文章目录
如何控制并发是数据库领域中非常重要的问题之一,MySQL为了解决并发带来的问题,设计了事务隔离机制、锁机制、MVCC机制等等,用一整套机制来解决并发问题,接下来会分几篇来分析MySQL5.7版本InnoDB引擎的锁机制。
由于锁机制的内容很多,一篇写完字数太多,所以我决定分几篇来逐步更新。行锁更重要,优先从行锁说起,然后再说表锁。
对于行锁,行锁的S/X模式和3种算法是最基础的,然后再深入分析行锁的加锁规则等等几篇,本文主要深入分析行锁的加锁规则中的等值查询。
行级锁从锁的模式(lock_mode),可以分为共享锁和排它锁:
SQL语句对应上的行锁说明如下:
| 操作 | 锁的模式 | 说明 |
|---|---|---|
| 普通select语句 | 无行锁 | 在上文MVCC机制讲过,普通的 select 语句属于快照读 |
| select…lock in share mode | S | 显示(explicit)读锁, 上锁后,其它事务对锁定的索引记录仍可以上S锁,但阻塞其它事务对锁定的索引记录上X锁 |
| select…for update | X | 显式(explicit)写锁,上锁后,阻塞其它事务对锁定的索引记录上S或X锁 |
| insert/update/delete | X | 隐式(implicit)写锁,上锁后,阻塞其它事务对锁定的索引记录上S或X锁 |
InnoDB引擎有3种行锁的算法,都是锁定的索引:
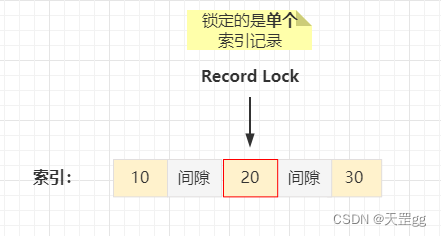
之前 的间隙,白话说就是:每个索引值管着前面的间隙;举个例子:当索引的值有10,20,30,40时,那么索引就存在如下间隙(圆括号表示不包括区间点):
(下界限, 10)
(10, 20)
(20, 30)
(30, 40)
(40, 上界限supremun)
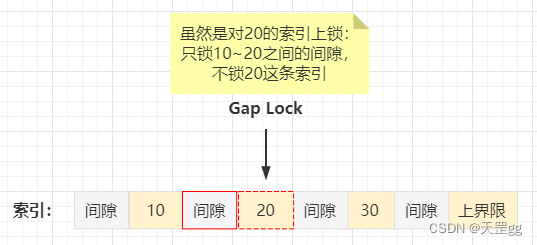
因为是锁定索引之前的间隙,所以就存在如下间隙锁:
| 间隙范围 | 索引记录 |
|---|---|
| (下界限, 10) | 10 |
| (10, 20) | 20 |
| (20, 30) | 30 |
| (30, 40) | 40 |
| (40, 上界限supremun) | supremun |
特殊说明:由于间隙锁是为了解决
幻读问题,所以在读已提交(RC)事务隔离级别是显示禁用间隙锁的。
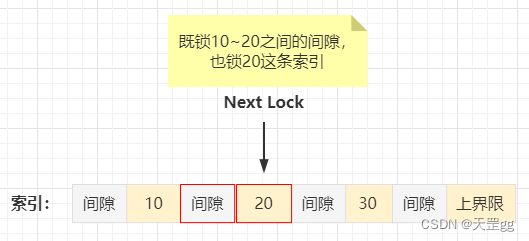
(下界限, 10]
(10, 20]
(20, 30]
(30, 40]
(40, 上界限supremun)
当给索引值20加上了Next-key Lock,那么这个范围是 (10,20] 包括20 ,而不包括10。
由于上界限supremun实际是个伪值,所以上界限并不是真正的索引记录。因此,实际上,这个Next-key Lock只锁定最大索引值之后的间隙。
明白了3种算法,那么这3种算法又是怎么落地的呢?
实际上,默认使用的是Next-key Lock,也就是 索引记录 和 间隙 全锁上。但也会在不同场景下降级优化为Gap Lock或Record Lock。那我们就来分析一下:
由于在读已提交(RC)事务隔离级别下,间隙锁是禁用的(官方说是仅用于外键约束检查和重复键检查),这不是重点,所以本文主要深入分析:在默认的可重复读(RR)事务隔离级别下的加锁规则 之 等值查询。
等值查询也就是where条件: = ,因为行锁都是对索引上锁,所以我们主要分析InnoDB引擎常见的3类索引:
准备一个ct(country team 国家队)表:id 是自增主键,abc是普通索引,abc_uk是唯一索引
并插入4条初始数据:
CREATE TABLE `ct` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`abc` int(10) unsigned NOT NULL,
`abc_uk` int(10) unsigned NOT NULL,
`remark` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_abc_uk` (`abc_uk`) USING BTREE,
KEY `idx_abc` (`abc`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
INSERT INTO `ct`
(`id`, `name`, `abc`, `abc_uk`, `remark`)
VALUES
(10, '巴西', 10, 10, NULL),
(20, '阿根廷', 20, 20, NULL),
(30, '葡萄牙', 30, 30, NULL),
(40, '法国', 40, 40, NULL);
预览下数据:
mysql> select * from ct;
+----+--------+-----+--------+--------+
| id | name | abc | abc_uk | remark |
+----+--------+-----+--------+--------+
| 10 | 巴西 | 10 | 10 | NULL |
| 20 | 阿根廷 | 20 | 20 | NULL |
| 30 | 葡萄牙 | 30 | 30 | NULL |
| 40 | 法国 | 40 | 40 | NULL |
+----+--------+-----+--------+--------+
4 rows in set (0.00 sec)
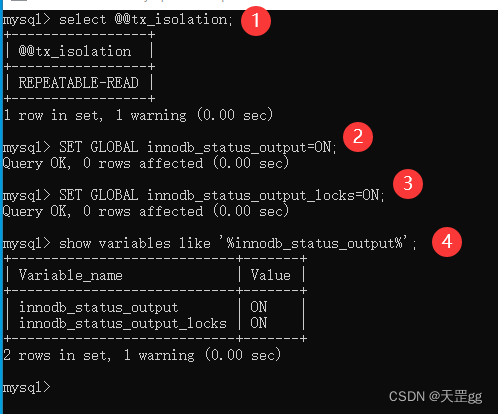
我们新建Session1,做以下基本设置:
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
set tx_isolation='repeatable-read';
SET GLOBAL innodb_status_output=ON;
SET GLOBAL innodb_status_output_locks=ON;
mysql> show variables like '%innodb_status_output%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_status_output | OFF |
| innodb_status_output_locks | OFF |
+----------------------------+-------+
我操作的步骤,如下图:
这个Session1就留着我们分析锁来用,具体执行SQL我们新开另一个Session2,好了,准备开始~
我们先从聚集索引开始说起,那么这里也分等值条件有匹配和无匹配索引两种情况,对应上的锁也是不同的,让我们来分别瞧一瞧:
在Session2执行SQL如下(按id=10):
begin;
update ct set remark = '怀念2002年, 巴西夺冠, 中国进世界杯'
where id = 10;
注意不要commit或rollback,以便于我们分析行锁
然后我们在"Session1"查看锁的详细信息
show engine innodb status\G;
我们主要看TRANSACTIONS这段,如下图:
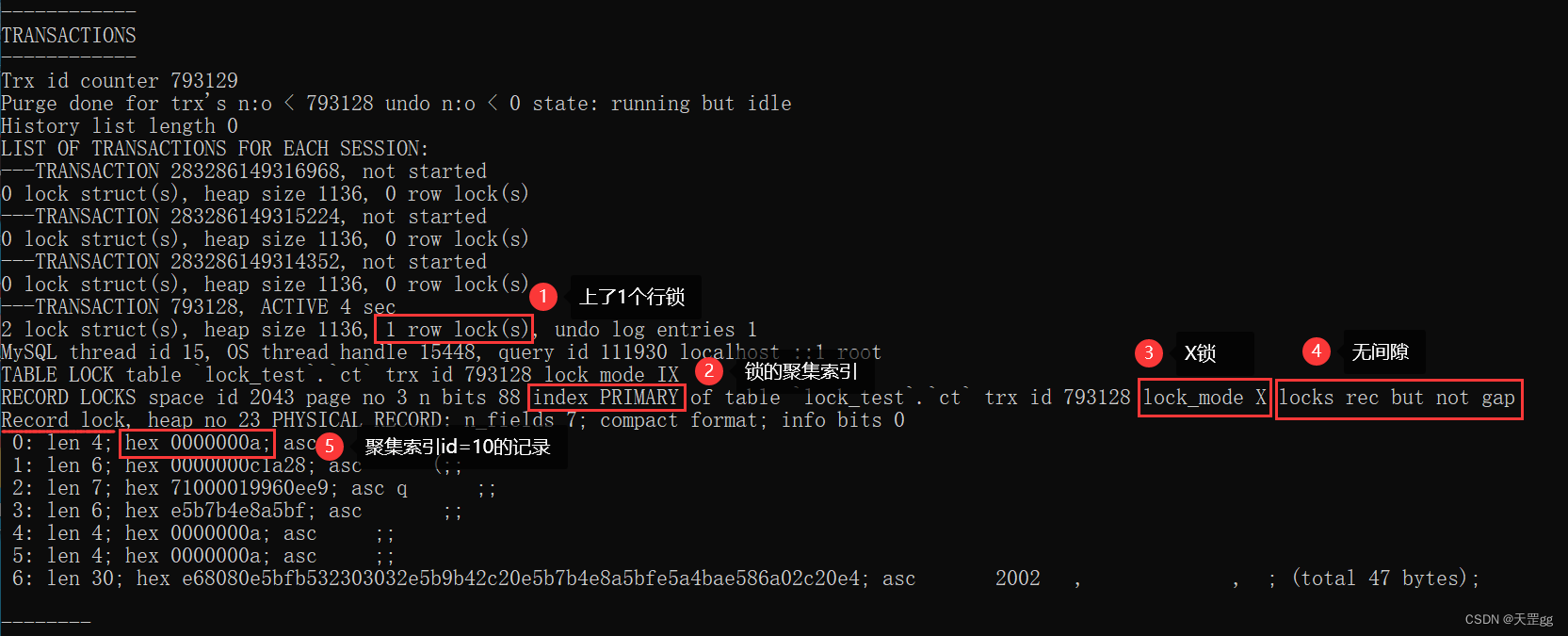
我们来分析一下,上图中包含的信息:
小结:
等值查询 匹配到 聚集索引 时,行级锁 会上一把 无间隙的Record Lock。
这里是因为聚集索引id具有唯一性,所以Next-key Lock降级优化为Record Lock。
先在Session2 rollback上一个SQL,再执行SQL如下(按id=11 不存在):
begin
update ct set remark = '没有id=11的记录~~'
where id = 11;
注意不要commit或rollback,以便于我们分析行锁
然后我们在"Session1"查看锁的详细信息
show engine innodb status\G;
我们主要看TRANSACTIONS这段,如下图:
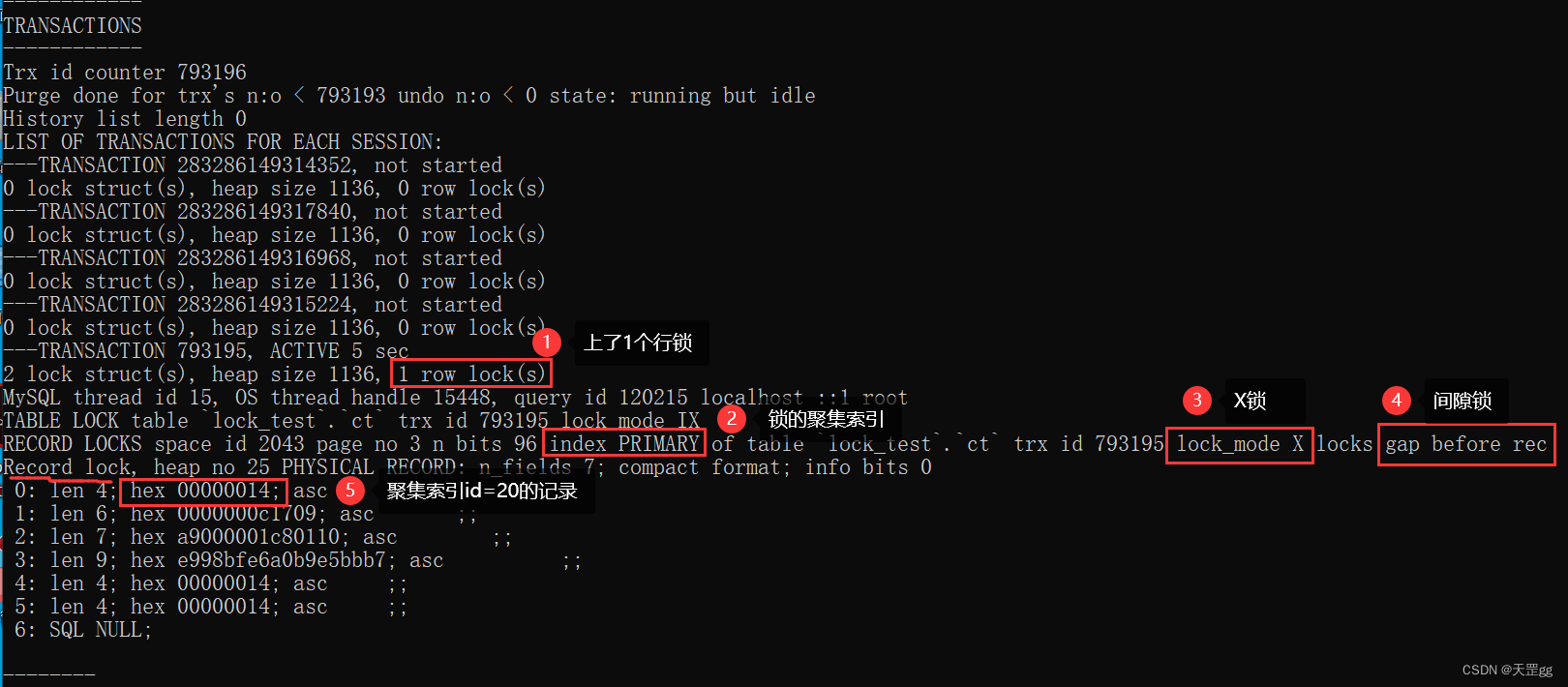
小结:
等值查询 未匹配到 聚集索引 时,行级锁 会上一把 间隙锁
为什么是对 id=20 加的锁,而不是对 id=11 加的锁呢?
