Elasticsearch 映射如果不做特殊处理,默认 dynamic 为 true。dynamic 为 true 的确切含义是:根据导入的数据自定识别字段类型(有可能不精确),也就是说,可以提前不指定 Mapping,也能写入数据。
但,这导致的问题也非常明显。Mapping 字段越多,会超过默认字段数上限。超过上限后会导致性能下降和内存问题,特别是在高负载或资源有限的集群中表现更为突出。
举例:index.mapping.total_fields.limit 限制的默认最大字段数为 1000。
之前被问过类似的问题:
“博主,我们现在的业务场景是在宽表中,2000+个字段的联合查询,但是es默认单个索引的字段数是1000个,过多会导致内存问题,和es的性能问题,该如何解决这样的场景呢?”
如下所示,如果任由“sub_field”字段扩展,就会导致 Mapping “爆炸”。
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field",
"field4": {
"sub_user": "a sub field",
"sub_amount": "another sub field",
"sub_field3": "yet another subfield",
"sub_field4": "yet another subfield",
"sub_field5": "yet another subfield",
"sub_field6": "yet another subfield",
"sub_field7": "yet another subfield",
"sub_field8": "yet another subfield",
"sub_field9": "yet another subfield",
"sub_fieldx": "yet another subfield"
}
}
}实际业务中不见得所有的字段都需要检索和聚合操作,但如上所有字符串类型都被映射为 “text” 和 “keyword” 组合类型。
我们将浪费内存和磁盘空间来存储这些字段,极大可能这些字段中的某些字段从未被使用过,它们存在的目的仅是:"万一 "它们需要被用于搜索。
第一:业务层面要尽可能的梳理清楚需求,尽可能避免后期的需求变更导致的 Mapping 的大改。
第二:技术层面要贴合业务需求,合理、规范、站在未来用户使用的角度建模。
dynamic 一旦设置为 strict,就意味着只要字段不在初始设定的范围内,就禁止写入。这是最严格的 Mapping 控制策略。
举例,如下的索引创建dynamic 设置为 strict,而后导入了预制 Mapping 中没有的字段 “field3”。
DELETE dynamic-mapping-test
PUT dynamic-mapping-test
{
"mappings": {
"dynamic": "strict",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field"
}
}写入 “field3”会报错如下:
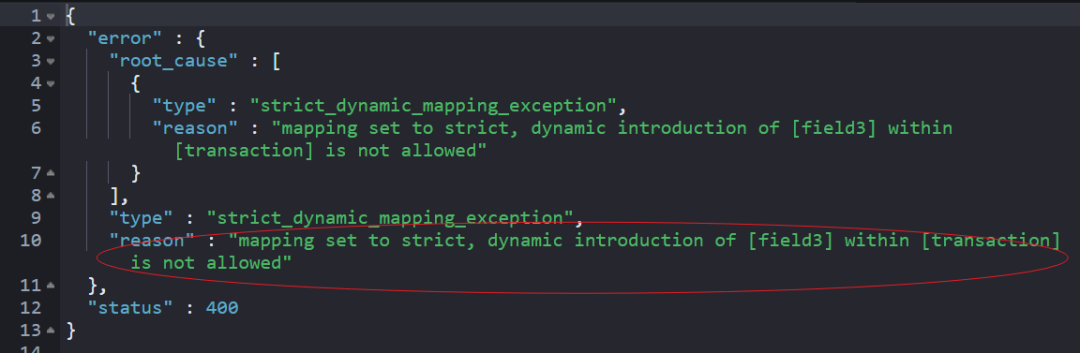
"dynamic:strict" 应用场景:
确定业务层面 Mapping 一经敲定,后面不再修改,则可大胆使用 strict。
这对业务层面、需求层面要求非常高!
如果 dynamic 设置为 true 代表很“宽泛”的要求;dynamic 设置为 strict 代表很‘’严格”近乎苛刻的要求。
则,dynamic 设置为 false 则代表介于两者中间的要求。
如下所示,批量写入数据的时候,写入了 mapping 中没有的字段 title。
PUT dynamic-mapping-disabled
{
"mappings": {
"dynamic": "false",
"properties": {
"message": {
"type": "text"
}
}
}
}
POST dynamic-mapping-disabled/_bulk
{"index":{"_id":1}}
{"title":"elasticsearch is very good!"}写入不会报错。但写入后查看一下 Mapping。
GET dynamic-mapping-disabled/_mapping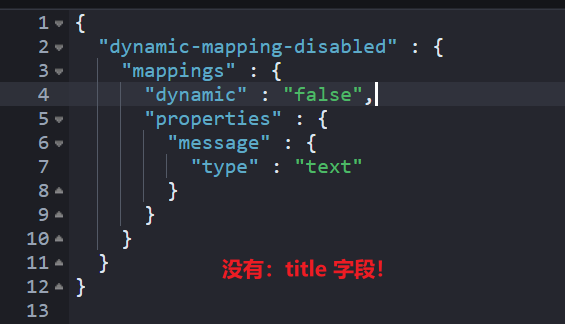
执行检索和聚合操作如下,检索和聚合均没有任何数据召回。
## 如下查询,没有任何数据召回!
POST dynamic-mapping-disabled/_search
{
"query": {
"match": {
"title": "good"
}
}
}
## 如下聚合,没有任何数据召回
POST dynamic-mapping-disabled/_search
{
"size":0,
"aggs": {
"terms_aggs": {
"terms": {
"field": "title",
"size": 10
}
}
}
}"dynamic:false" 应用场景:
当设置 dynamic 为 false 时,非 Mapping 指定的字段数据,如上“title”也可以写入索引。但,并没有建立倒排索引和正排索引,也就是说,不会被检索和聚合召回。仅在_source 中被召回显示。这些字段仅会浪费磁盘空间,不会占据内存空间。
POST dynamic-mapping-disabled/_search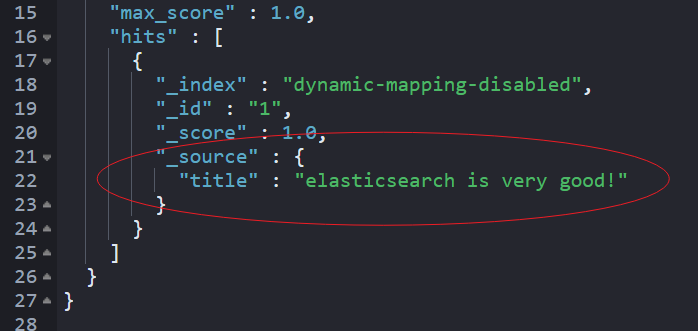
之前咱们已经过 runtime field 的来龙去脉。
如果把没有 runtime field 之前的 Mapping 叫做 shema on write,那么 runtime field 革命性创新在与其是 schema on read。
runtime field 的本质是:不会在新字段上浪费内存存储,但我们要付出查询或聚合操作响应速度变慢的代价。
仍拿之前的索引和数据为例。
DELETE dynamic-mapping-runtime
PUT dynamic-mapping-runtime
{
"mappings": {
"dynamic": "runtime",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}
POST dynamic-mapping-runtime/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field",
"field4": {
"sub_user": "a sub field",
"sub_amount": "another sub field",
"sub_field3": "yet another subfield",
"sub_field4": "yet another subfield",
"sub_field5": "yet another subfield",
"sub_field6": "yet another subfield",
"sub_field7": "yet another subfield",
"sub_field8": "yet another subfield",
"sub_field9": "yet another subfield"
}
}
}GET dynamic-mapping-runtime/_mappingMapping 返回如下:
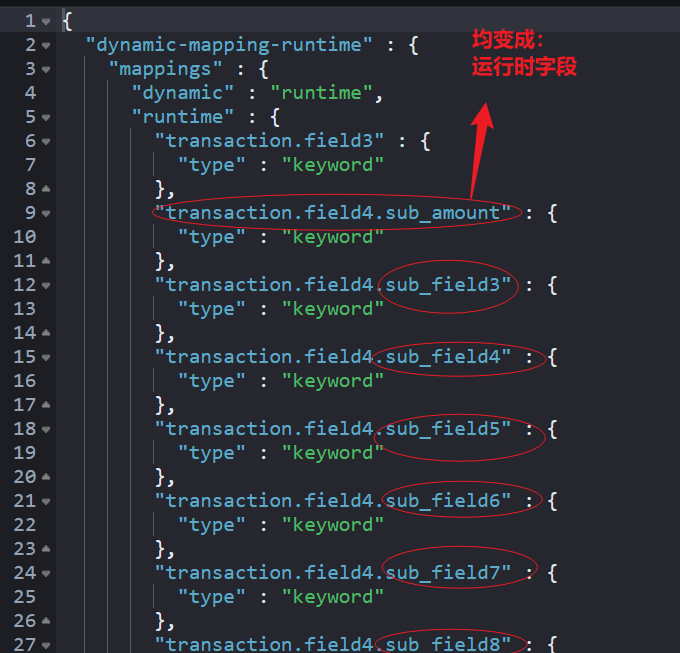
这些运行时的字段是可以被检索的,举例如下:
POST dynamic-mapping-runtime/_search
{
"query": {
"term": {
"transaction.field4.sub_field6": "yet another subfield"
}
}
}"dynamic:runtime" 应用场景:
当不知道要写入什么类型的文档时,这个策略会很有用!使用运行时字段是一个保守的方法,需要在性能和映射复杂性之间有一个很好的权衡。
每种方案都有优点,当然也存在不足,我们需要结合自己业务场景仔细斟酌后选型。
| 类别 | 优点 | 缺点 |
|---|---|---|
| strict | 字段必须先明确指定 | 非明确指定的字段,禁止写入 |
| false | 所有字段均可写入 | 未被映射的字段不能用于搜索或聚合 |
| runtime | 更为灵活的方式 | 在查询运行时字段时,搜索响应时间相对较慢,需要做好取舍、权衡利弊 |
大家还有没有更好的方案?欢迎留言交流。
1、https://www.elastic.co/cn/blog/3-ways-to-prevent-mapping-explosion-in-elasticsearch
2、Elasticsearch 运行时类型 Runtime fields 深入详解
3、阿里云大佬叮嘱我务必要科普这个 Elasticsearch API
4、Elasticsearch 可以更改 Mapping 吗?如何修改?

更短时间更快习得更多干货!
中国50%+Elastic认证专家出自于此!
在不确定的时代,寻求确定性!

比同事抢先一步学习进阶干货!
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我有一个ActiveRecord对象,我想在不对模型进行永久验证的情况下阻止它被保存。您过去可以使用errors.add执行类似的操作,但它看起来不再有效了。user=User.lastuser.errors.add:name,"namedoesn'trhymewithorange"user.valid?#=>trueuser.save#=>true或user=User.lastuser.errors.add:base,"myuniqueerror"user.valid?#=>trueuser.save#=>true如何在不修改用户对象模型的情况下防止将用户对象保存在Rails3.2中
是否可以让这段代码更紧凑?我在这里错过了什么吗?ifvaluemax_ratemax_rateelsevalueend 最佳答案 这里有一些完全不同的东西:[min_rate,value,max_rate].sort[1] 关于ruby-如何更优雅地记下这三种情况?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/13309740/
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
Ruby中防止SQL注入(inject)的好方法是什么? 最佳答案 直接使用ruby?使用准备好的语句:require'mysql'db=Mysql.new('localhost','user','password','database')statement=db.prepare"SELECT*FROMtableWHEREfield=?"statement.execute'value'statement.fetchstatement.close 关于ruby-防止SQL注入(inject
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion我想知道是否有人知道Ruby的rubyzip替代品,它可以处理各种格式,特别是zip/rar/7z?我知道libarchive,但它对我的目的来说并不完整(它是一个很好的gem)。(澄清一下,libarchive-对我不起作用-因为
我在生产环境(CentOS5.6)中遇到此错误,但在开发环境(Ubuntu11.04)中运行良好。在这两种环境中,该应用程序都使用Ruby1.9.3和Rails3.0.9,并由passenger和nginx提供服务。我的Mechanizegem版本是2.3。未找到代码转换器(UTF-8)此代码的最后一行触发它:mech=Mechanize.newpage=mech.get("http://myurl.com/login.php?login_name=a&password=b")form=page.form_with(:name=>"loginForm")form.field_with(