在使用 vite 进行项目打包时,默认已经帮我们做了一些优化工作,比如代码的压缩,分包等等。除此之外,我们还有一些可选的优化策略,比如使用 CDN ,开启 Gzip 压缩等。本文会介绍在 vite 中使用插件来开启 Gzip 压缩。
Gzip 是一种压缩算法,在网络传输中使用非常普遍。随便打开一个网页,都使用了 gzip 压缩:

需要注意的是,Gzip 压缩仅对于文本类型的资源有明显提示,压缩后的体积大约是压缩前的 1/3。对于图片,音视频等媒体资源,本身就采用了有损压缩,所以再使用 gzip 并不能得到很大提升,有时候反而会适得其反。
前端项目打包出的 js,css资源,非常适合使用 gzip 进行压缩。
这样,用户浏览器收到服务器返回的 gzip 类型资源时,会自动解压缩。这样,既能减少带宽的损耗,也能加快资源传输的时间。
Vite 社区插件中有一个 vite-plugin-compression,可以用来做 gzip 压缩。请看示例。
未使用 gzip 压缩前,打包后有一个很大的文件,控制台也给出了提示,使用 gzip 能大大减小文件体积:
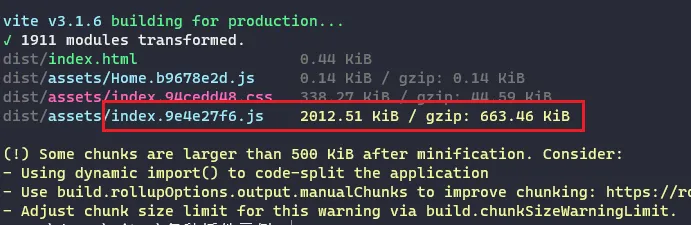
安装插件:
pnpm add -D vite-plugin-compression
配置文件:
vite.config.js
import viteCompression from 'vite-plugin-compression'
export default defineConfig({
plugins: [
// ...
viteCompression({
threshold: 1024000 // 对大于 1mb 的文件进行压缩
})
],
});
再次打包:
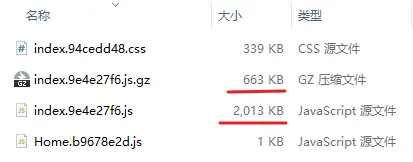
可以看到,原来 2mb 多的文件,经过压缩后还剩 663 kb,压缩带来的提升非常明显。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
是否有任何可用于Ruby的开源压缩/解压库?有没有人实现过LZW?或者,是否有任何使用压缩组件的开源库可以提取出来独立使用?编辑——感谢您的回答!我应该提到我必须压缩的是只驻留在数据库中的长字符串(我不会压缩文件)。此外,如果可以执行此操作的任何库都具有用于客户端压缩/分解的等效JavaScript实现,那将是理想的,因为这将用于Web应用程序。 最佳答案 您会在rubystdlib下找到所有已交付的ruby库的一个很好的列表.我会使用zlib库,它是开放的,无处不在,您会发现几乎所有语言的库!
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我有一个包含100多个zip文件的目录,我需要读取zip文件中的文件以进行一些数据处理,而无需解压缩存档。是否有一个Ruby库可以在不解压缩文件的情况下读取zip存档中的文件内容?使用rubyzip报错:require'zip'Zip::File.open('my_zip.zip')do|zip_file|#Handleentriesonebyonezip_file.eachdo|entry|#Extracttofile/directory/symlinkputs"Extracting#{entry.name}"entry.extract('here')#Readintomemoryc
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L
目录一.大致如下常见问题:(1)找不到程序所依赖的Qt库version`Qt_5'notfound(requiredby(2)CouldnotLoadtheQtplatformplugin"xcb"in""eventhoughitwasfound(3)打包到在不同的linux系统下,或者打包到高版本的相同系统下,运行程序时,直接提示段错误即segmentationfault,或者Illegalinstruction(coredumped)非法指令(4)ldd应用程序或者库,查看运行所依赖的库时,直接报段错误二.问题逐个分析,得出解决方法:(1)找不到程序所依赖的Qt库version`Qt_5'
我有一个使用Qt4绑定(bind)的Ruby应用程序。我希望能够打包并发布它。我查看了其他应用程序,例如rake和puppet,以了解它们是如何打包的。rake和puppet都被打包为gems。当我意识到rake和puppet都是更多的系统级工具而不是用户级应用程序时,我开始走这条路。我也看过orca,但它只是windows。除了gem或orca,是否还有其他选项可用于打包RubyGUI应用程序?我想要跨平台的东西。 最佳答案 看看platformgem规范。您可以为您的代码支持的每个平台打包一个gem。Somegemsconsis