系统上公有云安全需要考虑什么?
最近在项目合作中涉及到部分业务需要上公有云,但翻了一些公开材料没有发现很好的介绍业务上公有云安全应该怎么做,故整理一篇材料分享业务上公有云应该怎么实践,本人水平有限难免疏漏,当作抛砖引玉了,欢迎同仁交流。
随着信息化的程度加深,一般来说客户上云有可能是基于以下几点考虑:
基于云上系统的业务需求,梳理上云后需要使用的安全服务,一般来说会涉及以下几块内容:
假设:如果一个云上架构的业务,涉及生产环境、开发环境、涉及数据与IDC进行交换,并具有互联网资产暴露、云上同时具有应用服务及其对应的数据库,部分安全能力使用自有系统部署的公有云安全架构基本会如下图(图例以腾讯云为例)所示:
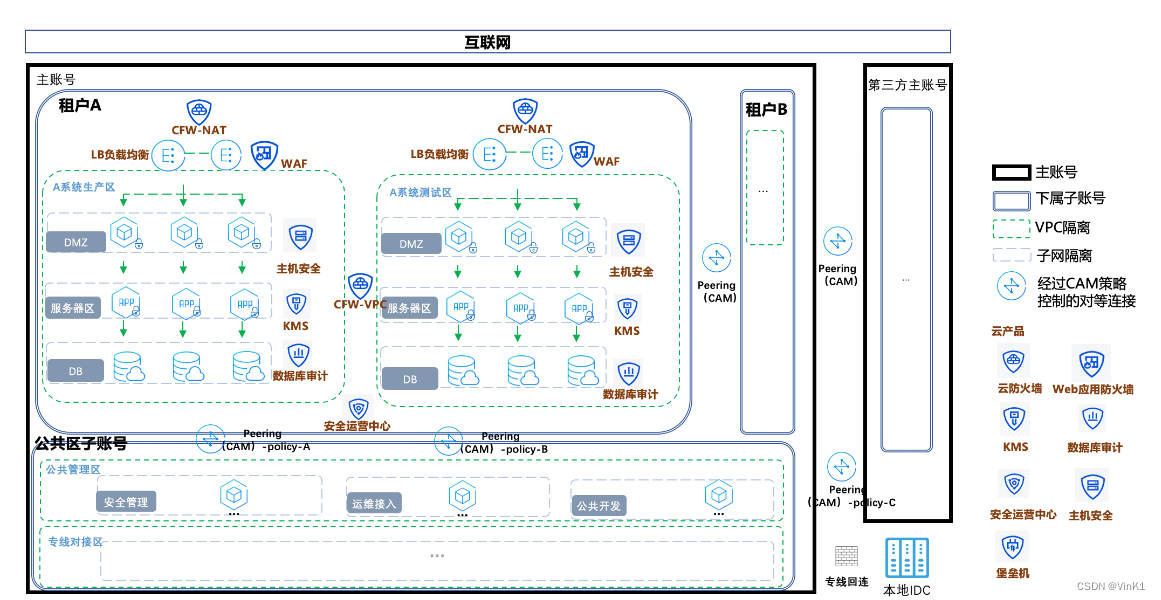
安全能力的隔离层级从小到大依次为:
由于云服务商把云上常用的IT能力封装成了云服务,故对于权限管控的设计主要着眼于:不同的子账号、不同的AKSK可以有什么权限访问业务所需访问的云服务。
一般来说建议将安全、网络、主机、数据库、监控等这些可以直接对IT资源进行操作的账号进行权限分离,避免单独账号或AKSK权限过大导致的外部入侵扩散或内部权限滥用,并在区域、系统、可操作模块实现细化控制,
如:基于腾讯云的提供的权限管控功能,可以大致实现以下的权限矩阵:
灰色部分为按需设计,
黄色格子为可读权限
蓝色格子为可写权限
绿色格子为读写权限
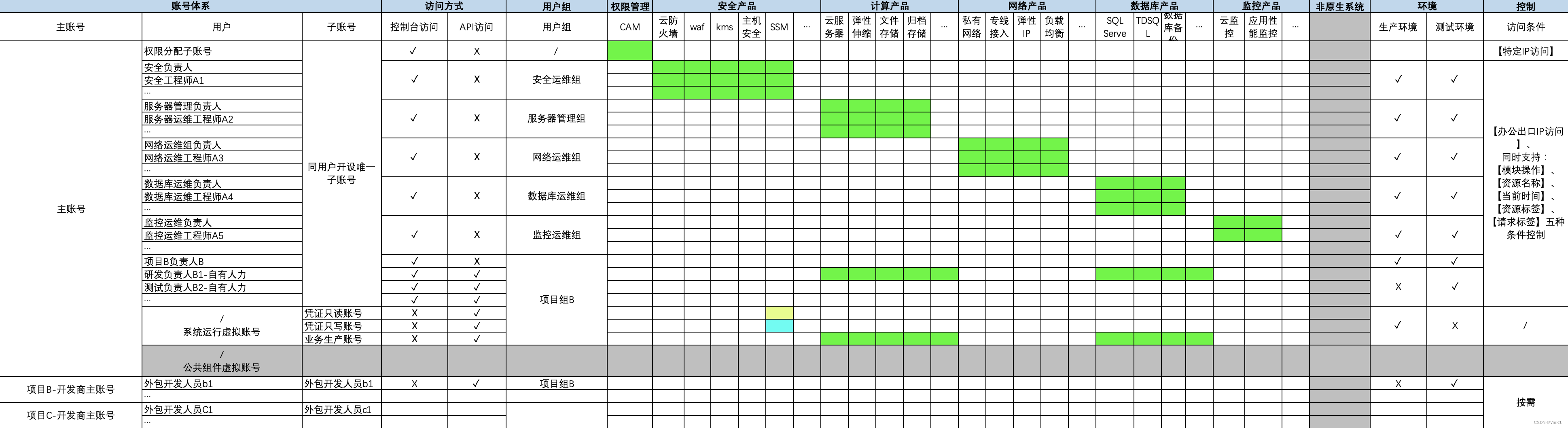
其中需要注意的两个点是:
1. 由于希望避免云服务之间调用的AKSK需要留存在本地导致的硬编码问题,基于凭证管理服务,使用三权分立的原则进行服务之间调用的AKSK的全生命周期管理;
2. 各个角色访问控制台基于云平台提供的【IP】、【标签】、【时间】、【请求资源】、【具体功能模块】进行细化的权限管控,并形成安全策略组进行默认策略分发
基于上述的云厂商提供的服务、安全服务的启用,并对权限矩阵进行设计后,基本可以实现公有云基础安全能力的保障以及账号和AKSK的权限分离,但在实际安全的落地中,仍然有很多安全性上的问题需要进一步,下面罗列一些以供后续实际落地中进行考虑:
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串