 离线开发是大数据平台的基础模块,提供大规模数据存储与计算能力,帮助数据开发人员完成数据加工工作,例如将数据从源头表加工成明细表,再加工成汇总表等。可选择搭载其它大数据产品,实现数据集成、数据研发、数据治理、数据服务等功能,灵活满足客户的各类场景。
离线开发是大数据平台的基础模块,提供大规模数据存储与计算能力,帮助数据开发人员完成数据加工工作,例如将数据从源头表加工成明细表,再加工成汇总表等。可选择搭载其它大数据产品,实现数据集成、数据研发、数据治理、数据服务等功能,灵活满足客户的各类场景。
insert overwrite table intern_new.dim_user_info_p
partition (ds='2021-07-25')
select id as user_id,
name as user_name,
province,
age
from intern_new.ods_user_info
where ds='2021-07-25';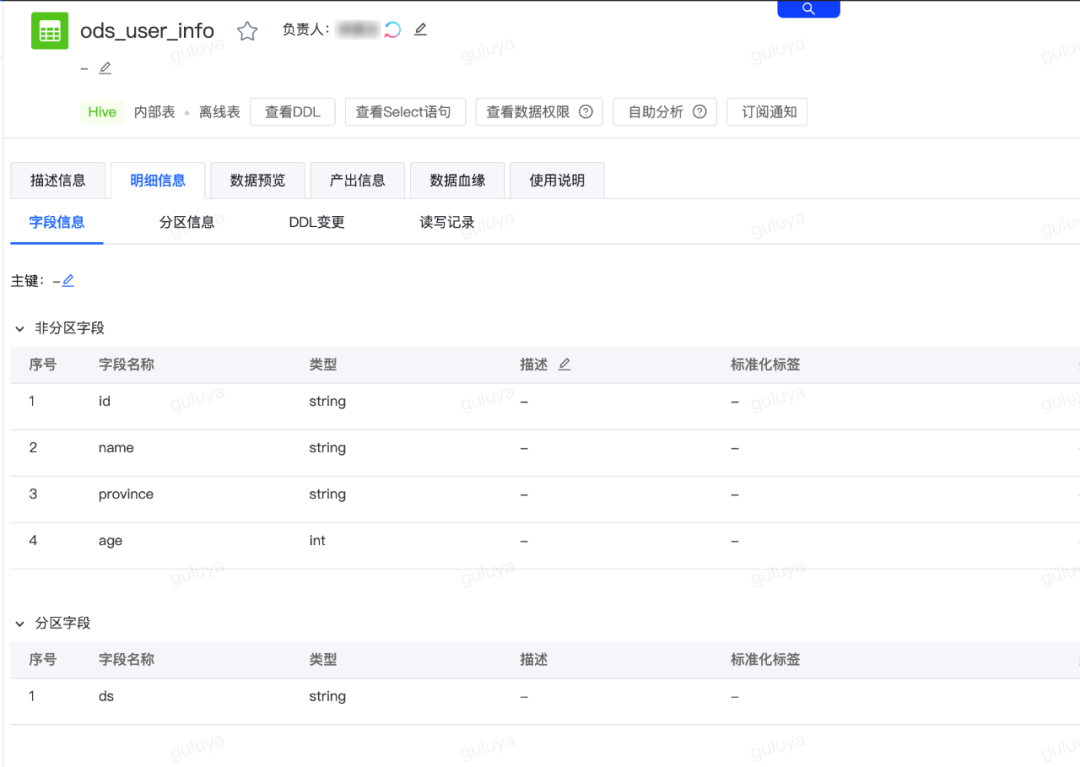 涉及的产品模块:离线开发、自助分析数据开发的流程:
涉及的产品模块:离线开发、自助分析数据开发的流程: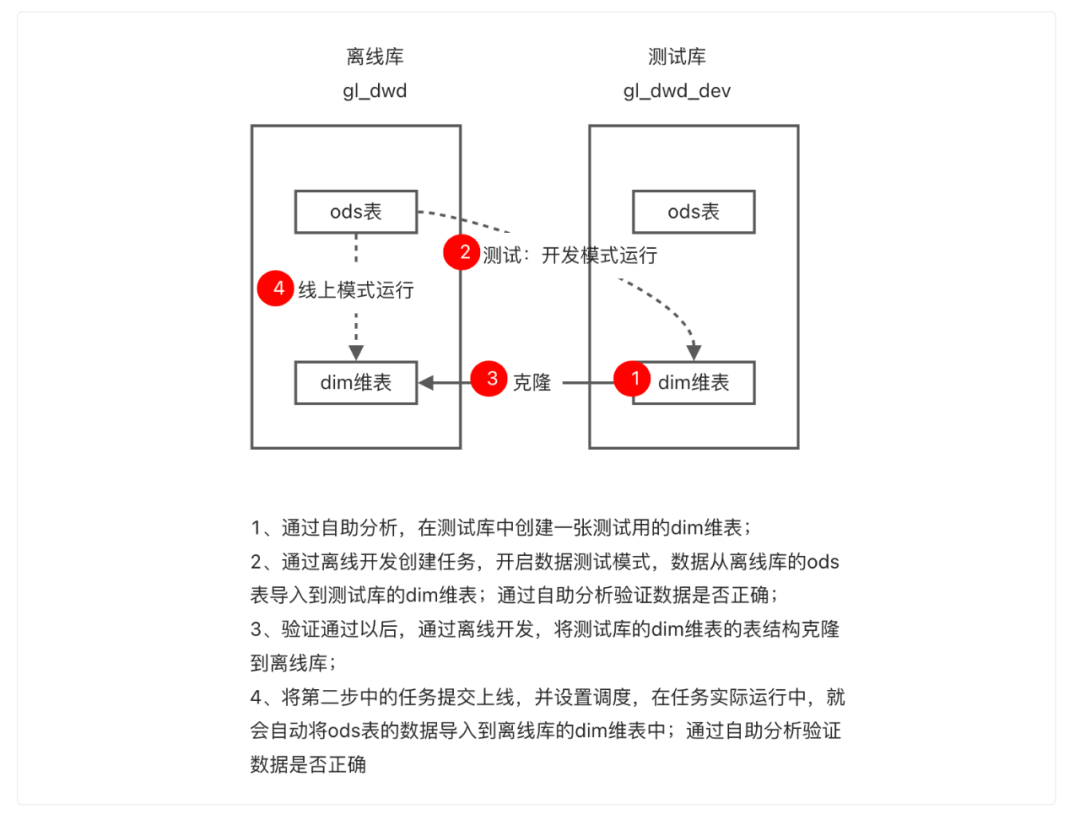 第一步:通过自助分析创建测试表首先我们需要通过自助分析,在gl_dwd_dev库中建一张测试用的dim维表,dim维表的表结构:
第一步:通过自助分析创建测试表首先我们需要通过自助分析,在gl_dwd_dev库中建一张测试用的dim维表,dim维表的表结构:| 字段 | 字段类型 | 字段描述 |
| user_id | string | 用户id |
