各位朋友们大家好,今天是我leedcode刷题系列的第三篇,废话不多说,直接进入主题。
文章目录
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你不需要 保留 每个分区中各节点的初始相对位置。
示例 1:
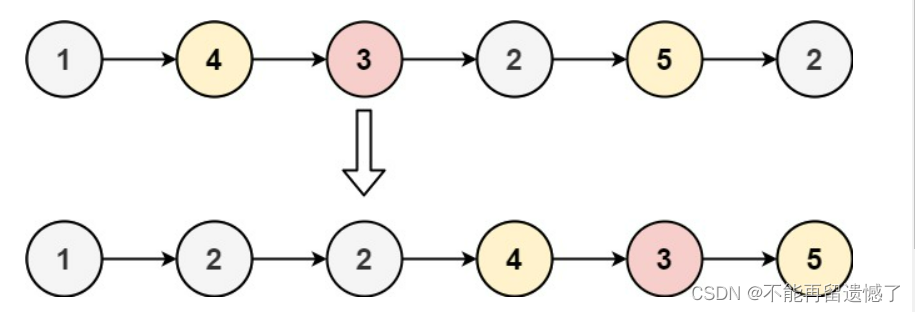
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1,2]
这是题目提供的接口
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* partition(struct ListNode* head, int x){
}
提示:
链表中节点的数目在范围 [0, 200] 内
-100 <= Node.val <= 100
-200 <= x <= 200
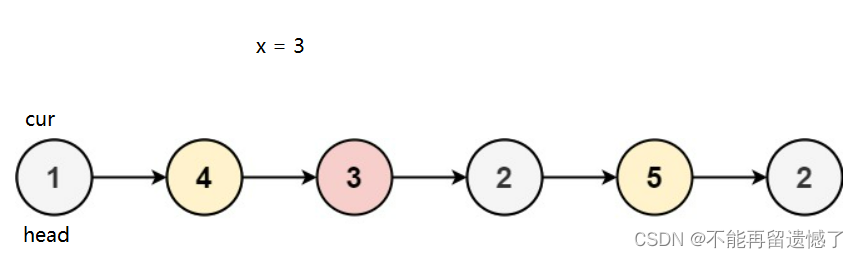
我们可以使用一个指针来遍历链表,遇到比x值小的数字就放在左侧,大于或等于的结点就放在右侧,最后再用指针将这两个部分连接起来,得出来的就是我们需要的结果。
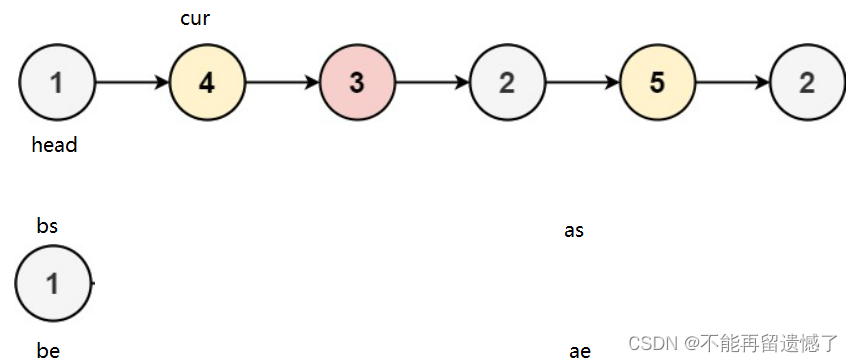
定义四个结构体指针:bs和be分别指向小于x部分链表的头和尾,as和ae分别指向大于或等于x部分链表的头和尾。
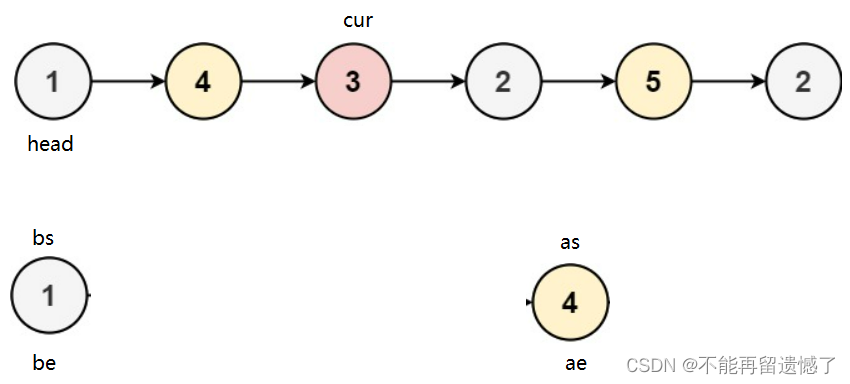
持续这个动作,知道cur等于NULL。
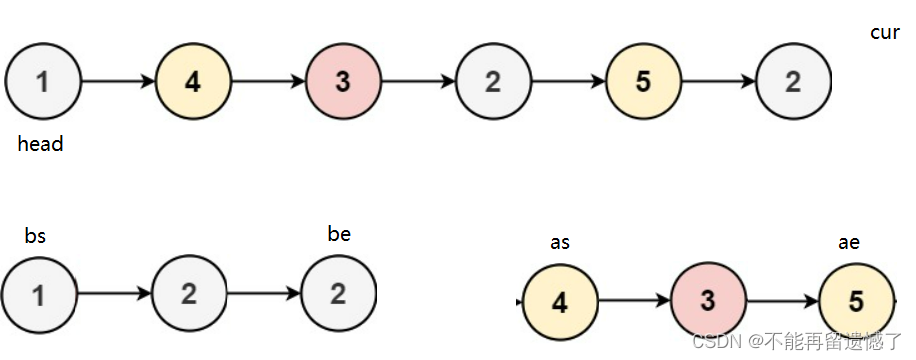
然后我们这两部分用指针连接起来。并且将ae手动置为NULL,防止链表出现死循环。

我们在做完了之后我们还需要注意的是:当只有小于x的值或者只有大于x的部分的时候我们上面的思路是不行的,我们需要做出判断,当bs为NULL时我们可以直接返回as,因为就算as也为NULL,返回的也是NULL。当as为NULL时,我们直接返回bs,不需要将ae置为NULL。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* partition(struct ListNode* head, int x){
//定义四个结构体指针来管理小于和大于等于x两部分的链表
//小于x部分的头节点
struct ListNode* bs = NULL;
//小于x部分的尾节点
struct ListNode* be = NULL;
//大于x部分的头节点
struct ListNode* as = NULL;
//大于x部分的尾节点
struct ListNode* ae = NULL;
//cur用来遍历链表
struct ListNode* cur = head;
while(cur != NULL)
{
if(cur->val < x)
{
//当第一次出现小于x的节点的时候,bs和be都是这个节点
if(bs == NULL)
{
bs = cur;
be = cur;
}
else
{
be->next = cur;
be = be->next;
}
}
else
{
//第一次出现大于x的节点
if(as == NULL)
{
as = cur;
ae = cur;
}
else
{
ae->next = cur;
ae = ae->next;
}
}
cur = cur->next;
}
//判断是否有小于x的节点
if(bs == NULL)
{
return as;
}
//连接两部分链表
be->next = as;
//判断是否有大于x的节点
if(as != NULL)
{
ae->next = NULL;
}
return bs;
}
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode partition(ListNode head, int x) {
//我们的Java代码与c语言略有不同,
//我们将bs和as作为哨兵位
if(head == null) {
return null;
}
ListNode bs = new ListNode(0);
ListNode be = bs;
ListNode as = new ListNode(0);
ListNode ae = as;
ListNode cur = head;
while(cur != null) {
if(cur.val < x) {
be.next = cur;
be = be.next;
}else {
ae.next = cur;
ae = ae.next;
}
cur = cur.next;
}
if(bs.next == null) {
return as.next;
}
be.next = as.next;
if(as.next != null) {
ae.next = null;
}
return bs.next;
}
}
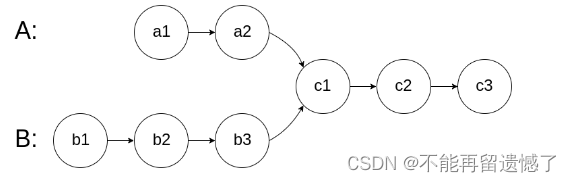
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
示例 1:
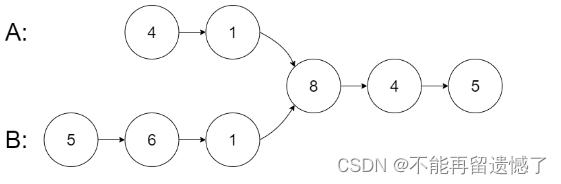
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at ‘8’
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
示例 2:
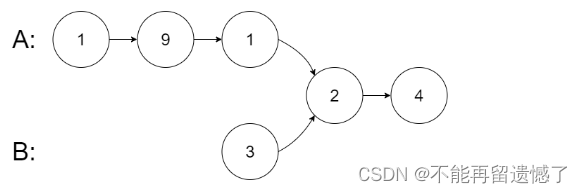
输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at ‘2’
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
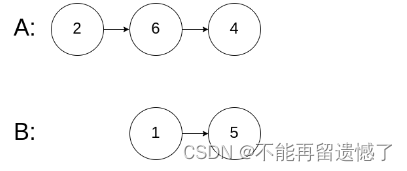
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
题目提供的接口
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
}
提示:
listA 中节点数目为 m
listB 中节点数目为 n
1 <= m, n <= 3 * 104
1 <= Node.val <= 105
0 <= skipA <= m
0 <= skipB <= n
如果 listA 和 listB 没有交点,intersectVal 为 0
如果 listA 和 listB 有交点,intersectVal == listA[skipA] == listB[skipB]
当这两个链表从后面剩余的节点的个数相同的地方开始走,他们会在相交节点相遇。但是因为两个链表的长度不一定是相同的,所以我们需要求出两个链表的长度的差值len,然后让长的链表先走len步,然后再一起走,当他们的地址相同时就说明到达了相交节点,我们就返回这个节点。
//我们将计算链表长度这个功能单独提出来,写成一个函数
int listLength(struct ListNode* head)
{
struct ListNode* cur = head;
int count = 0;
while (cur != NULL)
{
count++;
cur = cur->next;
}
return count;
}
struct ListNode* getIntersectionNode(struct ListNode* headA, struct ListNode* headB) {
//当其中一个链表为空就说明没有相交节点,我们直接返回
if (headA == NULL || headB == NULL)
{
return NULL;
}
//我们将ll作为长度较长的链表的指针
struct ListNode* ll = headA;
//sl作为长度较短的链表的指针
struct ListNode* sl = headB;
int lenA = listLength(headA);
int lenB = listLength(headB);
int len = lenA - lenB;
//如果len<0,我们就交换ll跟sl的指向
if (len < 0)
{
ll = headB;
sl = headA;
len = -len;
}
for (int i = 0; i < len; i++)
{
ll = ll->next;
}
while (ll && sl)
{
if (ll == sl)
{
return ll;
}
ll = ll->next;
sl = sl->next;
}
return NULL;
}
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
//链表长的就走差值步
//pl永远指向较长的链表
//p2永远指向较短的链表
public class Solution {
public int getLength(ListNode head) {
int count = 0;
ListNode cur = head;
while(head != null) {
head = head.next;
count++;
}
return count;
}
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if(headA == null || headB == null) {
return null;
}
ListNode pl = headA;
ListNode ps = headB;
int len1 = getLength(pl);
int len2 = getLength(ps);
int len = len1-len2;
if(len < 0) {
pl = headB;
ps = headA;
len = -len;
}
while(len != 0) {
pl = pl.next;
len--;
}
while(pl != ps) {
pl = pl.next;
ps = ps.next;
}
return pl;
}
}
ValidPalindromeGivenastring,determineifitisapalindrome,consideringonlyalphanumericcharactersandignoringcases. [#125]Example:"Aman,aplan,acanal:Panama"isapalindrome."raceacar"isnotapalindrome.Haveyouconsiderthatthestringmightbeempty?Thisisagoodquestiontoaskduringaninterview.Forthepurposeofthisproblem
前言我们习惯用idea编写、调试代码,在LeetCode上刷题时,如果能够在IDEA编写代码,并且做好代码管理,是一件事半功倍的事情。对于后续复习题目,做笔记也会非常便利。本文目的在于介绍LeetCodeEditor的使用,以及配置工具类,最终目录结构如下:note:放置笔记src:放置代码leetcode.editor.cn:插件LeetCodeEditor自动生成utils:自定义的工具包,可用于自动化输入测试用例,定义题目需要的类(结构体)out:运行测试时自动生成LeetCodeEditorGitHub:https://github.com/shuzijun/leetcode-edit
一、题目给你一个整数数组ranks和一个字符数组suit。你有5张扑克牌,第i张牌大小为ranks[i],花色为suits[i]。下述是从好到坏你可能持有的手牌类型:“Flush”:同花,五张相同花色的扑克牌。“ThreeofaKind”:三条,有3张大小相同的扑克牌。“Pair”:对子,两张大小一样的扑克牌。“HighCard”:高牌,五张大小互不相同的扑克牌。请你返回一个字符串,表示给定的5张牌中,你能组成的最好手牌类型。注意:返回的字符串大小写需与题目描述相同。来源:力扣(LeetCode)链接:https://leetcode.cn/problems/best-poker-hand/d
一.面试总结 4月20号下午进行了一场大数据视频面试,总结一下踩坑点: 1.确定面试后,第一件事要和HR确定面试方式,具体时间、地点、什么软件、岗位JD等必须信息。 这里很多人有一个思想误区,认为问的太多会给HR不好的印象;其实大可不必,如果你通过了简历筛选,你就有权力使用公司招聘的人力资源。 2.要在面试10分钟前就进入面试的环境中,以防突发事件。 3.面试最开始都会有一个自我介绍环节,这个自我介绍环节,一定要慎之又慎,最好写下来,让朋友、长辈等审核多遍。 注:我面试时,在这踩了一个坑,自我介绍的时候踩了我要面试的岗位一脚,被技术面试官抓住了这一点
🍎道阻且长,行则将至。🍓🌻算法,不如说它是一种思考方式🍀算法专栏:👉🏻123一、🌱344.反转字符串题目描述:编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组s的形式给出。不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用O(1)的额外空间解决这一问题。来源:力扣(LeetCode)难度:简单提示:1s[i]都是ASCII码表中的可打印字符示例1:输入:s=[“h”,“e”,“l”,“l”,“o”]输出:[“o”,“l”,“l”,“e”,“h”]示例2:输入:s=[“H”,“a”,“n”,“n”,“a”,“h”]输出:[“h”,“a”,“n”,“n”,“a”,“H”
数据规模->时间复杂度10^8内容二维数组中的路径问题买卖股票的最佳时机lc62【剑指098】【top100】:不同路径https://leetcode.cn/problems/unique-paths/提示:1题目数据保证答案小于等于2*10^9#方案一:dfs+记忆化classSolution:defuniquePaths(self,m:int,n:int)->int:memo=[[-1]*nfor_inrange(m)]defdfs(i,j):ifi==m-1andj==n-1:return1ifi>=morj>=n:return0ifmemo[i][j]!=-1:returnmemo[
🍎道阻且长,行则将至。🍓🌻算法,不如说它是一种思考方式🍀算法专栏:👉🏻123hash是什么,哈希表为什么叫哈希表?一、🌱454.四数相加II题目描述:给你四个整数数组nums1、nums2、nums3和nums4,数组长度都是n,请你计算有多少个元组(i,j,k,l)能满足:0nums1[i]+nums2[j]+nums3[k]+nums4[l]==0来源:力扣(LeetCode)难度:中等提示:n==nums1.lengthn==nums2.lengthn==nums3.lengthn==nums4.length1-2^28示例1:输入:nums1=[1,2],nums2=[-2,-1],n
Halo,这里是Ppeua。平时主要更新C语言,C++,数据结构算法......感兴趣就关注我吧!你定不会失望。🌈个人主页:主页链接🌈算法专栏:专栏链接 我会一直往里填充内容哒!🌈LeetCode专栏:专栏链接 目前在刷初级算法的LeetBook。若每日一题当中有力所能及的题目,也会当天做完发出🌈代码仓库:Gitee链接🌈点击关注=收获更多优质内容🌈目录题目:111. 二叉树的最小深度题解:代码实现:题目:700. 二叉搜索树中的搜索题解:代码实现:题目:701. 二叉搜索树中的插入操作题解:代码实现:题目:450. 删除二叉搜索树中的节点题解:代码实现:完结撒花:人生苦短,
👻内容专栏:《LeetCode刷题专栏》🐨本文概括:189.轮转数组🐼本文作者:花碟🐸发布时间:2023.4.12目录思想1暴力求解代码实现:思想2三次倒置代码实现: 思想3memcpy零时拷贝代码实现:189.轮转数组 点击跳转到LeetCode平台OJ页面题目:给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。示例1:输入:nums=[1,2,3,4,5,6,7],k=3输出:[5,6,7,1,2,3,4]解释:向右轮转1步:[7,1,2,3,4,5,6]向右轮转2步:[6,7,1,2,3,4,5]向右轮转3步:[5,6,7,1,2,3,4]
🚀算法题🚀🌲算法刷题专栏|面试必备算法|面试高频算法🍀🌲越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨🌲作者简介:硕风和炜,CSDN-Java领域新星创作者🏆,保研|国家奖学金|高中学习JAVA|大学完善JAVA开发技术栈|面试刷题|面经八股文|经验分享|好用的网站工具分享💎💎💎🌲恭喜你发现一枚宝藏博主,赶快收入囊中吧🌻🌲人生如棋,我愿为卒,行动虽慢,可谁曾见我后退一步?🎯🎯🚀算法题🚀🍔目录🚗知识回顾🚩题目链接⛲题目描述🌟求解思路&实现代码&运行结果⚡动态规划🥦求解思路🥦实现代码🥦运行结果💬共勉🚗知识回顾大家再看这道题目之前,可以先去看一下我之前写过的一篇关于最长递增子序列算法