摘要:循环神经网络(RNN)可是在语音识别、自然语言处理等其他领域中引起了变革!
本文分享自华为云社区《【MindSpore易点通】深度学习系列-循环神经网络上篇》,作者:Skytier
循环神经网络(RNN)可是在语音识别、自然语言处理等其他领域中引起了变革!
循环神经网络(RNN)其实就是序列模型,我们先来看看其应用场景。

在语音识别时,给定了一个输入音频片段X ,并要求输出对应的文字记录Y 。这里的输入和输出数据都是序列模型,输入X是一个按时播放的音频片段,输出Y是一系列文字。
音乐生成问题也是一样,输出数据Y是序列,而输入数据X可以是空集,也可以是个单一的整数(代表音符)。
而系列模型在DNA序列分析中也十分有用,DNA可以用A、C、G、T四个字母来表示。所以给定一段DNA序列,你能够标记出哪部分是匹配某种蛋白质的吗?
以上所有类似问题都可以被称作使用标签数据(X,Y)作为训练集的监督学习,输入数据X或者输出数据Y是序列,即使两者都是序列也有数据长度不同的问题。
比如建立一个序列模型,它的输入语句是这样的:“Sam Li and Tom date on Tuesday.”。然后模型是可以自动识别句中人名位置的命名实体识别模型,可以用来查找不同类型的文本中的人名、公司名、时间、地点、国家名和货币名等等。
假定输入数据x,序列模型的输出y,使得输入的每个单词都对应一个输出值,同时y还需要表明输入的单词是否是人名的一部分。
首先输入语句是7个单词组成的时序序列,所以最终会有7个特征集x:x<1>,x<2>,...,x<7>,同时可以索引其序列中的位置。Tx表示输出序列的长度,这里Tx=7。
同理,输出数据也是一样,分别对应y<1>,y<2>,...,y<7>,Ty表示输出序列的长度。

那么问题来了,首先我们需要准备一个比较大的词典库,可能该库里的第一个单词是a,and出现在第367个位置上,Sam是在7459这个位置,Tom则在8674。
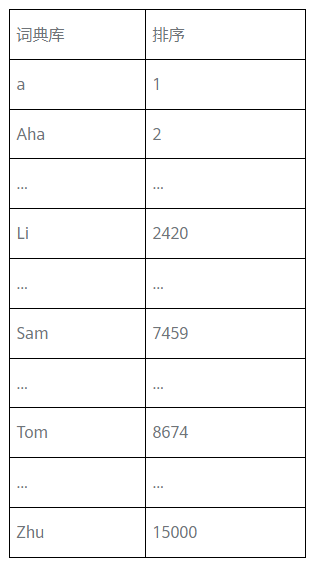
那么我们就可以在这个词典库的基础上遍历训练集。
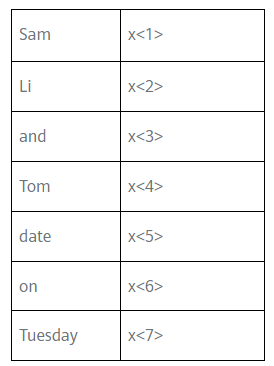
那么也就是说,Sam由x<1>表示,其是一个第7459行是1,其余值都是0的向量;Li由x<2>表示,其是一个第2420行是1,其余值都是0的向量。
通常我们称这种x指代句子里的任意词为one-hot向量,只有一个值是1,其余值都是0,所以整句话中我们会有7个one-hot向量,用序列模型在X和Y目标输出之间学习建立一个映射关系。
PS:如果遇到了一个在你词表中的单词,可以创建一个Unknow Word的伪造单词,用<UNK>作为标记。
通常情况下,我们会首先选取标准的神经网络,输入7个one-hot向量,经过一些隐藏层,最终会输出7个值为0或1的项,表明每个输入单词是否是人名的一部分。

但最后我们总会遇到这样的问题:
1.输入和输出数据的长度并不完全一致,即使采用填充(pad)或零填充(zero pad)使每个输入语句都达到最大长度,但最后的表达式会很奇怪。
2.简单的神经网络并不会共享从文本的不同位置上学到的特征。因为我们希望,如果首次学习的时候我们已经知道了Tom是人名,那么当Tom出现在其他位置时,其并不能够自动识别,因此也不能够减少模型中参数的数量。
那么循环神经网络为啥会比普通的神经网络更加出众呢?
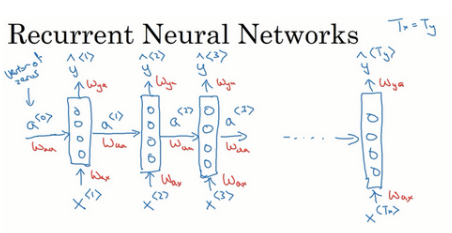

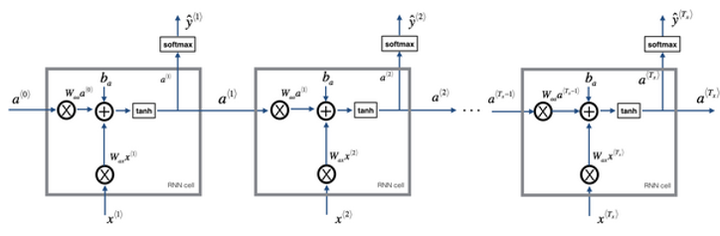
另外循环神经网络是从左向右扫描数据,同时每个时间步的参数也是共享的,用Wax来表示从x<1>到隐藏层的连接的一系列参数,每个时间步使用的都是相同的Wax参数,而激活值是由参数Waa决定的,输出结果由Way决定。
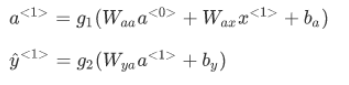
先输入零向量a<0>,接着进行前向传播过程,计算激活值a<1>,然后再计算y<1>。
更普遍来说,在t时刻:

为了更加简化一点,定义Wa:
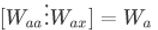
,假设a是100维的,x是10,000维的,那么Waa是(100,100)维的矩阵,Wax是(100,10000)维,Wa为(100,10100)。
同样,假定
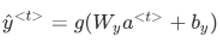
,Wy表明它是计算y类型的量的权重矩阵,而Wa和ba则表示这些参数是用来计算激活值的。
RNN前向传播示意图:
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
我是Ruby的新手,有些闭包逻辑让我感到困惑。考虑这段代码:array=[]foriin(1..5)array[5,5,5,5,5]这对我来说很有意义,因为i被绑定(bind)在循环之外,所以每次循环都会捕获相同的变量。使用每个block可以解决这个问题对我来说也很有意义:array=[](1..5).each{|i|array[1,2,3,4,5]...因为现在每次通过时都单独声明i。但现在我迷路了:为什么我不能通过引入一个中间变量来修复它?array=[]foriin1..5j=iarray[5,5,5,5,5]因为j每次循环都是新的,我认为每次循环都会捕获不同的变量。例如,这绝对
我经常将预配置的lambda插入可枚举的方法中,例如“map”、“select”等。但是“注入(inject)”的行为似乎有所不同。例如与mult4=lambda{|item|item*4}然后(5..10).map&mult4给我[20,24,28,32,36,40]但是,如果我制作一个2参数lambda用于像这样的注入(inject),multL=lambda{|product,n|product*n}我想说(5..10).inject(2)&multL因为“inject”有一个可选的单个初始值参数,但这给了我......irb(main):027:0>(5..10).inject
是否有self验证的问题列表。看着那个,我可以确定我知道。我应该复习一下。在学习的过程中,我列了一个这样的list,但它只包含我在某处听说过的项目。我需要一段时间才能找到新的东西。 最佳答案 以下是针对ruby和Rails的一些测试列表。证书名称:RubyonRails谁提供:oDeskIncorporation认证费用:免费网站:https://www.odesk.com/tests/985?pos=0证书名称:RubyonRails提供者:Techgig.com(TimesBusinessSolutionsLimited(T
我想覆盖store_accessor的getter。可以查到here.代码在这里:#Fileactiverecord/lib/active_record/store.rb,line74defstore_accessor(store_attribute,*keys)keys=keys.flatten_store_accessors_module.module_evaldokeys.eachdo|key|define_method("#{key}=")do|value|write_store_attribute(store_attribute,key,value)enddefine_met
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案