| user_name | string | 用户姓名 |
| province | string | 省份 |
| age | int | 年龄 |
CREATE TABLE gl_dwd_dev.gly_dim_user_info_p (
user_id STRING COMMENT '用户id',
user_name STRING COMMENT '用户姓名',
province STRING COMMENT '省份',
age INT COMMENT '年龄')
PARTITIONED BY (ds STRING COMMENT '时间分区')
STORED AS PARQUET;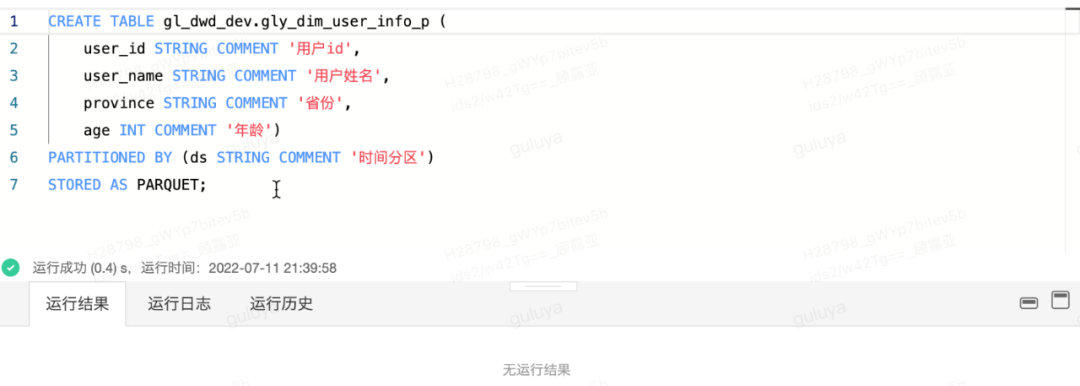 看到“运行成功”的提示,则说明测试库中的dim维表已经成功创建~第二步:通过离线开发创建任务我们通过离线开发创建任务,使得ods表的数据能够写入dim维表。先新建一个任务,然后在画布中拖入SQL节点,进入SQL编辑页面后输入下方代码,将gl_dwd.ods_user_info表的数据写入gl_dwd_dev.gly_dim_user_info_p这张表中:
看到“运行成功”的提示,则说明测试库中的dim维表已经成功创建~第二步:通过离线开发创建任务我们通过离线开发创建任务,使得ods表的数据能够写入dim维表。先新建一个任务,然后在画布中拖入SQL节点,进入SQL编辑页面后输入下方代码,将gl_dwd.ods_user_info表的数据写入gl_dwd_dev.gly_dim_user_info_p这张表中: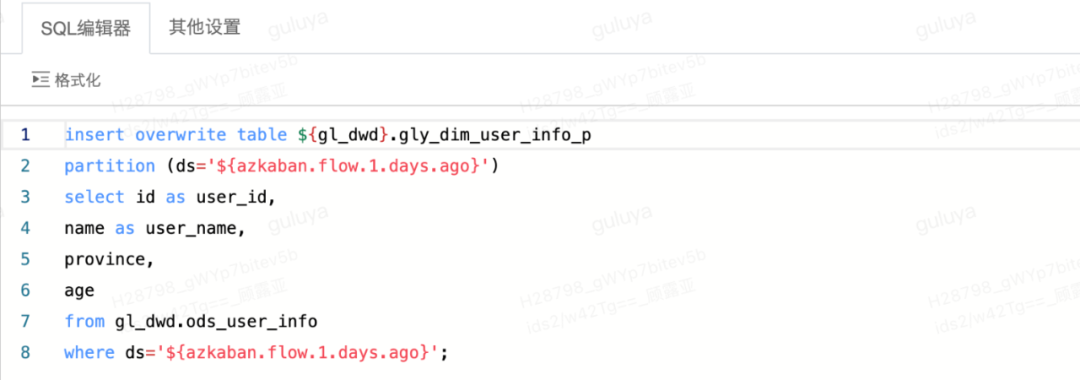 然后通过在开发模式下运行节点,若运行结果为成功,则表示代码能够正常执行,代码验证通过以后,我们可以去自助分析对数据进行验证。通过select语句,检查dim表中是否确实有了新的数据,select语句示例如下:
