学习是一种基础性的能力。然而,“吾生也有涯,而知也无涯。”,如果学习不注意方法,则会“以有涯随无涯,殆矣”。
学习就像吃饭睡觉一样,是人的一种本能,人人都有学习的能力。我们在刚出生的时候,什么也不知道,是一张真正的白纸,我们靠学习的本能,学会了走路、说话、穿衣服…后来,我们上学了,老师把书本上的知识一点一点灌输到我们的脑子里,我们掌握的知识越来越多,与此同时,我们学习能力却好像越来越差了,习惯了被别人喂饱,似乎忘记了怎么来喂自己了。
学习本来只是一种本能,算不上什么能力,然而,经过二十多年的不断学习,学习反而成为了一种真正的能力,因为我们慢慢失去了它,它就更显得珍贵。
作为一个程序员,不断的学习更是重要,不学新的知识就迟早会被淘汰掉
ES(Elasticsearch下文统一称为ES)越来越多的企业在业务场景是使用ES存储自己的非结构化数据,例如电商业务实现商品站内搜索,数据指标分析,日志分析等,ES作为传统关系型数据库的补充,提供了关系型数据库不具备的一些能力。
而且,上手Elasticsearch 也很容易,花几分钟设置好开发环境,就能在成百上千台服务器上实现PB级的数据处理了。但要**深入理解并高效使用,就没那么简单了,**比如:
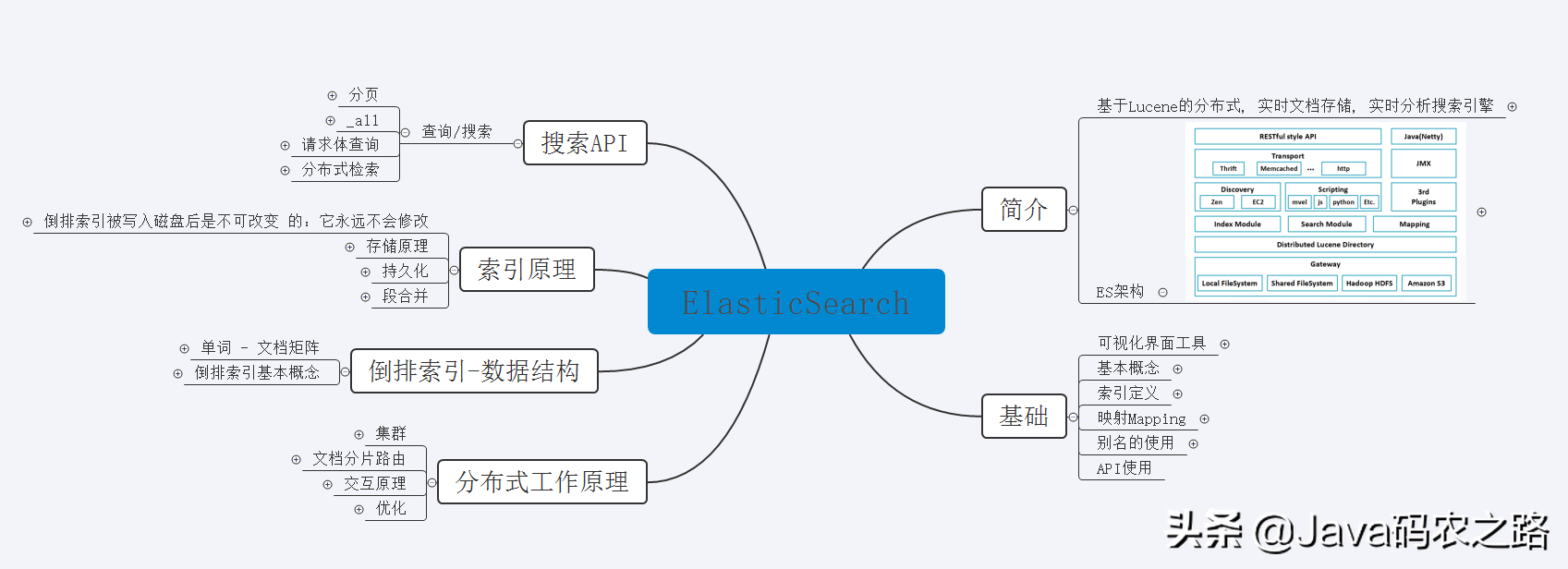
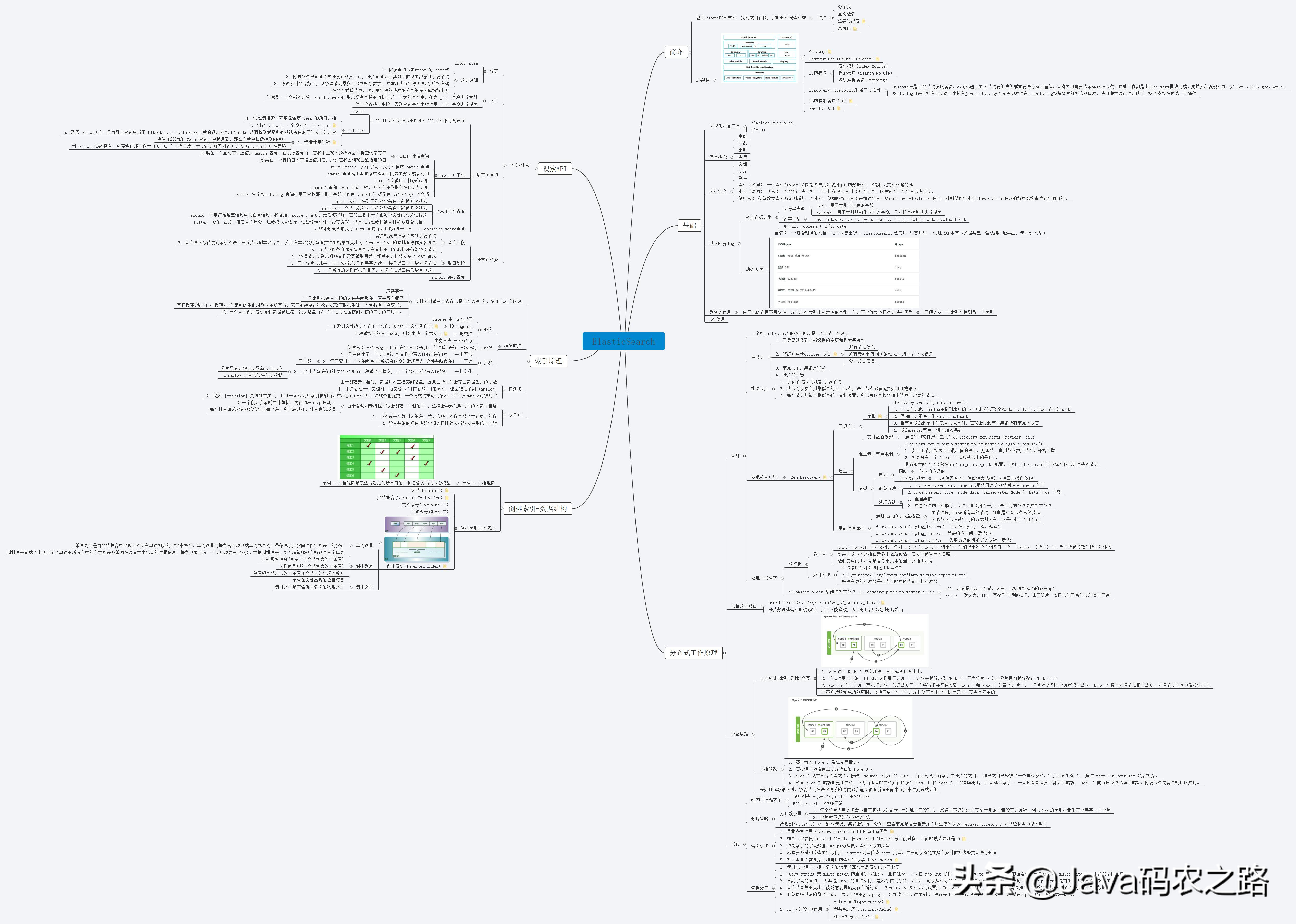
其实,想要掌握 Elasticsearch,不仅要理解其分布式架构的原理外,还要掌握一些信息检索领域的知识及相关技巧。这里,分享给你一份 **Elasticsearch 核心知识手册笔记,**只有深入理解每个知识点,才能解决工作中的实际问题。


Elasticsearch相关软件安装

es快速入门

文档document入门


Mapping映射入门

索引Index入门



聚合入门





作为目前最流行的开源搜索引擎,Elasticsearch 在同领域几乎没有竞争对手——近两年 DBRanking 的数据库评测中,ES 在搜索引擎领域始终位列第一,**腾讯、滴滴、今日头条、饿了么、360 安全、小米,vivo 等诸多知名公司都在使用。然而很多小伙伴在学习ES上却毫无头绪,如果你还在因想学习而没有好的学习笔记及思路的话,这份学习手册笔记及下面的思维学习路线笔记能够很好的帮助你!
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
我是Ruby分析的新手,看起来像ruby-prof是一个受欢迎的选择。我刚刚安装了gem并调用了我的程序:ruby-prof./my-prog.rb但是,输出非常冗长,因为包含所有Ruby核心和标准库方法以及其他gem的分析数据。例如,前三行是:8.790.0110.0100.0000.0013343*String#%7.280.0780.0090.0000.0692068*Array#each4.930.0380.0060.0000.0321098*Array#map这对我来说不是什么有用的信息,因为我已经知道我的程序经常处理字符串和数组,并且大概已经对这些类进行了优化。我只关心我代
假设我们有这样的东西:classCompanyincludeMongoid::Documenthas_many:usersfield:name,type:StringendclassUserincludeMongoid::Documentbelongs_to:companyfield:name,type:StringendmoduleCompanyRepresenterincludeRoar::Representer::JSONproperty:nameendmoduleUserRepresenterincludeRoar::Representer::JSONproperty:name
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建