文章目录
场景:
POST /testcopy/_bulk
{"index":{"_id": 1}}
{"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"光谷大道","address":"湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article"}
{"index":{"_id": 2}}
{"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"}
{"index":{"_id": 3}}
{ "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"经济技术开发区","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"}
{"index":{"_id": 4}}
{"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"沌口开发区","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"}
{"index":{"_id": 5}}
{ "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","provice" : "湖北省","city":"高新开发区","area":"武汉","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"}
{"index":{"_id": 6}}
{"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","provice" : "武汉市","city":"湖北省","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i like java developer"}
{"index":{"_id": 7}}
{"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","provice" : "湖北省","city":"黄冈市","area":"边城区","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer"}
{"index":{"_id": 8}}
{"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"汉阳区","address" : "湖北省武汉市江汉大学","content" : "i like spark language"}
{"index":{"_id": 9}}
{"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市郑州大学","content" : "i like java developer"}
{"index":{"_id": 10}}
{"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","provice" : "湖北省","city":"武汉","area":"高新开发区","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch"}
{"index":{"_id": 11}}
{"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am not like java "}
{"index":{"_id": 12}}
{"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good"}
{"index":{"_id": 13}}
{"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java "}
{"index":{"_id": 14}}
{"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部",,"provice" : "河南省","city":"郑州市","area":"金水区","address" : "河南省郑州市金水区","content" : "i like c++"}
{"index":{"_id": 15}}
{"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部",,"provice" : "河南省","city":"郑州市","area":"高新开发区","address" : "河南省郑州高新开发区","content" : "i think spark is good"}
aggs分组中有一些属性来控制条数及排序规则,参数如下:
#top_hits获取分组内 topN 前2条数据
get /testcopy/_search
{
"size":0,
"aggs":{
"group_by_dept":{
"terms": {
"field": "deptName.keyword"
},
//terms 同级进行 aggs聚合搜索
"aggs": {
"top_two_age": {
"top_hits": {
// top_hits中的size 就是取每个分组多少条
"size": 2,
//按照什么排序
"sort": [
{
"age": {
"order": "desc"
}
}
],
//取哪些字段
"_source": {
"includes": ["name","age","deptName"]
}
}
}
}
}
}
}
查询结果 所有的分组都是 取前2个, 比如 技术部有四个员工,只取 top2,前2个
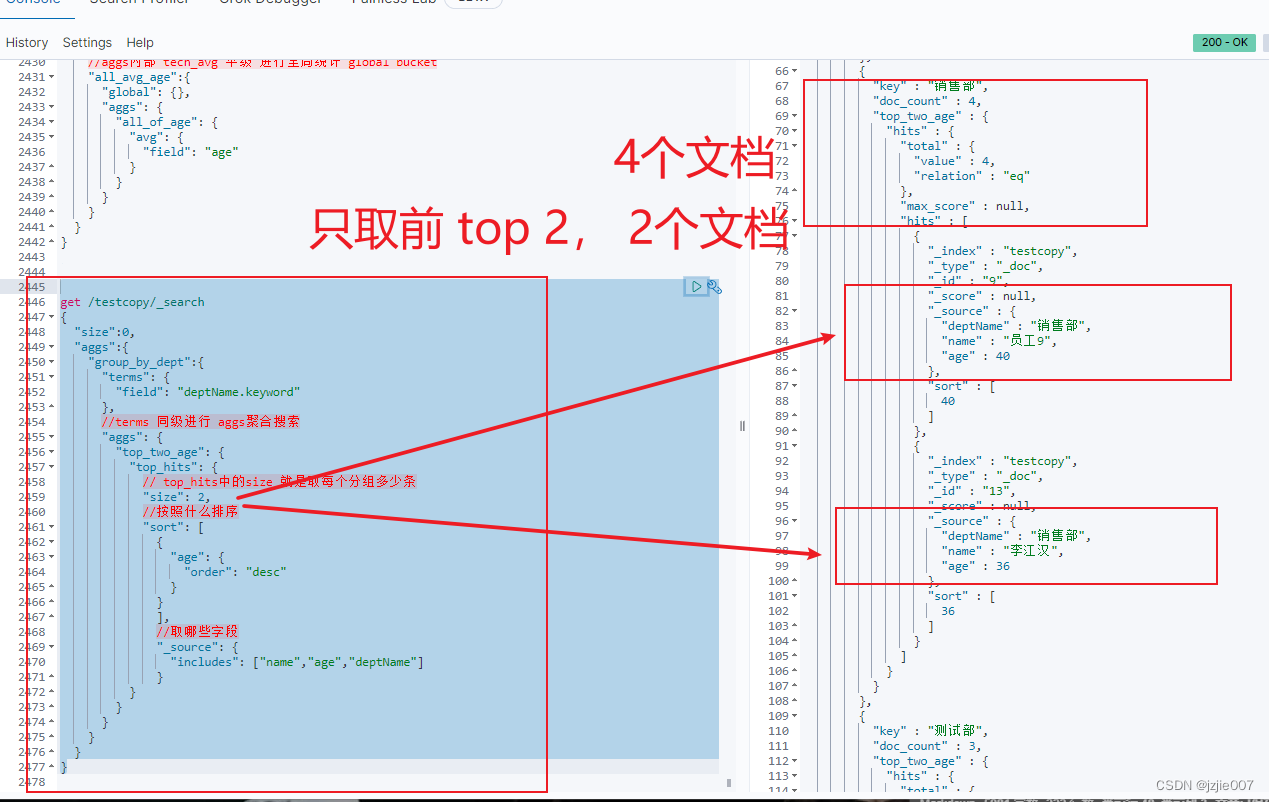
以10 为区间,统计每个年龄段多少人,或者统计每个年龄段的平均工资 salary,我们就以histogram来实现
hisgogram 参数 interval就是控制区间步长, 比如 10, 那么它划分的 区间就是 10-20/20-30/30-40/40-50/50-60/60-70 , 然后没有70岁以上的人 那就结束,直到最后一个区间
# 以10为区间,统计 每个年龄段的 平均工资
get /testcopy/_search
{
"size":0,
"aggs":{
"histogram_by_10_age":{
"histogram": {
"field": "age",
"interval": 10
},
//histogram 平级,然后进行 aggs 求每个区间的 平均工资
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
}
}
}
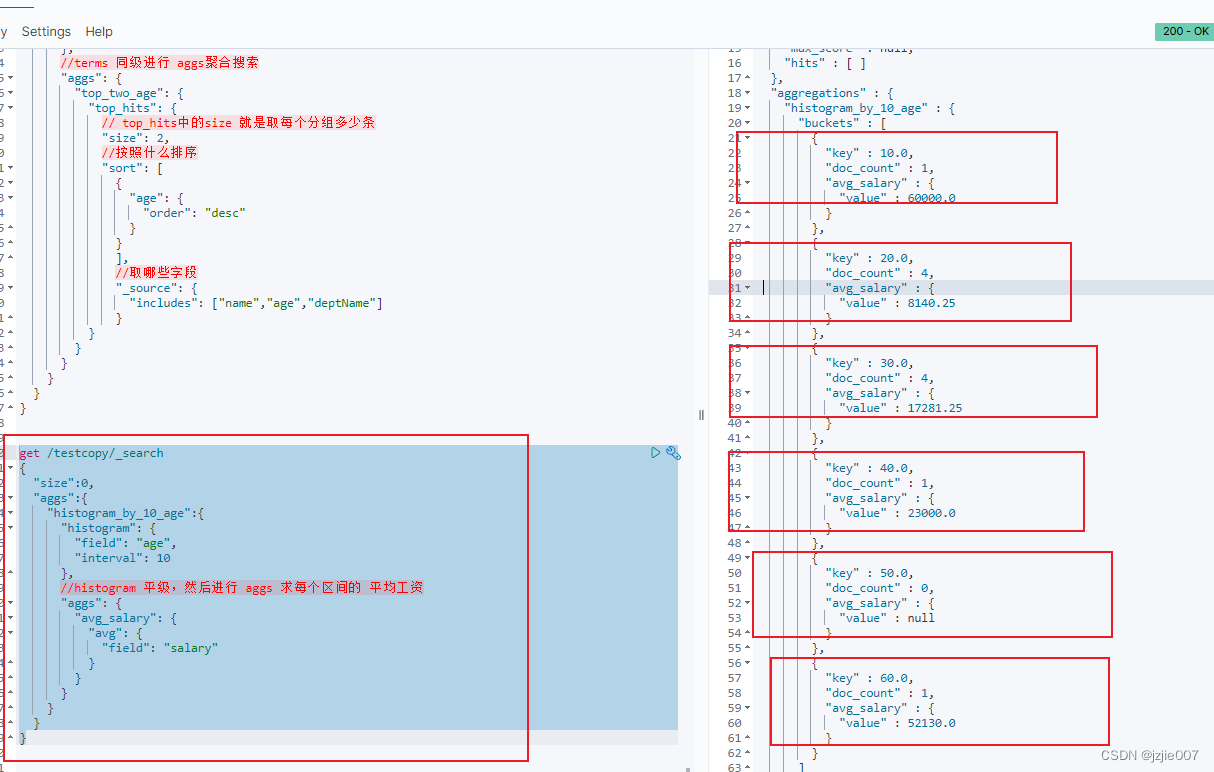
查询过滤 结果 可以看到 每个年龄段 都统计了人数及 平均工资,
最低年龄19,落在区间10-20区间内,所以第一个期间就是 key:10, 区间10-20 ,
没有人 超过70岁,所以就不显示 70及以后的区间
| 年龄区间 | 人数 | 平均工资 |
|---|---|---|
| 10-20区间 | 1人 | 60000 |
| 20-30区间 | 4人 | 8140.25 |
| 30-40区间 | 4人 | 17281.25 |
| 40-50区间 | 1人 | 23000.0 |
| 50-60区间 | 0人 | null |
| 60-70区间 | 1人 | 52130.0 |
上面我们介绍了 使用histogram来统计区间内数据,我们的数据都是按照日期进行更新插入的,如果现在要统计每月销售额如何实现?
原理就是 用 date_histogram来做时间月份的区间统计,然后sum销售额即可
先设计mapping,创建时间格式 mapping,否则插入的时间戳 要么是long数字,要么是text文本形式
put /selldata
{
"mappings" : {
"properties" : {
"addtime" : {
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
}
}
}
}
}
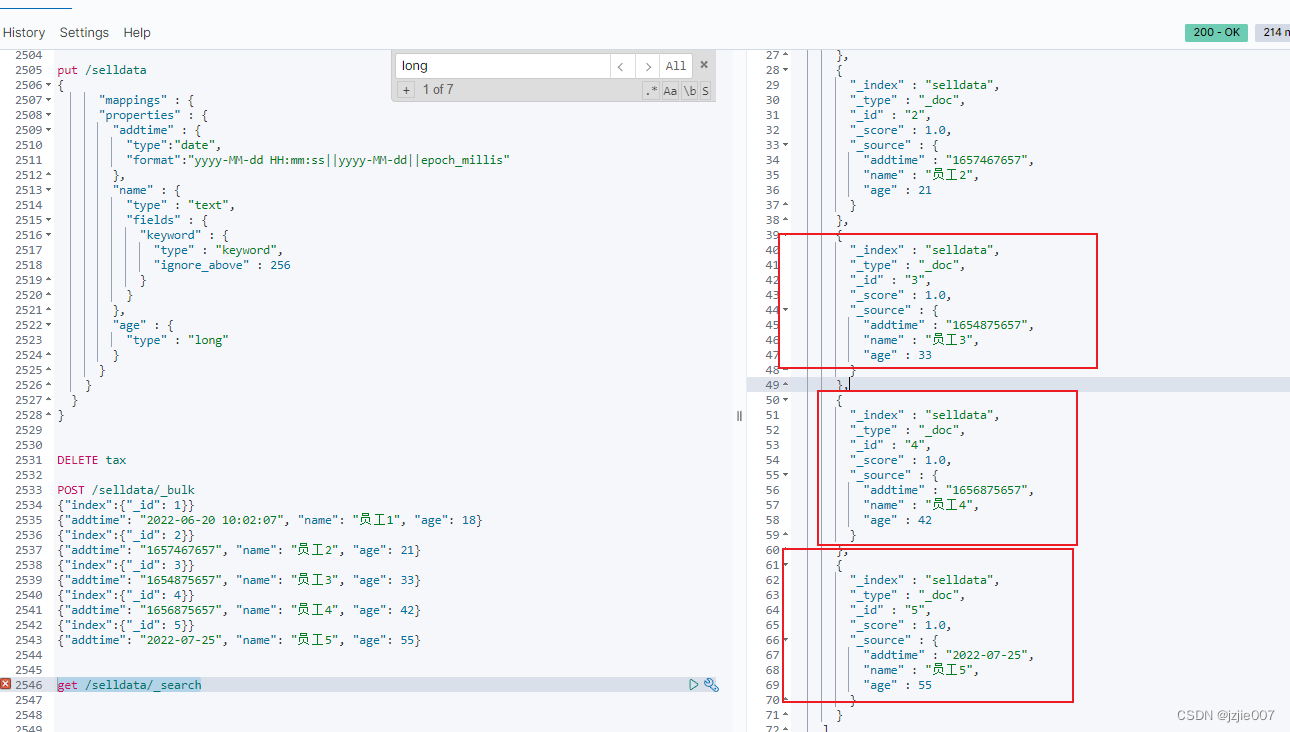
插入数据
我们准备了几种 date格式, yyyy-mm-dd HH:mm:ss 及 时间戳long,及UTC时间 2021-01-30T10:02:07Z 都 试一试,看看能否插入成功
# 错误数据 ,因为 员工3和员工4 是UTC时间,是无法插入的
POST /selldata/_bulk
{"index":{"_id": 1}}
{"addtime": "2022-06-20 10:02:07", "name": "员工1", "age": 18}
{"index":{"_id": 2}}
{"addtime": "1657467657000", "name": "员工2", "age": 21}
{"index":{"_id": 3}}
{"addtime": "2022-05-1T12:20:00Z", "name": "员工3", "age": 33}
{"index":{"_id": 4}}
{"addtime": "2022-06-30T10:02:07Z", "name": "员工4", "age": 42}
{"index":{"_id": 5}}
{"addtime": "2022-07-25", "name": "员工5", "age": 55}
执行报错 UTC时间无法匹配时间格式
failed to parse date field [2022-05-1T12:20:00Z] with format [yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis]",
所以修改下员工3和员工4的错误数据,再次插入
#正确数据, 插入成功
POST /selldata/_bulk
{"index":{"_id": 1}}
{"addtime": "2022-04-20 10:02:07", "name": "员工1", "age": 18}
{"index":{"_id": 2}}
{"addtime": "1657467657000", "name": "员工2", "age": 21}
{"index":{"_id": 3}}
{"addtime": "1654875657000", "name": "员工3", "age": 33}
{"index":{"_id": 4}}
{"addtime": "1656875657000", "name": "员工4", "age": 42}
{"index":{"_id": 5}}
{"addtime": "2022-07-25", "name": "员工5", "age": 55}
查询下 是否成功插入, 全都正确
get /selldata/_search
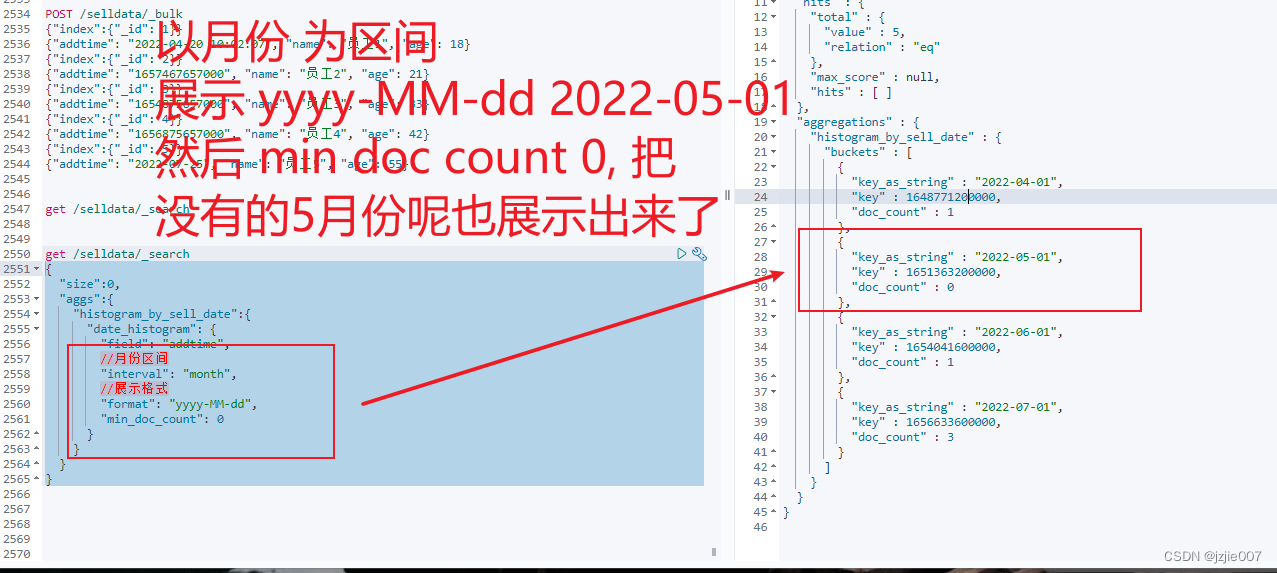
date_histogram 有以下参数
实现时间区间统计,统计 按照month区间
get /selldata/_search
{
"size":0,
"aggs":{
"histogram_by_sell_date":{
"date_histogram": {
"field": "addtime",
//月份区间
"interval": "month",
//展示格式
"format": "yyyy-MM-dd",
"min_doc_count": 0
}
}
}
}
查询结果 key_as_string 展示格式就是 yyyy-MM-dd 2022-04-01, 以month月度为统计区间
min_doc_count就是最小的文档数 为0 表示即使时0也要展示出来
我们修改下 min_doc_count = 2
试一下, 看看 文档doc数量为0/1的是否展示
get /selldata/_search
{
"size":0,
"aggs":{
"histogram_by_sell_date":{
"date_histogram": {
"field": "addtime",
//月份区间
"interval": "month",
//展示格式
"format": "yyyy-MM-dd",
//最小数目大于 等于 2的才展示
"min_doc_count": 2
}
}
}
}
查询结果
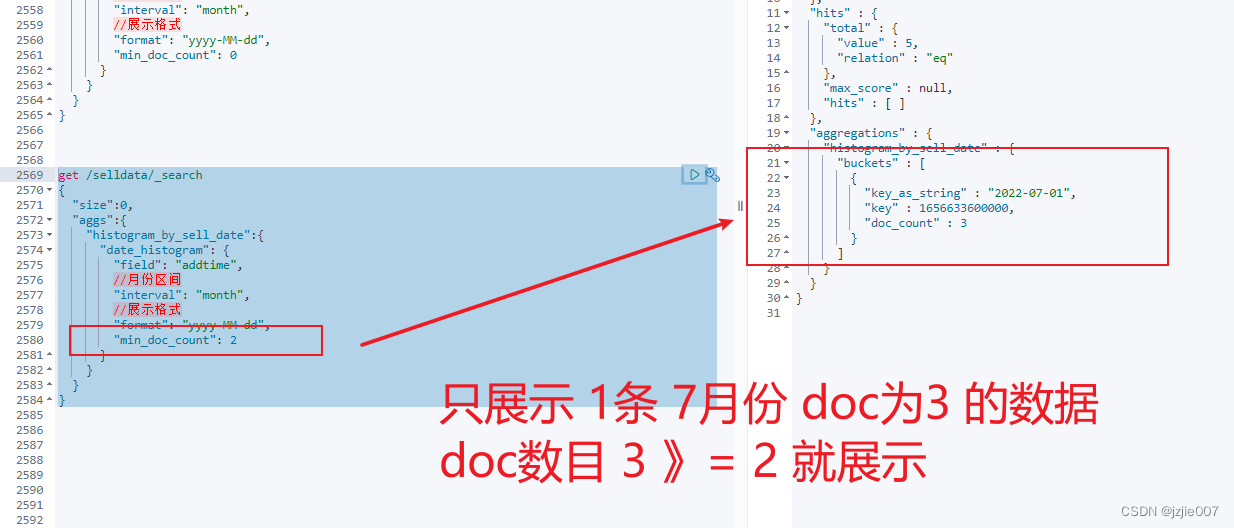
我们加一个参数 extend_bounds
经过刚才的查找, 我们看到 最早时间是 2022-04-01, 最晚时间在 2022-07-01 ,我们现在限制控制下 查询的开始时间及结束时间
不设置 extend_bounds 开 始时间时 2022-04-01 ~ 2022-07-01 就是数据存在的第一个月,及数据结束的最后一个月
现在设置 “extended_bounds”: { “min”: “2022-02-01”, “max”: “2022-09-30” } 意思就是 从 2022-02-01 开始 到 2022-09-01 结束,验证一下结果
# extended_bounds 控制数据展示的 开始及结束时间
get /selldata/_search
{
"size":0,
"aggs":{
"histogram_by_sell_date":{
"date_histogram": {
"field": "addtime",
//月份区间
"interval": "month",
//展示格式
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2022-02-01",
"max": "2022-09-30"
}
}
}
}
}
查询结果 ,可以看到的确是 从我们指定的 min,max日期开始进行统计展示
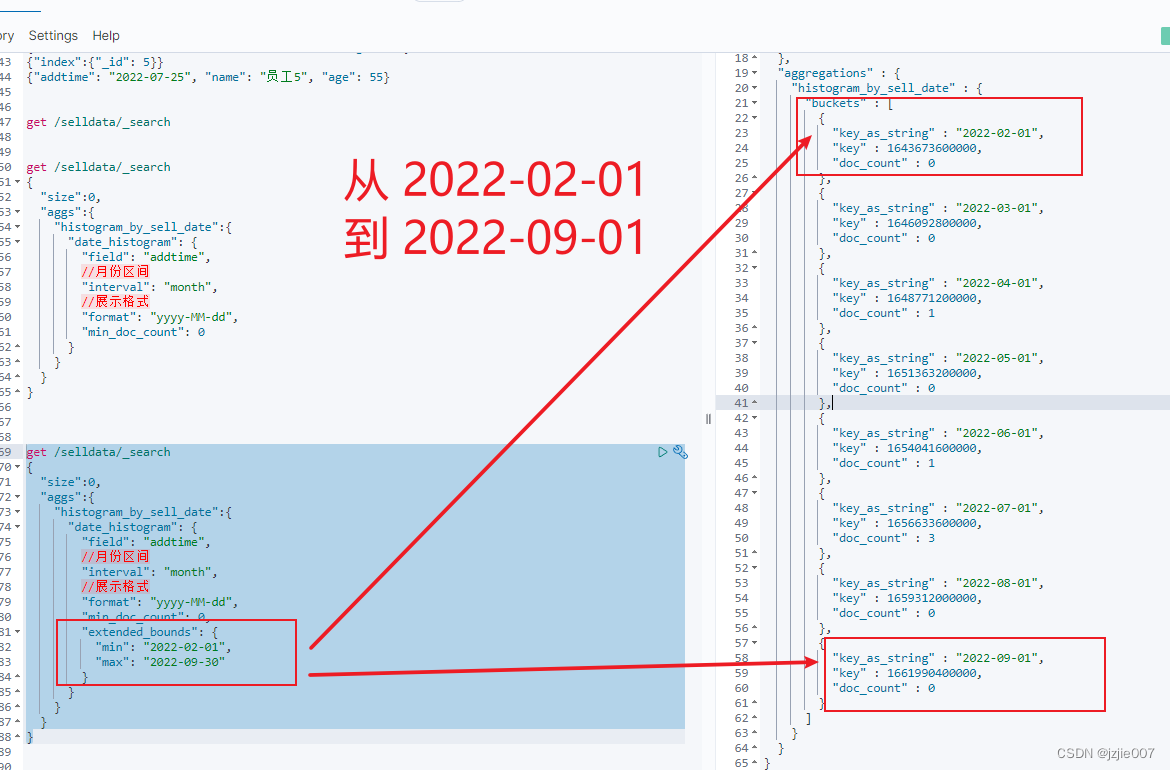
回到最初的问题,实现时间区间统计,统计 按照month区间,来统计 每个区间的年龄 平均值
get /selldata/_search
{
"size":0,
"aggs":{
"histogram_by_sell_date":{
"date_histogram": {
"field": "addtime",
//月份区间
"interval": "month",
//展示格式
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2022-02-01",
"max": "2022-09-30"
}
},
//分组内 date_histogram 同级 进行aggs 平均年龄统计
"aggs":{
"avg_age":{
"avg": {
"field": "age"
}
}
}
}
}
}
查询结果,符合预期
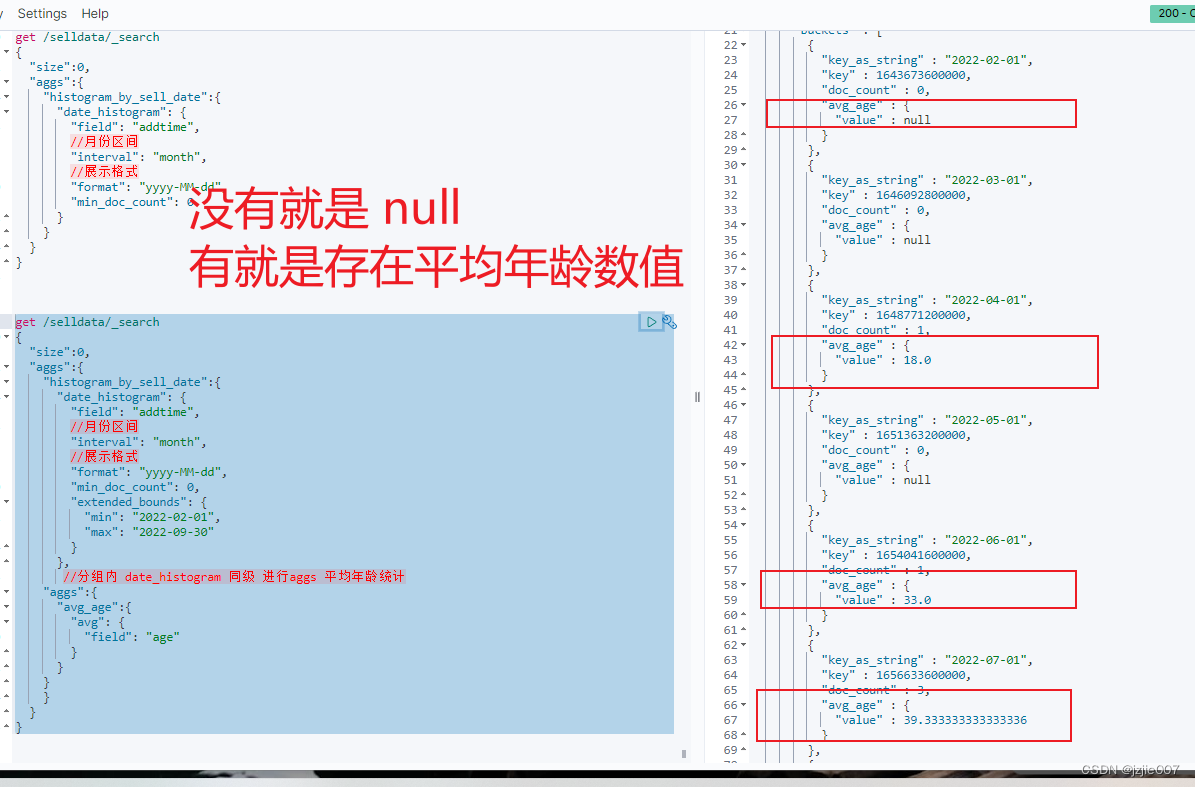
至此 我们已经学习了 TOP N分组内获取前N条数据的实现逻辑, 及如何使用区间统计histogram来对每一个区间内的数据进行统计分析, 及 如何使用date_histrogram 来进行时间区间统计
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我目前有一个reddit克隆类型的网站。我正在尝试根据我的用户之前喜欢的帖子推荐帖子。看起来K最近邻或k均值是执行此操作的最佳方法。我似乎无法理解如何实际实现它。我看过一些数学公式(例如k表示维基百科页面),但它们对我来说并没有真正意义。有人可以推荐一些伪代码,或者可以查看的地方,以便我更好地了解如何执行此操作吗? 最佳答案 K最近邻(又名KNN)是一种分类算法。基本上,您采用包含N个项目的训练组并对它们进行分类。如何对它们进行分类完全取决于您的数据,以及您认为该数据的重要分类特征是什么。在您的示例中,这可能是帖子类别、谁发布了该项
我查看了Stripedocumentationonerrors,但我仍然无法正确处理/重定向这些错误。基本上无论发生什么,我都希望他们返回到edit操作(通过edit_profile_path)并向他们显示一条消息(无论成功与否)。我在edit操作上有一个表单,它可以POST到update操作。使用有效的信用卡可以正常工作(费用在Stripe仪表板中)。我正在使用Stripe.js。classExtrasController5000,#amountincents:currency=>"usd",:card=>token,:description=>current_user.email)