然后通过在开发模式下运行节点,若运行结果为成功,则表示代码能够正常执行,代码验证通过以后,我们可以去自助分析对数据进行验证。通过select语句,检查dim表中是否确实有了新的数据,select语句示例如下:SELECT * from gl_dwd_dev.gly_dim_user_info_p where ds='2022-07-10';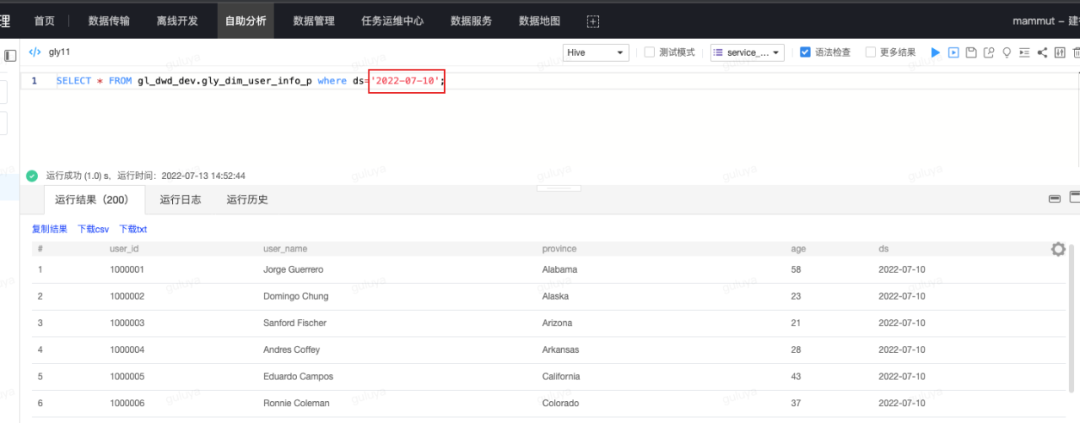 至此,我们就成功地通过离线开发,创建了一个开发任务,并且利用测试模式,完成了代码和表结构的验证!下一步,就可以将通过测试的测试库的表克隆到离线库,并将任务提交上线,让离线库中的我们真正的生产表也能有产出的数据。第三步:通过表克隆将测试完成的表结构克隆到离线库中仍然在离线开发,点击页面左上角的表克隆,选择待克隆的库表,以及目标库,即gl_dwd_dev库下在上一步骤中新建的dim维表,要将其克隆到离线库gl_dwd中,选择好以后点击克隆检验,检验通过后,即可点击下一步:
至此,我们就成功地通过离线开发,创建了一个开发任务,并且利用测试模式,完成了代码和表结构的验证!下一步,就可以将通过测试的测试库的表克隆到离线库,并将任务提交上线,让离线库中的我们真正的生产表也能有产出的数据。