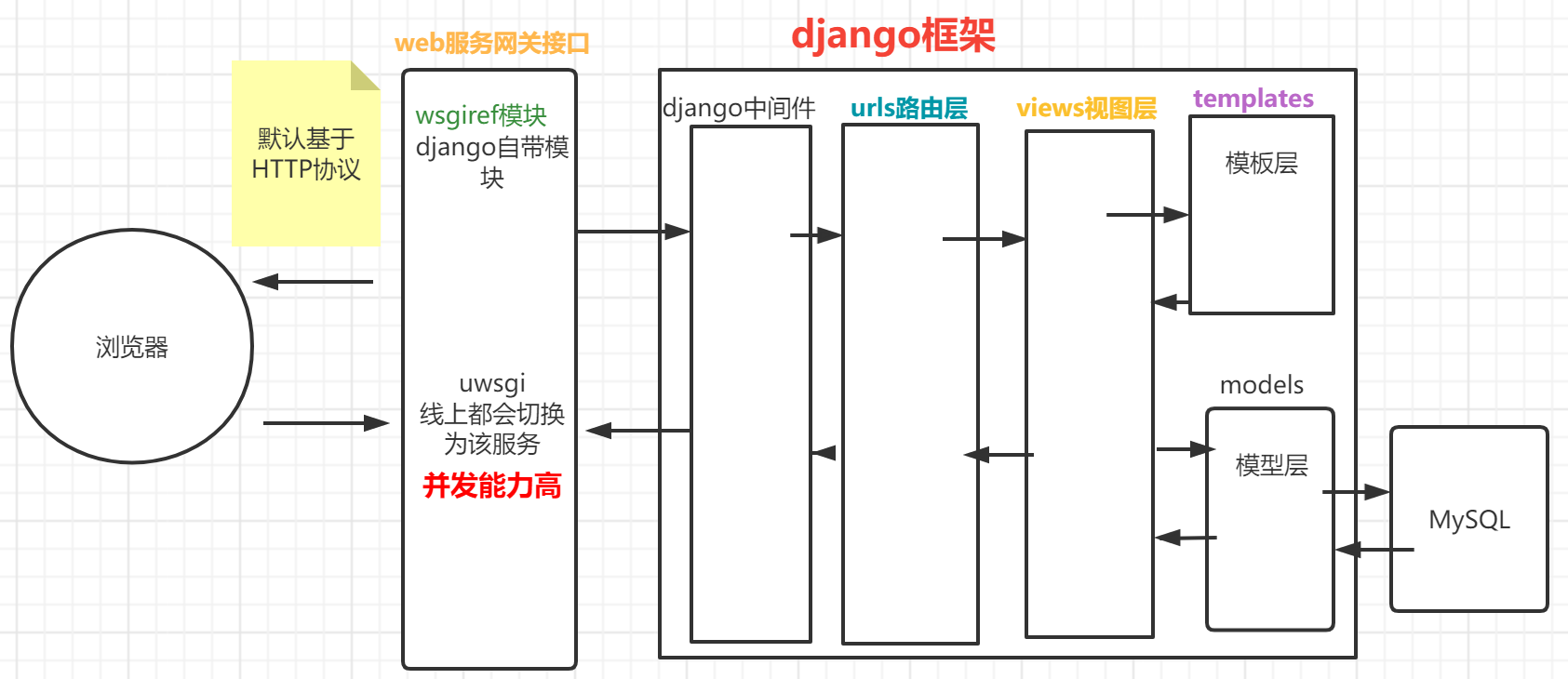
首先,用户在浏览器中输入URL,发送一个GET 或 POST 方法的request 请求。
Django 中封装了socket 的WSGI 服务器,监听端口接受这个request 请求。
再进行初步封装,然后传送到中间件中,这个request 请求再依次经过中间件。
对请求进行校验或处理,再传输到路由系统中进行路由分发,匹配相对应的视图函数(FBV)。
再将request 请求传输到views 中的这个视图函数中,进行业务逻辑的处理。
调用modles 中表对象,通过ORM 拿到数据库(DB)的数据。
同时拿到templates 中相应的模板进行渲染,然后将这个封装了模板response 响应传输到中间件中。
依次进行处理,最后通过WSGI 再进行封装处理,响应给浏览器展示给用户。
路由简单的来说就是根据用户请求的 URL 连接来判断对应的处理程序,并返回处理结果,也就是 URL 与 Django 的视图建立映射关系。
Django 路由在 urls.py 配置,urls.py 中的每一条配置对应相应的处理方法。
urls.py 文件
from django.conf.urls import url
# 由一条条映射关系组成的urlpatterns这个列表称之为路由表
urlpatterns = [
url(regex, view, kwargs=None, name=None), # url本质就是一个函数
]
#函数url关键参数介绍
# regex:正则表达式,用来匹配url地址的路径部分,
# 例如url地址为:http://127.0.0.1:8001/index/,正则表达式要匹配的部分是index/
# view:通常为一个视图函数,用来处理业务逻辑
# kwargs:略(用法详见有名分组)
# name:略(用法详见反向解析)案例:
urls.py 文件
from django.conf.urls import url
from django.contrib import admin
from app import views # 导入模块views.py
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/$', views.index),
]views.py 文件
# 导入HttpResponse,用来生成响应信息
from django.shortcuts import render, HttpResponse
# 新增视图函数index
def index(request):
return HttpResponse('index page')测试
python manage.py runserver # 在浏览器输入:http://127.0.0.1:8000/index/ 会看到 index page1 注意一
在浏览器输入:http: //127.0.0.1:8001/index/,Django 会拿着路径部分 index/ 去路由表(urls.py文件)中自上而下匹配正则表达式,一旦匹配成功,则会立即执行该路径对应的视图函数,也就是上面路由表(urls.py文件)中的 uelspatterns 列表中的url('^index/$',views.index) 也就是views.py 视图函数文件的index函数。
2 注意二
在浏览器中输入:http: //127.0.0.1:8001/index,Django 同样会拿着路径部分 index 去路由表中自上而下匹配正则表达式,看起来好像是匹配不到正则表达式(r'^index/$' 匹配的是必须以/结尾,所以必会匹配到成功index),但是实际上我们依然在浏览器宽口中看到了 ‘index page’,其原因如下:
在配置文件 settings.py 中有一个参数 APPEND_SLASH,该参数有连个值True/False。
当APPEND_SLASH = True(如果配置文件中没有该配置,则默认值为 True),并且用户请求的 URL 地址的路径部分不是以 / 结尾
例如请求的 URL 地址为:http: //127.0.0.1:8001/index,Django也会拿着部分地址 index 去路由表中匹配正则表达式,发现匹配不成功,那么Django 会在路径后加/(index/)在去路由表中匹配,去过还匹配不到,会返回路径找不到,如果匹配成功,则会返回重定向信息给浏览器,要求浏览器重新向 http: //127.0.0.1:8001/index/ 地址返送请求。
当APPEND_SLASH = False时,则不会执行上述过程,即以但 URL 地址的路径部分匹配失败就立即返回路劲未找到,不会做任何的附加操作。
# settings.py
APPEND_SLASH = False 
1 无名分组
urls.py 文件
from django.conf.urls import url
from django.contrib import admin
from app import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 下述正则表达式会匹配url地址的路径部分为:article/数字/
# 匹配成功的分组部分会以位置参数的形式传给视图函数,有几个分组就传几个位置参数
url(r'^aritcle/(\d+)/$', views.article),
]views.py 文件
from django.shortcuts import render, HttpResponse
# 需要额外增加一个形参用于接收传递过来的分组数据
def article(request,article_id):
return HttpResponse('id为 %s 的文章内容...' %article_id)测试
python manage.py runserver在浏览器输入: http://127.0.0.1:8000/article/1/ 会看到: id为 1 的文章内容...
2 有名分组
urls.py 文件
from django.conf.urls import url
from django.contrib import admin
from app import views
urlpatterns = [
url(r'^admin',admin.site.urls),
# 下面的正则表达式会匹配url地址的路径部分为:article/数字/
# 匹配成功的分组部分会以 关键字参数(article_id=..)的形式传给视图函数
# 有几个分组就传几个关键字参数
# (\d+)代表匹配数字1-无穷个
url(r'aritcle/(?P<article_id>\d+)/$', view.article),
]views.py 文件
from django.shortcuts import render, HttpResponse
# 需要额外增加一个形参,形参名必须为article_id
def article(request, article_id):
return HttpResponse('id为 %s 的文章内容...' %article_id)测试
python manage.py runserver在浏览器输入:http://127.0.0.1:8000/article/1/ 会看到: id为 1 的文章内容...
总结:有名分组和无名分组都是为了获取路径中的参数,并传递给视图函数,区别在于无名分组是以位置参数的形式传递,有名分组是以关键字参数的形式传递。
强调:无名分组和有名分组不要混合使用。
随着项目功能的增加,app会越来越多,路由也越来越多,每个app都会有属于自己的路由,如果再将所有的路由都放到一张路由表中,会导致结构不清晰,不便于管理,所以我们应该将app 自己的路由交由自己管理,然后在总路由表中做分发。
1 创建两个 app,记得注册
# 新建项目mystie
G:\src\django>django-admin startproject mysite
# 切换到项目目录下
G:\src\django>cd mysite
# 创建app01和app02
G:\src\django\mysite>python manage.py startapp app01
G:\src\django\mysite>python manage.py startapp app022 在每个app下手动创建urls.py 来存放自己的路由
app01 下的urls.py 文件
from django.conf.urls import url
# 导入app01 的views
from app01 import views
urlpatterns = [
url(r'^index/$',views.index),
]app01 下的views.py文件
from django.shortcuts import render, HttpResponse
def index(request):
return HttpResponse('我是app01 的index页面...')app02下 的urls.py文件
from django.conf.urls import url
# 导入app02的views
from app02 import views
urlpatterns = [
url(r'^index/$',views.index),
]app02 下的views.py文件
from django.shortcuts import render, HttpResponse
def index(request):
return HttpResponse('我是app02 的index页面...')3 在总路由表的 urls.py 文件中(mysite文件夹下的 urls.py)
注意:总路由中,一级路由的后面千万不加$符号,不然不能进行分发路由的操作,表示结束匹配。
from django.conf.urls import url, include
from django.contrib import admin
# 总路由表
# from app01 import urls as app01_urls
# from app02 import urls as app02_urls
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 1.路由分发
# url(r'^app01/',include(app01_urls)), # 只要url前缀是app01开头 全部交给app01处理
# url(r'^app02/',include(app02_urls)) # 只要url前缀是app02开头 全部交给app02处理
# 新增两条路由,注意不能以$结尾
# include 函数就是做分发操作的,当在浏览器输入 http://127.0.0.1:8001/app01/index/ 时
# 会先进入到总路由表中进行匹配,正则表达式 r'^app01/' 会先匹配成功路径app01/
# 然后 include 功能会去 app01 下的urls.py 中继续匹配剩余的路径部分
# 推荐使用
url(r'^app01/', include('app01.urls')),
url(r'^app02/', include('app02.urls')),
]4 测试
python manage.py runserver在浏览器输入: http://127.0.0.1:8000/app01/index/ 会看到:我是app01 的index页面...
在浏览器输入: http://127.0.0.1:8000/app02/index/ 会看到:我是app02 的index页面...
在软件开发初期,URL 地址的路径设计可能并不完美,后期需要进行调整,如果项目中很多地方使用了该路径,一旦该路径发生变化,就意味着所有使用该路径的地方都需要进行修改,这是一个非常繁琐的操作。
解决方案就是在编写一条 url(regex, view, kwargs=None, name=None) 时,可以通过参数name为 URL 地址的路径部分起一个别名,项目中就可以通过别名来获取这个路径。以后无论路径如何变化别名与路径始终保持一致。
上述方案中通过别名获取路径的过程称为反向解析。
案例:登录成功跳转到 index.html 页面。
1 在mysite/urls.py文件
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^login/$', views.login, name='login_page'), # 路径login/的别名为login_page
url(r'^index/$', views.index, name='index_page'), # 路径index/的别名为index_page
]2 在app01/views.py 文件
from django.shortcuts import render, HttpResponse, redirect, reverse # 用于反向解析
def login(request):
if request.method == 'GET':
# 当为get 请求时,返回login.html页面,页面中的 {% url 'login_page' %} 会被反向解析成路径:/login/
return render(request, 'login.html')
# 当为post 请求时,可以从 request.POST 中取出请求体的数据
name = request.POST.get('name')
pwd = request.POST.get('pwd')
if name == 'xyz' and pwd == '123':
url = reverse('index_page') # reverse 会将别名 'index_page' 反向解析成路径:/index/
return redirect(url) # 重定向到/index/
else:
return HttpResponse('用户名或密码错误')
def index(request):
return render(request, 'index.html')3 templates\login.html 文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Login</title>
</head>
<body>
<!--强调: login_page 必须加引号-->
<form action="{% url 'login_page' %}" method="post">
<p>用户名: <input type="text" name="name"></p>
<p>密 码: <input type="password" name="pwd"></p>
<p><input type="submit" value="提交"></p>
</form>
</body>
</html>4 templates\index.html 文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Index</title>
</head>
<body>
<h3>index page</h3>
</body>
</html>5 测试
python manage.py runserver在浏览器输入: http://127.0.0.1:8000/login/ 会看到登录页面,输入正确的用户名密码会跳转到 index.html
当我们修改路由表中匹配路径的正则表达式时,程序其余部分均无需修改
6 总结
7 如果路径存在分组的反向解析使用
from django.shortcuts import HttpResponse, render, reverse
from django.conf.urls import url
from django.contrib import admin
def index(request, args):
return HttpResponse('index page')
def user(request, uid):
return HttpResponse('user page')
def home(request):
# 无名
index = reverse('index_page', args=(1,))
# 有名
user = reverse('user_page', kwargs={'uid': 12})
# 简写
# user = reverse('user_page', args=(12,))
return render(request, 'home.html', locals())
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^$', home), # 首页
url(r'^index/(\d+)/$', index, name='index_page'), # 无名分组
url(r'^user/(?P<uid>\d+)/$', user, name='user_page'), # 有名分组
]8 templates\home.html 文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>home</title>
</head>
<body>
<h3>home page</h3>
<p>{{index}}</p>
<p>{{user}}</p>
<p>{% url 'index_page' 1%}</p>
<p>{% url 'user_page' 12%}</p>
<p>{% url 'user_page' uid=1 %}</p>
</body>
</html>无名分组
反向解析出:/index/1/ 这种路径,写法如下在 views.py 中。
反向解析的使用
url = reverse('index_page', args=(1,))在模版 login.html 文件中,反向解析的使用(1 是匹配\d+)
{% url 'index_page' 1 %}
有名分组
反向解析出:/user/1/ 这种路径,写法如下在 views.py 中。
反向解析的使用
url = reverse('user_page', kwargs={'uid':1})在模版 login.html 文件中,反向解析的使用
{% url 'user_page' uid=1 %}
当我们的项目下创建了多个app,并且每个app下都针对匹配的路径起了别名,如果别名存在重复,那么在反向解析时则会出现覆盖
from django.conf.urls import url
from app01 import views
urlpatterns = [
# 为匹配的路径 app01/index/ 起别名 'index_page'
url(r'^index/$', views.index, name='index_page'),
]from django.conf.urls import url
from app02 import views
urlpatterns = [
# 为匹配的路径 app02/index/ 起别名 'index_page',与app01 中的别名相同
url(r'^index/$', views.index, name='index_page'),
]2 在每个app下的view.py 中编写视图函数,在视图函数中针对别名 'index_page' 做反向解析
app01 下的 views.py 文件
from django.shortcuts import render, HttpResponse, reverse
def index(request):
url = reverse('index_page')
return HttpResponse('app01 的index页面,反向解析结果为%s' %url)from django.shortcuts import render, HttpResponse, reverse
def index(request):
url = reverse('index_page')
return HttpResponse('app02 的index页面,反向解析结果为%s' %url)from django.conf.urls import url, include
from django.contrib import admin
# 总路由表
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 新增两条路由,注意不能以$结尾
url(r'^app01/', include('app01.urls')),
url(r'^app02/', include('app02.urls')),
]python manage.py runserver1 总urls.py 在路由分发时,指定名称空间
from django.conf.urls import url, include
from django.contrib import admin
# 总路由表
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 传给include功能一个元组,元组的第一个值是路由分发的地址,第二个值则是我们为名称空间起的名字
# url(r'^app01/', include(('app01.urls', 'app01'))),
# url(r'^app02/', include(('app02.urls', 'app02'))),
url(r'^app01/', include(('app01.urls', 'app01'), namespace='app01')),
url(r'^app02/', include(('app02.urls', 'app02'), namespace='app02'))
]2 修改每个app下的view.py 中视图函数,针对不同名称空间中的别名 'index_page' 做反向解析
app01 下的views.py 文件
from django.shortcuts import HttpResponse
def index(request):
# 解析的是名称空间app01 下的别名 'index_page'
url = reverse('app01:index_page')
return HttpResponse('app01 的index页面,反向解析结果为%s' %url)app02 下的views.py 文件
from django.shortcuts import HttpResponse
def index(request):
# 解析的是名称空间app02下的别名'index_page'
url = reverse('app02:index_page')
return HttpResponse('app02 的index页面,反向解析结果为%s' %url)3 测试
python manage.py runserver浏览器输入: http://127.0.0.1:8000/app01/index/ 反向解析的结果是 /app01/index/
浏览器输入: http://127.0.0.1:8000/app02/index/ 反向解析的结果是 /app02/index/
总结 + 补充
# 在视图函数中基于名称空间的反向解析,用法如下
url = reverse('名称空间的名字:待解析的别名')
# 在模版里基于名称空间的反向解析,用法如下
<a href="{% url '名称空间的名字:待解析的别名'%}">index page</a>
# 其实只要保证名字不冲突 就没有必要使用名称空间4 namespace 参数
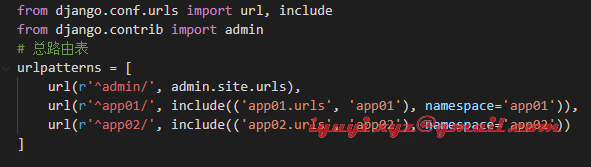
在根目录下的 urls.py 中使用了 include 方法,并且使用了 namespace 参数,如下图

在启动项目时,会报错:'Specifying a namespace in include() without providing an app_name '
这是因为Django2 相对于Django1 做了改动,在include 函数里增加了参数 app_name,表示app的名字。
解决方法:
在 include 中传入该app的名字(第二个参数),即
1 re_path
Django2.0 中的re_path与Django1.0 的URL一样,传入的第一个参数都是正则表达式
from django.urls import re_path # Django3.2 中的re_path
from django.conf.urls import url # Django3.2 中同样可以导入1.0中的url
urlpatterns = [
# 用法完全一致
url(r'^app01/', include(('app01.urls','app01'))),
re_path(r'^app02/', include(('app02.urls','app02'))),
]2 path
在Django2.0 中新增了一个path功能,用来解决:数据类型转换问题与正则表达式冗余问题
from django.shortcuts import HttpResponse,
from django.urls import path, re_path
urlpatterns = [
# 虽然path 不支持正则 但是它的内部支持五种转换器
# 将第二个路由里面的内容先转成整型然后以 关键字 的形式传递给后面的视图函数
path('index/<int:id>/', index)
]
# id 关键字参数
def index(request, id):
print(id, type(id))
return HttpResponse('index page')强调
例如
path('articles/<int:year>/<int:month>/<slug:other>/', views.article_detail) 针对路径 http://127.0.0.1:8000/articles/2009/123/info/
path 会匹配出参数 year=2009,month=123,other='info' 传递给函数 article_detail。
很明显针对月份 month,转换器int是无法精准匹配的,如果我们只想匹配两个字符,那么转换器slug也无法满足需求,针对等等这一系列复杂的需要,我们可以定义自己的转化器。转化器是一个类或接口,它的要求有三点:
自定义转换器示例
在app01 下新建文件 path_ converters.py,文件名可以随意命名
class MonthConverter:
regex = '\d{2}' # 属性名必须为regex
def to_python(self, value):
return int(value)
def to_url(self, value):
return value # 匹配的regex是两个数字,返回的结果也必须是两个数字在urls.py中,使用 register_converter 将其注册到 URL 配置中
from django.urls import path,register_converter
from app01.path_converts import MonthConverter
register_converter(MonthConverter, 'mon')
from app01 import views
urlpatterns = [
path('articles/<int:year>/<mon:month>/<slug:other>/', views.article_detail, name='xxx'),
]views.py 文件中的视图函数 article_detail
from django.shortcuts import HttpResponse
def article_detail(request,year,month,other):
print(year, type(year))
print(month, type(month))
print(other, type(other))
print(reverse('xxx', args=(1988, 12, 'info'))) # 反向解析结果/articles/1988/12/info/
return HttpResponse('article detail page')测试
我正在用RubyonRails重写Django应用程序,并希望为用户保留旧密码。Django使用PBKDF2SHA1作为加密机制。所以我有一个加密密码是这个pbkdf2_sha256$10000$YsnGfP4rZ1IZ$Tpf4922MoNEjuJQA9EG2Elptyt3dMAyzBPUgmunFOW4=原密码是2bulls在Ruby中,我使用PBKDF256gem和base64进行检查。Base64.encode64PBKDF256.dk("2bulls","YsnGfP4rZ1IZ",10000,32)我很期待Tpf4922MoNEjuJQA9EG2Elptyt3dMAyzBP
目录1古彝文与古典保护2古文识别的挑战2.1西文与汉文OCR2.2古彝文识别难点3合合信息:古彝文保护新思路3.1图像矫正3.2图像增强3.3语义理解3.4工程技巧4总结1古彝文与古典保护彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。古彝文字义对照图(网络资料+邵文苑供图)古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、
摘要本论文主要论述了如何使用Python技术开发一个短视频智能推荐,本系统将严格按照软件开发流程进行各个阶段的工作,采用B/S架构,面向对象编程思想进行项目开发。在引言中,作者将论述短视频智能推荐的当前背景以及系统开发的目的,后续章节将严格按照软件开发流程,对系统进行各个阶段分析设计。 短视频智能推荐的主要使用者分为管理员和用户,实现功能包括管理员:首页、个人中心、用户管理、热门视频管理、用户上传管理、系统管理,用户:首页、个人中心、用户上传管理、我的收藏管理,前台首页;首页、热门视频、用户上传、公告信息、个人中心、后台管理等功能。由于本网站的功能模块设计比较全面,所以使得整个短视频智能推荐信
文章目录背景一、最初的疑惑二、简单聊聊原理三、组织内实践案例四、实践带来的反思五、最后聊几句问题背景这个概念由来已久,但是在国内兴起,是最近几年;低代码即Low-Code;指提供可视化开发环境,可以用来创建和管理软件应用;简单的说就是可以通过各种组件的拖拽,实现页面的创建,交互流程和逻辑,以及数据层面的管理,更加高效的实现需求;早先在数据公司时;见识过低代码的应用,也参与过部分研发,比如元数据平台,BI分析等;不过,当时还是以数据管理的工具来定义项目,并非是低代码;从「2020年底」开始;实际上,那个时间节点,低代码平台的应用已经形成趋势了;现在的公司,将低代码平台的使用规划到业务体系中;后来
有没有办法为Sinatra获取DjangoAdmin风格的网络管理员? 最佳答案 没用过,但通过谷歌很快就显示出来了:http://www.padrinorb.com/ 关于ruby-SinatraWeb管理员(如Django管理员),我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/2855494/
一、乱花迷人眼我就是被迷的那双眼。有时候需求来了,用熟悉的套路进行开发,确实很节省时间也能保证功能的稳定,但是这些开发的惯性无形中阻碍了我对技术的探索。我一直想改造详情页,解放重复功能开发的劳动力,但是详情页一眼望都是内容平铺,好像并没有什么可做的代码设计。后来我拨开繁花,发现详情页的组件化不必想的过于复杂,后台系统风格统一即可。因为大部分的详情页面是内容的展示,偶尔会出现少量的操作功能。将风格统一的部分进行组件化处理,操作功能使用回调函数放回当前页面,避免组件里做过多的业务逻辑。看,这不就成了。项目基于React框架开发的,所以代码写法是JSX语法,组件开发使用的hooks函数式组件,UI框
我正在深入了解Jekyll,并希望将其用作通用前端开发平台,但遇到了Liquid模板语言的局限性,特别是它与Django模板的区别。我发现了liquid-inheritancegem,它添加了Django中最重要的Extends和Block语法。这篇博文进一步扩展了gem以适应Jekyll的文件系统:http://www.sameratiani.com/2011/10/22/get-jekyll-working-with-liquid-inheritance.html问题是它似乎没有以与Django完全相同的方式实现block,这实际上使gem变得无用。为了便于理解,我有两个名为par
我目前正在尝试在Rails和Django之间做出决定。目前我发现ruby更优雅,所以我考虑Django的唯一原因是管理面板..我没有任何经验,但我必须在截止日期前快速开发应用程序。Rails中是否有一种方法可以根据您的模型(如django中的管理面板)为您的所有CRUD操作生成一组(接近生产就绪的)View?(即它会查看您的模型并看到您有一个属于某个组的人,并在创建人员View上为该组生成一个下拉列表)?如果不是,那是获得所有CRUDView初稿的最快方法(无需手动编写)?谢谢,丹尼尔 最佳答案 有趣的工具http://acti
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭9年前。Improvethisquestion我一直在找工作。大多数公司都需要RoR或Django经验。我不懂任何一种语言。使用RoR的组织数量多于Django。但我更喜欢django因为python。你们的程序员/招聘人员建议我知道什么?
假设我们有那些Django模型:classBand(models.Model):name=models.CharField(max_length=256,default="EaglesofDeathMetal")classSong(models.Model):band=models.ForeignKey(Band)当使用admin管理这些模型时,band字段关联到由Django呈现为selecthtml元素的Widget。Django的管理员还在select旁边添加了一个绿色加号图标,单击它会打开一个弹出窗口,用户会在其中看到Form添加一个新的乐队。单击此弹出窗口中的save按钮时,