文章目录
1、什么时候使用google test
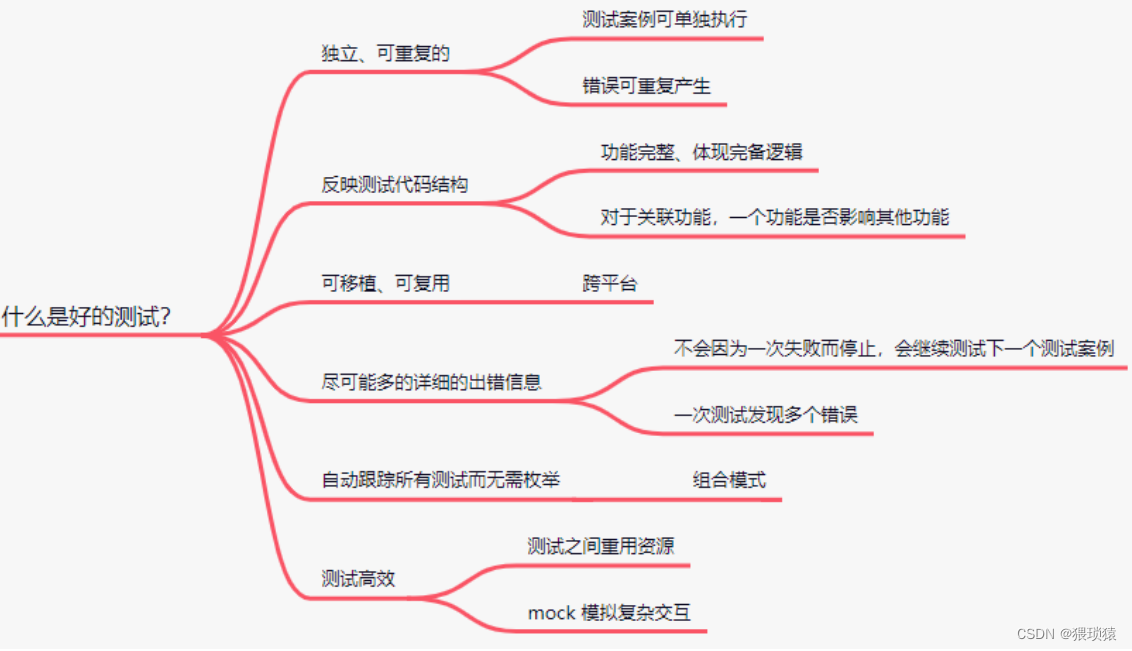
2、什么是一个好的测试工具
3、自己实现该单元的测试,应该注意哪些点
4、googletest的层次关系
5、学习一些googletest案例
6、学习googletest的事件,如何打桩
一个项目有以下这些阶段
开发阶段:写功能,编译调试
还有部署阶段和上线阶段
googletest作为一个工具可以快速发现一些错误,并且及时纠正错误,这个工具在代码编译成功后,要去发现一些逻辑错误。
主要在我们的开发阶段,也会在我们的部署阶段中遇到。
好的测试工具应该具备哪些特性
1、测试应该是独立的与可重复的
我们先看看我们的代码模块当中,每一个模块都有一个叫做test的文件,这个就是专门来检测模块功能的文件,里边会写很多的测试用例去验证结果,比如说为了验证这个模块是否有问题,那么就会运行这个test文件中的测试样例,对这个模块进行单独的测试,也可以整体地去跑整个项目的功能,这就是我们所说的可以单独性,与可重复性。先整体去跑,然后再局部去跑就可以发现其中的错误
2、测试应该很好地“组织”,并反映出测试代码的结构
比如说我们测试下边的模块,其中要包括所有情况的测试样例,就要枚举所有的情况,并且写出每一种情况的测试样例
这里我们可以看到多个线程并发读,其中包括1个到4个线程并发读与并发写的情况
3、测试应该是可移植的和可重用的。谷歌有许多与平台无关的代码;它的测试也应该是平台中立的。
googletest 可以在不同的操作系统上工作,使用不同的编译器,所以 googletest 测试可以在多种配
置下工作。
4、当测试失败时,他们应该提供尽可能多的关于问题的信息。googletest 不会在第一次测试失败时停止。相反,它只停止当前的测试并继续下一个测试。还可以设置报告非致命失败的测试,在此之后当前测试将继续进行。因此,您可以在一个运行-编辑-编译周期中检测和修复多个错误。意思就是说我们的测试不会因为一个模块出问题而影响其他模块的测试
5、测试框架应该将测试编写者从日常琐事中解放出来,让他们专注于测试“内容”。googletest 自动跟踪所有定义的测试,并且不要求用户为了运行它们而枚举它们。
6、测试应该是快速的。使用 googletest,您可以在测试之间重用共享资源,并且只需要为设置/拆除支付一次费用,而无需使测试彼此依赖
我们先了解一下测试的层次关系
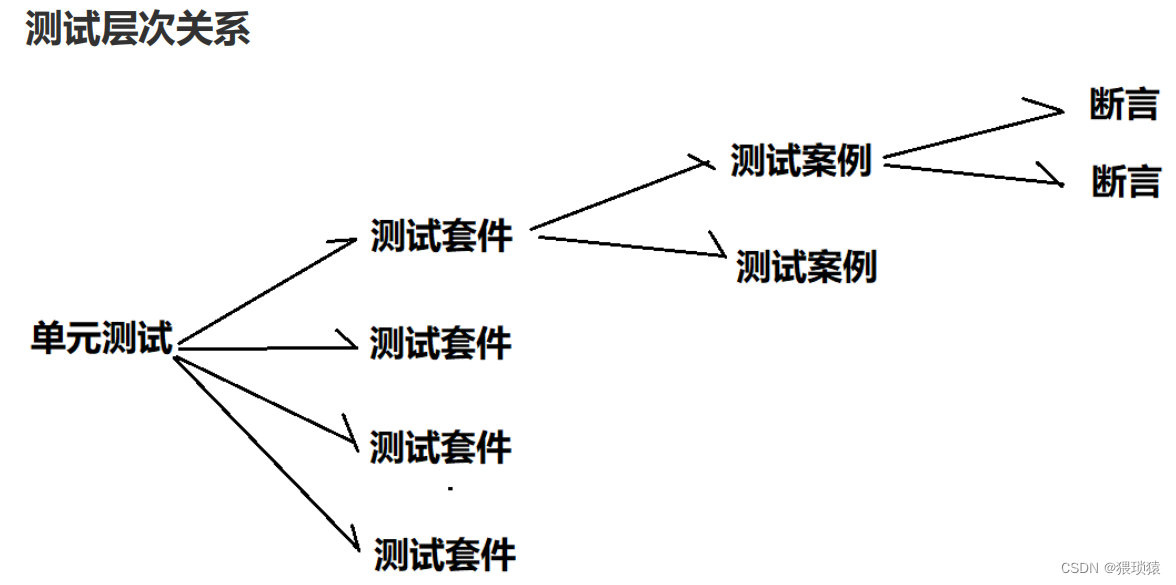
我们在测试的时候,一个测试集合会按照顺序执行,但是也会遇到测试样例增加的情况,我们怎么处理呢?我们就想到了设计模式。
我们来思考一下独立、自动跟踪怎么实现,我们所用的设计模式就是单例模式
单例模式:对象唯一,是全局的访问点
单元测试会不断增加测试样例,如何跟踪测试对象。
我们就要回到当时设计模式的两个概念,一个是稳定点一个是变化点
稳定点:测试集合,按照顺序执行案例
变化点:会不断地新增测试案例
我们还有个方法就是组合模式+责任链,因为我们看到好的测试方法当中有一项是不会因为一次失败而停止,会继续测试下一个用例,组合模式是用来解决自动跟踪所有测试。
比如说我们来看看这个Foo函数的测试,下边写了两个测试样例,用的断言去检验,第一个测试样例测试正确的,有一个是测试失败的。
main函数里边的RUN_ALL_TESTS()是运行所有的测试样例
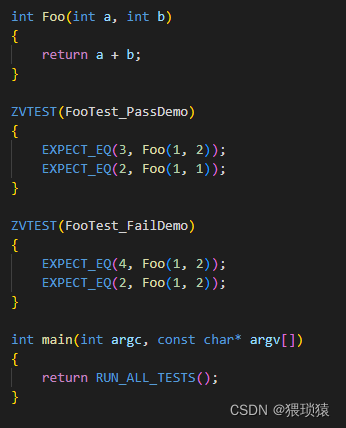
我们运行测试样例可以看到结果,有个成功有个失败的,我们可以看到这个结果,2+2期望的是4,然而实际是3,另外一个1+2也是,所以就有两处错误
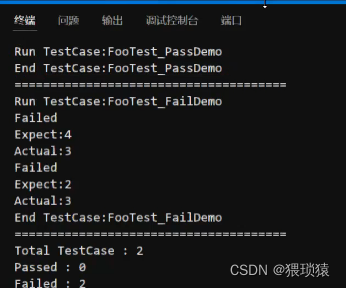
googletest一共两个部分,一个是googletest,另一个是googlemock,分别包含头文件和库文件,googlemock依赖于googletest我们在实际运用当中,用到了googlemock,就不用加googletest的头文件或者库文件,我们直接加googlemock的

这里我们要进行单独测试的时候,不需要执行main函数,就用图中的方法
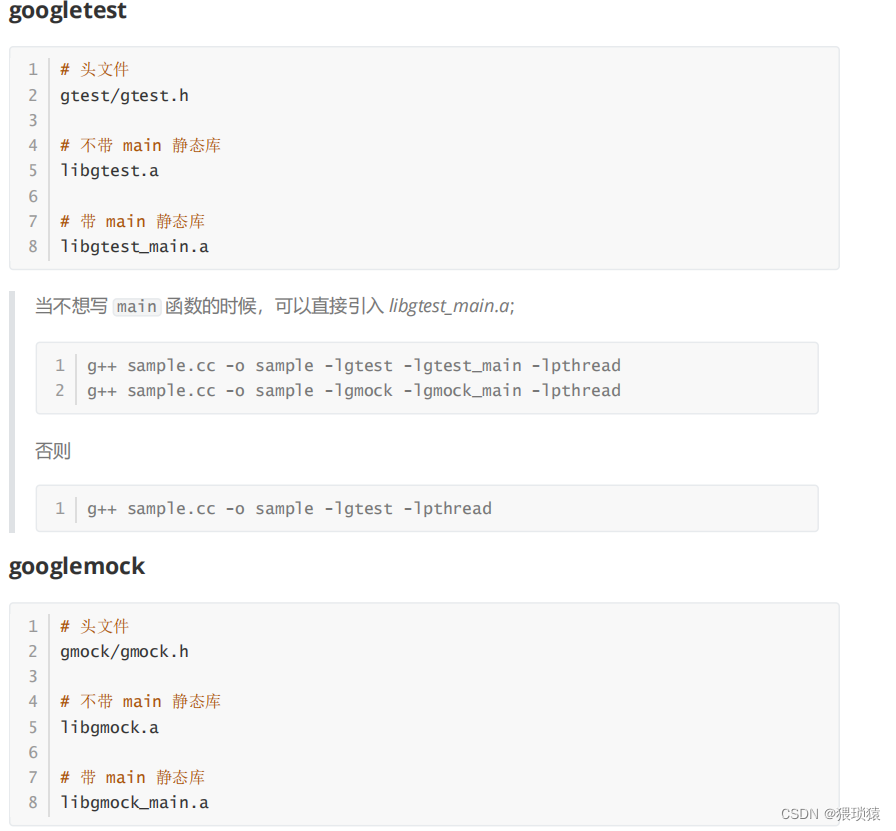
关于模块测试,我们再来剖析一下,先添加头文件,再写测试样例

比如说我们要测试阶乘和质数判断的功能,就要先添加头文件
我们可以看到test_suite_name的意思就是测试套件,一个测试套件就是一个功能
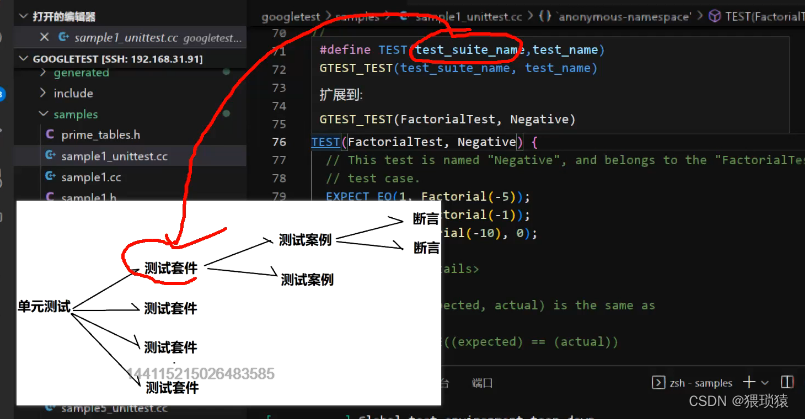
比如说这个Factorial我们在这个测试套件,输入一个测试案例Negative,下边的都是断言,还要注意边界问题,也就是INT_MIN那个测试断言
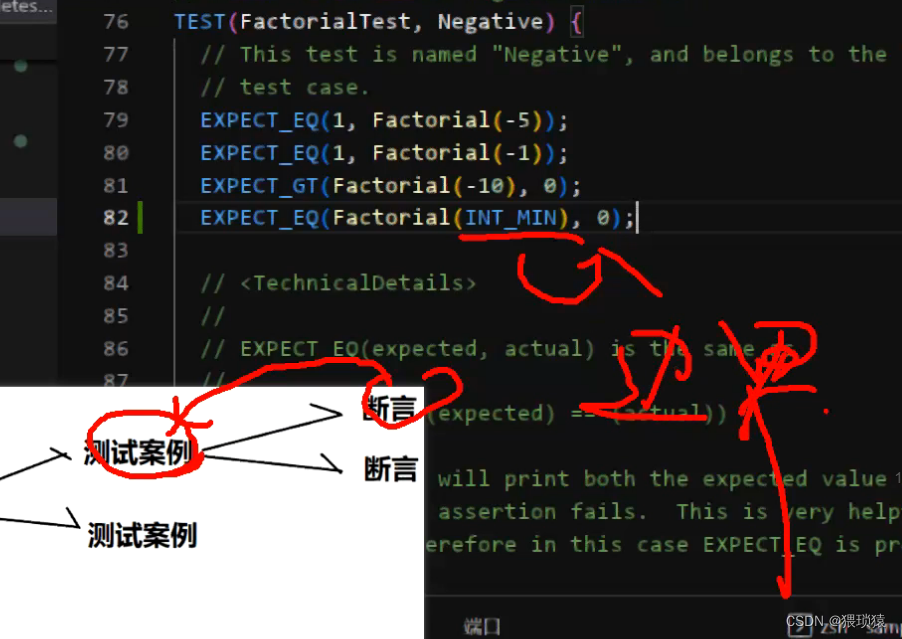
做了前边的加入头文件,以及写测试样例以后,我们就需要执行测试样例,我们就执行main,也就是执行main函数里边的RUN_ALL_TESTS()

用相同的数据配置来测试多个测试案例。
测试夹具也属于测试套件,然后呢,它的测试案例是可以共享数据的,比如说下边的派生类,与基类的关系,要测试这种类就需要共享数据,那么我们写测试套件使用的TEST_F而不是TEST了。测试夹具类似于我们的模板模式

EXPECT与ASSERT的区别在于它们处理错误的方式不一样,比如说前者出错,则可以继续运行后边的语句,后者出错将不会继续执行下去。它会走下一个测试案例,这个后者就是一个责任链模式
断言成对出现,它们测试相同的东西,但对当前函数有不同的影响。 ASSERT_* 版本在失败时产生致命失败,并中止当前测试案例。 EXPECT_* 版本生成非致命失败,它不会中止当前函数。通常首选 EXPECT_* ,因为它们允许在测试中报告一个以上的失败。但是,如果在有问题的断言失败时继续没有意义,则应该使用 ASSERT_* 。
所有断言宏都支持输出流,也就是当出现错误的时候,我们可以通过流输出更详细的信息;注意编码问题,经流输出的信息会自动转换为 UTF-8;
比如说下边这句,还可以打印后边的那个字符串。
EXPECT_TRUE(my_condition) << “My condition is not true”;
明确指定成功或者失败
有时候我们测试案例当中的条件太复杂,不能使用断言,那么自己写判断语句;自己返回 成功或者失败;‘
SUCCEED() 或者 FAIL()
还有我们的谓词断言
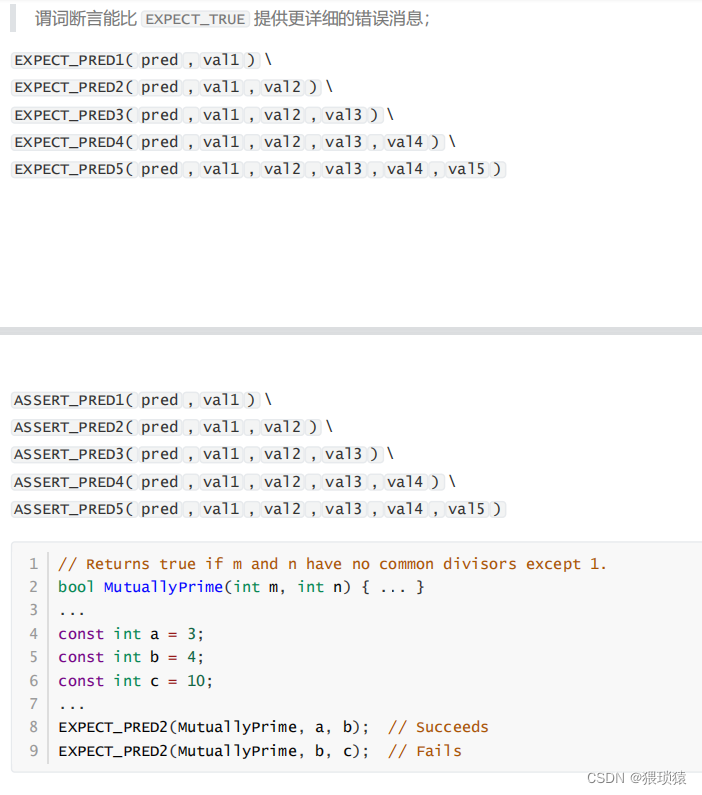
有时候相同的接口,有多个实现,下面是复用测试代码流程;
复用测试案例,我们可以只写一个测试案例,我们会有多种实现,然后只调用这一个测试案例,本质上是一种复用的方式
以下有这些步骤

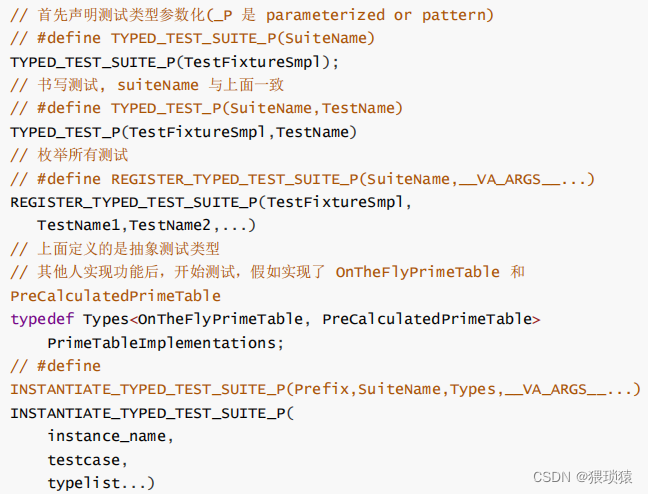
我们要实现的大致就是下面这个,第一步,tesfixture继承自test这个类,把这个类的多种实现,也就是多个class放到Implementtation的参数列表里边去,然后这个多个类的接口实现Implementation通过传参到TYPED_TEST_SUITE里边去,也就是我们参数化的测试套件,也就把多种实现的类(class1,class2.。。。)传进来,class1等都在TYPED_TEST里边测试。我们的参数化测试用的就是TYPED_TEST
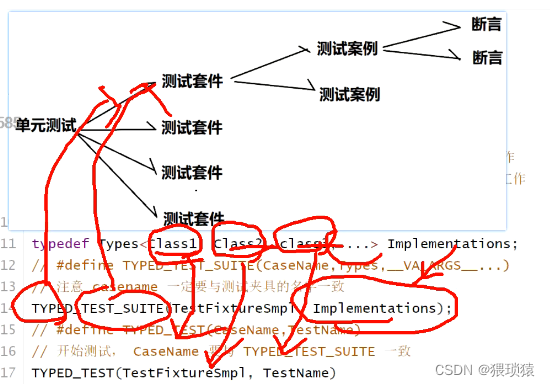
有时候你写了某个接口,期望其他人实现它,你可能想写一系列测试,确保其他人的实现满足你的测试;
可以通过 googletest 的事件机制,在测试前后进行埋点处理;
也就是在测试套件执行前加一个函数执行,或者在套件执行后加一个函数执行,也就可以是在测试案例前后加,也可以在断言前后加。类似于模板模式。
怎么产生?1. 忘记释放了;2. 因为逻辑bug,跳过了释放流程;
new 是 c++ 中的操作符;
调用 operator new 分配内存;
调用构造函数在步骤 1 返回的内存地址生成类对象;
可以通过重载 new 来修改 1 的功能;
delete 与 new 类似;只是是先调用析构函数,再释放内存;
我们可以重载new与delete操作符,用一个静态函数去计算new与delete的调用次数

我们·应该这样检测,使用测试案例,测试案例之前调用一下,测试案例结束之后调用一下就能够统计申请与释放的次数
class LeakChecker : public EmptyTestEventListener {
private:
// Called before a test starts.
void OnTestStart(const TestInfo& /* test_info */) override {
initially_allocated_ = CLeakMem::allocated();
}
// Called after a test ends.
void OnTestEnd(const TestInfo& /* test_info */) override {
int difference = CLeakMem::allocated() - initially_allocated_;
// You can generate a failure in any event handler except
// OnTestPartResult. Just use an appropriate Google Test assertion to do
// it.
EXPECT_LE(difference, 0) << "Leaked " << difference << " unit(s) of class!";
}
int initially_allocated_;
};
当你写一个原型或测试,往往不能完全的依赖真实对象。一个 mock 对象实现与一个真实对象相同的接口,但让你在运行时指定它时,如何使用?它应该做什么?(哪些方法将被调用?什么顺序?
多少次?有什么参数?会返回什么?等)
可以模拟检查它自己和调用者之间的交互;
mock 用于创建模拟类和使用它们;
使用一些简单的宏描述你想要模拟的接口,他们将扩展到你的 mock 类的实现;
创建一些模拟对象,并使用直观的语法指定其期望和行为;
练习使用模拟对象的代码。 googlemock 会在出现任何违反期望的情况时立即处理。
googlemock 依赖 googletest;调用 InitGoogleMock 时会自动调用 InitGoogleTest ;
什么时候使用?
测试很慢,依赖于太多的库或使用昂贵的资源;
测试脆弱,使用的一些资源是不可靠的(例如网络);某个功能由多个网络交互构成测试代码如何处理失败(例如,文件校验和错误),但不容易造成;
确保模块以正确的方式与其他模块交互,但是很难观察到交互;因此你希望看到观察行动结束时的副作用;想模拟出复杂的依赖;
编写模拟类,用这个来代替输入或者替换掉一些函数要调用的其他接口或者类

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r