第三步:通过表克隆将测试完成的表结构克隆到离线库中仍然在离线开发,点击页面左上角的表克隆,选择待克隆的库表,以及目标库,即gl_dwd_dev库下在上一步骤中新建的dim维表,要将其克隆到离线库gl_dwd中,选择好以后点击克隆检验,检验通过后,即可点击下一步: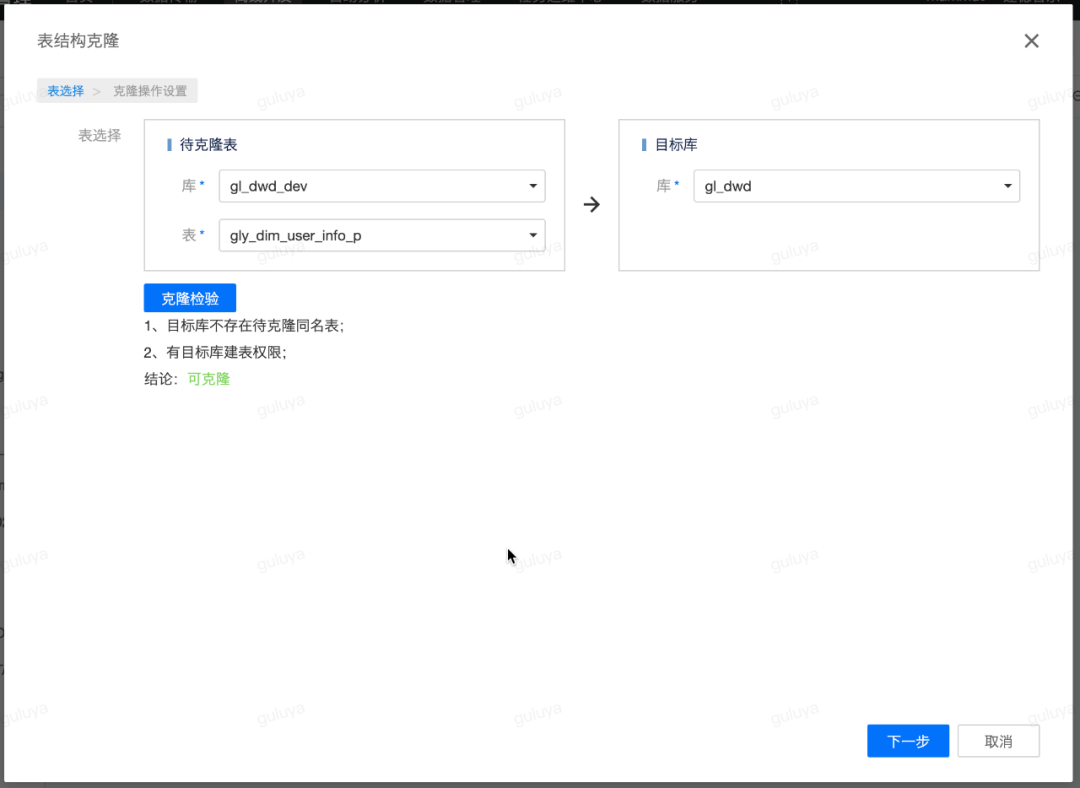 系统会自动生成对应表的DDL语句:
系统会自动生成对应表的DDL语句: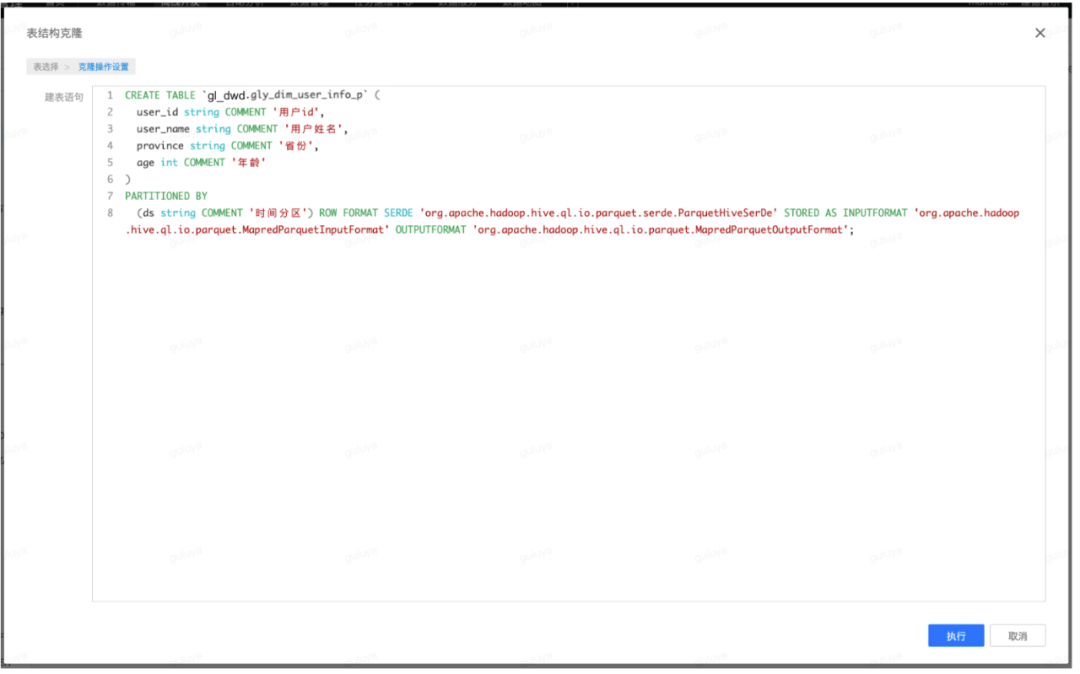 点击“执行”,会提示执行成功,即已经在gl_dwd库中生成了与gl_dwd_dev库中dim表结构一致、表名也一致的表。第四步:将任务提交上线并设置调度(1)提交上线:最后,就是将通过测试的任务提交上线并设置调度,让它能够按时产出数据,提供给下游使用。这里需要注意的是,我们用到的gl_dwd.ods_user_info表是任务gl_ods_user_info的产出表,这张表同时又是任务gly_demo的输入表,这两个任务均为每日调度产出,因此在实际数据加工的过程中,我们就需要保证,在任务gly_demo运行之前,同一调度周期内,任务gl_ods_uers_info必须已经成功产出数据,因此形成任务依赖关系:gl_ods_user_info-----> gly_demo,即任务gly_demo必须依赖任务gl_ods_user_info。离线开发支持通过自动解析任务的产出表,智能推荐任务依赖。在编辑调度页面,点击智能依赖,系统会自动计算并推荐上游任务及节点,点击确定后,就可以看到页面新增了任务依赖,表示该任务会在其依赖的任务,即gl_ods_user_info任务的实例产出后,才会开始运行。将任务调度信息设置完成之后,任务就会开始按照计划执行时间生成实例,在实际执行时,就会执行如下代码,将数据插入到“gl_dwd.gly_dim_user_info_p”表中:
点击“执行”,会提示执行成功,即已经在gl_dwd库中生成了与gl_dwd_dev库中dim表结构一致、表名也一致的表。第四步:将任务提交上线并设置调度(1)提交上线:最后,就是将通过测试的任务提交上线并设置调度,让它能够按时产出数据,提供给下游使用。这里需要注意的是,我们用到的gl_dwd.ods_user_info表是任务gl_ods_user_info的产出表,这张表同时又是任务gly_demo的输入表,这两个任务均为每日调度产出,因此在实际数据加工的过程中,我们就需要保证,在任务gly_demo运行之前,同一调度周期内,任务gl_ods_uers_info必须已经成功产出数据,因此形成任务依赖关系:gl_ods_user_info-----> gly_demo,即任务gly_demo必须依赖任务gl_ods_user_info。离线开发支持通过自动解析任务的产出表,智能推荐任务依赖。在编辑调度页面,点击智能依赖,系统会自动计算并推荐上游任务及节点,点击确定后,就可以看到页面新增了任务依赖,表示该任务会在其依赖的任务,即gl_ods_user_info任务的实例产出后,才会开始运行。将任务调度信息设置完成之后,任务就会开始按照计划执行时间生成实例,在实际执行时,就会执行如下代码,将数据插入到“gl_dwd.gly_dim_user_info_p”表中:
insert overwrite table gl_dwd.gly_dim_user_info_p
partition (ds='${azkaban.flow.1.days.ago}')
select id as user_id,
name as user_name,
province,
age
from gl_dwd.ods_user_info
where ds='${azkaban.flow.1.days.ago}';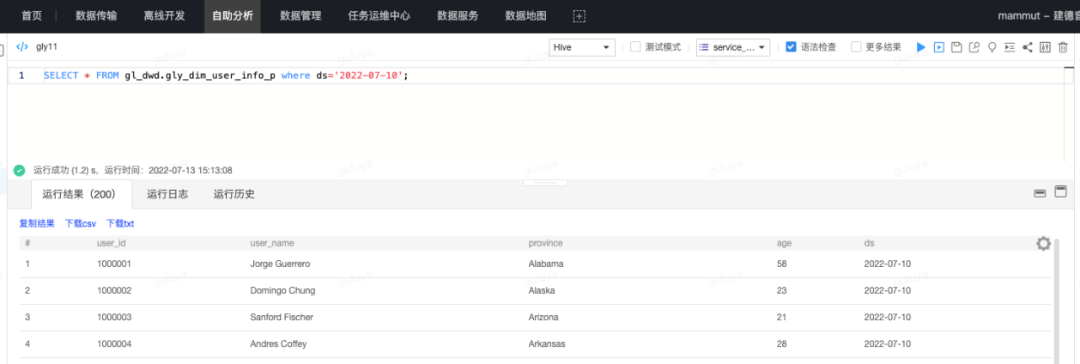 运行结果显示,离线库中的dim表已经拥有了正确的数据。至此,我们的离线开发任务就完成了开发、验证与上线的全部过程!3、总结以上通过一个简单案例完成了数据测试功能,引入“${db}”占位符,实现了db自动替换,解决了数据开发过程中的线上数据和开发数据隔离问题。在实际业务场景中,企业出于数据安全考虑往往存在着更复杂的数据存储方式与数据测试规范,大数据开发工作也逐渐往更规范、高效的方向发展,由此也对产品提出了更多的要求和挑战。离线开发产品也在不断吸收来自数据开发工作一线的用户使用场景与姿势,不断努力打磨产品,给用户带去更智能、更高效的大数据数据开发与测试体验。
运行结果显示,离线库中的dim表已经拥有了正确的数据。至此,我们的离线开发任务就完成了开发、验证与上线的全部过程!3、总结以上通过一个简单案例完成了数据测试功能,引入“${db}”占位符,实现了db自动替换,解决了数据开发过程中的线上数据和开发数据隔离问题。在实际业务场景中,企业出于数据安全考虑往往存在着更复杂的数据存储方式与数据测试规范,大数据开发工作也逐渐往更规范、高效的方向发展,由此也对产品提出了更多的要求和挑战。离线开发产品也在不断吸收来自数据开发工作一线的用户使用场景与姿势,不断努力打磨产品,给用户带去更智能、更高效的大数据数据开发与测试体验。 我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD