文章目录
😃😃😃😃😃
更多资源链接,欢迎访问作者gitee仓库:https://gitee.com/fanggaolei/learning-notes-warehouse/tree/master
Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。
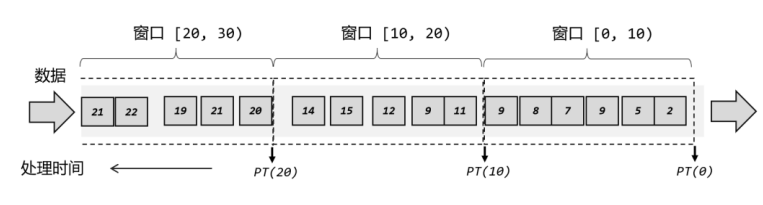
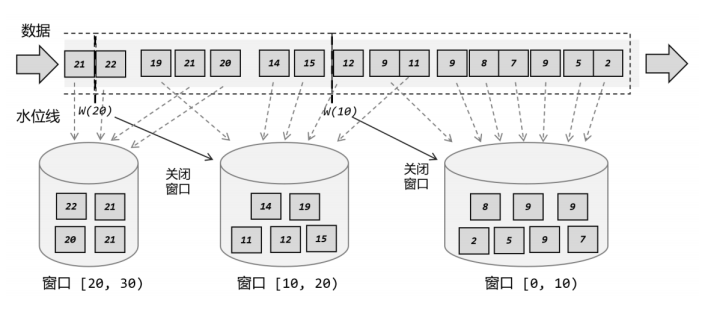
所以在 Flink 中,窗口其实并不是一个“框”,流进来的数据被框住了就只能进这一个窗口。相比之下,我们应该把窗口理解成一个“桶”。在 Flink 中,窗口可以把流切割成有限大小的多个“存储桶”(bucket);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
1.按照驱动类型分类
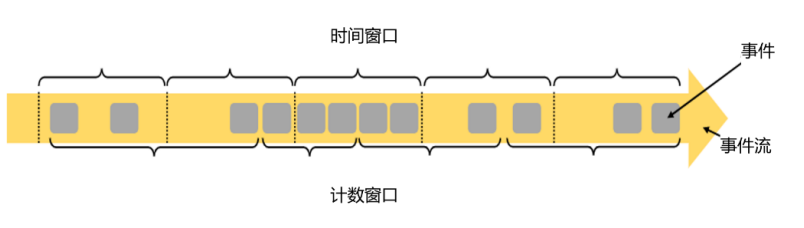
(1)时间窗口(Time Window)
时间窗口以时间点来定义窗口的开始(start)和结束(end),所以截取出的就是某一时间段的数据。到达结束时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。所以可以说基本思路就是“定点发车”。
(2)计数窗口(Count Window)
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。这相当于座位有限、“人满就发车”,是否发车与时间无关。每个窗口截取数据的个数,就是窗口的大小。
2.按照窗口分配数据的规则分类
(1)滚动窗口(Tumbling Windows)
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。
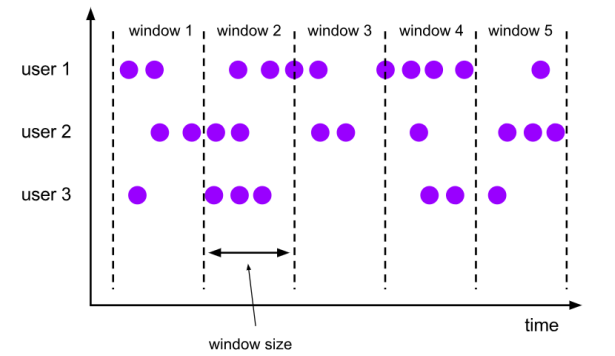
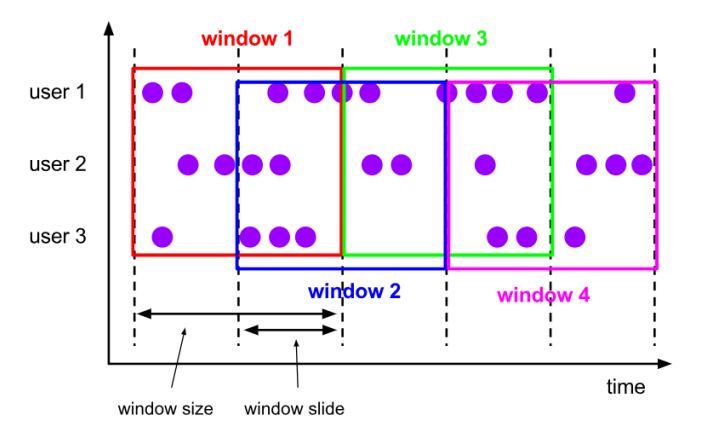
(2)滑动窗口(Sliding Windows)
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。
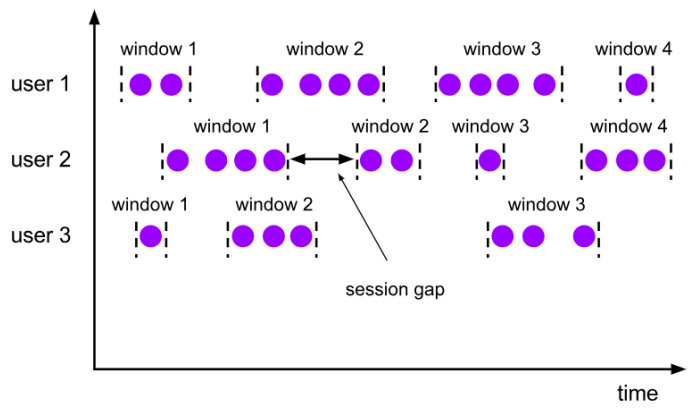
(3)会话窗口(Session Windows)
会话窗口顾名思义,是基于“会话”(session)来来对数据进行分组的。这里的会话类似Web 应用中 session 的概念,不过并不表示两端的通讯过程,而是借用会话超时失效的机制来描述窗口。简单来说,就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来,那么就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭。
(4)全局窗口(Global Windows)
还有一类比较通用的窗口,就是“全局窗口”。这种窗口全局有效,==会把相同 key 的所有数据都分配到同一个窗口中;==说直白一点,就跟没分窗口一样。无界流的数据永无止尽,所以这种窗口也没有结束的时候,默认是不会做触发计算的。

1.按键分区(Keyed)和非按键分区(Non-Keyed)
(1)按键分区窗口(Keyed Windows)
在调用窗口算子之前,是否有 keyBy 操作。
stream.keyBy(...)
.window(...)
(2)非按键分区(Non-Keyed Windows)
推荐KeyBy之后再开窗
这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了 1。所以在实际应用中一般不推荐使用这种方式。
stream.windowAll(...)
2.代码中窗口 API 的调用
stream.keyBy(<key selector>)
.window(<window assigner>) //窗口分配器
.aggregate(<window function>) //窗口函数
1.时间窗口
(1)滚动处理时间窗口
窗口分配器由类 TumblingProcessingTimeWindows 提供,需要调用它的静态方法.of()
stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
这里.of()方法需要传入一个 Time 类型的参数 size,表示滚动窗口的大小,我们这里创建了一个长度为 5 秒的滚动窗口。
(2)滑动处理时间窗口
窗口分配器由类 SlidingProcessingTimeWindows 提供,同样需要调用它的静态方法.of()
stream.keyBy(...)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
这里.of()方法需要传入两个 Time 类型的参数:size 和 slide,前者表示滑动窗口的大小,后者表示滑动窗口的滑动步长。我们这里创建了一个长度为 10 秒、滑动步长为 5 秒的滑动窗口。
滑动窗口同样可以追加第三个参数,用于指定窗口起始点的偏移量,用法与滚动窗口完全一致。
(3)处理时间会话窗口
窗口分配器由类 ProcessingTimeSessionWindows 提供,需要调用它的静态方法.withGap()或者.withDynamicGap()。
stream.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
这里.withGap()方法需要传入一个 Time 类型的参数 size,表示会话的超时时间,也就是最小间隔 session gap。我们这里创建了静态会话超时时间为 10 秒的会话窗口。
(4)滚动事件时间窗口
窗口分配器由类 TumblingEventTimeWindows 提供,用法与滚动处理事件窗口完全一致。
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(...)
这里.of()方法也可以传入第二个参数 offset,用于设置窗口起始点的偏移量。
(5)滑动事件时间窗口
窗口分配器由类 SlidingEventTimeWindows 提供,用法与滑动处理事件窗口完全一致。
stream.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
(6)事件时间会话窗口
窗口分配器由类 EventTimeSessionWindows 提供,用法与处理事件会话窗口完全一致
stream.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
2.计数窗口
(1)滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数 size,表示窗口的大小
stream.keyBy(...)
.countWindow(10)
(2)滑动计数窗口
与滚动计数窗口类似,不过需要在.countWindow()调用时传入两个参数:size 和 slide,前者表示窗口大小,后者表示滑动步长。
stream.keyBy(...)
.countWindow(10,3)
我们定义了一个长度为 10、滑动步长为 3 的滑动计数窗口。每个窗口统计 10 个数据,每隔 3 个数据就统计输出一次结果。
3.全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调用.window(),分配器由 GlobalWindows 类提供。
stream.keyBy(...)
.window(GlobalWindows.create());
需要注意使用全局窗口,必须自行定义触发器才能实现窗口计算,否则起不到任何作用。
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生
多年来,我在各种网站上遇到过各种问题,用户在字符串和文本字段的开头/结尾放置空格。有时这些会导致格式/布局问题,有时会导致搜索问题(即搜索顺序看起来不对,但实际上并非如此),有时它们实际上会使应用程序崩溃。我认为这会很有用,而不是像我过去所做的那样放入一堆before_save回调,向ActiveRecord添加一些功能以在保存之前自动调用任何字符串/文本字段上的.strip,除非我告诉它不是,例如do_not_strip:field_x,:field_y或类定义顶部的类似内容。在我去弄清楚如何做到这一点之前,有没有人看到更好的解决方案?明确一点,我已经知道我可以做到这一点:befor
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
我正在尝试为ChefRecipe编写一个库,以简化一些常见的搜索。例如,我希望能够在cookbook/libraries/library.rb中执行类似的操作,然后从同一Recipe中的Recipe中使用它:moduleExampledefself.search_attribute(attribute_name)returnsearch(:nodes,node[attribute_name])endend问题是,在Chef库文件中,node对象或search函数都不可用。似乎可以使用Chef::Search::Query.new().search(...)进行搜索,但我找不到任何可以访
目录一、安装包链接二、安装详细步骤1.安装Wireshark和WinPcap2.安装OracleVMVirtualBox3.安装ensp三、安装后注册四、启动路由器出现40错误怎么解决一、安装包链接二、安装详细步骤链接:https://pan.baidu.com/s/1QbUUYMOMIV2oeIKHWP1SpA?pwd=xftx提取码:xftx1.安装Wireshark和WinPcap找到Wireshark安装包所在文件夹,双击它,按照以下步骤安装。2.安装OracleVMVirtualBox找到OracleVMVirtualBox安装包所在文件夹,双击它,按照以下步骤安装。注:可自定义安装
Nginx安装1.官网下载Nginx2.使用XShell和Xftp将压缩包上传到Linux虚拟机中3.解压文件nginx-1.20.2.tar.gz4.配置nginx5.启动nginx6.拓展(修改端口和常用命令)(一)修改nginx端口(二)常用命令1.官网下载Nginxhttp://nginx.org/en/download.html这里我下载的是1.20.2版本,大家按需下载对应稳定版即可2.使用XShell和Xftp将压缩包上传到Linux虚拟机中没有XShell可以参考《Linux操作系统CentOS7连接XShell》3.解压文件nginx-1.20.2.tar.gz1)检查是否存
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.