文章目录
Doris 最早是解决百度凤巢统计报表的专用系统,随着百度业务的飞速发展对系统进行了多次迭代,逐渐承担起百度内部业务的统计报表和多维分析需求。2013 年,我们把 Doris 进行了 MPP 框架的升级,并将新系统命名为 Palo ,2017 年我们以百度 Palo 的名字在 GitHub 上进行了开源,2018 年贡献给 Apache 基金会时,由于与国外数据库厂商重名,因此选择用回最初的名字,这就是 Apache Doris 的由来。【总结】Doris属于百度的,Apache Doris是有百度贡献给Apache 的,DorisDB是百度前员工基于Apache Doris做的商业版本属于另外的公司,后面因为版权的问题,将DorisDB改名为StarRocks,所以StarRocks和DorisDB是属于一个产品,一个公司的。不知道小伙伴,还记不记得另外一个产品的经历跟Doris的经历非常的相似,那就是presto。这里主要讲StarRocks,因为StarRocks更新迭代很快,活跃度也高。
Apache Doris GitHub地址:https://github.com/apache/doris
Apache Doris 官网文档:https://doris.apache.org/docs/get-starting/get-starting.html
StarRocks GitHub地址:https://github.com/StarRocks/starrocks
StarRocks官方文档:https://docs.starrocks.com/zh-cn/main/introduction/StarRocks_intro
StarRocks是一款高性能分析型数据仓库,使用向量化、MPP(Massively Parallel Processing:大规模并行处理) 架构、可实时更新的列式存储引擎等技术实现多维、实时、高并发的数据分析。StarRocks 既支持从各类实时和离线的数据源高效导入数据,也支持直接分析数据湖上各种格式的数据。StarRocks 兼容 MySQL 协议,可使用 MySQL 客户端和常用 BI 工具对接。同时 StarRocks 具备水平扩展,高可用,高可靠,易运维等特性。广泛应用于实时数仓、OLAP 报表、数据湖分析等场景。
Delete-and-insert 的实现方式,通过主键索引快速过滤,消除了读取时 Sort merge 操作,同时还可以充分利用其他二级索引。可以在大量更新的场景下,仍然可以保证查询的极速性能。StarRocks 可以满足企业级用户的多种分析需求,包括 OLAP 多维分析、定制报表、实时数据分析和 Ad-hoc 数据分析等。
利用 StarRocks 的 MPP 框架和向量化执行引擎,用户可以灵活的选择雪花模型,星型模型,宽表模型或者预聚合模型。适用于灵活配置的多维分析报表,业务场景包括:
用户行为分析
用户画像、标签分析、圈人
高维业务指标报表
自助式报表平台
业务问题探查分析
跨主题业务分析
财务报表
系统监控分析
StarRocks 设计和实现了 Primary-Key 模型,能够实时更新数据并极速查询,可以秒级同步 TP 数据库的变化,构建实时数仓,业务场景包括:
电商大促数据分析
物流行业的运单分析
金融行业绩效分析、指标计算
直播质量分析
广告投放分析
管理驾驶舱
探针分析APM(Application Performance Management)
StarRocks 通过良好的数据分布特性,灵活的索引索引以及物化视图等特性,可以解决面向用户侧的分析场景,业务场景包括:
广告主报表分析
零售行业渠道人员分析
SaaS 行业面向用户分析报表
Dashboard 多页面分析
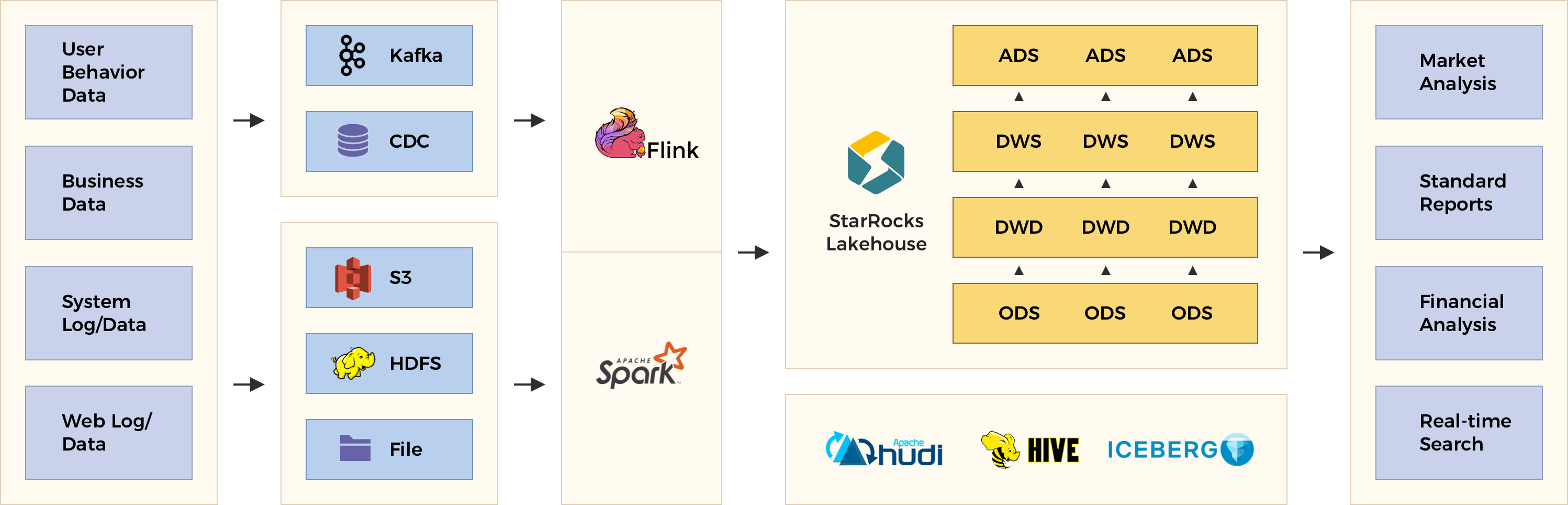
通过使用一套系统解决多维分析、高并发查询、预计算、实时分析查询等场景,降低系统复杂度和多技术栈开发与维护成本。
使用StarRocks 来统一数据湖和数据仓库,将高并发和实时要求性很高的业务放在StarRocks中分析,把数据湖上的分析使用StarRocks外表查询,统一使用 StarRocks 管理湖仓数据。
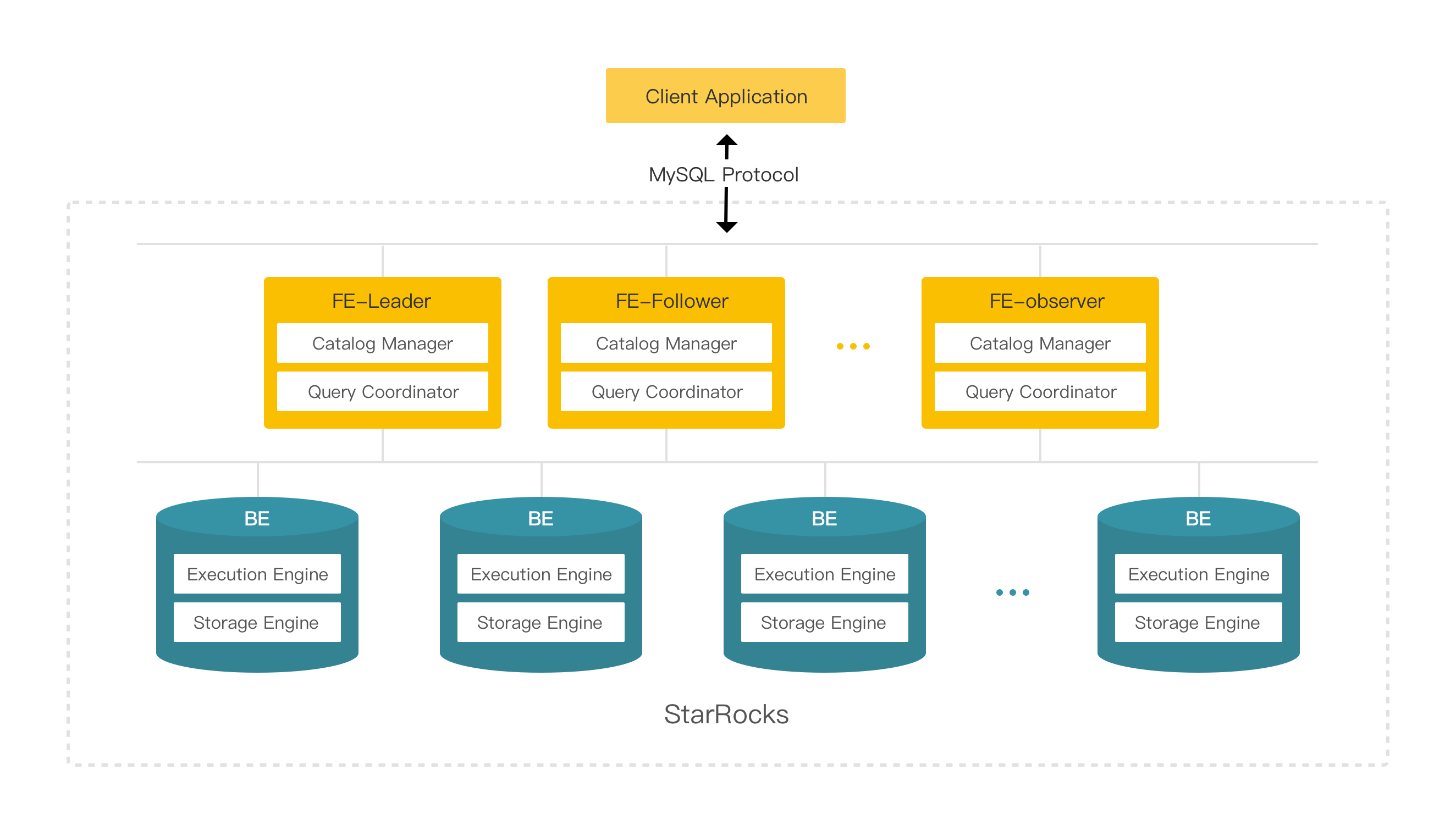
StarRocks的架构简洁,整个系统的核心只有FE(Frontend)和 BE(Backend)两类进程,不依赖任何外部组件,方便部署与维护。同时,FE和BE模块都可以在线水平扩展,元数据和数据都有副本机制,确保整个系统无单点。
Frontend是StarRocks的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。FE根据配置会有两种角色:
Follower和Observer。
Backend是StarRocks的后端节点,负责数据存储以及SQL执行等工作。
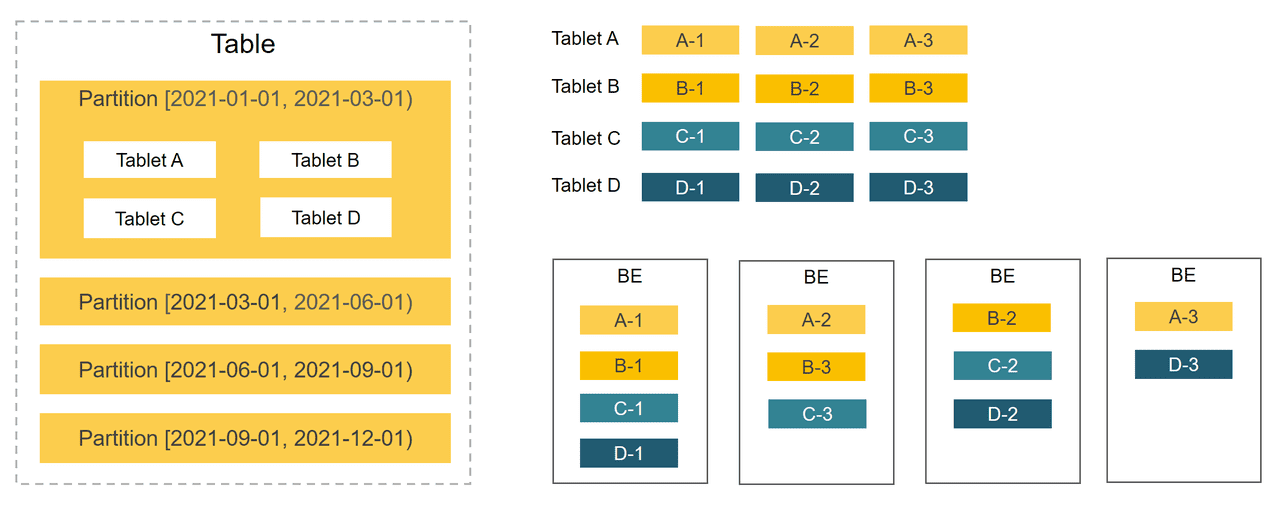
Table数据划分 + Tablet三副本的数据分布如下图:
StarRocks的集群部署分为两种模式:
StarRocksManager 自动化部署。自动部署的版本只需要在页面上简单进行配置、选择、输入后批量完成,并且包含Supervisor进程管理、滚动升级、备份、回滚等功能。因 StarRocksManager并未开源,因此我们只能使用命令部署。StarRocks 支持以 Docker 镜像和二进制安装包形式手动部署于集群中。这里讲二进制安装,后面也会讲k8s安装,请耐心等待~
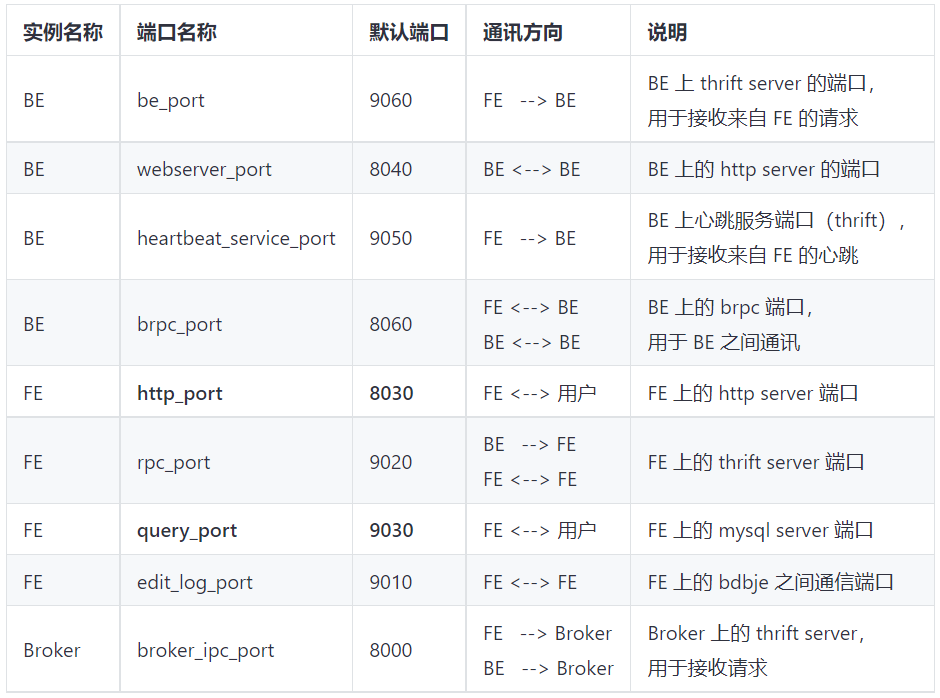
端口列表
| IP | 角色 |
|---|---|
| 192.168.0.113/192.168.0.120 | FE、Broker |
| 192.168.0.114 | BE、Broker |
| 192.168.0.115 | BE 、Broker |
| 192.168.0.116 | FE、Broker |
【温馨提示】节点数最好是基数,但是我这里资源不太够,所以就2+2了。这里的192.168.0.120是VPI。其实这里不需要用到VIP。但是启动FE时,可能会使用VIP192.168.0.120。
# 临时关闭;关闭swap主要是为了性能考虑
# 0值会命令内核不要使用swap,只有当free和文件使用的内存页数量少于一个zone的高水位,才会使用swap。
echo 0 | sudo tee /proc/sys/vm/swappiness
swapoff -a
# 永久关闭,调整 swappiness 参数
sed -ri 's/.*swap.*/#&/' /etc/fstab
vi /etc/sysctl.conf
# 修改 vm.swappiness 的修改为 0
vm.swappiness=0
# 使配置生效
sysctl -p
echo 1 | sudo tee /proc/sys/vm/overcommit_memory
官网下载:https://www.oracle.com/java/technologies/downloads/
百度云下载
链接:https://pan.baidu.com/s/1-rgW-Z-syv24vU15bmMg1w
提取码:8888
cd /opt/software/
tar -xf jdk-8u212-linux-x64.tar.gz
# 在文件加入环境变量/etc/profile
export JAVA_HOME=/opt/software/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# source加载
source /etc/profile
# 查看jdk版本
java -version
FE 是StarRocks的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。就是管理节点。
cd /opt/software
wget https://download.starrocks.com/zh-CN/download/request-download/35/StarRocks-2.2.2.tar.gz
# 解压
tar -xzvf StarRocks-2.2.2.tar.gz
# 设置环境变量/etc/profile
export STARROCKS_HOME=/opt/software/StarRocks-2.2.2
source /etc/profile
# 创建元数据目录
mkdir $STARROCKS_HOME/fe/meta
注意:当一台机器拥有多个 IP 地址时,需要在 FE 配置文件 conf/fe.conf 中设置 priority_networks,为该节点设定唯一 IP。
在${STARROCKS_HOME}/fe/conf/fe.conf文件中配置如下内容:
# 修改元数据目录。
meta_dir = /opt/software/StarRocks-2.2.2/meta
# 修改配置,网段,自动发现IP
priority_networks = 192.168.0.0/24
# 添加 Java 目录
JAVA_HOME = /opt/software/jdk1.8.0_212
# 修改JVM内存,默认是8G,根据自己机器自定义,默认是-Xmx8192m,这里我修改成Xmx512m,这里有两段配置,jdk 9+使用JAVA_OPTS_FOR_JDK_9
JAVA_OPTS="-Dlog4j2.formatMsgNoLookups=true -Xmx512m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:$STARROCKS_HOME/log/fe.gc.log.$DATE"
# For jdk 9+, this JAVA_OPTS will be used as default JVM options
JAVA_OPTS_FOR_JDK_9="-Dlog4j2.formatMsgNoLookups=true -Xmx512m -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xlog:gc*:$STARROCKS_HOME/log/fe.gc.log.$DATE:time"
如需在生产环境中对集群进行详细优化配置,参考 FE 参数配置。
${STARROCKS_HOME}/fe/bin/start_fe.sh --daemon
【温馨提示】如果由于端口被占用导致 FE 启动失败,可修改配置文件
fe/conf/fe.conf中的端口号http_port。
通过查看日志 fe/log/fe.log 确认 FE 是否启动成功。
tail -f ${STARROCKS_HOME}/fe/log/fe.log
通过运行 jps 命令查看 Java 进程,确认 StarRocksFe 进程是否存在。
jps
通过mysql客户端查看节点信息
yum -y install mysql
# 用户名为 root,密码为空
mysql -h 192.168.0.113 -P9030 -uroot
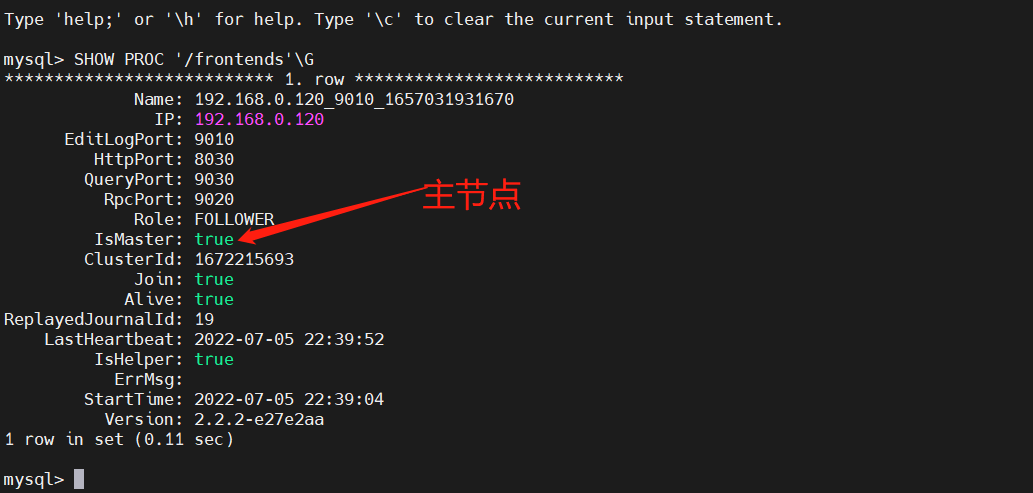
# 查看 FE 状态。
SHOW PROC '/frontends'\G
通过在浏览器访问 FE ip:http_port(默认 http_port 为 8030),进入 StarRocks 的 WebUI,用户名为 root,密码为空。
【温馨提示】FE节点之间的时钟相差不能超过5s, 使用NTP协议校准时间。一台机器上只可以部署单个FE节点。所有FE节点的http_port需要相同。
scp -r jdk1.8.0_212 StarRocks-2.2.2 k8s-master2-168-0-116:/opt/software/
# 设置环境变量
# 在文件加入环境变量/etc/profile
export JAVA_HOME=/opt/software/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export STARROCKS_HOME=/opt/software/StarRocks-2.2.2
# source加载
source /etc/profile
使用MySQL客户端连接已有的FE, 添加新实例的信息,信息包括角色、ip、port:
# 添加FOLLOWER 类型节点
# mysql> ALTER SYSTEM ADD FOLLOWER "host:port";
# 或者添加OBSERVER 类型节点,不参与选举
# mysql> ALTER SYSTEM ADD OBSERVER "host:port";
mysql -h 192.168.0.113 -P9030 -uroot
ALTER SYSTEM ADD FOLLOWER "192.168.0.116:9010";
host为机器的IP,如果机器存在多个IP,需要选取priority_networks里的IP,例如priority_networks=192.168.1.0/24 可以设置使用192.168.1.x 这个子网进行通信。port为edit_log_port,默认为9010。
如出现错误,需要删除FE,应用下列命令:
#alter system drop follower "fe_host:edit_log_port";
#alter system drop observer "fe_host:edit_log_port";
alter system drop follower "192.168.0.116:9010";
alter system drop observer "192.168.0.116:9010";
FE节点之间需要两两互联才能完成复制协议选主, 投票,日志提交和复制等功能。 添加到已有集群的新FE节点首次启动时,需要指定现有集群中的一个节点作为helper节点, 从该节点获得集群的所有FE节点的配置信息,才能建立通信连接,因此首次启动需要指定–helper参数:
cd $STARROCKS_HOME/fe
# ./bin/start_fe.sh --helper host:port --daemon
./bin/start_fe.sh --helper 192.168.0.120:9010 --daemon
host为helper节点的IP,如果有多个IP,需要选取priority_networks里的IP。port为edit_log_port,默认为9010。
当FE再次启动时,无须指定–helper参数,因为FE已经将其他FE的配置信息存储于本地目录, 因此可直接启动:
./bin/start_fe.sh --daemon
【温馨提示】如果启动失败了,删除元数据目录下的文件重新启动。
cd $STARROCKS_HOME/fe
./bin/stop_fe.sh --daemon
rm -fr meta/*
# 重新启动
./bin/start_fe.sh --helper 192.168.0.120:9010 --daemon
mysql -h 192.168.0.113 -P9030 -uroot
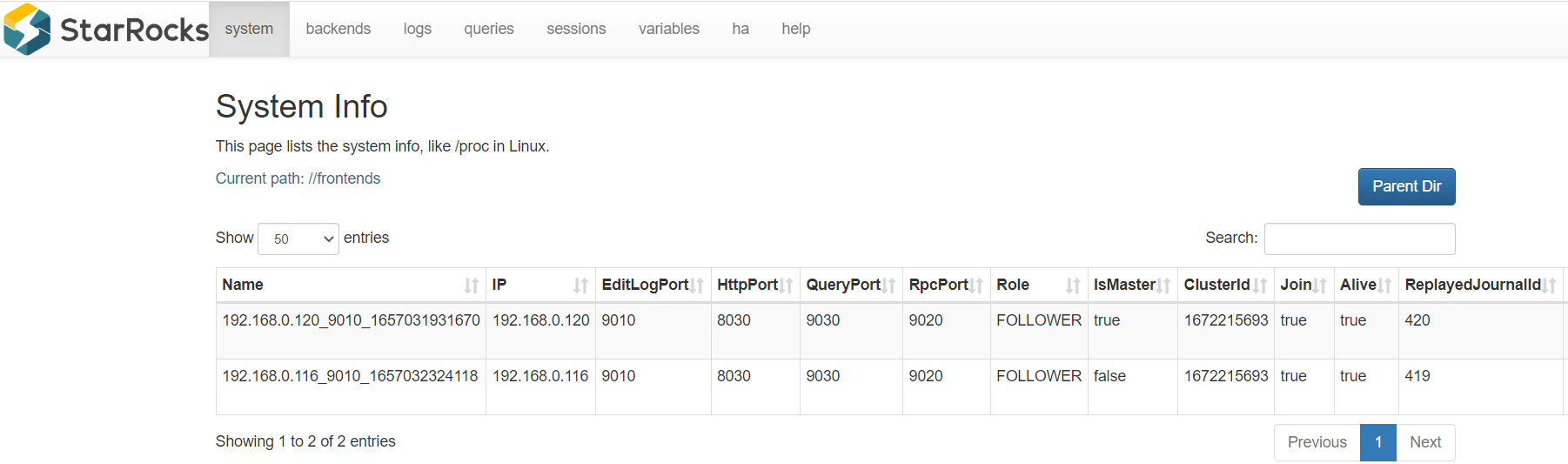
SHOW PROC '/frontends'\G
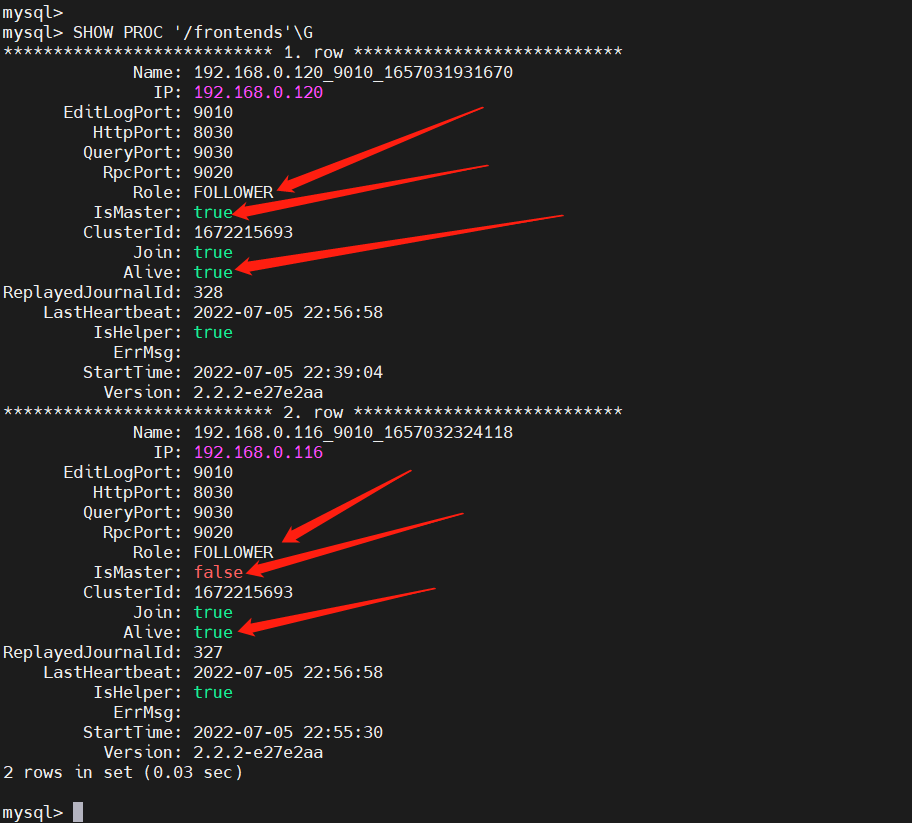
主要关注上面标注的三个指标,IsMaster:代表是否时主节点,Role:代表角色,节点类型,Alive:代表节点正常
web UI:http://192.168.0.113:8030/system
./bin/stop_fe.sh --daemon
# 在 k8s-master2-168-0-113节点上执行copy操作
cd /opt/software
scp -r jdk1.8.0_212 StarRocks-2.2.2 k8s-master2-168-0-114:/opt/software/
# 设置环境变量
# 在文件加入环境变量/etc/profile
export JAVA_HOME=/opt/software/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export STARROCKS_HOME=/opt/software/StarRocks-2.2.2
# source加载
source /etc/profile
mkdir -p $STARROCKS_HOME/be/storage
vi $STARROCKS_HOME/be/conf/be.conf
priority_networks = 192.168.0.0/24
storage_root_path = /opt/software/StarRocks-2.2.2/be/storage
通过 MySQL 客户端将 BE 节点添加至 StarRocks 集群。
yum -y install mysql
mysql -h 192.168.0.113 -P9030 -uroot
# ALTER SYSTEM ADD BACKEND "host:port";
ALTER SYSTEM ADD BACKEND "192.168.0.114:9050";
【温馨提示】host 需要与 priority_networks 相匹配,本机IP,port 需要与 be.conf 文件中的设置的 heartbeat_service_port 相同,默认为 9050。
如添加过程出现错误,需要通过以下命令将该 BE 节点从集群移除。
# ALTER SYSTEM decommission BACKEND "host:port";
ALTER SYSTEM decommission BACKEND "192.168.0.114:9050";
cd $STARROCKS_HOME/be
bin/start_be.sh --daemon
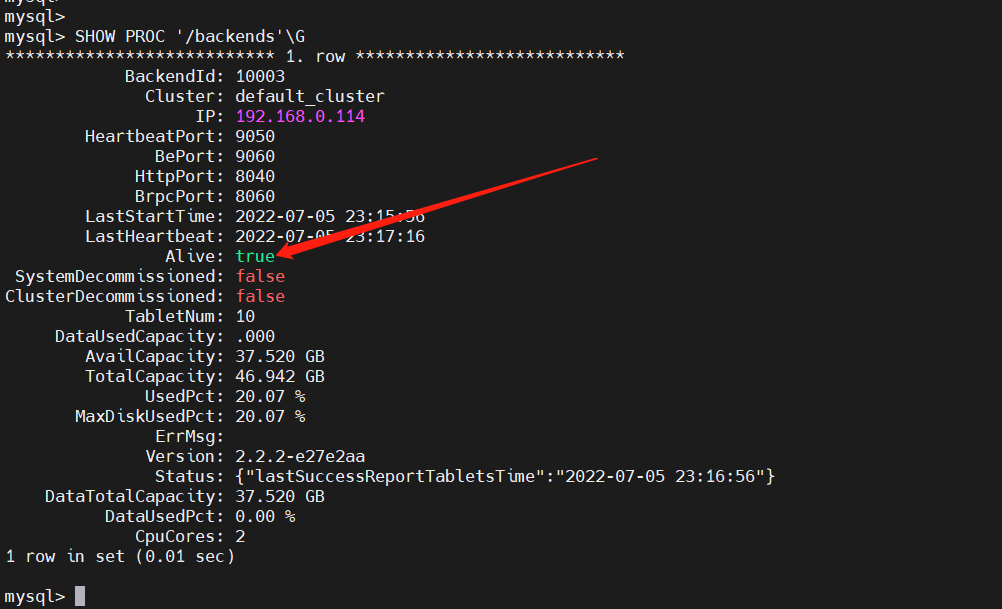
mysql -h 192.168.0.113 -P9030 -uroot
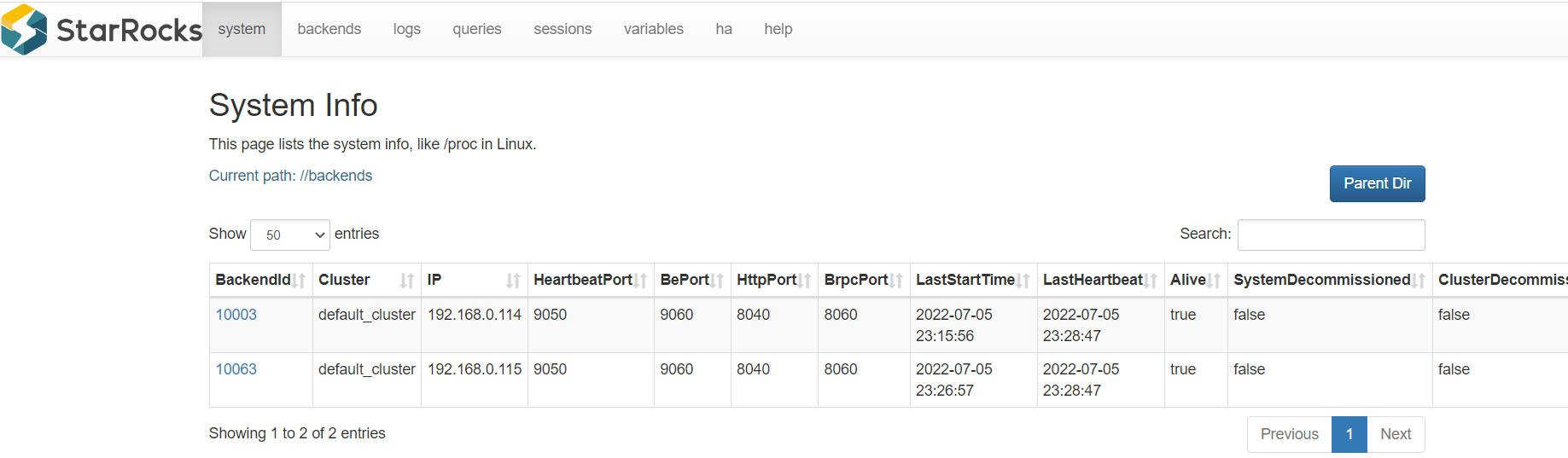
SHOW PROC '/backends'\G
添加另外一个BE节点,部署跟上面一样
#【第一步】 从已的be节点copy一份
cd /opt/software
scp -r jdk1.8.0_212 StarRocks-2.2.2 k8s-node2-168-0-115:/opt/software/
# 【第一步】设置环境变量
# 在文件加入环境变量/etc/profile
export JAVA_HOME=/opt/software/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export STARROCKS_HOME=/opt/software/StarRocks-2.2.2
# source加载
source /etc/profile
#【第三步】清空数据路径下的文件
rm -fr $STARROCKS_HOME/be/storage/*
# 【第四步】添加 BE 节点
yum -y install mysql
mysql -h 192.168.0.113 -P9030 -uroot
ALTER SYSTEM ADD BACKEND "192.168.0.115:9050";
# 【第五步】启动 BE 节点
cd $STARROCKS_HOME/be && bin/start_be.sh --daemon
#【第六步】查看EB节点状态
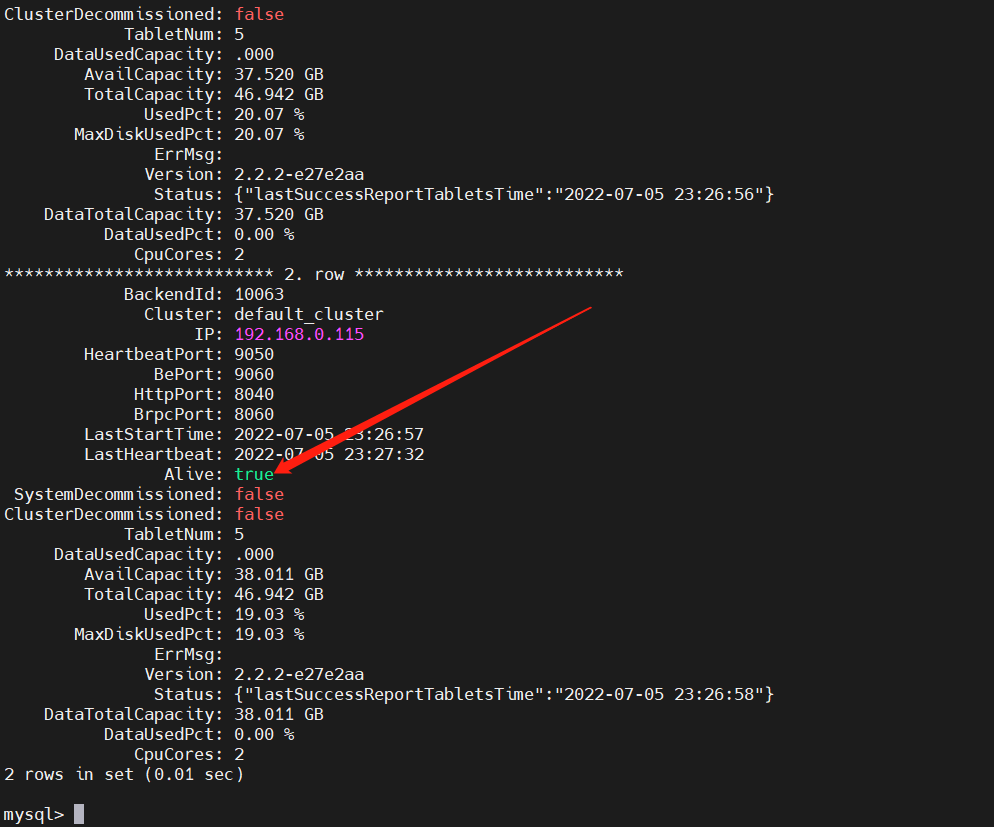
mysql -h 192.168.0.113 -P9030 -uroot
SHOW PROC '/backends'\G
通过部署的 Broker,StarRocks 可读取对应数据源(如HDFS、S3)上的数据,利用自身的计算资源对数据进行预处理和导入。除此之外,Broker 也被应用于数据导出,备份恢复等功能。
cd $STARROCKS_HOME/apache_hdfs_broker
修改 Broker 节点配置文件 conf/apache_hdfs_broker.conf。因默认配置即可启动集群,以下示例并未修改 Broker 点配置。您可以直接复制自己的 HDFS 集群配置文件并粘贴至
conf路径下。
您可通过 MySQL 客户端连接 StarRocks 以添加或删除 Broker 节点。
mysql -h 192.168.0.113 -P9030 -uroot
# ALTER SYSTEM ADD BROKER broker1 "172.16.xxx.xx:8000";
# 说明:默认配置中,Broker 节点的端口为 8000。
ALTER SYSTEM ADD BROKER broker1 "192.168.0.113:8000";
ALTER SYSTEM ADD BROKER broker1 "192.168.0.114:8000";
ALTER SYSTEM ADD BROKER broker1 "192.168.0.115:8000";
ALTER SYSTEM ADD BROKER broker1 "192.168.0.116:8000";
cd $STARROCKS_HOME/
./apache_hdfs_broker/bin/start_broker.sh --daemon
mysql -h 192.168.0.113 -P9030 -uroot
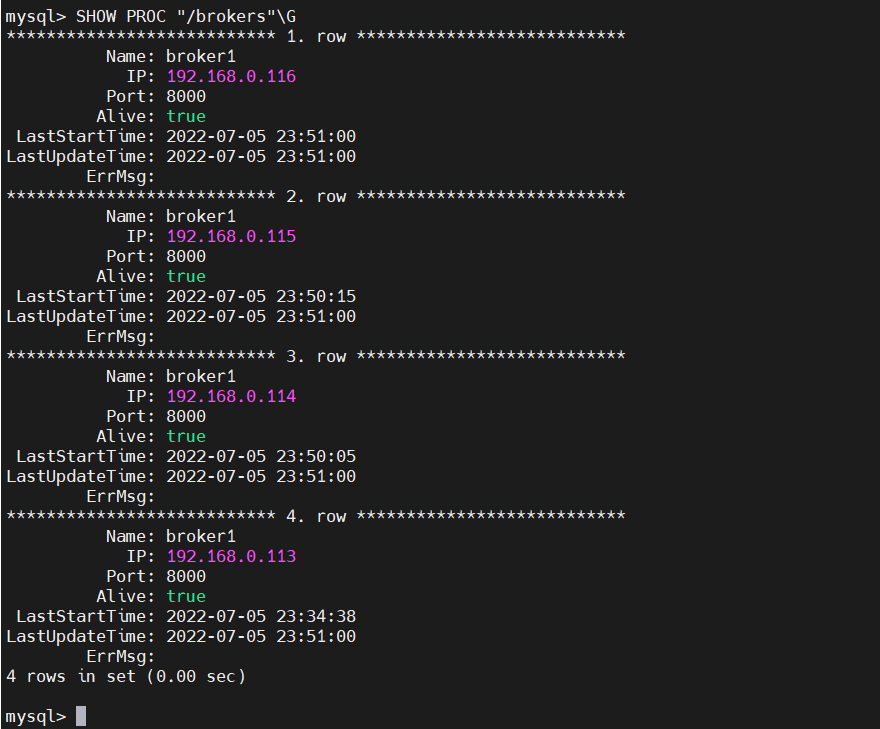
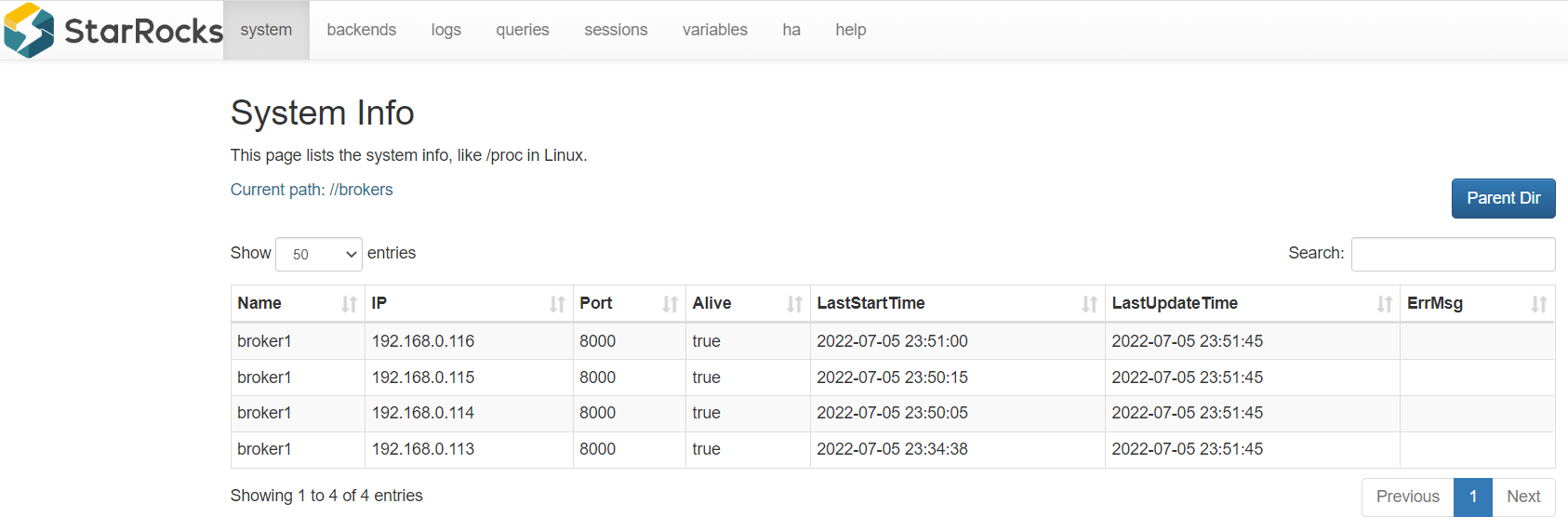
SHOW PROC "/brokers"\G
DorisDB介绍与环境部署就先到这里了,其实StarRocks部署还是非常简单的,后续会有更多关于StarRocks的文章,请小伙伴耐心等待哦~
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf