CPU的硬件电路被设计成只能运行处于内存中的程序,这是硬件基因的问题,其原因是首先内存比较快且容量大,其次由于各个硬件特性不同,若被设计成运行硬件里的程序则操作系统要分别考虑每种硬件特性才行,为了达到统一,故选择只运行内存中的程序。其次内存不仅仅是DRAM,即内存不仅仅是主板上的内存条(物理内存),包括外设的ROM等。
载入内存分为两部分:第一部分是程序被加载器(软件或硬件)加载到内存的某个区域,第二部分是设置CPU的CS:IP寄存器指向这个程序的起始地址。
上面说过,主板上的物理内存不是它眼里的“全部的内存”。计算机中,并不是只有咱们插在主板上的内存条需要通过地址总线访问,还有一些外设同样是需要地址总线来访问的。若把全部的地址总线用来指向物理内存那么其他设备访问不了。由于这个原因只好在地址总线上提前预留出来一些地址空间用于存放这些外设,比如把连续的地址分配给显存,连续的地址分配给硬盘控制器等。留够了以后,地址总线上其余的可用地址再指向DRAM,也就是指插在主板上的内存条,我们眼中的物理内存。
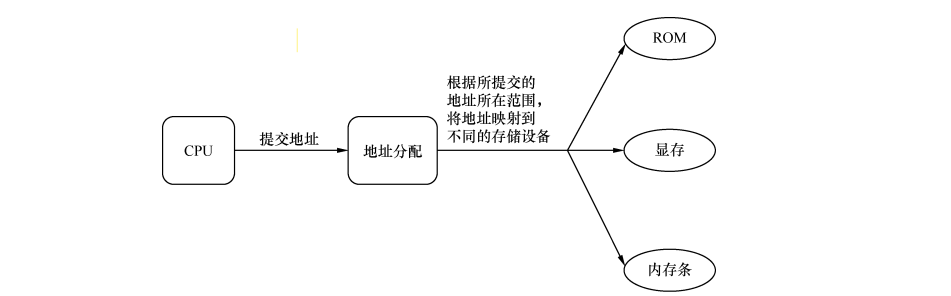
这也即是为什么电脑安装了8G,却显示7.8G的原因。
总之,表示地址的那串数字是地址总线的输入,相当于其参数,和内存条没关系。CPU能够访问一个地址,这是由于地址总线给的映射。相当于对该地址分配了一个存储单元。而该单元要么落在某个ROM上,要么落在物理内存条上,要么落在了某个外设的内存中。
“0 盘”说的是 0 磁头,因为一张盘是有上下 两个盘面的,一个盘面上对应一个磁头,所以用磁头 Header 来表示盘面。“0 道”是指 0 柱面,柱面 Cylinder 指的是所有盘面上、编号相同的磁道的集合,形象一点描述就是把很多环叠摞在一起的样子,组合在一起 之后是一个立体的管状。“1 扇区”才是我们要解释的部分,将磁道等距划分成一段段的小区间,由于磁 道是圆形的,确切地说是圆环,这些被划分出来的小区间便是扇形,所以称为扇区。
从主机上按下POWER键后,第一个运行的软件是BIOS(基本输入输出系统)。BIOS主要工作是检测,初始化硬件,怎么初始化的?硬件自己提供了一些初始化的功能调用,BIOS直接调用即可。不仅如此,BIOS还做了一个很重要的事,填写了中断向量表,这样就可以通过“int 中断号”来实现相关的硬件调用,当然BIOS建立的这些中断功能就是对硬件IO操作,也即输入输出。但是BIOS总共只有64KB,不可能把所有硬件的IO实现做的面面俱到,而且也没必要实现那么多因为在实模式下,对硬件支持得再丰富也是白搭,精彩的世界是进入保护模式以后才开始的,所以挑选一些重要的基本IO操作即可,这也是为什么称其为基本的原因。
BIOS如何启动的?因为BIOS是计算机上的第一个启动的软件,它不可能自己加载自己。由此可知道,它是由硬件加载的。这个硬件便是只读存储器ROM(硬件本身有一定的功能),此后,BIOS便被写入到该ROM中去,ROM也是块内存,于是被映射到低端的1MB处即0xf0000~0xfffff处,此后CS:IP被强制设置为0xf000:0xfff0(无论如何只要处理完后的地址是0xffff0即可为该16B为BIOS的入口地址)。只要访问该区间内的地址(映射所对应的存储单元,该映射是由硬件系统完成的)便是访问BIOS系统。
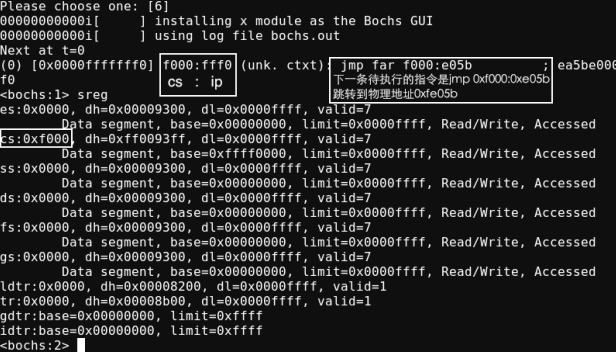
另外,因为 cs 和 ip 寄存器中存储的是下一条要执行的指令,目前还没有执行,也就是说,当前还没有 执行 BIOS,这是机器刚开机的那一刻。接下来BIOS就开始尽其责了,检测内存,显卡外设等,并初始化好硬件,开始在内存0x000~0x3ff处建立数据结构,中断向量表IVT并填写中断例程。
BIOS 最后一项工作校验启动盘中位于 0 盘 0 道 1 扇区的内容。如果此扇区末尾的两个字节分别是魔数 0x55 和 0xaa,BIOS 便认为此扇区中确实存在可执行的程序(在此先剧透一下,此程序便是久闻大名的主引导记录 MBR,MBR位于磁盘上最开始的那个扇区),便加载到物理地址 0x7c00,随 后跳转到此地址,继续执行,如果此扇区的最后 2 个不是 0x55 和 0xaa,即使里面有可执行代码也无济于事了,BIOS 不认。
那么会有两个疑问MBR为什么规定在为什么是 0 盘 0 道 1 扇区?为什么要加载到 0x7c00,而不是个好记或好看的其他地址?
第一个问题:我自行猜测很可能是为了约定,因为如果不告诉BIOS系统MBR在哪?BIOS系统会一遍遍的遍历所有硬盘直到碰见了0x55和0xaa两个魔数才知道是MBR所在位置,这样不如直接索性规定MBR在开始的扇区(可以是任意扇区,只要是固定位置即可),告诉BIOS系统 MBR在哪?这样方便很多
第二个问题:个人计算机肯定要运行操作系统,在这台计算机上,运行的操作系统是 DOS 1.0,不清楚此系统要求 的最小内存是 16KB,还是 32KB,反正 PC 5150 BIOS 研发工程师就假定其是 32KB 的,所以此版本 BIOS 是按最小内存 32KB 研发的。很简单,MBR首先其安装不能覆盖已有数据,其次也要避免自己的数据过早被覆盖(通常,MBR 的任务是加载某个程序<这个程序一 般是内核加载器,很少有直接加载内核的>到指定位置,并将控制权交给它。所谓的交控制权就是 jmp 过去而已。之后 MBR 就没用了,被覆盖也没关系。过早的覆盖指的是不被其加载的程序如内核加载器,使得内核加载器加载内核覆盖到自己的空间)。所以我们打个比方,比如说一个操作系统如DOS1.0要求内存至少要32KB,MBR希望给DOS留下更多的预留空间,这也是保全自己避免自己被过早覆盖,MBR 本身也是程序,是程序就要用到栈,栈也是在内存中的,MBR 虽然本身只有 512 字节,但还要为其 所用的栈分配点空间,所以其实际所用的内存空间要大于 512 字节,估计 1KB 内存够用了。结合以上三点,选择32KB中的最后1KB最为合适,那此地址是多少呢?32KB换算为十六进制为0x8000, 减去 1KB(0x400)的话,等于 0x7c00。
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
我最近与一位同事讨论了以下Ruby语法:value=ifa==0"foo"elsifa>42"bar"else"fizz"end我个人并没有看到太多这种逻辑,但我的同事指出,这实际上是一种相当普遍的Rubyism。我试着用谷歌搜索这个主题,但没有找到任何文章、页面或SO问题来讨论它,这让我相信这可能是一种非常实际的技术。然而,另一位同事发现语法令人困惑,而是将上面的逻辑写成这样:ifa==0value="foo"elsifa>42value="bar"elsevalue="fizz"end缺点是value=的重复声明和隐式elsenil的丢失,如果我们想使用它的话。这也感觉它与Ruby
多年来,我在各种网站上遇到过各种问题,用户在字符串和文本字段的开头/结尾放置空格。有时这些会导致格式/布局问题,有时会导致搜索问题(即搜索顺序看起来不对,但实际上并非如此),有时它们实际上会使应用程序崩溃。我认为这会很有用,而不是像我过去所做的那样放入一堆before_save回调,向ActiveRecord添加一些功能以在保存之前自动调用任何字符串/文本字段上的.strip,除非我告诉它不是,例如do_not_strip:field_x,:field_y或类定义顶部的类似内容。在我去弄清楚如何做到这一点之前,有没有人看到更好的解决方案?明确一点,我已经知道我可以做到这一点:befor
在尝试构建Rubygem(使用Bundler)时,我倾向于使用Bundler提供的REPL测试代码——可通过bundleconsole访问。有什么方法可以重新加载整个项目吗?我最终再次加载单个(更改的)文件以测试新更改。 最佳答案 以下hack适用于我的一个相对简单的gem和Ruby2.2.2。我很想看看它是否适合你。它做出以下假设:您具有传统的文件夹结构:一个名为lib/my_gem_name.rb的文件和一个文件夹lib/my_gem_name/,其中包含任何文件/文件夹结构。您要重新加载的所有类都嵌套在您的顶级模块MyGemN
这个问题在这里已经有了答案:Nokogiri:SelectcontentbetweenelementAandB(3个答案)关闭2年前。我正在从url中抓取文本的div,并想删除具有backtotop类的段落下方的所有内容。我在stackoverflow上看到了一段遍历代码片段,看起来很有希望,但我不知道如何将它合并,所以@el只包含第一个p.backtotop之前的所有内容分区我的代码:@doc=Nokogiri::HTML(open(url))@el=@doc.css("div")[0]end遍历片段:doc=Nokogiri::HTML(code)stop_node=doc.css
今天我遇到了下面的正则表达式,想知道Ruby会用它做什么:>"#a"=~/^[\W].*+$/=>0>"1a"=~/^[\W].*+$/=>nil在这种情况下,Ruby似乎忽略了+字符。如果这是不正确的,我不确定它在做什么。我猜它没有被解释为量词,因为*没有转义并且被用作量词。在Perl/Ruby正则表达式中,有时当一个字符(例如,-)在不能被解释为特殊字符的上下文中使用时,它会被视为文字。但如果在这种情况下发生这种情况,我希望第一个匹配失败,因为左值字符串中没有+。这是对+字符的巧妙正确使用吗?以上行为是错误吗?我是否遗漏了一些明显的东西? 最佳答案
我正在尝试为ChefRecipe编写一个库,以简化一些常见的搜索。例如,我希望能够在cookbook/libraries/library.rb中执行类似的操作,然后从同一Recipe中的Recipe中使用它:moduleExampledefself.search_attribute(attribute_name)returnsearch(:nodes,node[attribute_name])endend问题是,在Chef库文件中,node对象或search函数都不可用。似乎可以使用Chef::Search::Query.new().search(...)进行搜索,但我找不到任何可以访
解开谜团:深入探索ChatGPT的技术奇迹。ChatGpt无处不在,无论是在播客、博客、YouTube还是社交媒体上。当我注意到这项新技术如此受欢迎时,我决定试一试,我被震惊了!有很多关于ChatGpt及其魔力的博客,但在这篇博客中,我将深入探讨其内部技术及其工作原理!ChatGpt简介根据OpenAI,ChatGpt被描述为:“我们训练了一个名为ChatGpt的模型,它以对话方式进行交互。对话格式使ChatGpt可以回答后续问题、承认错误、挑战不正确的前提并拒绝不适当的请求。ChatGPT是InstructGPT的兄弟模型,它经过训练可以按照提示中的说明进行操作并提供详细的响应。”OpenA
由于安装nokogirigem(1.6.0)需要时间,我的生产部署需要额外几分钟。我知道这是因为安装gem会触发native扩展编译。请注意,我已经打包我的包并将其checkinDVCSbundlepackage如果没有其他任何变化,是否有一种方法可以避免重新编译native扩展,从而加快部署速度?更新:我使用OpscodeChef进行部署(具体来说是chef-solo)环境是:Ubuntu12.04LTS64位ruby193-p448 最佳答案 我找到了一种方法来做到这一点。解释如下:Bundler,默认情况下将gems安装到环境
我对Ruby很陌生,想知道运算符(operator)。当我用谷歌搜索这个运算符时,它说它是一个二进制左移运算符,给出了这个例子:awillgive15whichis11110000然而,它在这段代码中似乎不是“二进制左移运算符”:classTextCompressorattr_reader:unique,:indexdefinitialize(text)@unique=[]@index=[]add_text(text)enddefadd_text(text)words=text.splitwords.each{|word|doadd_word(word)}enddefadd_word(