
🔎这里是【阿里云·云原生架构·白皮书】,关注我学习云原生不迷路
👍如果对你有帮助,给博主一个免费的点赞以示鼓励
欢迎各位🔎点赞👍评论收藏⭐️
【阿里云·云原生架构·白皮书】 主要更新一些在学习云原生架构时的一些总结,以及对白皮书内容的解读。
主要介绍主要架构模式
云原生架构有非常多的架构模式,这里选取一些对应用收益更大的主要架构模式进行讨论。
服务化架构是云时代构建云原生应用的标准架构模式,要求以应用模块为颗粒度划分一个软件,以接口契约(例如IDL)定义彼此业务关系,以标准协议(HTTP、gRPC等)确保彼此的互联互通,结合DDD(领域模型驱动)、TDD(测试驱动开发)、容器化部署提升每个接口的代码质量和迭代速度。服务化架构的典型模式是微服务和小服务(Mini Service)模式,其中小服务可以看做是一组关系非常密切的服务的组合,这组服务会共享数据,小服务模式通常适用于非常大型的软件系统,避免接口的颗粒度太细而导致过多的调用损耗(特别是服务间调用和数据一致性处理)和治理复杂度。
通过服务化架构,把代码模块关系和部署关系进行分离,每个接口可以部署不同数量的实例,单独扩缩容,从而使得整体的部署更经济。此外,由于在进程级实现了模块的分离,每个接口都可以单独升级,从而提升了整体的迭代效率。但也需要注意,服务拆分导致要维护的模块数量增多,如果缺乏服务的自动化能力和治理能力,会让模块管理和组织技能不匹配,反而导致开发和运维效率的降低。
SBA网络架构具备三大特征:
1、松耦合的微服务
2、轻量高效的服务调用接口
3、自动化、智能化的服务管理框架
Mesh 化架构是把中间件框架(比如RPC、缓存、异步消息等)从业务进程中分离,让中间件SDK与业务代码进一步解耦,从而使得中间件升级对业务进程没有影响,甚至迁移到另外一个平台的中间件也对业务透明。分离后在业务进程中只保留很“薄”的Client部分,Client通常很少变化,只负责与Mesh进程通讯,原来需要在SDK中处理的流量控制、安全等逻辑由Mesh进程完成。整个架构如下图所示。
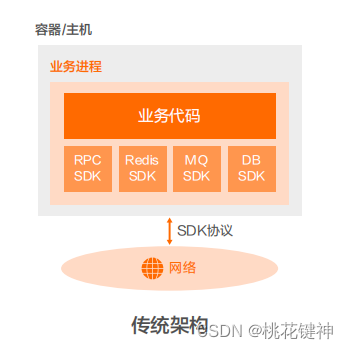

实施Mesh 化架构后,大量分布式架构模式(熔断、限流、降级、重试、反压、隔仓……)都由Mesh进程完成,即使在业务代码的制品中并没有使用这些三方软件包;同时获得更好的安全性(比如零信任架构能力)、按流量进行动态环境隔离、基于流量做冒烟/回归测试等。
Mesh网络有其自身的特点:
1、平衡负载,Mesh网络可以提供更大的冗余度以利负载平衡。在比较繁忙的网络,例如有两台设备进行大数据量的通讯,每台设备附近都有许多节点可供选择,创建多条路径来平衡负载。而单跳网络则没有动态调整的能力。
2、健壮性,因为Mesh网络不像单跳网络,仅仅依靠一个节点,一旦某个节点出现故障或者有冲突发生,Mesh网络可以继续工作,数据也可选择替代路径继续传递。
3、空间的复用性,Mesh网络可以充分地利用带宽。在一个单跳环境中,所有设备不得不共享一个节点,如果多台设备同时要求接入网络,那么必然导致速度变慢;而Mesh网络,多设备可以同时接入网络,却通过不同的节点。
和大部分计算模式不同,Serverless 将“部署”这个动作从运维中“收走”,使开发者不用关心应用在哪里运行,更不用关心装什么OS、怎么配置网络、需要多少CPU……从架构抽象上看,当业务流量到来/业务事件发生时,云会启动或调度一个已启动的业务进程进行处理,处理完成后云自动会关闭/调度业务进程,等待下一次触发,也就是把应用的整个运行时都委托给云。
今天Serverless 还没有达到任何类型的应用都适用的地步,因此架构决策者需要关心应用类型是否适合于Serverless运算。如果应用是有状态的,云在进行调度时可能导致上下文丢失,毕竟Serverless 的调度不会帮助应用做状态同步;如果应用是长时间后台运行的密集型计算任务,会得不到太多Serverless的优势;如果应用涉及到频繁的外部VO(网络或者存储,以及服务间调用),也因为繁重的IO负担、时延大而不适合。Serverless非常适合于事件驱动的数据计算任务、计算时间短的请求/响应应用、没有复杂相互调用的长周期任务。
Serverless 架构的 Traits 特质:
入门门槛低(Low barrier-to-entry)
无主机(Hostless)
无状态(Stateless)
弹性(Elasticity)
分布式(Distributed)
事件驱动(Event-driven)
分布式环境中的CAP困难主要是针对有状态应用,因为无状态应用不存在C(一致性)这个维度,因此可以获得很好的A(可用性)和P(分区容错性),因而获得更好的弹性。在云环境中,推荐把各类暂态数据(如session )、结构化和非结构化持久数据都采用云服务来保存,从而实现存储计算分离。但仍然有一些状态如果保存到远端缓存,会造成交易性能的明显下降,比如交易会话数据太大、需要不断根据上下文重新获取等,则可以考虑通过采用Event Log +快照(或 Check Point)的方式,实现重启后快速增量恢复服务,减少不可用对业务的影响时长。
分离架构有以下优势:
对于不同类型的集群,可以针对性地部署更加合适的服务器;
计算和存储可以分别按需进行扩展,而不是一起扩展;
不同集群可以有不同的升级周期;
划分了运维职责,更加便于管理;
提高了资源利用率,降低了能耗开销。
微服务模式提倡每个服务使用私有的数据源,而不是像单体这样共享数据源,但往往大颗粒度的业务需要访问多个微服务,必然带来分布式事务问题,否则数据就会出现不一致。架构师需要根据不同的场景选择合适的分布式事务模式。
可观测架构包括Logging、Tracing、Metrics三个方面,其中Logging提供多个级别( verboseldebuglwarning/errorlfatal)的详细信息跟踪,由应用开发者主动提供;Tracing 提供一个请求从前端到后端的完整调用链路跟踪,对于分布式场景尤其有用;Metrics则提供对系统量化的多维度度量。
架构决策者需要选择合适的、支持可观测的开源框架(比如OpenTracing、OpenTelemetry ) ,并规范上下文的可观测数据规范(例如方法名、用户信息、地理位置、请求参数等),规划这些可观测数据在哪些服务和技术组件中传播,利用日志和tracing 信息中的span id/trace id,确保进行分布式链路分析时有足够的信息进行快速关联分析。
由于建立可观测性的主要目标是对服务SLO ( Service Level Objective)进行度量,从而优化SLA,因此架构设计上需要为各个组件定义清晰的SLO,包括并发度、耗时、可用时长、容量等。
事件驱动架构(EDA,Event Driven Architecture)本质上是一种应用/组件间的集成架构模式,典型的事件驱动架构如下图:在这里插入图片描述

事件和传统的消息不同,事件具有schema,所以可以校验event的有效性,同时EDA具备QoS保障机制,也能够对事件处理失败进行响应。事件驱动架构不仅用于(微)服务解耦,还可应用于下面的场景中:

我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails