经过前面四天的学习,对Node.js已经有了一个基础的认识,今天继续学习Node.js网络通信编程相关内容,并稍加整理加以分享,如有不足之处,还请指正。
Node.js中,提供了一个path模块,在这个模块中,提供了许多实用的,可被用来处理与转换文件路径的方法及属性。path是一个系统模块,不需要单独安装,主要用于格式化或拼接完整路径。
以path模块中最常用的是join方法【拼接路径】为例,如下所示:
1 var path = require('path');
2 //拼接路径:将多个字符串拼接成一个完整的路径
3 var file = path.join(__dirname,'file1.txt');
4 console.log("当前路径:"+file);示例截图,如下所示:
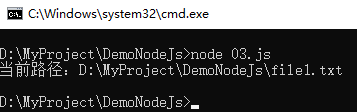
注意:__dirname是内置属性,表示当前程序所在的路径。
path模块除了join外,还提供了其他方法,如下所示:
1 var path = require('path');
2 //拼接路径:将多个字符串拼接成一个完整的路径
3 var file = path.join(__dirname,'file1.txt');
4 console.log("当前路径:"+file);
5 //返回路径中的文件夹部分
6 var dirname = path.dirname(file);
7 //返回路径中的文件部分,包含文件名和扩展名
8 var filename = path.basename(file);
9 //返回路径中的扩展名
10 var extname = path.extname(file);
11 //解析路径对象,返回一个对象
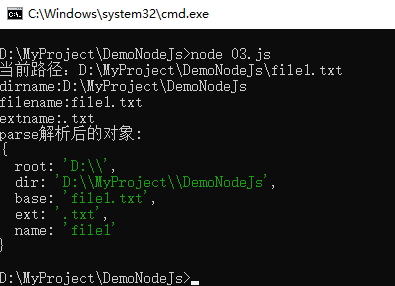
12 var p = path.parse(file);
13 console.log("dirname:"+dirname);
14 console.log("filename:"+filename);
15 console.log("extname:"+extname);
16 console.log("parse解析后的对象:");
17 console.log(p)示例截图,如下所示:
URL模块主要提供对URL(Uniform Resource Locator,统一资源定位器)的相关操作的属性和方法。
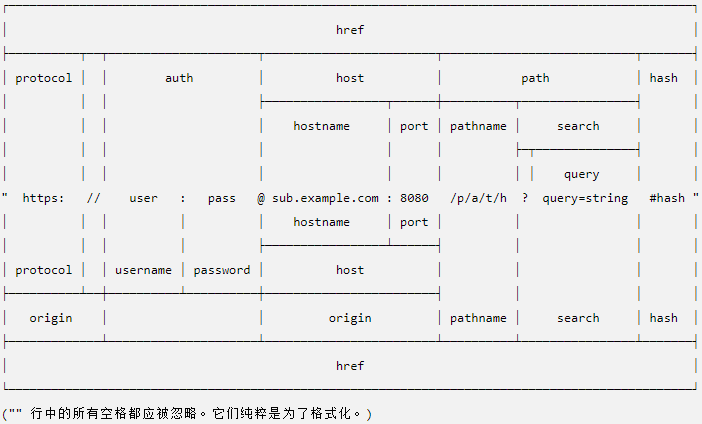
网址字符串是包含多个有意义组件的结构化字符串。 解析时,将返回包含每个组件的属性的网址对象。
url 模块提供了两种用于处理网址的 API:一种是 Node.js 特定的旧版 API,一种是实现了与 Web 浏览器使用的相同的 WHATWG 网址标准的新版 API。
下面提供了 WHATWG 和 旧版 API 之间的比较。
使用 WHATWG API 解析网址字符串:
1 const myURL =
2 new URL('https://user:pass@sub.example.com:8080/p/a/t/h?query=string#hash');使用旧版 API 解析网址字符串:
1 import url from 'url';
2 const myURL = url.parse('https://user:pass@sub.example.com:8080/p/a/t/h?query=string#hash');旧的解析方法,直接采用模块的parse函数即可,如下所示:
1 var url = require('url');
2 var u="https://www.cnblogs.com/hsiang/p/15182972.html";
3 //旧的解析方法
4 var obj = url.parse(u);
5 console.log("解析后的对象:");
6 console.log(obj);解析示例截图,如下所示:
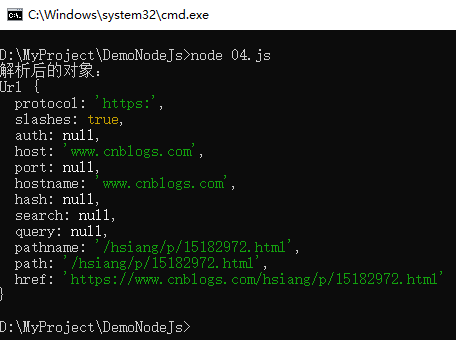
注意:返回的obj是一个对象,通过obj.属性名,可以获取更加详细的内容。
1 //新的解析方法【ES6写法】
2 const {URL} = require('url');
3 var u="https://www.cnblogs.com/hsiang/p/15182972.html";
4 const obj=new URL(u);
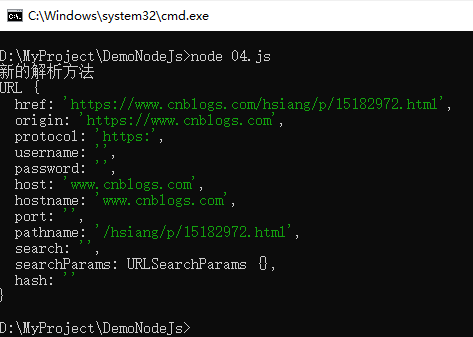
5 console.log("新的解析方法");
6 console.log(obj);示例截图,如下所示:
ES5写法,如下所示:
1 //新的解析方法【ES5写法】
2 var url = require('url');
3 var u="https://www.cnblogs.com/hsiang/p/15182972.html";
4 var obj =new url.URL(u);
5 console.log("新的解析方法");
6 console.log(obj);注意:通过对比,发现新旧两种方式解析出来的结果大体上相同,仅存细微差异,具体可参考上述新旧对比截图。
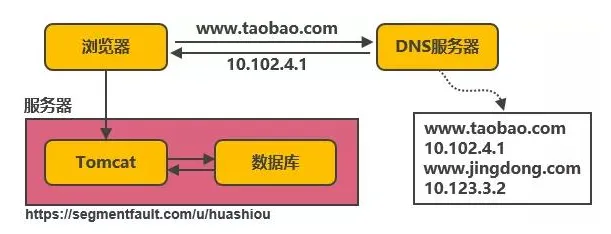
网络作为信息传输,接收,共享的虚拟平台,通过它将各个点,面,体的信息联系到一起,从而实现这些资源的共享。网络传输数据有一定的规则,这些规则称之为协议,http协议就是规则的一种,而且是使用最频繁的一种网络传输协议。
超文本传输协议(Hyper Text Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII形式给出;而消息内容则具有一个类似MIME的格式。HTTP协议定义了数据在浏览器和服务器之间网络传输的数据格式和过程。
HTTTP协议定义了浏览器和服务器之间交互数据的格式及过程。具体如下所示:
以浏览一次网页为例,请求响应过程如下所示:
因为网络中的请求,大部分都是get方式,且不带请求体,所以Node.js的http模块提供了便捷方法。如下所示:
1 var http=require('http');
2 var fs = require('fs');
3
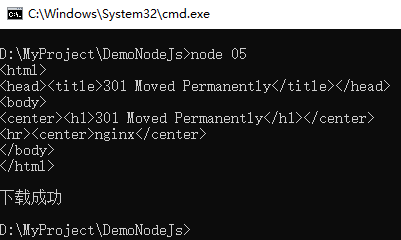
4 http.get('http://www.itsource.cn',function(res){
5 //res是一个IncomingMessage对象
6 //console.log(res);
7 var stream = fs.createWriteStream('./a.html');
8 //res是流对象,可以监听data事件
9
10 res.on('data',function(data){
11 console.log(data.toString());
12 stream.write(data);
13 });
14 res.on('end',function(){
15 stream.end();
16 console.log('下载成功');
17 });
18 //或者采用管道
19 //res.pipe(stream);
20 });上述示例采用get方法获取文件内容,并保存文件内容到文件中。示例结果如下:
谒金门·风乍起【作者】冯延巳
风乍起,吹皱一池春水。
闲引鸳鸯香径里,手挼红杏蕊。
斗鸭阑干独倚,碧玉搔头斜坠。
终日望君君不至,举头闻鹊喜。
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我开始了一个新的Rails3.2.5项目,Assets管道不再工作了。CSS和Javascript文件不再编译。这是尝试生成Assets时日志的输出:StartedGET"/assets/application.css?body=1"for127.0.0.1at2012-06-1623:59:11-0700Servedasset/application.css-200OK(0ms)[2012-06-1623:59:11]ERRORNoMethodError:undefinedmethod`each'fornil:NilClass/Users/greg/.rbenv/versions/1
rails新手。只是想了解\assests目录中的这两个文件。例如,application.js文件有如下行://=requirejquery//=requirejquery_ujs//=require_tree.我理解require_tree。只是将所有JS文件添加到当前目录中。根据上下文,我可以看出requirejquery添加了jQuery库。但是它从哪里得到这些jQuery库呢?我没有在我的Assets文件夹中看到任何jquery.js文件——或者直接在我的整个应用程序中没有看到任何jquery.js文件?同样,我正在按照一些说明安装TwitterBootstrap(http:
我有一个包含多个组件的存储库,其中大部分是用JavaScript(Node.js)编写的,一个是用Ruby(RubyonRails)编写的。我想要一个.travis.yml文件来触发一个运行每个组件的所有测试的构建。根据thisTravisCIGoogleGroupthread,目前还没有官方支持。我的目录结构是这样的:.├──构建服务器├──核心├──扩展├──网络应用├──流浪文件├──package.json├──.travis.yml└──生成文件我希望能够运行特定版本的Ruby(2.2.2)和Node.js(0.12.2)。我已经有了一个make目标,所以maketest在每
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据