对于一组数据,并查集主要支持两个动作:
union(p,q) - 将 p 和 q 两个元素连接起来。
find(p) - 查询 p 元素在哪个集合中。
isConnected(p,q) - 查看 p 和 q 两个元素是否相连接在一起。
在上一小节中,我们用 id 数组的形式表示并查集,实际操作过程中查找的时间复杂度为 O(1),但连接效率并不高。
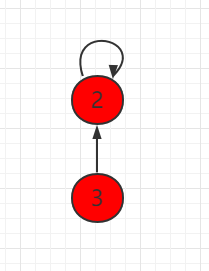
本小节,我们将用另外一种方式实现并查集。把每一个元素,看做是一个节点并且指向自己的父节点,根节点指向自己。如下图所示,节点 3 指向节点 2,代表 3 和 2 是连接在一起的,节点2本身是根节点,所以指向自己。
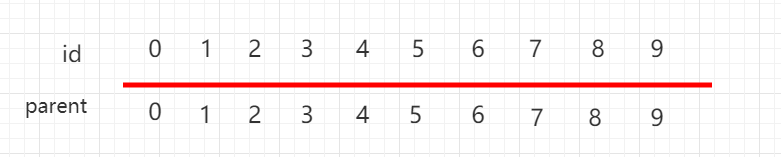
同样用数组表示并查集,但是下面一组元素用 parent 表示当前元素指向的父节点,每个元素指向自己,都是独立的。

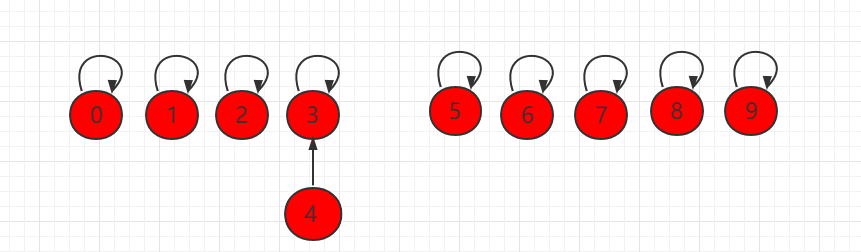
如果此时操作 union(4,3),将元素 4 指向元素 3:
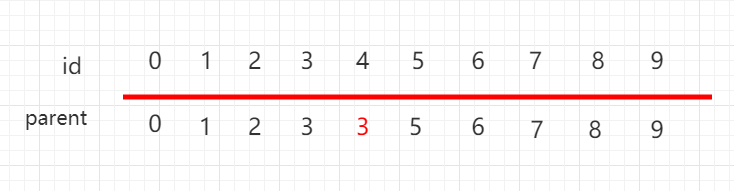
数组也进行相应改变:
判断两个元素是否连接,只需要判断根节点是否相同即可。
如下图,节点 4 和节点 9 的根节点都是 8,所以它们是相连的。
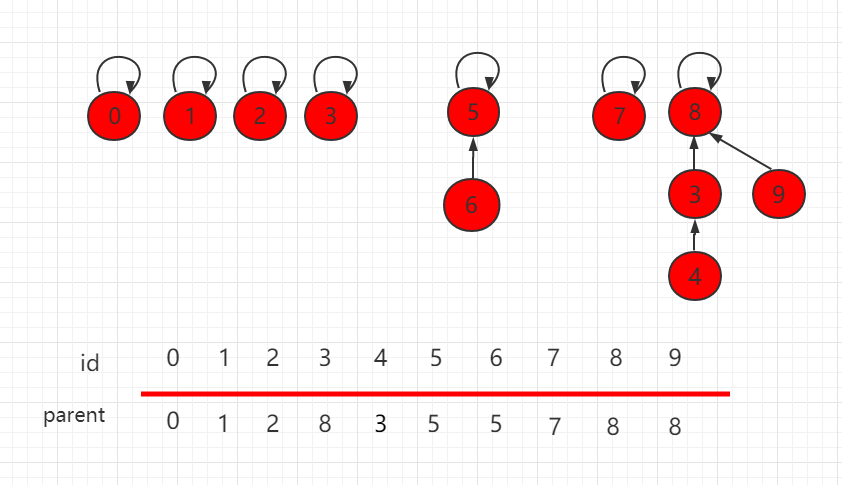
连接两个元素,只需要找到它们对应的根节点,使根节点相连,那它们就是相连的节点。
假设要使上图中的 6 和 4 相连,只需要把 6 的根节点 5 指向 4 的根节点 8 即可。
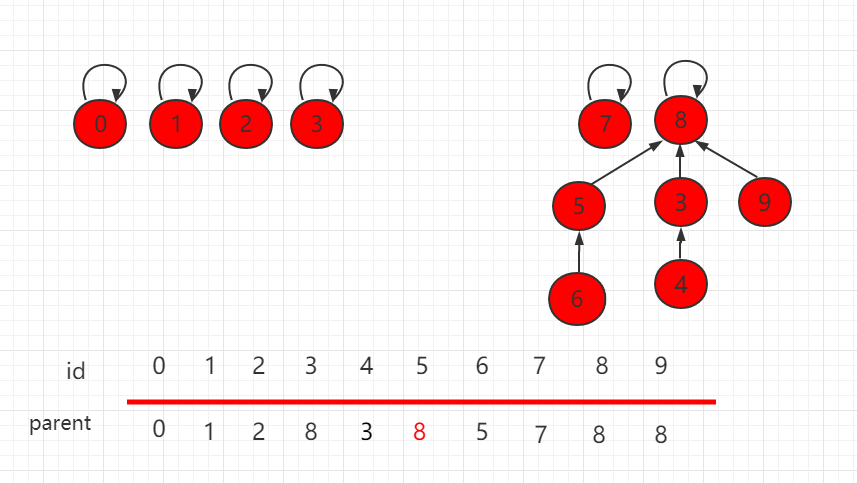
构建这种指向父节点的树形结构, 使用一个数组构建一棵指向父节点的树,parent[i] 表示 i 元素所指向的父节点。
查找过程, 查找元素 p 所对应的集合编号,不断去查询自己的父亲节点, 直到到达根节点,根节点的特点 parent[p] == p,O(h) 复杂度, h 为树的高度。
合并元素 p 和元素 q 所属的集合,分别查询两个元素的根节点,使其中一个根节点指向另外一个根节点,两个集合就合并了。这个操作是 O(h) 的时间复杂度,h 为树的高度。
源码包下载:Download
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu
有没有办法快速将表格格式的ruby哈希打印到文件中?如:keyAkeyBkeyC...1232343451253474456...其中散列的值是不同大小的数组。还是使用双循环是唯一的方法?谢谢 最佳答案 试试我写的这个gem(在表中打印散列、ruby对象、ActiveRecord对象):http://github.com/arches/table_print 关于ruby-如何以表格格式快速打印Ruby哈希值?,我们在StackOverflow上找到一个类似的问题:
之前有人问过这个问题,我发现了以下clip关于如何一次设置一个类对象的所有属性,但由于批量分配保护,这在Rails中是不可能的。(例如,您不能Object.attributes={})有没有一种很好的方法可以将一个类的属性合并到另一个类中?object1.attributes=object2.attributes.inject({}){|h,(k,v)|h[k]=vifObjectModel.column_names.include?(k);h}谢谢。 最佳答案 利用assign_attributes使用:without_prote
我一直在尝试使用nanoc用于生成静态网站。我需要组织一个复杂的排列页面,我想让我的内容保持干燥。包含或合并的概念在nanoc系统中如何运作?我已阅读文档,但似乎找不到我想要的内容。例如:我如何获取两个部分内容项并将它们合并到一个新的内容项中。在staticmatic您可以在您的页面中执行以下操作。=partial('partials/shared/navigation')类似的约定在nanoc中如何运作? 最佳答案 这里是nanoc的作者。在nanoc中,部分是布局。因此,您可以拥有layouts/partials/shared/
电脑启动出现显示器黑屏是一个相当常见的问题。如果您遇到了这个问题,不要惊慌,因为它有很多可能的原因,可以采取一些简单的措施来解决它。在本文中,小编将介绍下面4种常见的电脑启动后显示器黑屏的原因,排查这些原因,快速解决! 演示机型:联想Ideapad700-15ISK-ISE系统版本:Windows10一、显示器问题如果出现电脑启动后显示器黑屏的情况。那么首先您需要检查一下显示器是否正常工作。您可以通过更换另一个显示器或将当前显示器连接到另一台计算机来检查显示器是否存在问题。如果问题仍然存在,那么您可以排除显示器故障的可能性。 二、显卡问题如果您的电脑配备了独立显卡,那么显卡故障也可能是导致电脑
我很难理解我需要合并两个哈希数组的逻辑,看来我已经问过hisquestionawhileback以不同的方式,我还尝试了其他一些方法,例如此处提供的答案:mergingarraysofhashes任何形式的帮助理解这对我来说都是非常有帮助的。假设我有以下数组,这是方法本身的输出,所以你可以想象那些:timestamp是Time对象[{:timestamp=>2011-12-1900:00:00UTC},{:timestamp=>2011-12-1901:00:00UTC},{:timestamp=>2011-12-1902:00:00UTC},{:timestamp=>2011-12-
mutationtesting遇到一个问题是它很慢,因为默认情况下您会为每个生成的突变执行完整的测试运行(测试文件或一组测试文件)。加快突变测试的一种方法是,一旦遇到单一故障(但仅在突变测试期间),就停止对给定突变体的测试运行。更好的做法是让变异测试者记住杀死最后一个变异体的第一个测试是什么,并将其首先交给下一个变异体。ruby中是否有任何东西可以做这些事情,或者我最好的选择是开始猴子修补?(是的,我知道单元测试应该很快。显示所有失败的测试在突变测试之外很有用,因为它不仅可以帮助您识别出问题,还可以查明哪里出了问题)编辑:我目前正在对测试/单元使用heckle。如果测试/单元不可能记住
我有两个类:1.Sale是ActiveRecord的子类;它的工作是将销售数据持久保存到数据库中。classSale2.SalesReport是一个标准的Ruby类;它的工作是生成和绘制有关销售的信息。classSalesReportdefinitialize(start_date,end_date)@start_date=start_date@end_date=end_dateenddefsales_in_durationSale.total_for_duration(@start_date,@end_date)end#...end因为我想使用TDD并且我希望我的测试运行得非常快,所