本篇分析的技巧点其实是比较常见的,但是最近的几次的代码评审还是发现有不少兄弟没注意到。
所以还是想拿出来说下。
是个什么场景呢?
就是 for循环 里面还有 for循环, 然后做一些数据匹配、处理 这种场景。
我们结合实例代码来看看。
场景示例:
比如我们现在拿到两个list 数据 ,
一个是 User List 集合 ;
另一个是 UserMemo List集合;
我们需要遍历 User List ,然后根据 userId 从 UserMemo List 里面取出 对应这个userId 的 content 值,做数据处理。
代码 User.java :
import lombok.Data;
@Data
public class User {
private Long userId;
private String name;
}
代码 UserMemo.java :
import lombok.Data;
@Data
public class UserMemo {
private Long userId;
private String content;
}
模拟 数据集合 :
5W 条 user 数据 , 3W条 userMemo数据
public static List<User> getUserTestList() {
List<User> users = new ArrayList<>();
for (int i = 1; i <= 50000; i++) {
User user = new User();
user.setName(UUID.randomUUID().toString());
user.setUserId((long) i);
users.add(user);
}
return users;
}
public static List<UserMemo> getUserMemoTestList() {
List<UserMemo> userMemos = new ArrayList<>();
for (int i = 30000; i >= 1; i--) {
UserMemo userMemo = new UserMemo();
userMemo.setContent(UUID.randomUUID().toString());
userMemo.setUserId((long) i);
userMemos.add(userMemo);
}
return userMemos;
}
先看平时大家不注意的时候可能会这样去写代码处理 :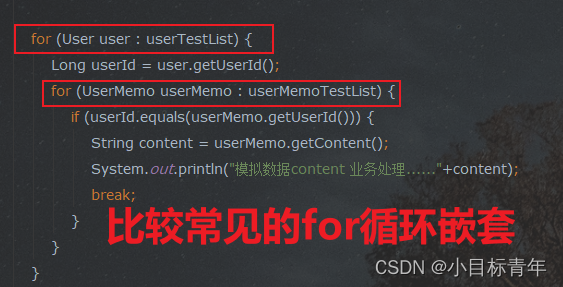
ps: 其实数据量小的话,其实没多大性能差别,不过我们还是需要知道一些技巧点。
代码:
public static void main(String[] args) {
List<User> userTestList = getUserTestList();
List<UserMemo> userMemoTestList = getUserMemoTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (User user : userTestList) {
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList) {
if (userId.equals(userMemo.getUserId())) {
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......"+content);
}
}
}
stopWatch.stop();
System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());
}
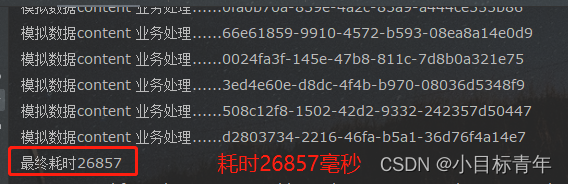
我们来看看 这时候的一个耗时情况 :
相当于迭代了 5W * 3W 次
可以看到用时 是 26857毫秒
其实到这,插入个题外点,如果说每个userId 在 UserMemo List 里面 都是只有一条数据的场景。
for (User user : userTestList) {
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList) {
if (userId.equals(userMemo.getUserId())) {
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......"+content);
}
}
}
单从这段代码有没有问题 ,有没有优化点。
显然是有的, 因为当我们从内循环UserMemo List里面找到匹配数据的时候, 没有做其他操作了。
这样 内for循环会继续下,直到跑完再进行下一轮整体循环。
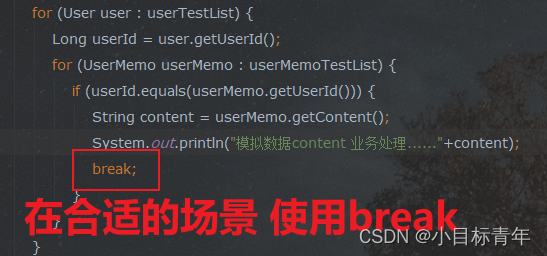
所以,仅针对这种情形,1对1的或者说我们只需要找到一个匹配项,处理完后我们 应该使用 break 。
我们来看看 加上 break 的一个耗时情况 :
代码:
public static void main(String[] args) {
List<User> userTestList = getUserTestList();
List<UserMemo> userMemoTestList = getUserMemoTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (User user : userTestList) {
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList) {
if (userId.equals(userMemo.getUserId())) {
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......"+content);
break;
}
}
}
stopWatch.stop();
System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());
}
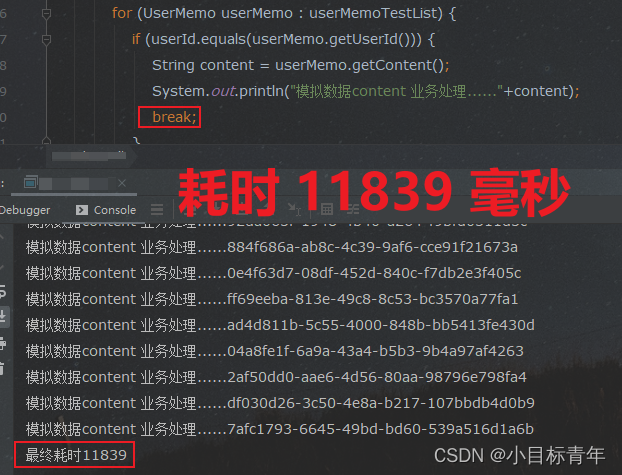
耗时情况:
可以看到 从 2W 多毫秒 变成了 1W 多毫秒, 这个break 加的很OK。
回到我们刚才, 平时需要for 循环 里面再 for 循环 这种方式,可以看到耗时是 2万6千多毫秒。
那如果场景更复杂一定, 是for 循环里面 for循环 多个或者, for循环里面还有一层for 循环 ,那这样代码耗时真的非常恐怖。
那么接下来这个技巧点是 使用map 去优化 :
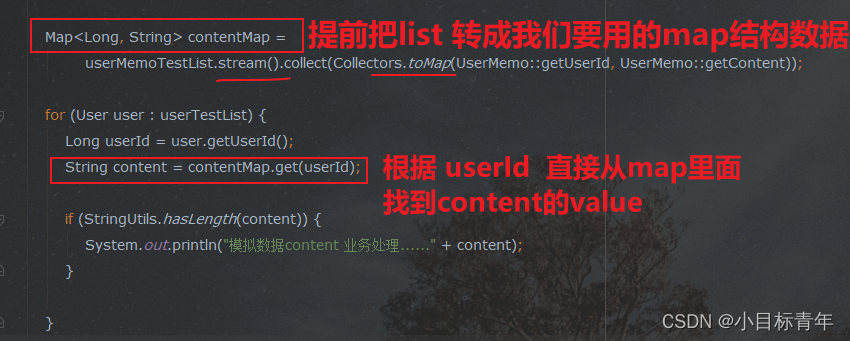
代码:
public static void main(String[] args) {
List<User> userTestList = getUserTestList();
List<UserMemo> userMemoTestList = getUserMemoTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
//使用stream() 记得一定要判空 这里没列出来,大家自己注意
Map<Long, String> contentMap =
userMemoTestList.stream().collect(Collectors.toMap(UserMemo::getUserId, UserMemo::getContent));
for (User user : userTestList) {
Long userId = user.getUserId();
String content = contentMap.get(userId);
if (StringUtils.hasLength(content)) {
System.out.println("模拟数据content 业务处理......" + content);
}
}
stopWatch.stop();
System.out.println("最终耗时" + stopWatch.getTotalTimeMillis());
}看看耗时:
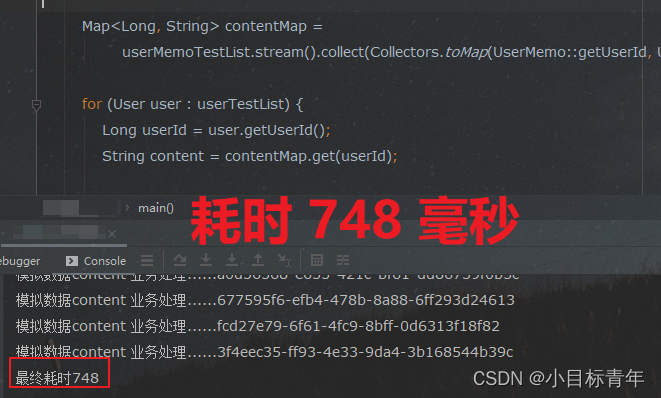
为什么 这么显著的效果 ?
这其实就是时间复杂度,
for循环嵌套for循环,
就好比 循环每一个 user ,拿出 userId
需要在里面的循环从 userMemo list集合里面 按顺序去开盲盒匹配,
拿出第一个,看看userId ,拿出第二个,看看userId ,一直找匹配的。
而我们提前对 userMemo list集合 做一次 遍历,转存储在map里面 。
map的取值效率 在多数的情况下是能维持接近 O(1) 的 , 毕竟数据结构摆着,数组加链表。
相当于拿到userId 想去开盲盒的时候, 根据userId 这个key hash完能直接找到数组里面的索引标记位, 如果底下没链表(有的话O(logN)),直接取出来就完事了。
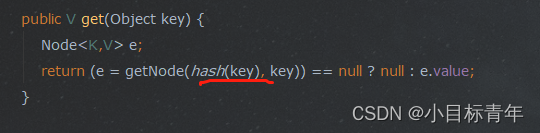
然后补充一个getNode的代码注释 :
/**
* Implements Map.get and related methods.
* 这是个 Map.get 的实现 方法
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
// final 写死了 无法更改 返回 Node 传入查找的 hash 值 和 key键
final Node<K,V> getNode(int hash, Object key) {
// tab 还是 哈希表
// first 哈希表找的链表红黑树对应的 头结点
// e 代表当前节点
// k 代表当前的 key
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 赋值 并过滤 哈希表 空的长度不够的 对应位置没存数据的 都直接 return null
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 头结点就 找到了 hash相等值相等 或者 不空的 key 和当前节点 equals
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 头结点不匹配 没找到就 就用 next 找
if ((e = first.next) != null) {
// 是不是红黑树 的
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 红黑树就直接 调用 红黑树内查找
// 不为空或者没找到就do while 循环
do {
// 当前节点 找到了 hash相等值相等 或者 不空的 key 和当前节点 equals
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
=
按照目前以JDK8 的hash算法,起hash冲突的情况是非常非常少见了。
最恶劣的情况,只有当 全部key 都冲突, 全都分配到一个桶里面去都占用一个位置 ,这时候就是O(n),这种情景不需要去考虑。
好了,该篇就到这。
当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我得到了一个包含嵌套链接的表单。编辑时链接字段为空的问题。这是我的表格:Editingkategori{:action=>'update',:id=>@konkurrancer.id})do|f|%>'Trackingurl',:style=>'width:500;'%>'Editkonkurrence'%>|我的konkurrencer模型:has_one:link我的链接模型:classLink我的konkurrancer编辑操作:defedit@konkurrancer=Konkurrancer.find(params[:id])@konkurrancer.link_attrib
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
这道题是thisquestion的逆题.给定一个散列,每个键都有一个数组,例如{[:a,:b,:c]=>1,[:a,:b,:d]=>2,[:a,:e]=>3,[:f]=>4,}将其转换为嵌套哈希的最佳方法是什么{:a=>{:b=>{:c=>1,:d=>2},:e=>3,},:f=>4,} 最佳答案 这是一个迭代的解决方案,递归的解决方案留给读者作为练习:defconvert(h={})ret={}h.eachdo|k,v|node=retk[0..-2].each{|x|node[x]||={};node=node[x]}node[
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121