
为了提升应用稳定性,我们对前端项目开展了脚本异常治理的工作,对生产上报的js error进行了整体排查,试图通过降低脚本异常的发生频次来提升相关告警的准确率,结合最近在这方面阅读的相关资料,尝试阶段性的做个总结,下面我们来介绍下js异常处理的一些经验。
先来看一下官方的定义:
Error objects are thrown when runtime errors occur. The Error object can also be used as a base object for user-defined exceptions.
描述的很简单,我们总结一下就是代码在执行过程中遇到了问题,程序已经无法正常运行了,Error对象会被抛出,这一点它不同于大部分编程语言里使用的异常对象Exception,甚至更适合称之为错误,应该说事实也确实如此,Error对象在未被抛出时候和js里其他的普通对象没有任何差别是不会引发异常的,同时Error 对象也可用于用户自定义错误的基础对象。
看下面两个例子:
try {
const 123variable = 2;
} catch(e) {
console.log('捕获到了:', e)
}↓↓↓执行结果↓↓↓

结论:只有在执行过程中的异常可以被捕获,语法解析阶段的异常或者不在当前同步任务中的异常都无法被捕获。
<script>
function throwSomeError() {
throw new Error('抛个异常玩玩');
console.log('我估计是凉了,不会执行我了!');
}
throwSomeError();
console.log('那么我呢?')
</script>
<script>
console.log('大家猜猜我会执行吗?');
</script>↓↓↓执行结果↓↓↓
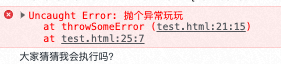
以上红色信息里包含了异常信息(message)和栈跟踪(stack trace)信息,对于定位代码中的问题起到重要作用,可以看到栈跟踪是从底部文件位置21:15到顶部25:7位置的;前两个console在遇到异常时候未被执行,第二个script标签内的代码被正常执行。
结论:当任务执行过程中出现未处理的异常,会一直沿着调用栈一层层向外抛出(有点像事件冒泡),最终会导致当前任务被终止执行。当前任务终止后JS 线程会继续从任务队列中提取下一个任务继续执行。
异常的类型
|
错误名 |
描述 |
示例 |
|
EvalError |
关于 eval [1]函数的错误,已不在当前ECMAScript规范中使用,不再会被运行时抛出。 |
throw new EvalError('EvalError', 'file.js', 10); // 可以由业务代码主动抛出 |
|
RangeError |
值不在允许的范围内,典型的是试图传递一个数值给一个范围内不包含该数值的函数,此时应该引发RangeError。 |
const numObj = 123; numObj.toFixed(-1); // Uncaught RangeError: toFixed() digits argument must be between 0 and 100 at Number.toFixed |
|
ReferenceError |
当一个不存在(或尚未初始化)的变量被引用时发生的错误。 |
const a = undefinedVariable; // Uncaught ReferenceError: undefinedVariable is not defined |
|
SyntaxError |
解析代码阶段,发现了不符合语法规范的代码。 |
const 111variable = 1; // Uncaught SyntaxError: Invalid or unexpected token |
|
TypeError |
类型错误,用来表示值的类型是非预期类型。 |
const a = null; a.doSomeThing(); // Uncaught TypeError: Cannot read properties of null (reading 'doSomeThing') |
|
URIError |
使用URI处理函数产生的错误 |
decodeURIComponent('%') // Uncaught URIError: URI malformed |
1.以上这些异常很多都来会由Javascript引擎抛出,但异常类型都是实际的构造函数,旨在生成一个新的异常实例,所以你可以:
// 获取分页数据
const getPagedData = (pageIndex, pageSize) => {
if(pageIndex < 0 || pageSize < 0 || pageSize > 1000) {
throw new RangeError(`pageIndex 必须大于0, pageSize必须在0和1000之间`);
}
return [];
}
// 转换时间格式
const dateFormat = (dateObj) => {
if(dateObj instanceof Date) {
return 'formated date string';
}
throw new TypeError('传入的日期类型错误');
}2.Error实例被创建时不能被称之为异常,只有在使用throw关键字将其抛出时才会引发异常;
new Error('出错了!');
console.log('我吃嘛嘛香,喝嘛嘛棒!'); // 正常输出 '我吃嘛嘛香,喝嘛嘛棒!'3.技术上来讲,你可以抛出任何类型的异常,而不仅仅是Error的实例,但请不要这么做,总是抛出正确的错误对象会让我们更容易定位问题,同时可以保持错误处理的一致性,捕获异常时候也总能够拿到Error实例上的message和stack;
// bad
throw '出错了';
throw 123;
throw [];
throw null;
异常捕获
前面有提到如果引发异常后不做任何处理会冒泡似的在你的调用栈中向顶部传播,直到导致当前任务崩溃。有时候发生致命错误时候我们确实希望安全的停止程序的运行,如果希望程序得以恢复一般我们会用到try...catch...finally代码结构,它是js中处理异常的标准方式;
try {
// 要运行的代码,可能引发异常
doSomethingMightThrowError();
}
catch (error) {
// 处理异常的代码块,当发生异常时将会被捕获,如果不继续throw则不会再向上传播
// error为捕获的异常对象
// 这里一般能让程序恢复的代码
doRecovery();
}
finally {
// 无论是否出现异常,始终都会执行的代码
doFinally();
}被忽略的finally:此语句块会在try和catch语句结束之后执行,无论结果是否报错。
同时要注意,异步中的发生的异常无法被上层捕获,比如:
// Timeout
try {
setTimeout(() => {
throw Error("定时器出错了!");
}, 1000);
} catch (error) {
console.error(error.message);
}
// Events
try {
window.addEventListener("click", function() {
throw Error("点击事件出错了!");
});
} catch (error) {
console.error(error.message);
}Promise本身是就可以捕获异常,语法上也类似于try catch,一旦发生异常,程序跳过promise内的代码继续执行;可以使用了catch方法捕获后进行处理,也可以使用then方法中的第二个参数处理异常。promise的异常对象同样是冒泡的,前者捕获了就不会抛给后者,参见示例:
const promiseA = new Promise((resolve,reject)=>{
throw new Error('Promise出错了!');
});
const doSomethingWhenResolve = () => {};
const doSomethingWhenReject = (error) => {
logger.log(error)
}
// 使用catch捕获
const promiseB = promiseA.then(doSomethingWhenResolve).catch(doSomethingWhenReject);
// 等价于
const promiseB = promise.then(doSomethingWhenResolve, doSomethingWhenResolve);
promiseB.then(() => {
console.log('我又可以正常进到then方法了!');
}).catch(()=>{
console.log('不会来这里!');
})如何处理异常
异常的发生不可避免,所以在软件开发中,合理的异常处理就成为了高质量代码不可或缺的一部分,只有处理好了异常我们才能对程序中的意外情况进行有效的控制。我们最容易容易犯的一个问题就是将异常处理和业务的流程混为一谈。
根据Clean Code的建议,面对异常我们可以遵循以下一些原则,提高代码质量:
Prefer Exceptions to Returning Error Codes
优先选择异常而不是错误码。
要理解这句话还是得结合例子,下面的第一段代码定义了一个Laptop类,在它的sendShutDown方法实现中,用if语句去检查了getID的返回值中是否存在无效的deviceID,错误检查会使调用者的代码变得复杂不易阅读业务逻辑,同时如果这个错误检查被遗漏也会导致代码出现问题,这个错误的处理可以交给语言让整个过程更加优雅。第二段代码中则将异常处理隔离了两个不同的逻辑,这样做会带来一些优势:
1.业务流程更加清晰易读,我们把异常和业务流程理解为两个不同的问题,可以分开去处理;
2.分开来的两个逻辑都更加聚焦,代码更简洁;
3.将处理程序异常的职责交给了编程语言,明确了边界;
// Dirty
class Laptop {
sendShutDown() {
const deviceID = getID(DEVICE_LAPTOP);
if (deviceID !== DEVICE_STATUS.INVALID) {
pauseDevice(deviceID);
clearDeviceWorkQueue(deviceID);
closeDevice(deviceID);
} else {
logger.log('Invalid handle for: ' + DEVICE_LAPTOP.toString());
}
}
getID(status) {
...
// 总是会返回deviceID,无论是不是合法有效的
return deviceID;
}
}
// Clean
class Laptop {
sendShutDown() {
try {
tryToShutDown();
} catch (error) {
logger.log(error);
}
}
tryToShutDown() {
const deviceID = getID(DEVICE_LAPTOP);
pauseDevice(deviceID);
clearDeviceWorkQueue(deviceID);
closeDevice(deviceID);
}
getID(status) {
...
throw new DeviceShutDownError('Invalid handle for: ' + deviceID.toString());
...
return deviceID;
}
}Don't ignore caught error!
捕获到异常后不要忽略异常处理!
在之前的代码评审中就经常有看到我们同学会在catch块中什么都不做,或者迫于eslint的检查会写一个console.log(error),这同样意味着什么都没有做。属于眼睁睁看到异常发生了不采取任何措施,这样的处理方式非常危险,因为这些异常通常由我们没有考虑到的意外情况引起,从中能发现业务逻辑中不易发现的问题,一旦我们捕获了这些异常,顶层的错误监控也不能主动捕获到这些问题,程序也许没有崩溃但如果没有用户告知我们,我们就无法发现用户的哪些功能无法正常使用了,因此最起码也要对这些异常做日志上报;
// bad
try {
doSomethingMightThrowError();
} catch (error) {
console.log(error);
}
// good
try {
doSomethingMightThrowError();
} catch (error){
console.error(error);
message.error(error.message);
logger.log(error);
}Don't ignore rejected promises!
不要轻易忽略Promise的异常,除非你确定它已经被处理了!
这一块我们还是有血泪教训的,在接入AEM的项目中曾经在脚本异常的上报里将disable_unhandled_rejection开启,禁止捕获了所有Promise异常,当时是基于我们线上应用大部分的promise异常都是umi-request请求接口出错和antd表单验证错误,且未带来什么线上问题,于是就天真的认为未捕获的promise异常毫无危害;这个想法同样危险,因为深入跟踪发现接口请求出错请求库捕获了异常并使用了message.error进行处理,表单验证错误的异常同样是antd在处理完之后选择继续向上抛出,这两者确实没什么危害,可当我们面对这些更多未做处理的Promise异常时候(比如接口返回成功但约定的数据格式错误)同时又不做上报,我们就损失了很多线上问题的案发现场,只能抓瞎去盲猜复现,依赖用户反馈。
查看以下案例:
// bad
fetchData().then(doSomethingMightThrowError).catch(console.log);
// good
fetchData()
.then(doSomethingMightThrowError)
.catch(error => {
console.error(error);
message.error(error.message);
logger.log(error);
});Exceptions Hierarchy
使用自定义异常,让异常层次结构分明。
管理好业务代码中的异常是非常酷的一件事,上面章节有介绍到Javascript给我们提供的一些基础的异常类型,这些异常类型并不与我们的业务相关。所以使用这些异常来控制代码中的错误也显得不那么恰当,我们的代码正是对我们业务的建模。同样的,我们也要将与业务相关的这些异常建模管理,对异常进行语义化,并在业务逻辑发生特定情况时触发。否则就算调用方捕获了异常也不知道该如何去处理。
这样做往往会带来一些好处:
1.使用error instanceof CustomBizError更容易识别异常,会让判断逻辑更简洁且已读,更容易处理捕获到的异常并恢复程序。
2.通过标准化我们的自定义错误类,让我们更容易做上层处理,比如上面有提到的接口异常我可以选择不作为脚本异常全局上报,因为通常在接口异常里就已经上报了该信息;
参考以下例子
export class RequestException extends Error {
constructor(message) {
super(`RequestException: ${mesage}`);
}
}
export class AccountException extends Error {
constructor(message) {
super(`AccountException: ${message}`);
}
}
const AccountController = {
getAccount: (id) => {
...
throw new RequestException('请求账户信息失败!');
...
}
}
// 客户端代码,创建账户
const id = 1;
const account = AccountController.getAccount(id);
if(account){
throw new AccountException('账户已存在!');
}Provide context with exceptions
提供异常上下文
异常一旦发生了,一般都会有异常信息(message)和栈跟踪(stack trace)信息还有文件名之类的来定位发生错误的现场,但哪怕是这样在定位起来还是比较困难,所以一般建议去丰富异常信息让我们定位问题更加的快速。可以是在捕获到异常的地方解释我们的意图,同时这些额外的信息也都应该只是面向我们开发者用以定位问题,不需要让使用者去感知这些异常上下文,不在用户界面中进行体现。
结合上一条的自定义错误,我们还要为这些自定义错误提供更加丰富个上下文。
局部UI的JS Error不应该导致整个应用崩溃白屏,我们应该把他的影响范围控制在最小,这是一个容易形成共识的结论,于是React 16引入了错误边界(Error Boundaries)的概念。
React Error Boundaries 官方文档[2] 里提到:
错误边界是一种 React 组件,这种组件可以捕获发生在其子组件树任何位置的 JavaScript 错误,并打印这些错误,同时展示降级 UI,而并不会渲染那些发生崩溃的子组件树。错误边界可以捕获发生在整个子组件树的渲染期间、生命周期方法以及构造函数中的错误。
ProComponents[3]的很多组件应该都有使用Error Boundaries比如ProTable,用以异常发生时只对局部UI产生影响,查看@ant-design/pro-utils中的源码可以看到和官网的处理别无二致,更多的信息查看官网有非常详细的介绍:
import { Result } from 'antd';
import type { ErrorInfo } from 'react';
import React from 'react';
// eslint-disable-next-line @typescript-eslint/ban-types
class ErrorBoundary extends React.Component<
{ children?: React.ReactNode },
{ hasError: boolean; errorInfo: string }
> {
state = { hasError: false, errorInfo: '' };
static getDerivedStateFromError(error: Error) {
return { hasError: true, errorInfo: error.message };
}
componentDidCatch(error: any, errorInfo: ErrorInfo) {
// You can also log the error to an error reporting service
// eslint-disable-next-line no-console
console.log(error, errorInfo);
}
render() {
if (this.state.hasError) {
// You can render any custom fallback UI
return <Result status="error" title="Something went wrong." extra={this.state.errorInfo} />;
}
return this.props.children;
}
}
export { ErrorBoundary };所以给我们的启示是组件库或者业务系统中的块级的一些东西(spm模型中的c位)一定要考虑好组件级别的异常处理。
基本上这是对付不可预知异常的终极解法,自动收集错误报告并在达到阈值时做出告警,属于在理想情况下异常发生后能让研发同学们能第一时间发现并定位解决问题,主要会使用2个全局事件:
window.onerror事件
JS运行中的大部分异常(包括语法错误),都会触发window上的error事件执行注册的函数,不同于try catch,onerror既可以感知同步异常也可以感知异步任务的异常(除了promise异常),使用方法如下:
// message:错误信息(字符串)。
// source:发生错误的脚本URL(字符串)
// lineno:发生错误的行号(数字)
// colno:发生错误的列号(数字)
// error:Error对象(对象)
window.onerror = function(message, source, lineno, colno, error) {
logger.log('捕获到异常:',{ message, source, lineno, colno, error });
}unhandledrejection事件
作为以上方案的补充版,promise异常的捕获依赖于全局注册unhandledrejection,使用方法如下
window.addEventListener('unhandledrejection', (e) => {
console.error('catch', e)
}, true)
1.将面向开发的异常信息转换成更友好的用户界面提示;
2.将异常信息上报到服务端让研发同学去解决这些异常;
希望大家看了本篇文章有所收获!
参考链接:
[1]https://developer.mozilla.org/zh-CN/Core_JavaScript_1.5_Reference/Global_Functions/eval
[2]https://reactjs.org/docs/error-boundaries.html
[3]https://procomponents.ant.design/
作 者 | 肖荣强(路迁)
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我正在学习Rails,并阅读了关于乐观锁的内容。我已将类型为integer的lock_version列添加到我的articles表中。但现在每当我第一次尝试更新记录时,我都会收到StaleObjectError异常。这是我的迁移:classAddLockVersionToArticle当我尝试通过Rails控制台更新文章时:article=Article.first=>#我这样做:article.title="newtitle"article.save我明白了:(0.3ms)begintransaction(0.3ms)UPDATE"articles"SET"title"='dwdwd
在Cooper的书BeginningRuby中,第166页有一个我无法重现的示例。classSongincludeComparableattr_accessor:lengthdef(other)@lengthother.lengthenddefinitialize(song_name,length)@song_name=song_name@length=lengthendenda=Song.new('Rockaroundtheclock',143)b=Song.new('BohemianRhapsody',544)c=Song.new('MinuteWaltz',60)a.betwee
我早就知道Ruby中的“常量”(即大写的变量名)不是真正常量。与其他编程语言一样,对对象的引用是唯一存储在变量/常量中的东西。(侧边栏:Ruby确实具有“卡住”引用对象不被修改的功能,据我所知,许多其他语言都没有提供这种功能。)所以这是我的问题:当您将一个值重新分配给常量时,您会收到如下警告:>>FOO='bar'=>"bar">>FOO='baz'(irb):2:warning:alreadyinitializedconstantFOO=>"baz"有没有办法强制Ruby抛出异常而不是打印警告?很难弄清楚为什么有时会发生重新分配。 最佳答案
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
我想找到在某些文本中找到一些(让它是两个)句子的好方法。什么会更好-使用正则表达式或拆分方法?你的想法?应JeremyStein的要求-有一些例子示例:输入:ThefirstthingtodoistocreatetheCommentmodel.We’llcreatethisinthenormalway,butwithonesmalldifference.IfwewerejustcreatingcommentsforanArticlewe’dhaveanintegerfieldcalledarticle_idinthemodeltostoretheforeignkey,butinthis
我遇到了一个非常奇怪的问题,我很难解决。在我看来,我有一个与data-remote="true"和data-method="delete"的链接。当我单击该链接时,我可以看到对我的Rails服务器的DELETE请求。返回的JS代码会更改此链接的属性,其中包括href和data-method。再次单击此链接后,我的服务器收到了对新href的请求,但使用的是旧的data-method,即使我已将其从DELETE到POST(它仍然发送一个DELETE请求)。但是,如果我刷新页面,HTML与"new"HTML相同(随返回的JS发生变化),但它实际上发送了正确的请求类型。这就是这个问题令我困惑的
我对图像处理完全陌生。我对JPEG内部是什么以及它是如何工作一无所知。我想知道,是否可以在某处找到执行以下简单操作的ruby代码:打开jpeg文件。遍历每个像素并将其颜色设置为fx绿色。将结果写入另一个文件。我对如何使用ruby-vips库实现这一点特别感兴趣https://github.com/ender672/ruby-vips我的目标-学习如何使用ruby-vips执行基本的图像处理操作(Gamma校正、亮度、色调……)任何指向比“helloworld”更复杂的工作示例的链接——比如ruby-vips的github页面上的链接,我们将不胜感激!如果有ruby-
我有一个super简单的脚本,它几乎包含了FayeWebSocketGitHub页面上用于处理关闭连接的内容:ws=Faye::WebSocket::Client.new(url,nil,:headers=>headers)ws.on:opendo|event|p[:open]#sendpingcommand#sendtestcommand#ws.send({command:'test'}.to_json)endws.on:messagedo|event|#hereistheentrypointfordatacomingfromtheserver.pJSON.parse(event.d