy->next;// 记录原链表的下一个节点
// 复制节点链接为新链表(本质为尾插)
if (copyTail == NULL)
{
copyHead = copyTail = copy;
}
else
{
copyTail->next = copy;
copyTail = copy;
}
cur->next = next;// 恢复链接
cur = next;
}
return copyHead;
}
今天我们分析并完成环形链表相关OJ题,也学习和了解环形链表延伸问题,通过分析明白了底层原理,愿这篇博客能帮助大家理解这些OJ题,因为环形链表系列问题是十分经典的面试题。希望我的文章和讲解能对大家的学习提供一些帮助。到这里,链表OJ题系列也就到此收官了。之后会继续更新数据结构的相关知识点。
当然,本文仍有许多不足之处,欢迎各位小伙伴们随时私信交流、批评指正!我们下期见~

我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
首先回顾一下拉格朗日定理的内容:函数f(x)是在闭区间[a,b]上连续、开区间(a,b)上可导的函数,那么至少存在一个,使得:通过这个表达式我们可以知道,f(x)是函数的主体,a和b可以看作是主体函数f(x)中所取的两个值。那么可以有, 也就意味着我们可以用来替换 这种替换可以用在求某些多项式差的极限中。方法: 外层函数f(x)是一致的,并且h(x)和g(x)是等价无穷小。此时,利用拉格朗日定理,将原式替换为 ,再进行求解,往往会省去复合函数求极限的很多麻烦。使用要注意:1.要先找到主体函数f(x),即外层函数必须相同。2.f(x)找到后,复合部分是等价无穷小。3.要满足作差的形式。如果是加