当前,很多自然语言处理(NLP)应用需要高质量的标注数据来支撑,特别是当这些数据被用于训练分类器或评估无监督模型的性能等任务中。
例如,人工智能研究人员通常希望过滤嘈杂的社交媒体数据的相关性,将文本分配到不同的主题或概念类别,或衡量其情绪或立场。
而且,无论这些任务使用什么具体方法(监督、半监督或无监督),都需要标注好的数据来建立一个训练集或黄金标准。
然而,在大多数情况下,要完成高质量的数据标注(data annotation)工作,依然离不开数据标注平台上的众包工作者或诸如研究助理等训练有素的标注者来手动进行。
通常情况下,训练有素的标注者先创建一个相对较小的黄金标准数据集,然后雇用众包工作者来增加标注数据的数量,进行重复性工作。根据规模大小和复杂程度,数据标注任务有时会非常费时费力,不仅需要花费一定的人力成本,而且也不能保证数据标注的质量。
那么,能否让机器帮助人类完成这一基础任务呢?
在以往的认知中,机器并不擅长这类「慢工出细活」的任务,但出乎意料的是,「数据标注」这件事已经让 ChatGPT 完成了,而且比大多数人做得还更好。

在一项今天发表的新研究中,来自苏黎世大学的研究团队使用由 2382 条推文组成的样本,证明了 ChatGPT 在相关性、主题和框架检测等标多个注任务上优于众包工作者。
相关研究论文以「ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks」为题,已发表在预印本网站 arXiv 上。
具体来说,ChatGPT 在五项任务的四项中的零样本(zero-shot)准确率超过了众包工作者;在所有任务中表现出的编码者间一致性(intercoder agreement)方面,ChatGPT 不仅超过了众包工作者,也同样超过了训练有素的标注者。
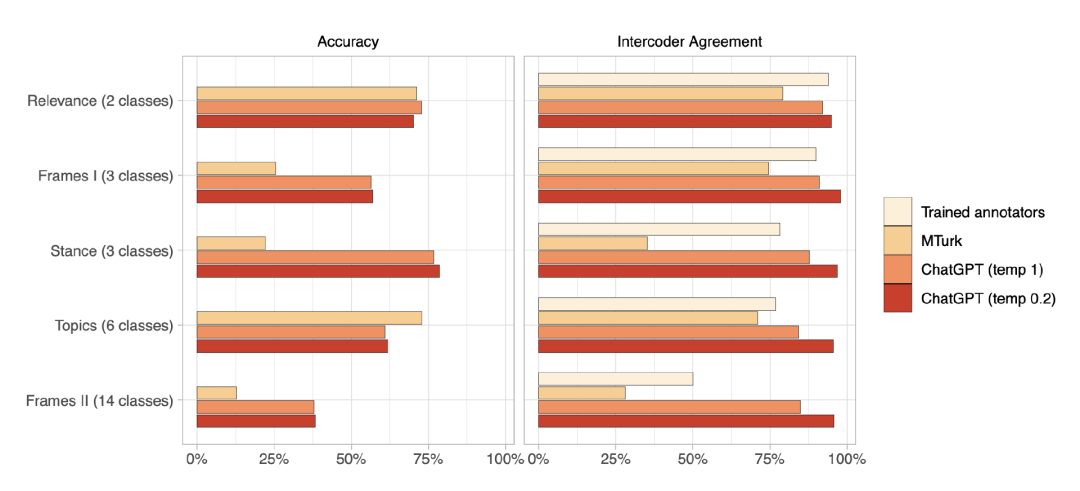
ChatGPT 零样本文本数据标注表现
值得一提的是,ChatGPT 的每个标注成本只有不到 0.003 美元,而比数据标注平台便宜约 20 倍。
研究团队认为,虽然需要进一步的研究来更好地了解 ChatGPT 和其他 LLMs 在更广泛的背景下的表现,但该研究结果表明,它们有可能改变研究人员进行数据注释的方式,极大地提高文本分类的效率,并破坏数据标注平台的部分商业模式。
至少,从目前来看,这些发现表明了更深入地研究 LLMs 的文本标注特性和能力的重要性。
未来,研究团队将在 ChatGPT 在多种语言中的表现、ChatGPT 在多种类型的文本(社会媒体、新闻媒体、立法、演讲等)中的表现、使用思维链(CoT)提示和其他策略来提高零样本推理的性能等方面继续努力。
值得一提的是,研究团队在进行这项工作时,OpenAI 还没有发布 GPT-4,如果让 GPT-4 来完成数据标注任务,又会是怎样的结果呢?
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
-if!request.path_info.include?'A'%{:id=>'A'}"Text"-else"Text"“文本”写了两次。我怎样才能只写一次并同时检查path_info是否包含“A”? 最佳答案 有两种方法可以做到这一点。使用部分,或使用content_forblock:如果“文本”较长,或者是一个重要的子树,您可以将其提取到一个部分。这会使您的代码变干一点。在给出的示例中,这似乎有点矫枉过正。在这种情况下更好的方法是使用content_forblock,如下所示:-if!request.path_info.inc
我查看了Stripedocumentationonerrors,但我仍然无法正确处理/重定向这些错误。基本上无论发生什么,我都希望他们返回到edit操作(通过edit_profile_path)并向他们显示一条消息(无论成功与否)。我在edit操作上有一个表单,它可以POST到update操作。使用有效的信用卡可以正常工作(费用在Stripe仪表板中)。我正在使用Stripe.js。classExtrasController5000,#amountincents:currency=>"usd",:card=>token,:description=>current_user.email)
我写了一个脚本,其中包含一些方法定义,没有类和一些公共(public)代码。其中一些方法执行一些非常耗时的shell程序。然而,这些shell程序只需要在第一次调用该方法时执行。现在在C中,我会在每个方法中声明一个静态变量,以确保这些程序只执行一次。我怎么能在Ruby中做到这一点? 最佳答案 ruby中有一个成语:x||=y。defsomething@something||=calculate_somethingendprivatedefcalculate_something#somelongprocessend但是如果您的“长时间
我想在格式化数字时每隔三个字符放置一个空格。根据这个规范:it"shouldformatanamount"dospaces_on(1202003).should=="1202003"end我想出了这段代码来完成这项工作defspaces_onamountthousands=amount/1000remainder=amount%1000ifthousands==0"#{remainder}"elsezero_padded_remainder='%03.f'%remainder"#{spaces_onthousands}#{zero_padded_remainder}"endend所以我
提供3种Ubuntu系统安装微信的方法,在Ubuntu20.04上验证都ok。1.WineHQ7.0安装微信:ubuntu20.04安装最新版微信--可以支持微信最新版,但是适配的不是特别好;比如WeChartOCR.exe报错。2.原生微信安装:linux系统下的微信安装(ubuntu20.04)--微信适配的最好,反应最快,但是微信版本只到2.1.1,版本太老,很多功能都没有。3.深度deepin-wine6安装微信:ubuntu20.04+系统deepin-wine6安装新版微信--综合比较好,当前个人使用此种方法1个月,微信版本3.4;没什么大问题,尚可。一、WineHQ7.0安装微信