目录
本次数据是在网上获取的来源于:数据集-阿里云天池,不在进行抓取或收集,大家可以看这篇文章Python爬虫-抓取数据到可视化全流程的实现,详细的写了数据抓取的过程
使用的主要工具:python --jupyter notebook
用户行为分析是对用户在产品上的产生的行为及行为背后的数据进行分析,通过本次分析希望可以实现:
1、通过构建用户行为模型和用户画像,来改变产品决策,实现精细化运营,指导业务增长。
2、 在产品运营过程中,对用户行为的数据进行收集、存储、跟踪、分析与应用等,可以找到实现用户自增长的存在的问题、群体特征与目标用户。
data=final_data
data.head()查看一下我们合并后表格的情况,可以发现目前表格的列数为7列

其中'Unnamed: 0','user_geohash'(有缺失)两列数据我们在分析时不涉及,对这两列数据进行删除。
import pandas as pd
final_data.drop(['Unnamed: 0','user_geohash'],axis=1,inplace=True)
final_data.head()
成功进行删除,检查数据类型
data.dtypes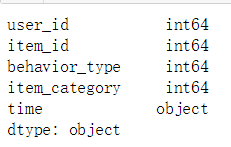
可以发现目前time是object型的,因为分析涉及到时间、天、小时,所以,要把数据集里的时间戳列,即time_stamp列转化为日期。。
data['date'] = data['time'].map(lambda x:x.split(' ')[0])
data['hour'] = data['time'].map(lambda x:x.split(' ')[1])
data['date']=pd.to_datetime(data['date'])
data['hour'] = data['hour'].astype('int32')
data.head()
data.dtypes

data.isnull().sum()
data.shape
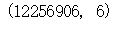
可以看到数据中并没有空数据,数据的规模在1000万左右,分为6列,依次为用户id、商品id、用户行为类型、时间。其中用户行为类型中1代表点击(当做pv),2代表collect(收藏),3代表cart(加入购物车)数据较为完整,不需要继续进行清洗,对数据进行分析
1)每天的PV、UV变化情况
# 总PV值=数据条数
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
data.shape[0]##日PV
pv_daily = data.groupby(['date'])['user_id'].count().reset_index().rename(columns={'user_id':'pv_daily'})
pv_daily.head()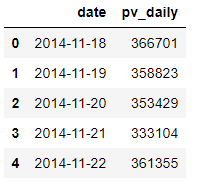
日平均独立访客数与日平均流量的区别在于要进行去重
##日UV
uv_daily = data.groupby(['date'])['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv_daily'})
uv_daily.head()
s=uv_daily['uv_daily']
pv_daily['uv_daily']=s
pv_daily将两表合并

plt.figure(figsize=(40,20),dpi=80)
font={
"family":"kaiti",
"size":'30'
}
plt.rc("font",**font)
plt.subplot(211)#在第一个位置日平均流量图
plt.plot(pv_daily['date'],pv_daily['pv_daily'],'co-')
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
plt.gca().xaxis.set_major_locator(mdates.DayLocator()) # 按月显示,按日显示的话,将MonthLocator()改成DayLocator()
plt.gcf().autofmt_xdate()
ax=plt.gca()
ax.spines["top"].set_color("w")
ax.spines["bottom"].set_color("r")
ax.spines["left"].set_color("r")
ax.spines["right"].set_color("w")
plt.gcf().autofmt_xdate()
#设置X轴标签
plt.xlabel("时间")
#设置y轴标签
plt.ylabel("日平均流量统计图")
plt.title('日平均流量')
plt.figure(figsize=(40,20), dpi=80)
plt.subplot(212)#第二个位置绘制日平均独立访客数
plt.plot(pv_daily['date'],pv_daily['uv_daily'],'yo-')
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
plt.gca().xaxis.set_major_locator(mdates.DayLocator())
ax=plt.gca()
ax.spines["top"].set_color("w")
ax.spines["bottom"].set_color("r")
ax.spines["left"].set_color("r")
ax.spines["right"].set_color("w")
plt.title('日独立访问客流量')
plt.gcf().autofmt_xdate()
#设置X轴标签
plt.xlabel("时间")
#设置y轴标签
plt.ylabel("日独立访客量统计图")
plt.show()
绘制子图,将日平均流量和独立访问客数放在一起进行对比分析:

可以发现在双十二当天是流量和独立访客数的高峰,在平常波动不大
每天时刻数据
# 每天的时刻数据
pv_daily_hour = data.groupby(['hour'])['user_id'].count().reset_index().rename(columns={'user_id':'pv'})
uv_daily_hour = data.groupby(['hour'])['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv'})
pv_daily_hour.head()
uv_daily_hour.head()

plt.figure(figsize=(15,18),dpi=80)
plt.subplot(211)
plt.plot(pv_daily_hour['hour'],pv_daily_hour['pv'],'bo-')
plt.title("每小时PV")
plt.savefig("每小时PV.png")
plt.xticks(np.arange(0, 24, step=1))
plt.xlim(data.index.values[0])
plt.figure(figsize=(15,18),dpi=80)
plt.subplot(212)
plt.plot(uv_daily_hour['hour'],uv_daily_hour['uv'],'yo-')
plt.title("每小时UV")
plt.savefig("每小时UV.png")
plt.xticks(np.arange(0, 24, step=1))
plt.xlim(data.index.values[0])
plt.show()

plt.figure(figsize=(10, 4))
sns.lineplot(data=d_pv_h, lw=3)
plt.show()
plt.figure(figsize=(10, 4))
sns.lineplot(data=d_pv_h.iloc[:, 1:], lw=3)
plt.show() 
虽然大体上各波动趋势相同,但是加购物车数远高于收藏数。
## 每个UV的平均访问深度=总流量/独立访客数
round(data['user_id'].shape[0]/data['user_id'].nunique(),2)
##=1225.69
## 每个UV的日平均访问深度
round(data['user_id'].shape[0]/data['user_id'].nunique()/data['date'].nunique(),2)
##=39.54分析期间,每个UV的平均PV量是1225.69,每个UV的平均访问深度是39.54
## 计算每一个行为环节用户的访问量
view = data.groupby(['behavior_type'])['user_id'].count().reset_index().rename(columns={'user_id':'pv'})
view.head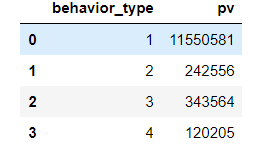
其中:
| beihavior_type | - |
| 1 | 点击 |
| 2 | 收藏 |
| 3 | 加购物车 |
| 4 | 支付 |
#计算各个环节的流失率
print("点击->加购物车流失率是:%d" % round((view['pv'][0]-view['pv'][2])*100/view['pv'][0],4) + '%')
print('点击->收藏流失率是:%d' % round((view['pv'][0]-view['pv'][1])*100/view['pv'][0],4) + '%')
print('加购物车->支付的流失率是:%d' % round((view['pv'][2]-view['pv'][3])*100/view['pv'][2],4) + '%')
print('收藏->支付的流失率是:%d' % round((view['pv'][1]-view['pv'][3])*100/view['pv'][1],4) + '%')
from pyecharts.charts import Funnel
attr = ['点击','收藏','加购物车','支付']
# 数据支持[(属性,数量)]
image_data = [(attr[i],int(view['pv'][i])) for i in range(len(attr))]
print(image_data)
funnel = (Funnel().add(series_name='用户行为漏斗', data_pair=image_data))
funnel.render_notebook()
用户产生点击后可能进行的操作分别为:点击->加购物车、点击->收藏、加购物车->支付、收藏->支付,可以明显的看出用户的流失率比较大,根据用户购买途径计算出各个阶段用户流失率:
独立访客漏斗模型计算:
view = data.groupby(['behavior_type'])['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'pv'})
view
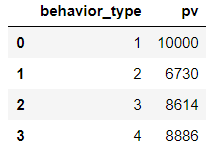

可以看到相应的转化率还是比较高的!
##计算每天的购买数量
df = data[data['date']!='2014-12-12']
date_buy = df[df['behavior_type']==4].groupby(['date'])['item_id'].count().reset_index()
date_buy
##计算每小时的购买数量
hour_buy = df[df['behavior_type']==4].groupby(['hour'])['item_id'].count().reset_index()
hour_buy

plt.figure(figsize=(20,5))
plt.plot(date_buy['date'],date_buy['item_id'])
plt.xticks(rotation=30)
plt.title('按日期观察成交量')
plt.savefig("按日期观察成交量.png")
plt.show() 
plt.figure(figsize=(20,5))
plt.plot(hour_buy['hour'],hour_buy['item_id'])
plt.xticks(rotation=30)
plt.title('按时段观察成交量')
plt.savefig("按时段观察成交量.png")
plt.show() 
用户转化行为漏斗模型分析
UV):29233,页面总访问量为(PV):2685348,平均每人每周访问量为91.8次页面
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我在新的Debian6VirtualBoxVM上安装RVM时遇到问题。我已经安装了所有需要的包并使用下载了安装脚本(curl-shttps://rvm.beginrescueend.com/install/rvm)>rvm,但以单个用户身份运行时bashrvm我收到以下错误消息:ERROR:Unabletocheckoutbranch.安装在这里停止,并且(据我所知)没有安装RVM的任何文件。如果我以root身份运行脚本(对于多用户安装),我会收到另一条消息:Successfullycheckedoutbranch''安装程序继续并指示成功,但未添加.rvm目录,甚至在修改我的.bas
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_