我们来分析一下:
按这么说,可能有同学又有疑问:如果id大于最大索引值,锁哪个索引记录?
咱们直接看结果,锁的伪值:上界限supremum,范围是(40, supremum),不包括40.
update ct set remark = '比最大id还要大!'
where id = 41;

先在Session2 rollback上一个SQL,再执行SQL如下(按abc_uk=10):
begin;
update ct set remark = '怀念2002年, 巴西夺冠, 中国进世界杯'
where abc_uk = 10;
注意不要commit或rollback,以便于我们分析行锁
然后我们在"Session1"里查看锁的详细信息
show engine innodb status\G;
我们主要看TRANSACTIONS这段,如下图:
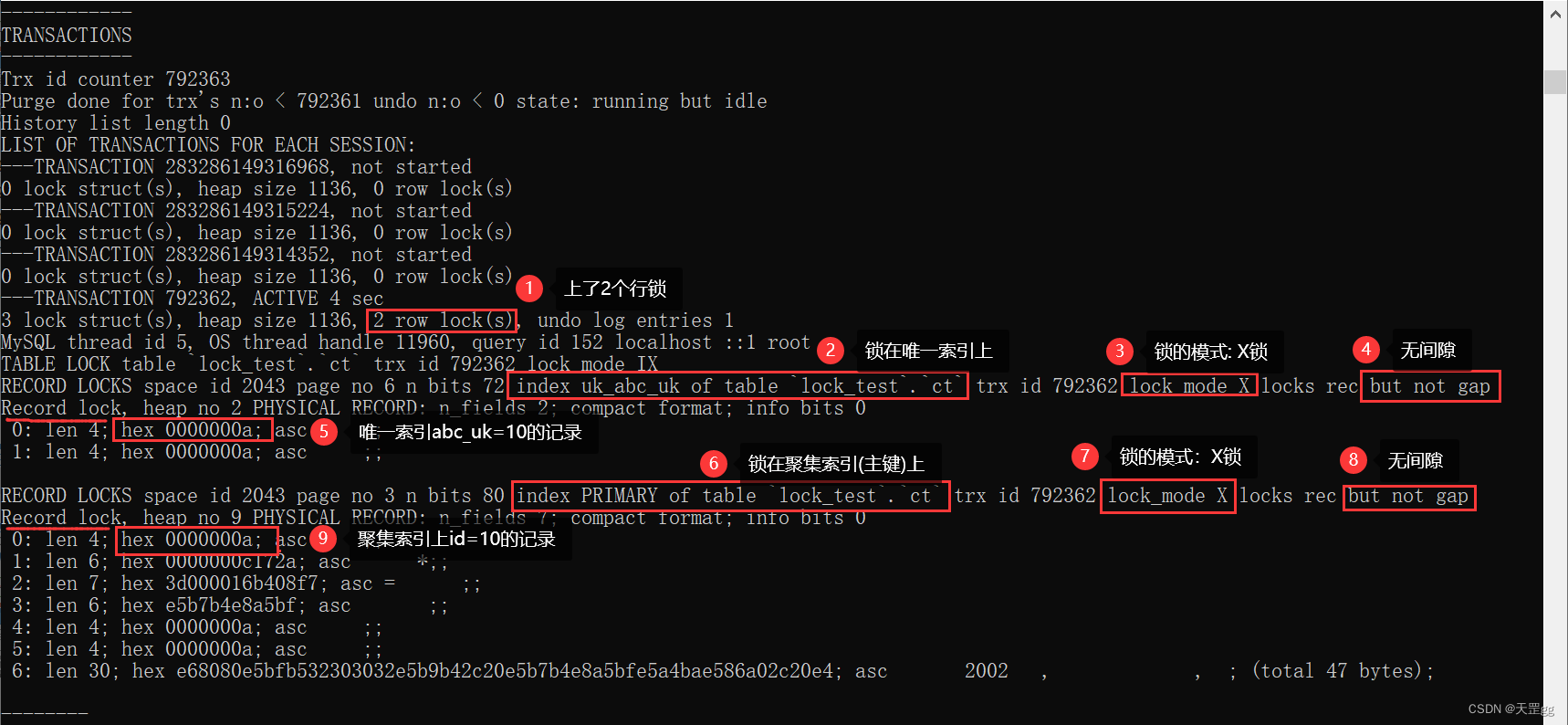
和聚集索引非常类似,不做赘述,但这里是上了2个行锁,所以有两条Record lock, heapno。。。
小结:
等值查询 匹配到 唯一索引 时,行级锁上了2把锁:
- 锁了一条唯一索引记录(abc_uk=10)
- 锁了一条聚集索引记录(id=10)
因为唯一索引具有唯一性,所以都是无间隙的Record Lock,这里也是Next-key Lock降级优化为Record Lock。
先在Session2 rollback上一个SQL,再执行SQL如下(按abc_uk=35):
begin
update ct set remark = '没有abc_uk=35的记录~~'
where abc_uk = 35;
注意不要commit或rollback,以便于我们分析行锁
然后我们在"Session1"查看锁的详细信息
show engine innodb status\G;
我们主要看TRANSACTIONS这段,如下图:

小结:
等值查询 未匹配到 唯一索引 时,行级锁 会上一把 间隙锁,与聚集索引规则相同,具体不做赘述。
先在Session2 rollback上一个SQL,再执行SQL如下(按abc=10):
begin;
update ct set remark = '怀念2002年, 巴西夺冠, 中国进世界杯'
where abc = 10;
注意不要commit或rollback,以便于我们分析行锁
然后我们在Session1里查看锁的详细信息
show engine innodb status\G;
我们主要看TRANSACTIONS这段,如下图:
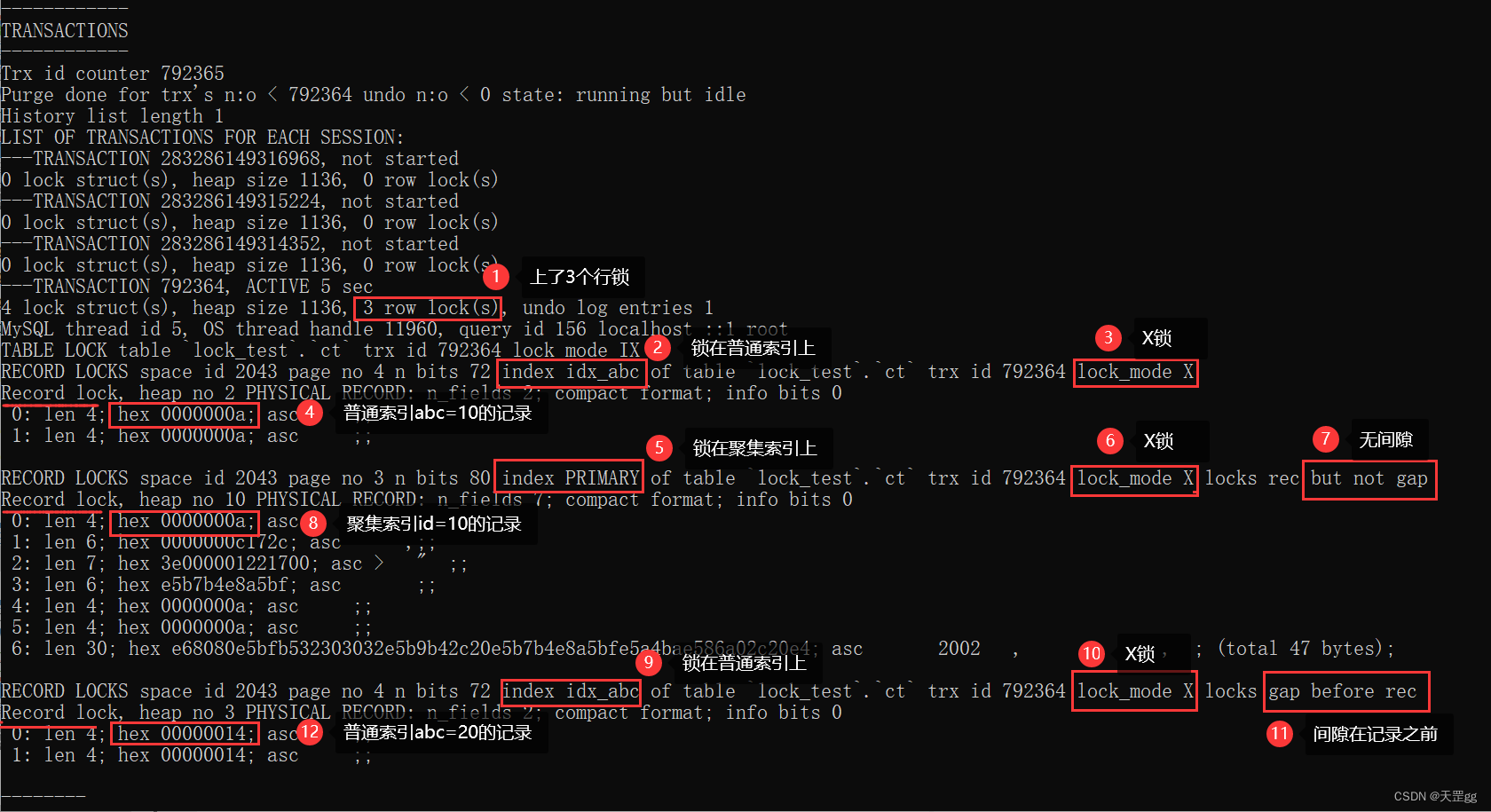
我们来分析一下:
这里就有意思了,上了3个行锁,还是3种不同的行锁,3种算法都齐了,咱们统一说一下怎么区分:
locks rec but not gap:这说明是无间隙的Record Locklocks gap before rec:这说明是间隙锁Gap Lock小结:
等值查询 匹配到 普通索引 时,行级锁上了3把锁:
- abc=10的普通索引记录上了Next-key Lock,这里的范围是:(下界值, 10]
- id=10的聚集索引记录上了Record Lock(单条)
- abc=20的普通索引记录上了Gap-key Lock,这里的范围是:(10, 20)
可以这样说:一个普通索引的等值查询update时,相当于把这条索引记录前后的空隙都锁上了~
这和聚集索引、唯一索引有着很大的不同,你知道这是为什么吗?
思考一下!!!
我们新开一个Session3先来验证一下吧:
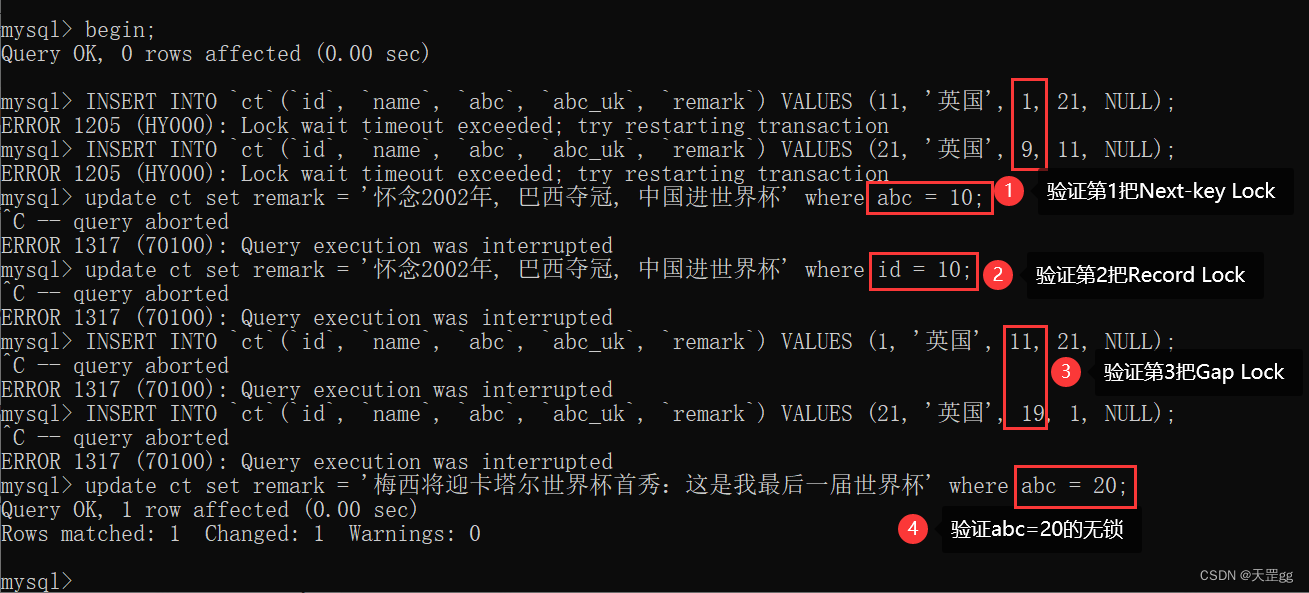
特殊说明:
正常的锁超时异常是:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
^C – query aborted 这是我不想等锁超时按Ctrl+C中止了🐼
验证第1把Next-key Lock
INSERT INTO `ct`(`id`, `name`, `abc`, `abc_uk`, `remark`)
VALUES (11, '英国', 1, 21, NULL);
INSERT INTO `ct`(`id`, `name`, `abc`, `abc_uk`, `remark`)
VALUES (21, '英国', 9, 11, NULL);
update ct set remark = '怀念2002年, 巴西夺冠, 中国进世界杯'
where abc = 10;
验证第2把Record Lock
update ct set remark = '怀念2002年, 巴西夺冠, 中国进世界杯'
where id = 10;
验证第3把Gap Lock
INSERT INTO `ct`(`id`, `name`, `abc`, `abc_uk`, `remark`)
VALUES (1, '英国', 11, 21, NULL);
INSERT INTO `ct`(`id`, `name`, `abc`, `abc_uk`, `remark`)
VALUES (21, '英国', 19, 1, NULL);
验证修改abc=20的索引记录,不会阻塞
update ct set remark = '梅西将迎卡塔尔世界杯首秀:这是我最后一届世界杯'
where abc = 20;
我们来分析为什么 按abc=10 更新时, 却上了3把锁:
通过这样分析,你是不是发现了上面说的不够严谨?
没错,我们再加一条记录,让abc = 10的记录不止一条:
INSERT INTO `ct`
(`id`, `name`, `abc`, `abc_uk`, `remark`)
VALUES
(15, '克罗地亚', 10, 15, NULL);
我们再确认一下现在的记录(一直没有提交):
mysql> select * from ct;
+----+----------+-----+--------+--------+
| id | name | abc | abc_uk | remark |
+----+--------- +-----+--------+--------+
| 10 | 巴西 | 10 | 10 | NULL |
| 15 | 克罗地亚 | 10 | 15 | NULL |
| 20 | 阿根廷 | 20 | 20 | NULL |
| 30 | 葡萄牙 | 30 | 30 | NULL |
| 40 | 法国 | 40 | 40 | NULL |
+----+----------+-----+--------+--------+
5 rows in set (0.00 sec)
先在Session2 rollback上一个SQL,再执行SQL如下(按abc=10):
begin;
update ct set remark = '怀念2002年, 巴西夺冠, 中国进世界杯'
where abc = 10;
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0
这里看到已经是2行受影响了
注意不要commit或rollback,以便于我们分析行锁
然后我们在Session1里查看锁的详细信息
show engine innodb status\G;
我们主要看差异,如下图:
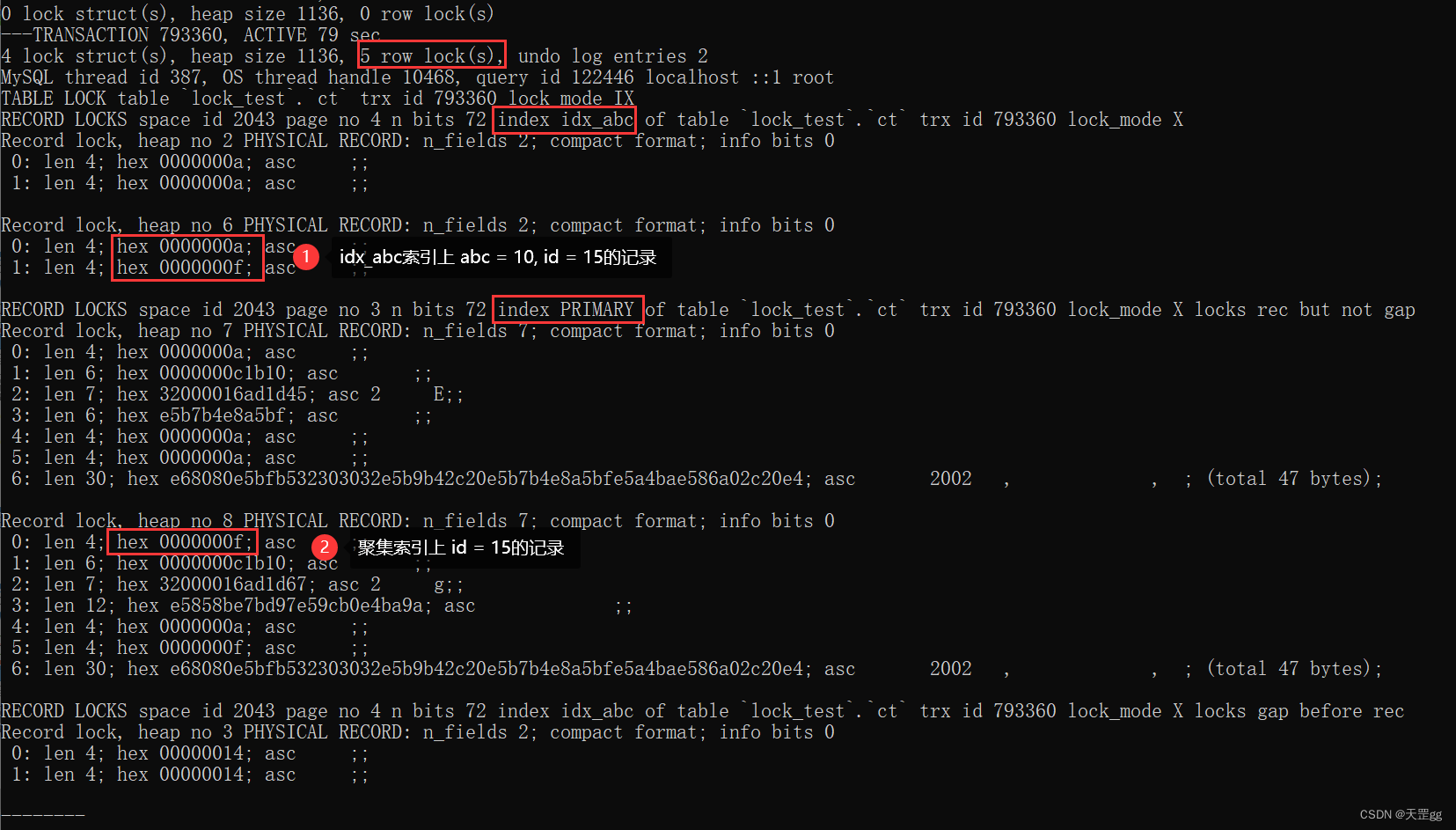
一共上了5把锁,多的2把就是我们新增的那条id =15, abc = 10记录,对应的普通索引和聚集索引上的锁。
更严谨的小结:
等值查询 匹配到 普通索引 时,行级锁会上2m+1把锁,m是匹配的记录数:
上面例子匹配了2条记录,所以上了2*2+1 = 5把锁,分别是
- abc=10, id =10 的普通索引记录上了Next-key Lock,这里的范围是:(下界值, 10]
- abc=10, id =15 的普通索引记录上了Next-key Lock,这里的范围是:(下界值, 10]
- id=10的聚集索引记录上了Record Lock(单条)
- id=15的聚集索引记录上了Record Lock(单条)
- abc=20的普通索引记录上了Gap-key Lock,这里的范围是:(10, 20)
先在Session2 rollback上一个SQL,再执行SQL如下(按abc=1):
begin
update ct set remark = '没有abc=1的记录~~'
where abc = 1;
注意不要commit或rollback,以便于我们分析行锁
然后我们在"Session1"查看锁的详细信息
show engine innodb status\G;
我们主要看TRANSACTIONS这段,如下图:
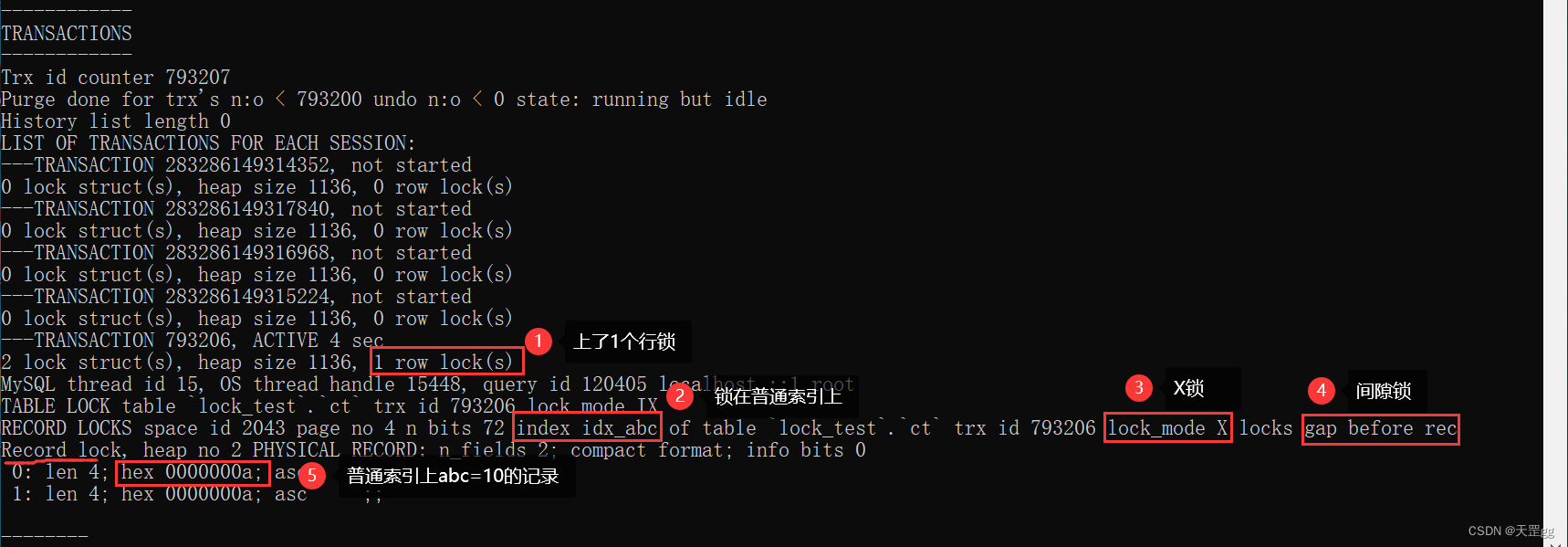
小结:
等值查询 未匹配到 普通索引 时,行级锁 会上一把 间隙锁,与聚集索引和唯一索引的规则相同,具体不做赘述。
再次说明:本文分析加锁规则的事务隔离级别为:默认的可重复读(RR)事务隔离级别。
有匹配索引:
有唯一性的索引,都会降级为Record Lock。
无匹配索引:
如果感觉不错,请收藏本专栏,后面还有更详细的锁机制陆续放出。
关注我 天罡gg 分享更多干货: https://blog.csdn.net/scm_2008
大家的「关注 + 点赞 + 收藏」就是我创作的最大动力!
同类文章:
https://blog.csdn.net/weixin_48460141/article/details/124284443
https://blog.csdn.net/qq_39360632/article/details/127013702
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果