 想体验千亿参数大模型的门槛,真是越来越低了!想让大模型回答问题?只需在网页端输入问题,运行二三十秒,答案就噌噌生成了。
想体验千亿参数大模型的门槛,真是越来越低了!想让大模型回答问题?只需在网页端输入问题,运行二三十秒,答案就噌噌生成了。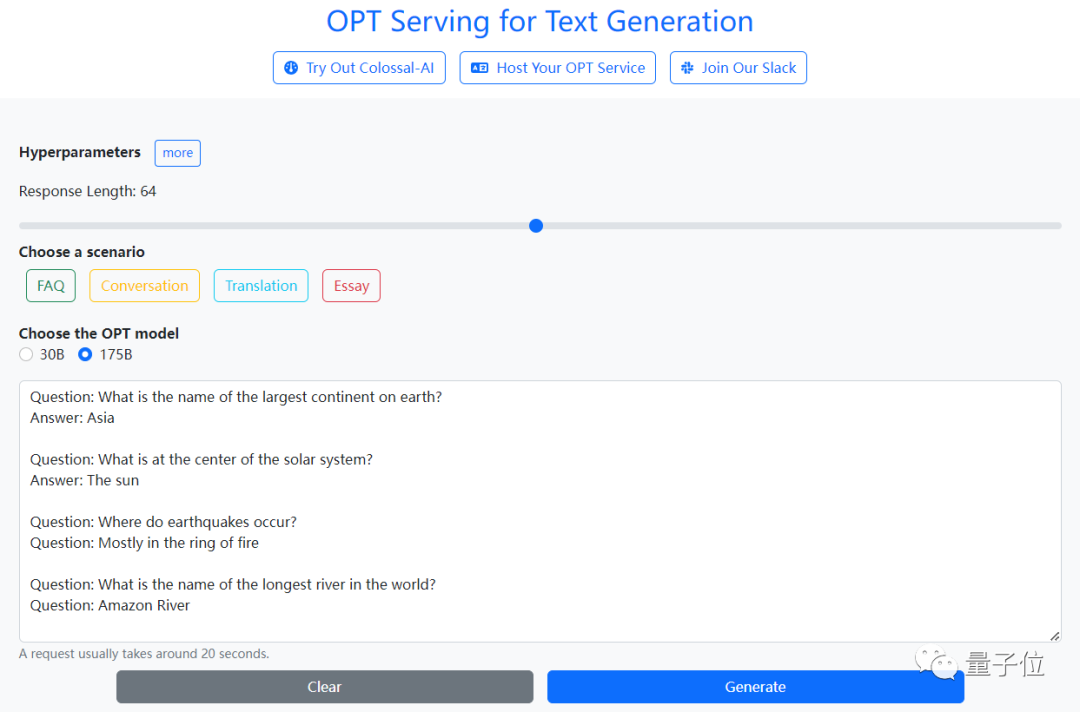 用的正是今年由Meta开源的Open Pretrained Transformer(OPT),参数量达1750亿。如果是传统在本地运行,对算力可是个大考验。这就是由开源项目Colossal-AI支持的云端demo,无需注册即可上手体验,对硬件完全没门槛,普通笔记本电脑甚至手机就能搞定。也就是说,完全不用懂代码的小白,现在也能调戏OPT这样的大模型了。让我们来试玩一把~
用的正是今年由Meta开源的Open Pretrained Transformer(OPT),参数量达1750亿。如果是传统在本地运行,对算力可是个大考验。这就是由开源项目Colossal-AI支持的云端demo,无需注册即可上手体验,对硬件完全没门槛,普通笔记本电脑甚至手机就能搞定。也就是说,完全不用懂代码的小白,现在也能调戏OPT这样的大模型了。让我们来试玩一把~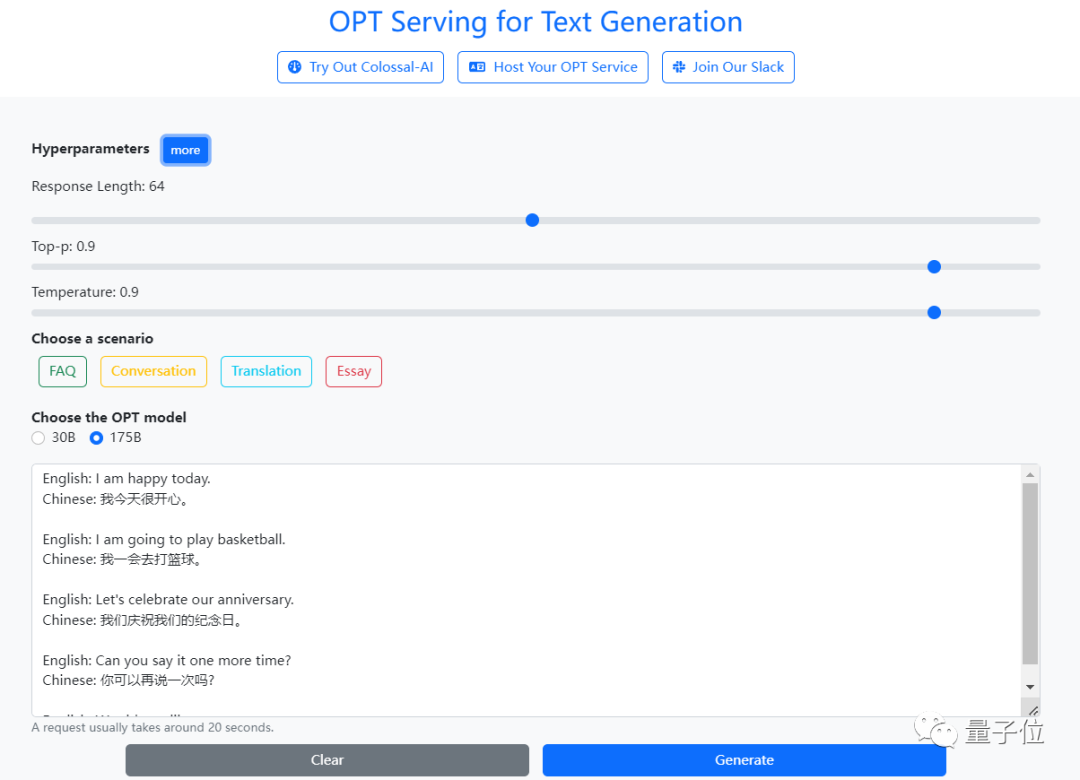 我们体验了下文章创作,开头给了一句“今天是个好日子啊”。很快,网页就输出了一连串大好事,刚刚加薪、正在玩刺客信条、明天还要去海滩……看着让人羡慕!
我们体验了下文章创作,开头给了一句“今天是个好日子啊”。很快,网页就输出了一连串大好事,刚刚加薪、正在玩刺客信条、明天还要去海滩……看着让人羡慕!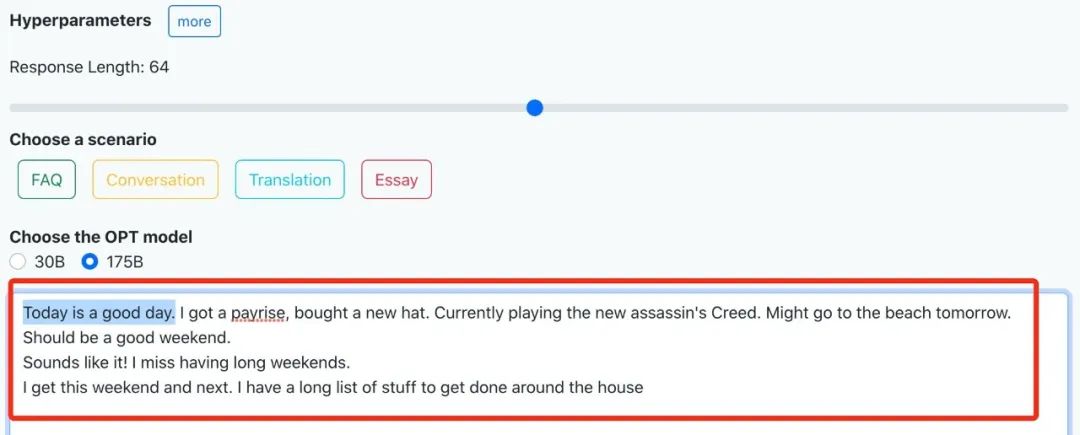 还能构建个场景让聊天机器人唠上几块钱的。随机生成的一段长对话是买手机的场景。嗯,和今天iPhone 14发布可以说是非常应景了。
还能构建个场景让聊天机器人唠上几块钱的。随机生成的一段长对话是买手机的场景。嗯,和今天iPhone 14发布可以说是非常应景了。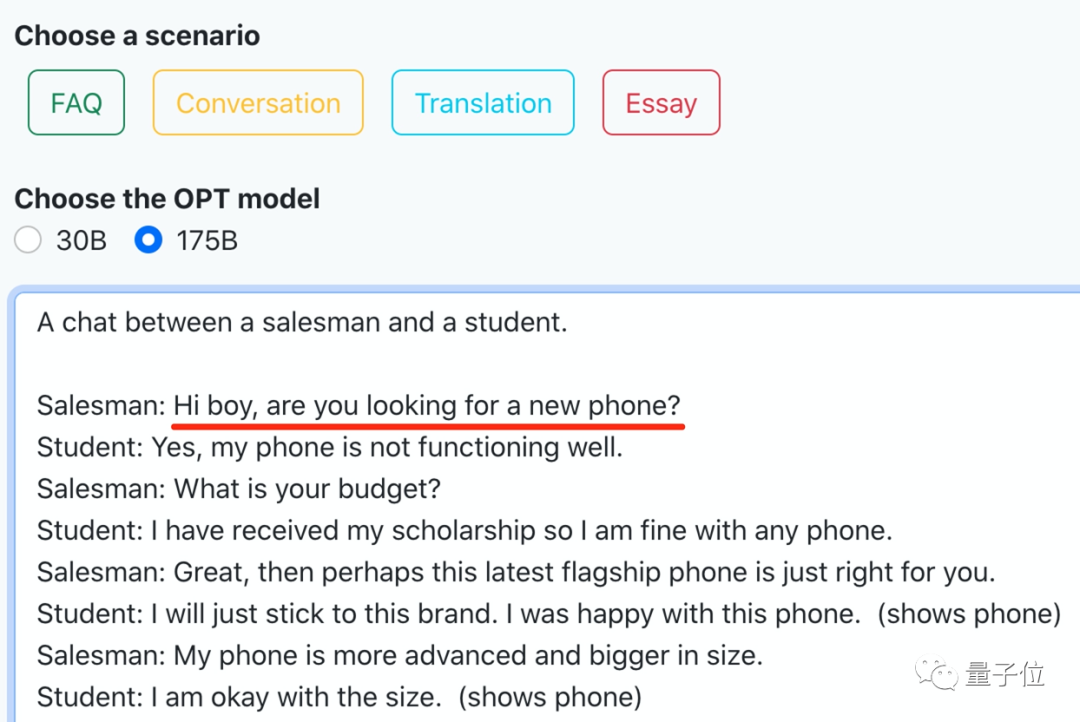 感觉即便是不懂AI、不懂编程的小白也能玩转OPT的各种任务,体验过程相当丝滑。要知道,像OPT这样千亿参数大模型的运行,一直都有着“对硬件要求高”、“成本高”的特点。一个免费无限玩的网站,到底是怎么实现如上效果的?
感觉即便是不懂AI、不懂编程的小白也能玩转OPT的各种任务,体验过程相当丝滑。要知道,像OPT这样千亿参数大模型的运行,一直都有着“对硬件要求高”、“成本高”的特点。一个免费无限玩的网站,到底是怎么实现如上效果的?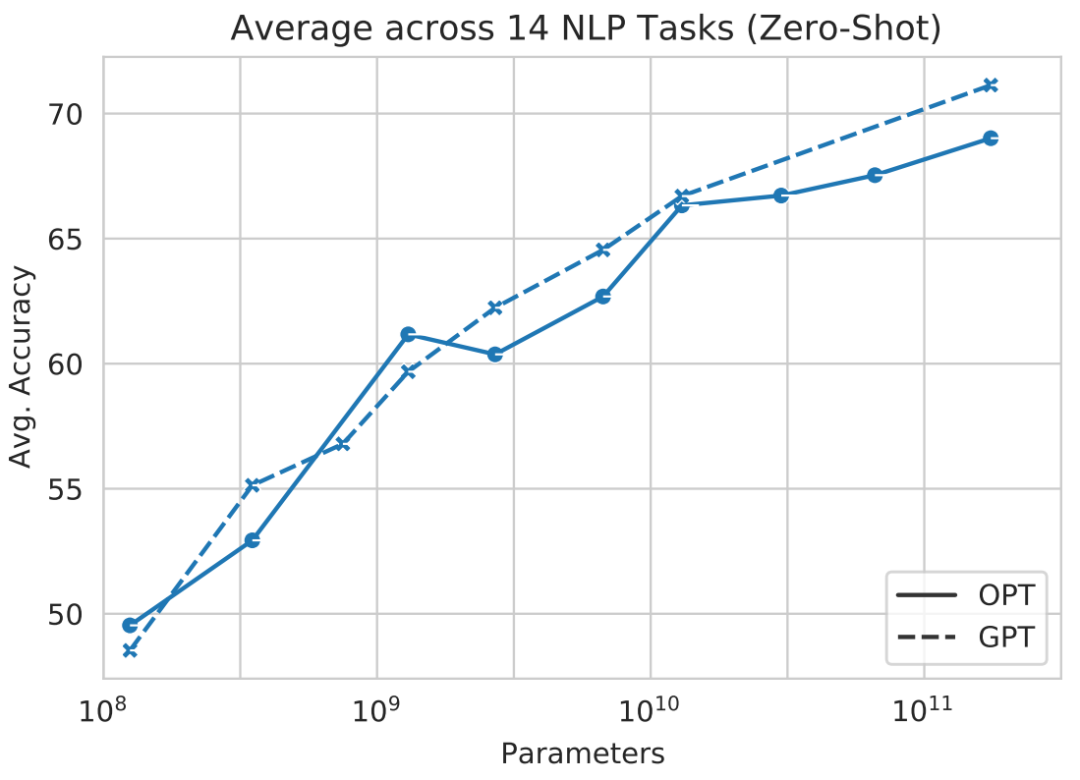 而且推理问题不光要考虑吞吐量,还要顾及到时延问题。针对这两方面问题,并行计算是个不错的解决思路。尤其是Colossal-AI本身就十分擅长将一个单机模型转换成并行运行,获得并行OPT模型自然不成问题。不过并行方案中的参数加载一直是个难题。在这方面,Colossal-AI可以让用户只需要参考样例,简单提供参数名映射关系,即可完成模型参数的加载。最后,再将模型导入到Colossal-AI的推理引擎中,设置相应的超参数。到这一步,OPT主干网络的推理部分就能上线且输出有意义的结果了。但是这还远远不够。因为OPT是生成式模型,生成式任务需要不断循环模型的输出结果,这就导致推理中常见的batching策略无法直接应用。具体来看,由于生成任务输入的语句长度往往参差不齐,而且大部分语言阅读和书写都是从左向右的。如果用常规的right padding,那么针对较短的句子就很难生成有意义的结果,或者需要进行复杂处理。
而且推理问题不光要考虑吞吐量,还要顾及到时延问题。针对这两方面问题,并行计算是个不错的解决思路。尤其是Colossal-AI本身就十分擅长将一个单机模型转换成并行运行,获得并行OPT模型自然不成问题。不过并行方案中的参数加载一直是个难题。在这方面,Colossal-AI可以让用户只需要参考样例,简单提供参数名映射关系,即可完成模型参数的加载。最后,再将模型导入到Colossal-AI的推理引擎中,设置相应的超参数。到这一步,OPT主干网络的推理部分就能上线且输出有意义的结果了。但是这还远远不够。因为OPT是生成式模型,生成式任务需要不断循环模型的输出结果,这就导致推理中常见的batching策略无法直接应用。具体来看,由于生成任务输入的语句长度往往参差不齐,而且大部分语言阅读和书写都是从左向右的。如果用常规的right padding,那么针对较短的句子就很难生成有意义的结果,或者需要进行复杂处理。

 除此之外,开发人员还注意到生成式任务的计算量是参差不齐的。输入、输出的句子长短变化范围都很大。如果用简单的batching方法,将两个相差很大的推理放在同一个批次里,就会造成大量的冗余计算。因此他们提出了bucket batching。即按照输入句长以及输出目标句长进行桶排序,同一个桶内的序列作为一个batching,以此降低冗余。
除此之外,开发人员还注意到生成式任务的计算量是参差不齐的。输入、输出的句子长短变化范围都很大。如果用简单的batching方法,将两个相差很大的推理放在同一个批次里,就会造成大量的冗余计算。因此他们提出了bucket batching。即按照输入句长以及输出目标句长进行桶排序,同一个桶内的序列作为一个batching,以此降低冗余。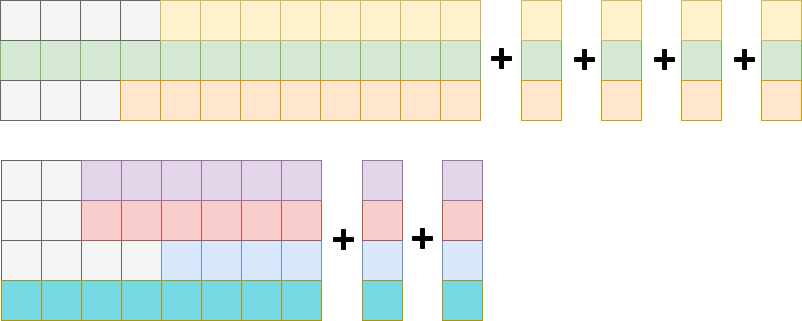
 此前Colossal-AI多次在GitHub、Paper With Code热榜位列世界第一。相关解决方案成功在自动驾驶、云计算、零售、 医药、芯片等行业知名厂商落地应用。最近,Colossal-AI还连续入选和受邀全球超级计算机大会、国际数据科学会议、世界人工智能大会、亚马逊云科技中国峰会等国际专业盛会。
此前Colossal-AI多次在GitHub、Paper With Code热榜位列世界第一。相关解决方案成功在自动驾驶、云计算、零售、 医药、芯片等行业知名厂商落地应用。最近,Colossal-AI还连续入选和受邀全球超级计算机大会、国际数据科学会议、世界人工智能大会、亚马逊云科技中国峰会等国际专业盛会。 我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