目录
①需要从第三方获取数据,第三方接口有两个参数,开始时间和结束时间
②获取回来的数据并没有入库,所以不能通过数据库将数据归类统计,excel合并大概的流程是判断上一行或者左右相邻列是否相同,然后进行合并,所以不能是零散的数据且客户要求每一个自治区和每一个航站要统计总数(后续会出一个数据整合文章),咱们默认数据已经整理好了.效果如下:
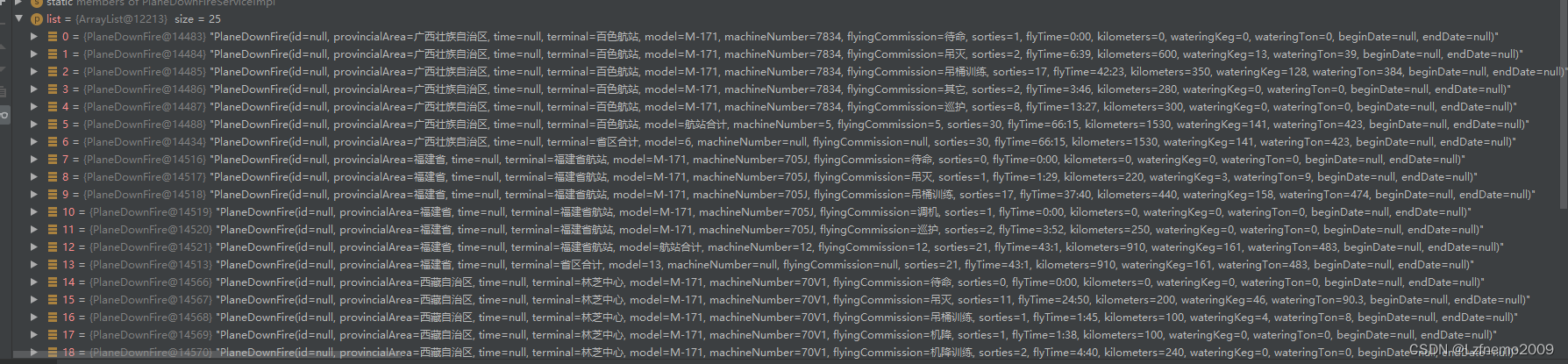
③最终效果:
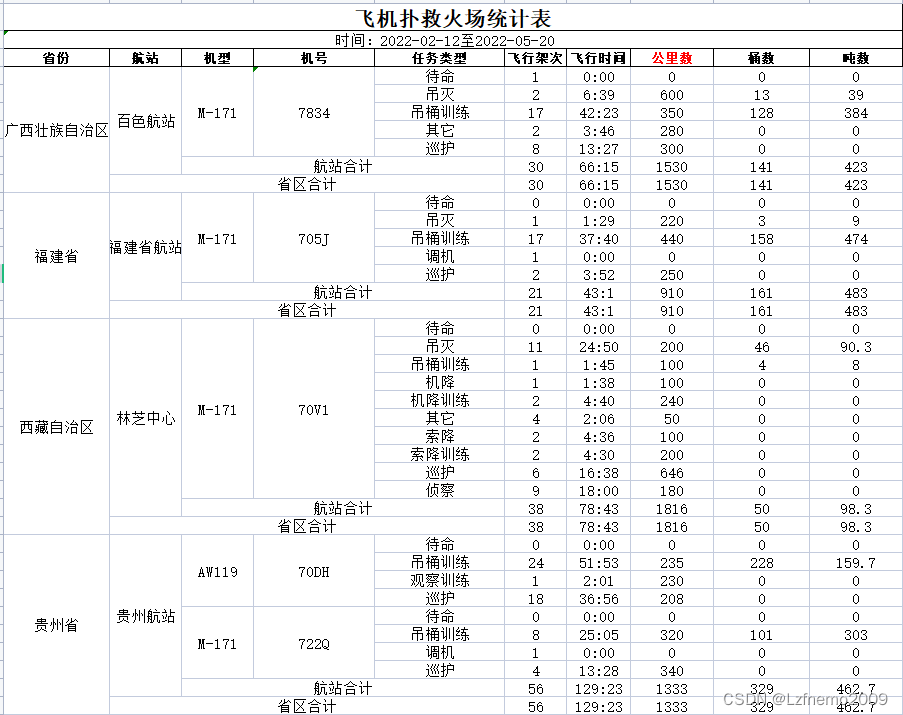
①利用easyExcel模板填充,实现效果如下图

代码:
//模板位置
InputStream template = new PathMatchingResourcePatternResolver()
.getResource("templates/飞机扑救火场统计表.xlsx").getInputStream();
response.setContentType("application/octet-stream");
response.setCharacterEncoding("utf-8");
// 这里URLEncoder.encode可以防止中文乱码
response.setHeader("Content-Disposition",
"attachment;filename=" + java.net.URLEncoder.encode("飞机扑救火场统计表.xlsx", "UTF-8"));
//ExcelWriter该对象用于通过POI将值写入Excel
ExcelWriter excelWriter = EasyExcel.write(response.getOutputStream()).withTemplate(template).build();
//构建excel的sheet
WriteSheet writeSheet = EasyExcel.writerSheet().build();
Map<String, String> fileData = new HashMap<>();
fileData.put("beginDate", beginDate);
fileData.put("endDate", endDate);
excelWriter.fill(list, writeSheet);
excelWriter.fill(fileData, writeSheet);
excelWriter.finish();模板:

列合并工具类,合并代码在afterCellDispose这个方法中,不管是列合并还是行合并其实是重写这个方法,将你的合并逻辑写在里面就可以.
//列合并工具类
public class ExcelFillCellMergePrevColUtils implements CellWriteHandler {
private static final String KEY ="%s-%s";
//所有的合并信息都存在了这个map里面
Map<String, Integer> mergeInfo = new HashMap<>();
public ExcelFillCellMergePrevColUtils() {
}
@Override
public void beforeCellCreate(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, Row row, Head head, Integer integer, Integer integer1, Boolean aBoolean) {
}
@Override
public void afterCellCreate(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, Cell cell, Head head, Integer integer, Boolean aBoolean) {
}
@Override
public void afterCellDataConverted(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, CellData cellData, Cell cell, Head head, Integer integer, Boolean aBoolean) {
}
@Override
public void afterCellDispose(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, List<CellData> list, Cell cell, Head head, Integer integer, Boolean aBoolean) {
//当前行
int curRowIndex = cell.getRowIndex();
//当前列
int curColIndex = cell.getColumnIndex();
Integer num = mergeInfo.get(String.format(KEY, curRowIndex, curColIndex));
if(null != num){
// 合并最后一行 ,列
mergeWithPrevCol(writeSheetHolder, cell, curRowIndex, curColIndex,num);
}
}
public void mergeWithPrevCol(WriteSheetHolder writeSheetHolder, Cell cell, int curRowIndex, int curColIndex, int num) {
Sheet sheet = writeSheetHolder.getSheet();
CellRangeAddress cellRangeAddress = new CellRangeAddress(curRowIndex, curRowIndex, curColIndex, curColIndex + num);
sheet.addMergedRegion(cellRangeAddress);
}
//num从第几列开始增加多少列,(6,2,7)代表的意思就是第6行的第2列至第2+7也就是9列开始合并
public void add (int curRowIndex, int curColIndex , int num){
mergeInfo.put(String.format(KEY, curRowIndex, curColIndex),num);
}
}
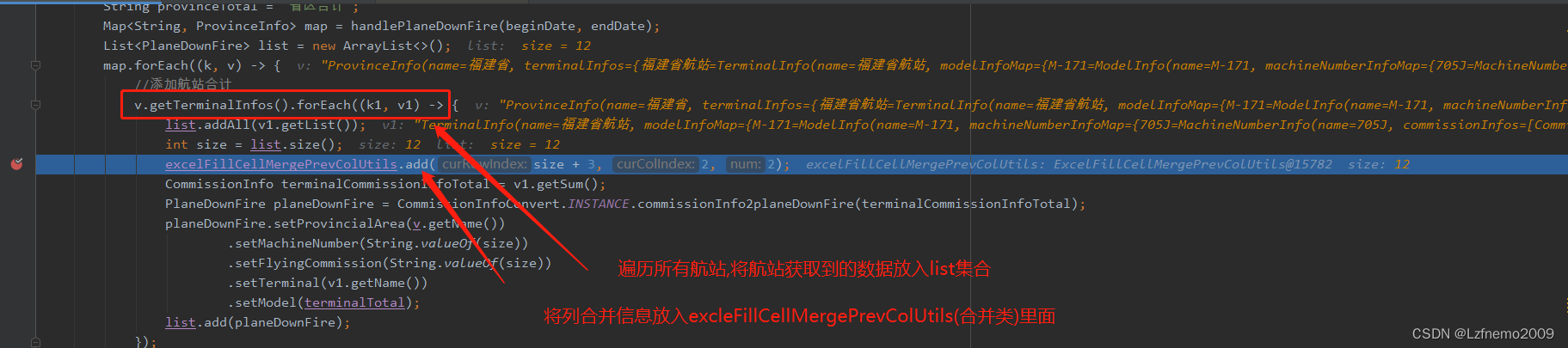
可以参考下面的这个excel看一下,广西壮族自治区的航站合计是从第8行,第2列开始+2列的范围合并
列合并效果图: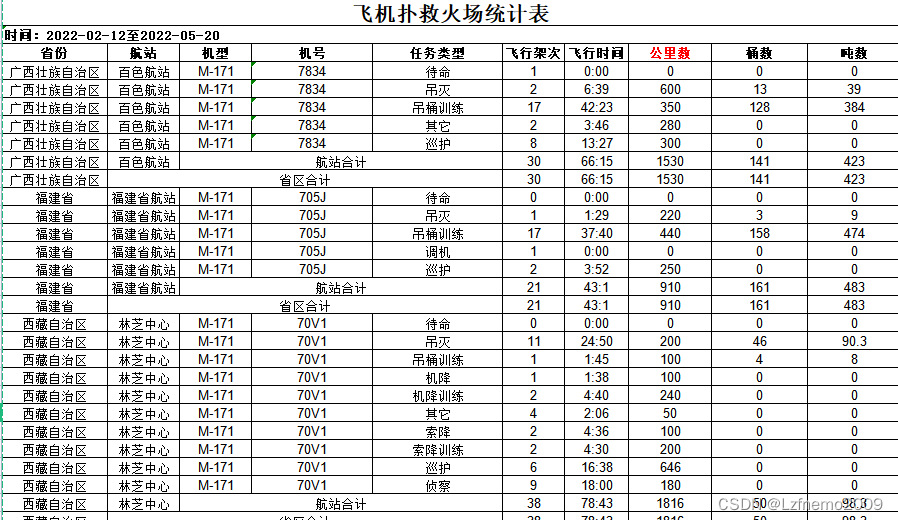
行合并工具类初级版本:
报错位置:ExcelFillCellMergeStrategyUtils合并策略类的 mergeWithPrevRow()方法中
这一行代码会报空指针异常 java.lang.NullPointerException
Row preRow = cell.getSheet().getRow(curRowIndex - 1); 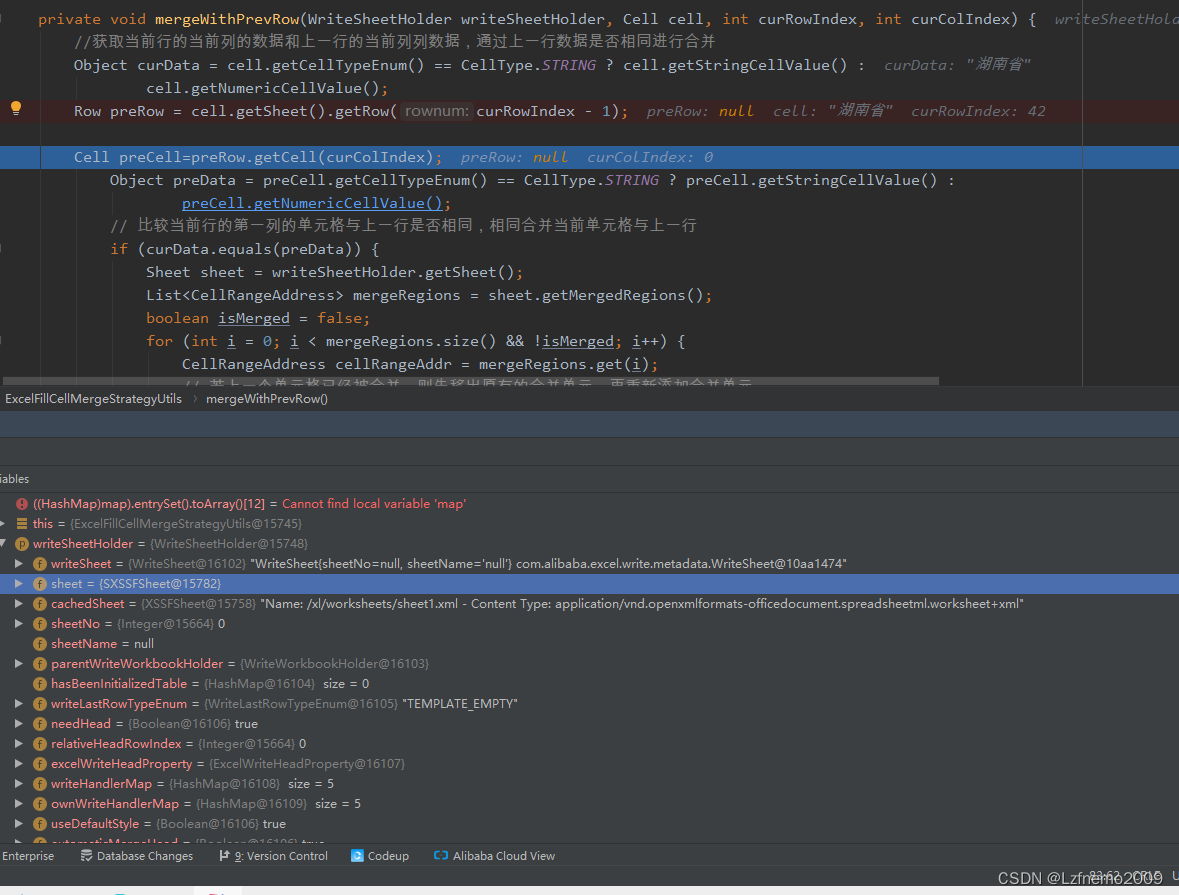
原因:
debug发现,cell.getSheet() 行的下标第0到42的数据行,获取的是同一个 sheet 实例
当下标为43时,执行cell.getSheet()获取到的 sheet 实例不一样
而下标0到42的行数据被存储到 存储sheet中。如果上一行为空则去缓存中获取上一行,
writeSheetHolder.getCachedSheet()
Row preRow = cell.getSheet().getRow(curRowIndex - 1);
if (preRow == null) {
// 当获取不到上一行数据时,使用缓存sheet中数据
preRow = writeSheetHolder.getCachedSheet().getRow(curRowIndex - 1);
}
Cell preCell=preRow.getCell(curColIndex);行合并工具类最终版:
public class ExcelFillCellMergeStrategyUtils implements CellWriteHandler {
/**
* 合并字段的下标
*/
private int[] mergeColumnIndex;
/**
* 合并几行
*/
private int mergeRowIndex;
public ExcelFillCellMergeStrategyUtils(int mergeRowIndex, int[] mergeColumnIndex) {
this.mergeRowIndex = mergeRowIndex;
this.mergeColumnIndex = mergeColumnIndex;
}
@Override
public void beforeCellCreate(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, Row row,
Head head, Integer integer, Integer integer1, Boolean aBoolean) {
}
@Override
public void afterCellCreate(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, Cell cell,
Head head, Integer integer, Boolean aBoolean) {
}
@Override
public void afterCellDataConverted(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder,
CellData cellData, Cell cell, Head head, Integer integer, Boolean aBoolean) {
}
@Override
public void afterCellDispose(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder,
List<CellData> list, Cell cell, Head head, Integer integer, Boolean aBoolean) {
//当前行
int curRowIndex = cell.getRowIndex();
//当前列
int curColIndex = cell.getColumnIndex();
if (curRowIndex > mergeRowIndex) {
for (int i = 0; i < mergeColumnIndex.length; i++) {
if (curColIndex == mergeColumnIndex[i]) {
mergeWithPrevRow(writeSheetHolder, cell, curRowIndex, curColIndex);
break;
}
}
}
}
private void mergeWithPrevRow(WriteSheetHolder writeSheetHolder, Cell cell, int curRowIndex, int curColIndex) {
//获取当前行的当前列的数据和上一行的当前列列数据,通过上一行数据是否相同进行合并
Object curData = cell.getCellTypeEnum() == CellType.STRING ? cell.getStringCellValue() :
cell.getNumericCellValue();
Row preRow = cell.getSheet().getRow(curRowIndex - 1);
if (preRow == null) {
// 当获取不到上一行数据时,使用缓存sheet中数据
preRow = writeSheetHolder.getCachedSheet().getRow(curRowIndex - 1);
}
Cell preCell=preRow.getCell(curColIndex);
Object preData = preCell.getCellTypeEnum() == CellType.STRING ? preCell.getStringCellValue() :
preCell.getNumericCellValue();
// 比较当前行的第一列的单元格与上一行是否相同,相同合并当前单元格与上一行
if (curData.equals(preData)) {
Sheet sheet = writeSheetHolder.getSheet();
List<CellRangeAddress> mergeRegions = sheet.getMergedRegions();
boolean isMerged = false;
for (int i = 0; i < mergeRegions.size() && !isMerged; i++) {
CellRangeAddress cellRangeAddr = mergeRegions.get(i);
// 若上一个单元格已经被合并,则先移出原有的合并单元,再重新添加合并单元
if (cellRangeAddr.isInRange(curRowIndex - 1, curColIndex)) {
sheet.removeMergedRegion(i);
cellRangeAddr.setLastRow(curRowIndex);
sheet.addMergedRegion(cellRangeAddr);
isMerged = true;
}
}
// 若上一个单元格未被合并,则新增合并单元
if (!isMerged) {
CellRangeAddress cellRangeAddress = new CellRangeAddress(curRowIndex - 1, curRowIndex, curColIndex,
curColIndex);
sheet.addMergedRegion(cellRangeAddress);
}
}
}
}样式工具类:
public class CellStyleStrategy extends AbstractCellStyleStrategy {
private WriteCellStyle headWriteCellStyle;
private List<WriteCellStyle> contentWriteCellStyleList;
private CellStyle headCellStyle;
private List<CellStyle> contentCellStyleList;
public CellStyleStrategy(WriteCellStyle headWriteCellStyle,
List<WriteCellStyle> contentWriteCellStyleList) {
this.headWriteCellStyle = headWriteCellStyle;
this.contentWriteCellStyleList = contentWriteCellStyleList;
}
public CellStyleStrategy(WriteCellStyle headWriteCellStyle, WriteCellStyle contentWriteCellStyle) {
this.headWriteCellStyle = headWriteCellStyle;
contentWriteCellStyleList = new ArrayList<WriteCellStyle>();
contentWriteCellStyleList.add(contentWriteCellStyle);
}
@Override
protected void initCellStyle(Workbook workbook) {
if (headWriteCellStyle != null) {
headCellStyle = StyleUtil.buildHeadCellStyle(workbook, headWriteCellStyle);
}
if (contentWriteCellStyleList != null && !contentWriteCellStyleList.isEmpty()) {
contentCellStyleList = new ArrayList<CellStyle>();
for (WriteCellStyle writeCellStyle : contentWriteCellStyleList) {
contentCellStyleList.add(StyleUtil.buildContentCellStyle(workbook, writeCellStyle));
}
}
}
@Override
protected void setHeadCellStyle(Cell cell, Head head, Integer relativeRowIndex) {
if (headCellStyle == null) {
return;
}
cell.setCellStyle(headCellStyle);
}
@Override
protected void setContentCellStyle(Cell cell, Head head, Integer relativeRowIndex) {
if (contentCellStyleList == null || contentCellStyleList.isEmpty()) {
return;
}
cell.setCellStyle(contentCellStyleList.get(0));
}
} public CellStyleStrategy horizontalCellStyleStrategyBuilder() {
WriteCellStyle headWriteCellStyle = new WriteCellStyle();
//设置头字体
WriteFont headWriteFont = new WriteFont();
headWriteFont.setFontHeightInPoints((short) 13);
headWriteFont.setBold(true);
headWriteCellStyle.setWriteFont(headWriteFont);
//设置头居中
headWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.CENTER);
//内容策略
WriteCellStyle contentWriteCellStyle = new WriteCellStyle();
//设置 水平居中
contentWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.CENTER);
//垂直居中
contentWriteCellStyle.setVerticalAlignment(VerticalAlignment.CENTER);
return new CellStyleStrategy(headWriteCellStyle, contentWriteCellStyle);
} public void exportExcel(HttpServletResponse response, String beginDate, String endDate) throws IOException {
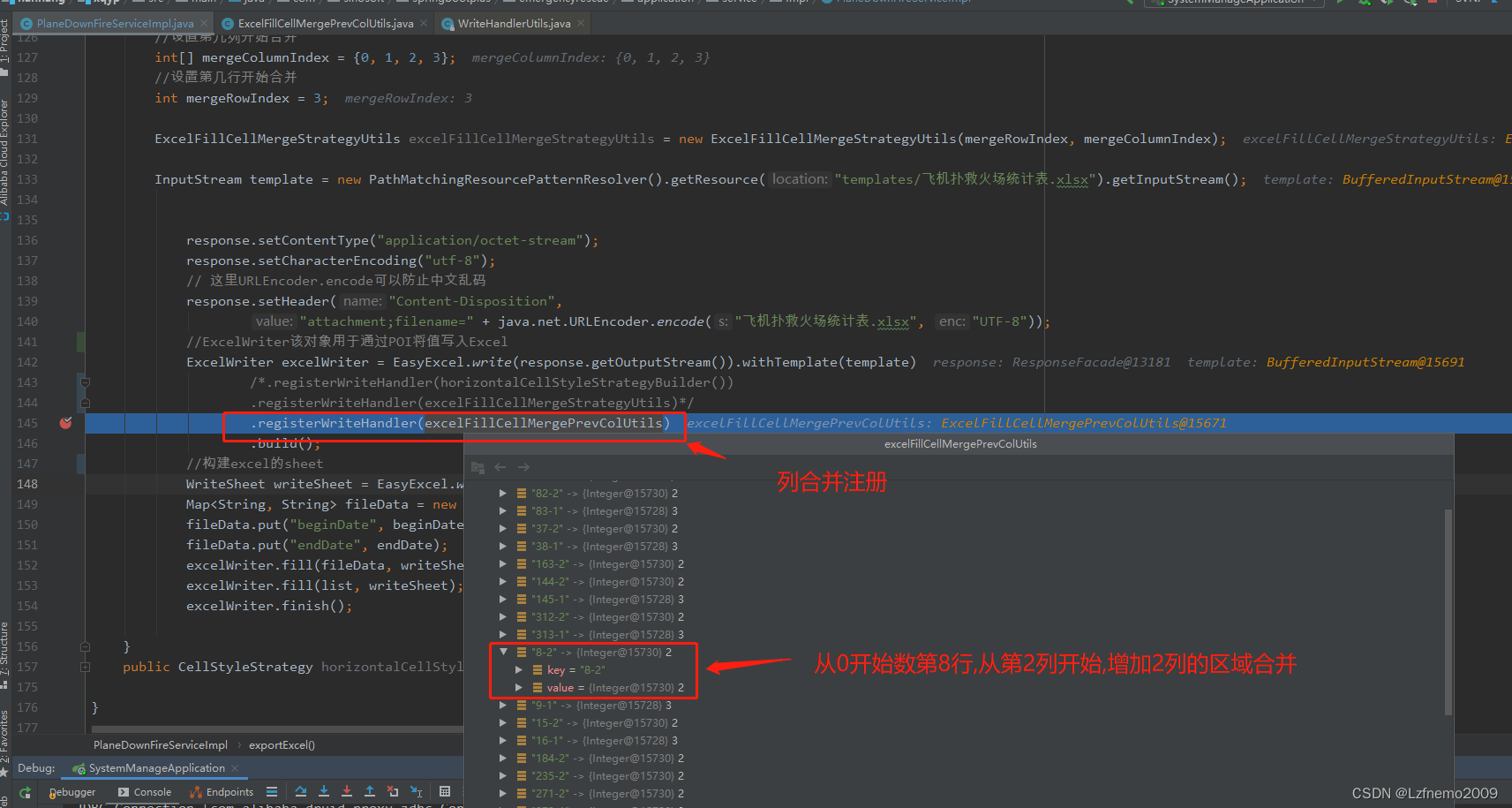
ExcelFillCellMergePrevColUtils excelFillCellMergePrevColUtils = new ExcelFillCellMergePrevColUtils();
String terminalTotal = "航站合计";
String provinceTotal = "省区合计";
Map<String, ProvinceInfo> map = handlePlaneDownFire(beginDate, endDate);
List<PlaneDownFire> list = new ArrayList<>();
map.forEach((k, v) -> {
//添加航站合计
v.getTerminalInfos().forEach((k1, v1) -> {
list.addAll(v1.getList());
int size = list.size();
excelFillCellMergePrevColUtils.add(size + 3, 2, 2);
CommissionInfo terminalCommissionInfoTotal = v1.getSum();
PlaneDownFire planeDownFire = CommissionInfoConvert.INSTANCE.commissionInfo2planeDownFire(terminalCommissionInfoTotal);
planeDownFire.setProvincialArea(v.getName())
.setMachineNumber(String.valueOf(size))
.setFlyingCommission(String.valueOf(size))
.setTerminal(v1.getName())
.setModel(terminalTotal);
list.add(planeDownFire);
});
int size = list.size();
excelFillCellMergePrevColUtils.add(size + 3, 1, 3);
//省区合计
CommissionInfo provinceCommissionInfoTotal = v.getSum();
PlaneDownFire planeDownFire = CommissionInfoConvert.INSTANCE.commissionInfo2planeDownFire(provinceCommissionInfoTotal);
planeDownFire.setProvincialArea(v.getName())
.setTerminal(provinceTotal)
.setModel(String.valueOf(size));
list.add(planeDownFire);
});
//设置第几列开始合并
int[] mergeColumnIndex = {0, 1, 2, 3};
//设置第几行开始合并
int mergeRowIndex = 3;
ExcelFillCellMergeStrategyUtils excelFillCellMergeStrategyUtils = new ExcelFillCellMergeStrategyUtils(mergeRowIndex, mergeColumnIndex);
InputStream template = new PathMatchingResourcePatternResolver().getResource("templates/飞机扑救火场统计表.xlsx").getInputStream();
response.setContentType("application/octet-stream");
response.setCharacterEncoding("utf-8");
// 这里URLEncoder.encode可以防止中文乱码
response.setHeader("Content-Disposition",
"attachment;filename=" + java.net.URLEncoder.encode("飞机扑救火场统计表.xlsx", "UTF-8"));
//ExcelWriter该对象用于通过POI将值写入Excel
ExcelWriter excelWriter = EasyExcel.write(response.getOutputStream()).withTemplate(template)
//样式注册
.registerWriteHandler(horizontalCellStyleStrategyBuilder())
//行注册
.registerWriteHandler(excelFillCellMergeStrategyUtils)
//列注册
.registerWriteHandler(excelFillCellMergePrevColUtils)
.build();
//构建excel的sheet
WriteSheet writeSheet = EasyExcel.writerSheet().build();
Map<String, String> fileData = new HashMap<>();
fileData.put("beginDate", beginDate);
fileData.put("endDate", endDate);
excelWriter.fill(fileData, writeSheet);
excelWriter.fill(list, writeSheet);
excelWriter.finish();
}总结:EasyExcel动态导出几乎能够满足大部分需求,说到底还是实现CellWriteHandler 类里面的
afterCellDispose方法,里面实现你想要的效果.
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
我正在使用Mandrill的RubyAPIGem并使用以下简单的测试模板:testastic按照Heroku指南中的示例,我有以下Ruby代码:require'mandrill'm=Mandrill::API.newrendered=m.templates.render'test-template',[{:header=>'someheadertext',:main_section=>'Themaincontentblock',:footer=>'asdf'}]mail(:to=>"JaysonLane",:subject=>"TestEmail")do|format|format.h
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
所以这可能有点令人困惑,但请耐心等待。简而言之,我想遍历具有特定键值的所有属性,然后如果值不为空,则将它们插入到模板中。这是我的代码:属性:#===DefaultfileConfigurations#default['elasticsearch']['default']['ES_USER']=''default['elasticsearch']['default']['ES_GROUP']=''default['elasticsearch']['default']['ES_HEAP_SIZE']=''default['elasticsearch']['default']['MAX_OP
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu