文章目录
输入命令: select * from employess_table 查看员工表的所有信息
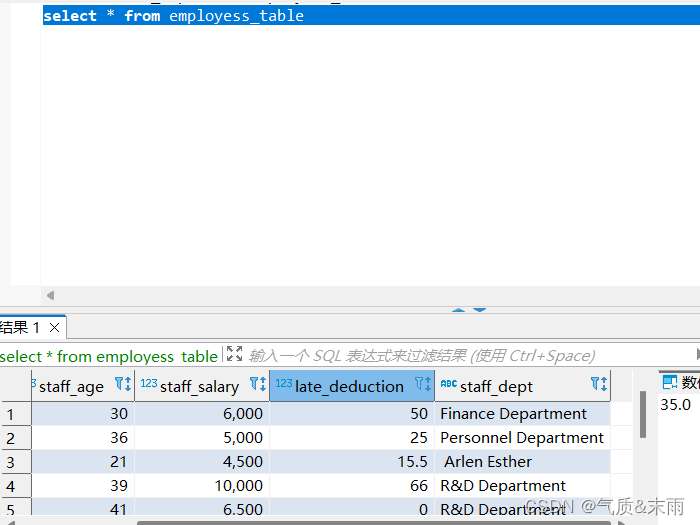
输入命令: select distinct staff_dept from employess 对员工信息表的部门字段进行查询,distinct 去重 查看出来了员工信息表有五个部门
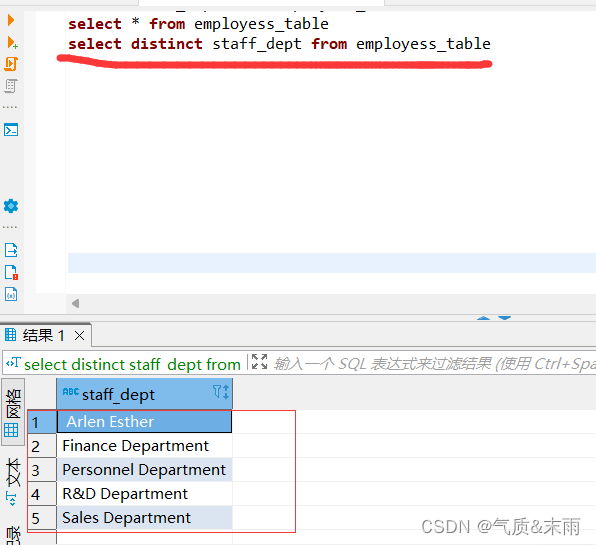
HAVING子句的用法与WHERE子句的用法一致,都是在查询语句中指定查询条件,不同的是HAVING子句中可以使用聚合函数,并且HAVING子句必须配合GROUP BY子句一同使用,而WHERE子句中不能使用聚合函数,例如查询每个部门平均薪资大于5000的部门,具体命令如下
输入命令
输入命令: select staff_dept from emplyess_table group by staff_table having AVG(staff_salary) > 5000 注意having 一定要 配聚合函数 group by 而where 不可以用聚合函数 gropy by 聚合的那个字段在前面的字段里面去找,要是只有一个那肯定就是
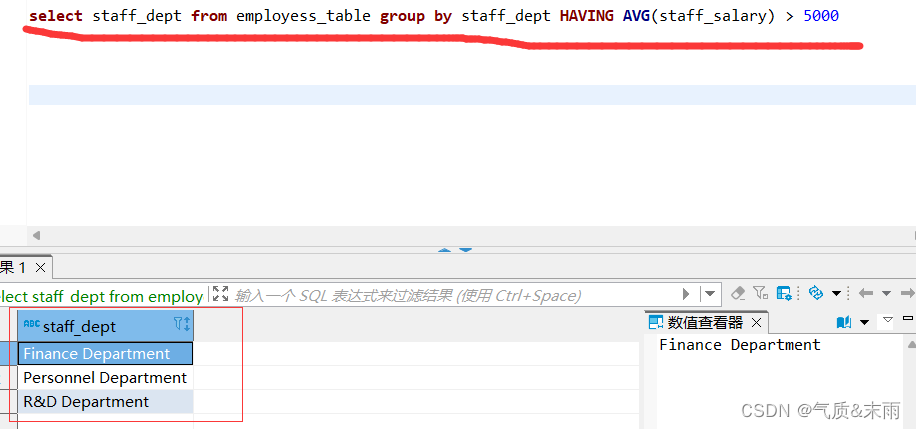
关系运算符通常在SELECT句式的WHERE子句中使用,用来比较两个操作数,下面通过一张表来介绍Hive内置的常用关系运算符。
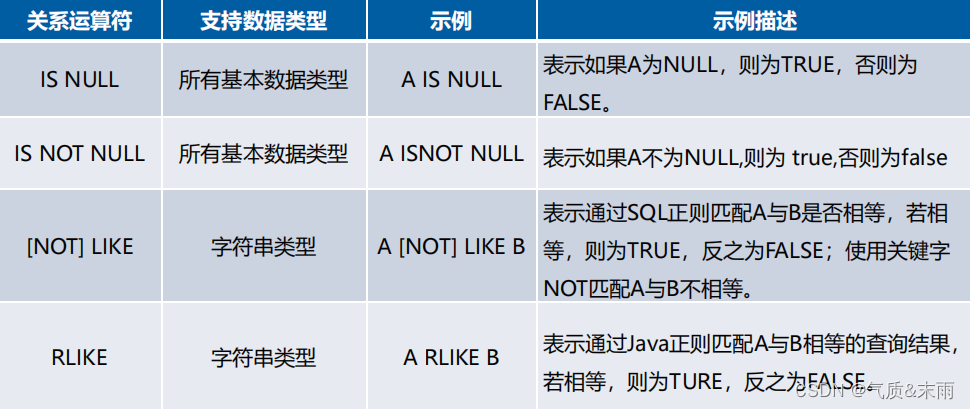

输入命令: select * from employess_table where staff_table = 36 查询出年龄为36岁的员工信息,有两条
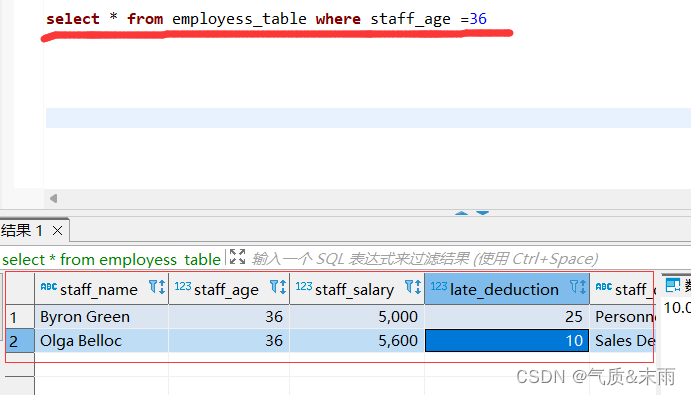
输入命令: select * from employess_table where staff_dept like “P%” %是通配符代表所有的,注意使用了模糊查询 like 就不能有=了,相当于是替代了
输入命令: select * from employess_table where staff_name like “D% || A%”
对这个表的所有员工姓名字段进行查询,发现根本没有A开头的名字,所以上面D||A会查询为空

算数运算符是用来计算两个数值的操作,下面通过一张表来介绍Hive内置的常用算数运算符
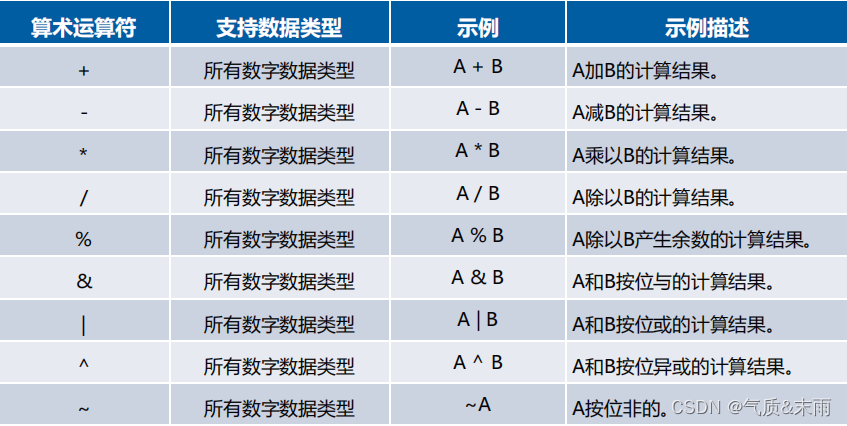
输入命令: select staff_name,staff_salary from employess_table 把员工的信息还有工资查询出来
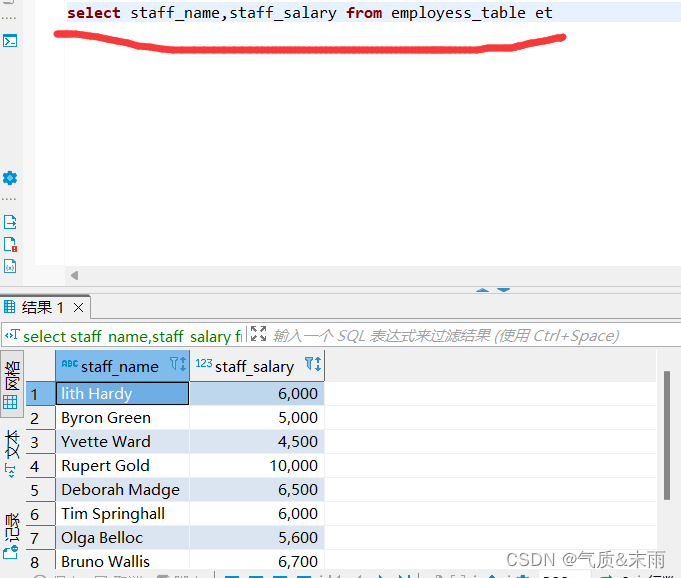
输入命令:select staff_name,staff_salary / 20 from employess_table 在前面工资字段直接除以20,直接就查询出来了每一天的工资,不用在后面用where
逻辑运算符可以将两个或者多个关系表达式合并为一个表达式或者反转表达式的逻辑。下面通过一张表来介绍Hive内置的常用逻辑运算符: and &&是与的意思,or || 是或的意思, ! not 是非的意思

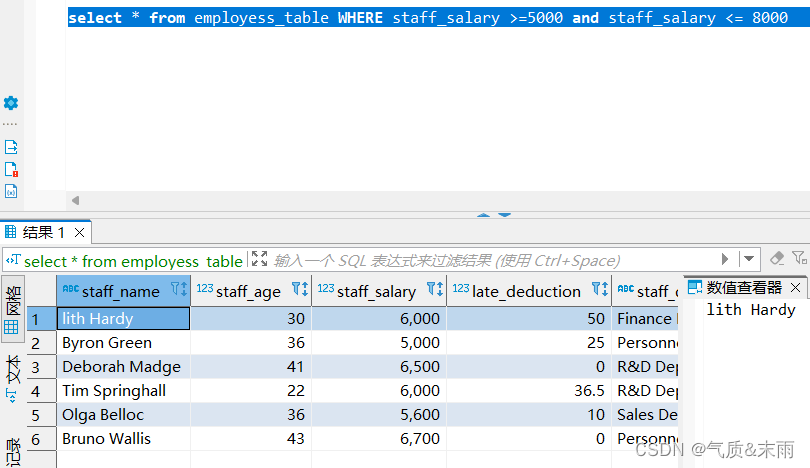
输入命令: select * from employess_table where staff_salary>=5000 and staff_salary <= 8000 查询出有六条信息
复杂运算符用于操作Hive集合数据类型的列,集合数据类型包括array(数据),map,或struct 下面通过一张表来介绍Hive内置的复杂运算符

先输入命令: select * from student_exam_table 查看表里的志愿一共有多少个
可以看到intent_university 字段是用字典装的,一个学生有三个志愿
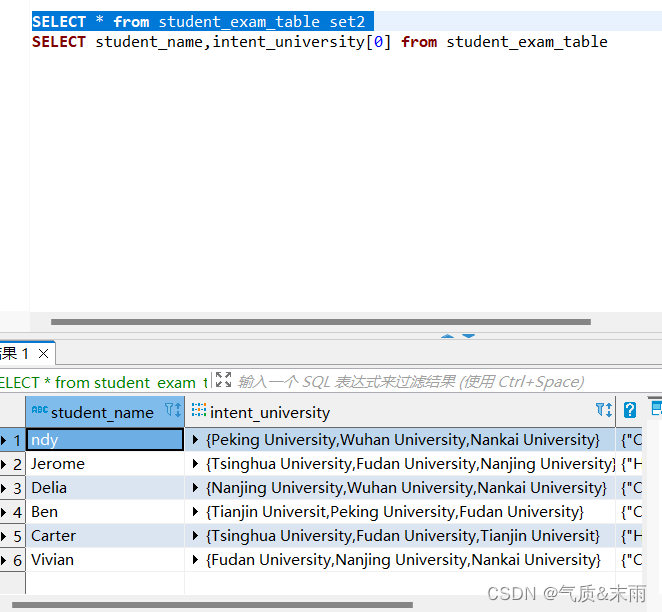
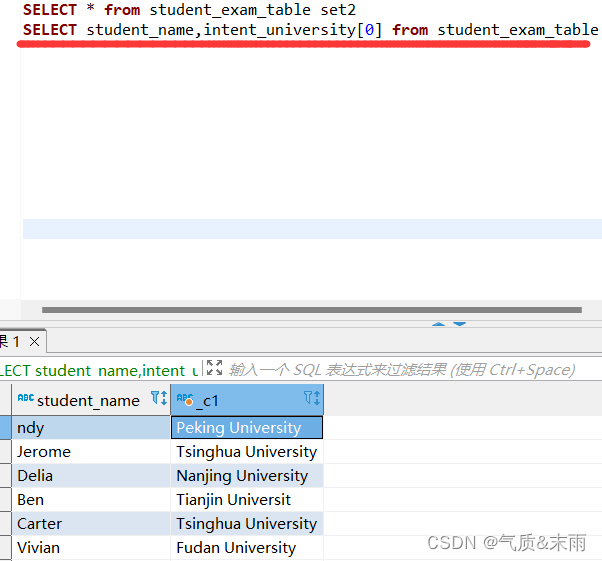
输入命令: select student_name,intent_university[0] from student_exam_table
取出intent_university 字段字典中的第一个元素,就是学生的第一个志愿 用到了复杂运算符中的复杂数据类型 array
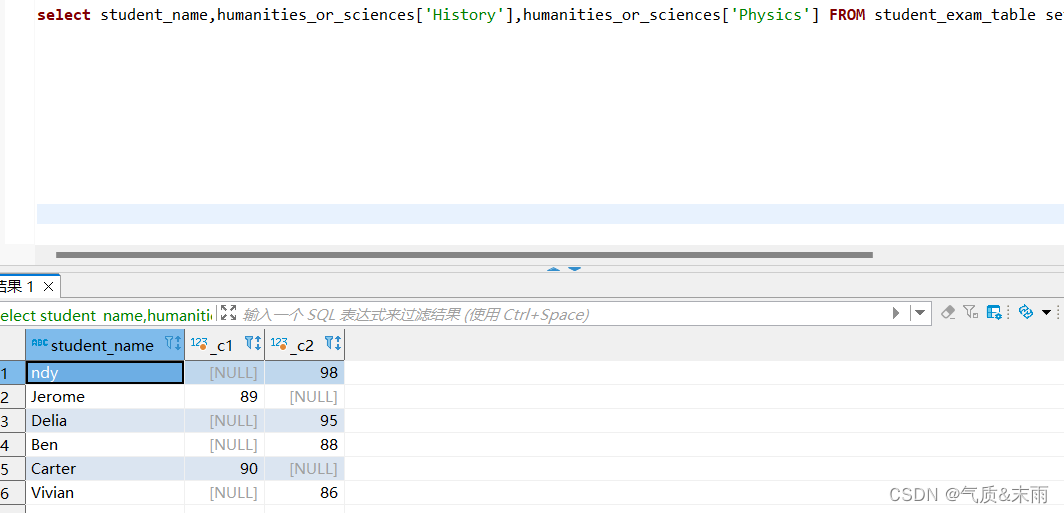
输入命令:select student_name,humanities_or_sciences[‘History’],humanities_or_sciences[‘Physics’] from student_exam_table 这样就查询出了 物理和历史科目的成绩 用到了复杂运算符中的map M[key],返回括号里的key指定的value值
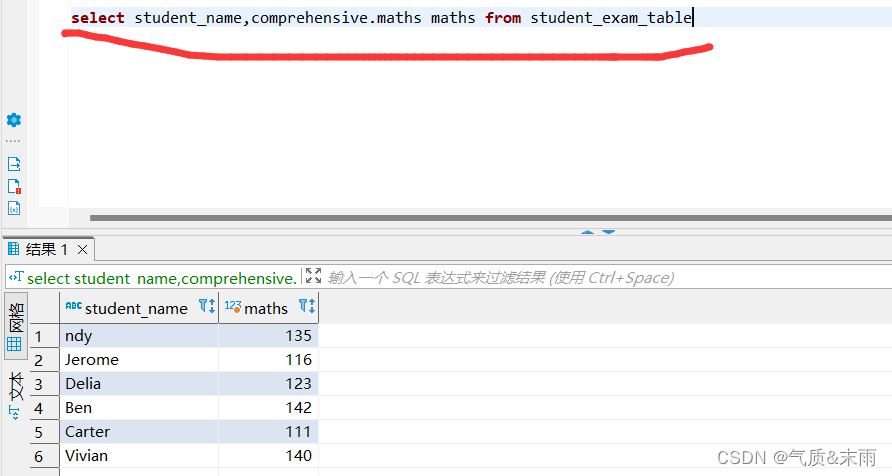
数学成绩是在comprehensive 这个字段里
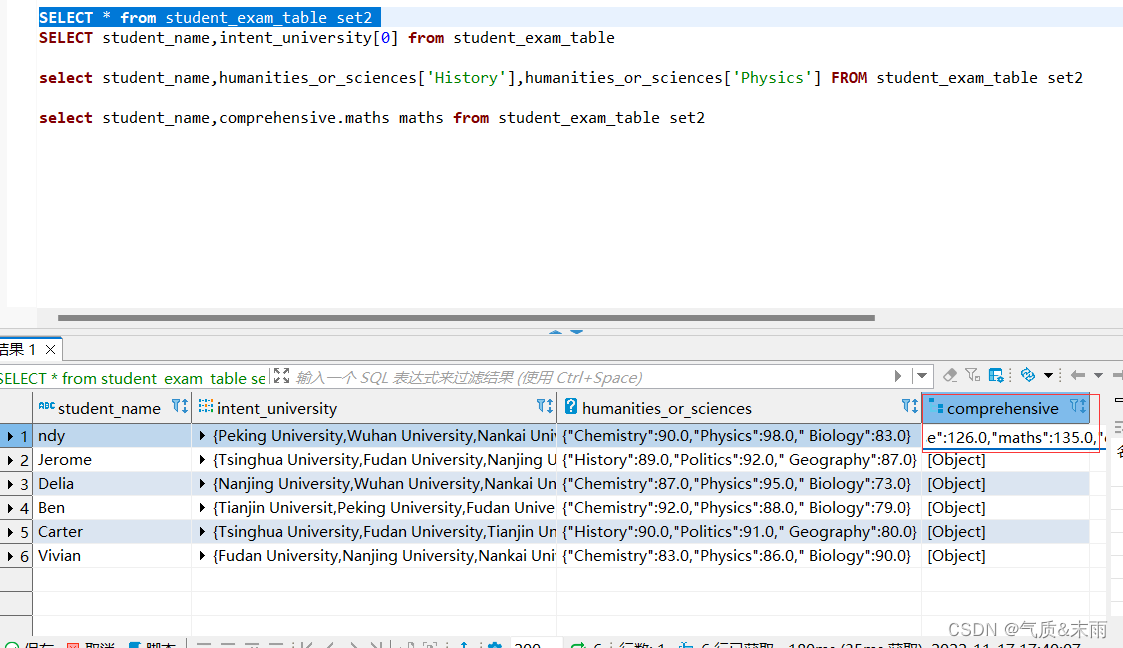
输入命令:select student_name,comprehensive.maths maths from student_exam_table comprehensive.maths 将这个字段下的maths取出,进行查询就查出来了所有的数学成绩
分组操作是按照数据表某一列或多列的值进行分组,将相同的值放在一组,执行操作时触发MapReduce 任务进行处理,分组是通过select语句中的子句group by实现
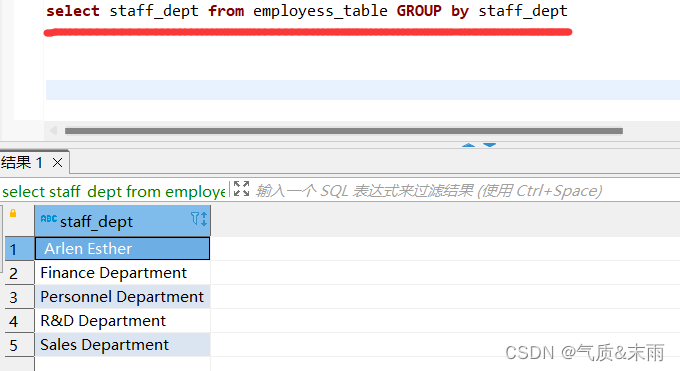
输入命令: select staff_dept from group by staff_dept 注意前面查询的字段一定要有后面分组的字段,不能直接*,后面没有条件判断的话也最好不要用where
order by 用来对查询结果进行全局排序,查询的结果集只会交由一个Reducer处理,如果查询的结果集数据量较大,建议order by 和 limlt子句一同使用,目的是为了控制全局排序的显示条数。
sort by 用来对查询结果做局部排序,根据Mapreduce默认划分Reducer个数的规则,将查询结果集交由多个Reduce处理,sort by 会对每个Reducer进行排序,每个Reducer中的数据都是有序的。
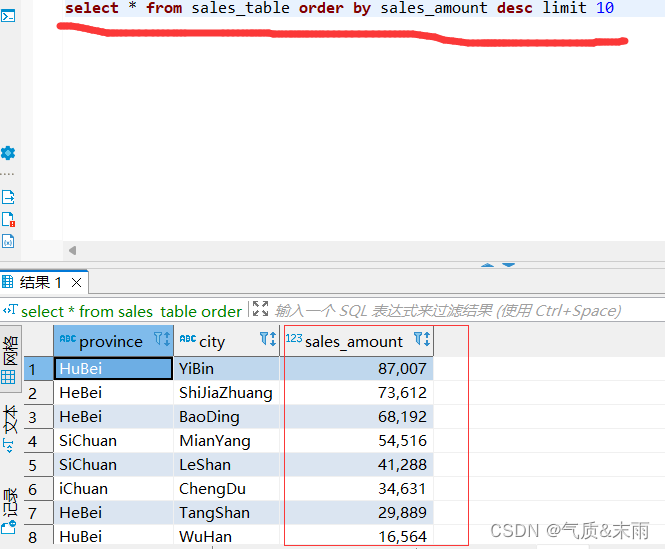
输入命令: select * from sales_table order by sales_amout desc limit 10 对销售表中的sales_amout字段进行全局排序,使用desc 进行倒序,使用limit方法只取前十条信息,注意后面要是没有条件的话就不要使用where,不然会报错。
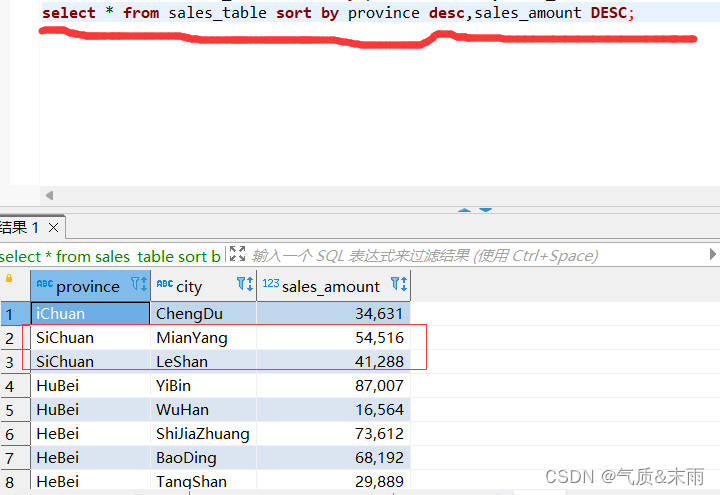
1、使用order by 全局排序,对province省份和sales_amount销售额进行降序,注意要同时对两个字段进行排序。
输入命令: select * from sales_table order by province desc,sales_amount desc; 这个和下面的局部排序的效果是一样的。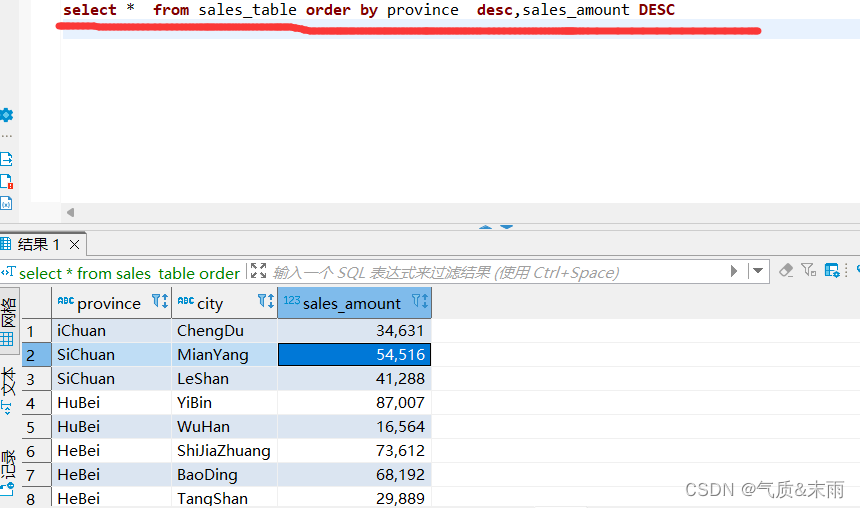
2、使用sort by 局部排序,对province省份和sales_amount销售额进行降序,注意要同时对两个字段进行排序。
输入命令: select * from sales_table sort by province desc,sales_amount desc;
1、升序(ASC) 降序(DESC)
升序排列与降序排列的区别在于数据的排列方式不同,它们在数值类型数据,字符串数据类型和时间数据类型上的排列方式都有所不同。
2、Cluster by
Cluster by可以看作是disribute by 和 sort by 的合集,若distribute by 和 sort by 指定的列名一致,则可以使cluster by 代替,不过cluster by默认只允许升序排列,不支持降序
union语句 用于将多个select句式的结果合并为一个结果集,合并数据
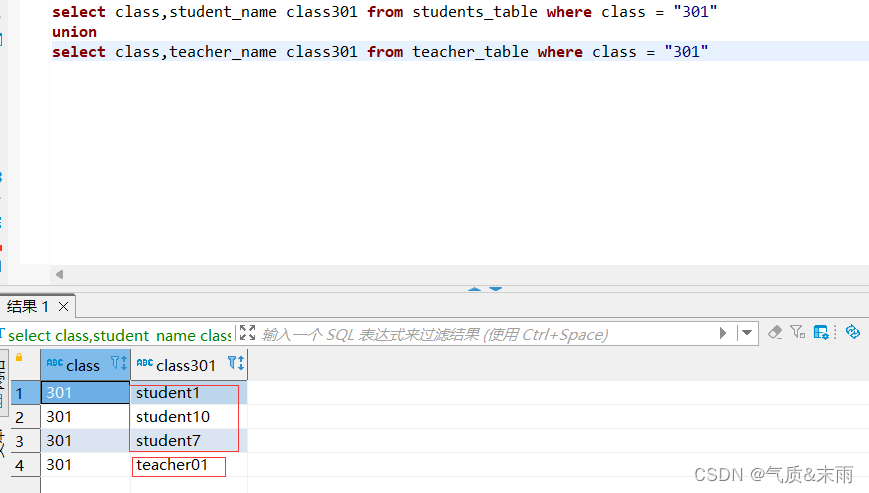
输入命令:select class,student_name class301 from students_table where class = “301” union select class,teacher_name class301 from teacher_table where class = “301”
先把学生表中的数据 中的教室字段用where 查询出来301教室的信息,然后把教室的那个字段别名改为class301 然后教师表一样的操作,两个表的查询完成用 union 进行连接,就合并起来了
join语句主要是基于两个或者多个表列之间的关系,将这些表进行连接
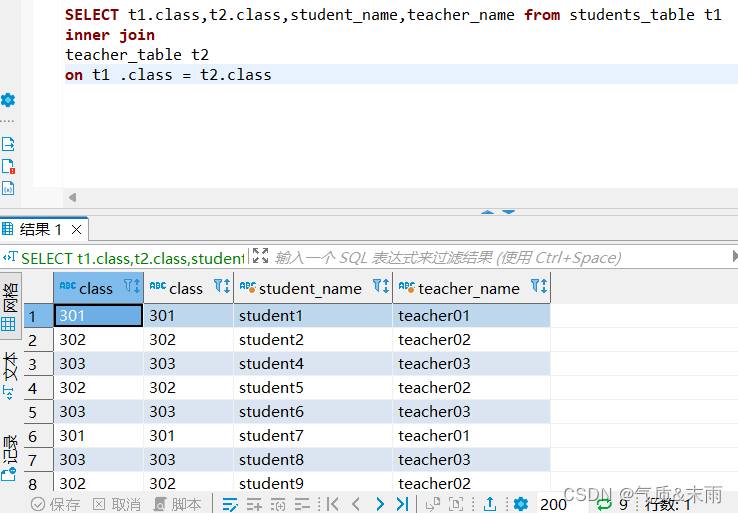
输入命令: select t1.class,t2.class,stdudent_name,teacher_name from students_table t1 inner join
teacher_table t2 on t1.class = t2.class
先进行查询学生表的class字段和教师表的class字段然后给两个表进行别名,学生表为t1,教师表为t2然后 使用 inner join 进行内连接 教师表 然后用 on 两个表相同的字段进行相等 t1.class=t2.class
注意使用join进行多表关联,一定要有相同的字段 内连接连接两个表都有的相同的字段,里面都有的数据,才会显示出来,比如学生表没有304这个教室,而教师表有那么连接两个表这个就不会显示,只会显示两个表都有的
使用join语句的左外连接,连接学生名单表和教师名单表
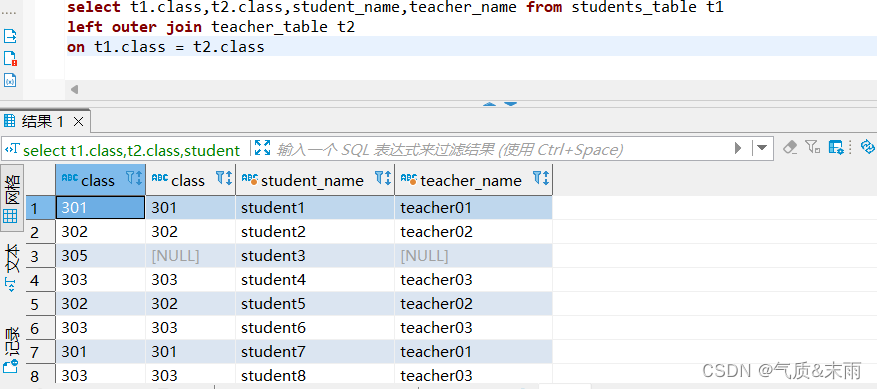
输入命令:select t1.class,t2.class,student_name,teacher_name from students_table left outer join teacher_table on t1.class = t2.class
使用左外连接大致和内连接相似,但是连接的语句 使用 left outer join 左外连接 使用左连接就是以左边的那个表为基准,比如class那个字段两个表都有,但是只有学生表有305,但是教师表没有305这个教室,那么只会显示学生表的,教师表的305教室为显示为空
输入命令:select t1.class,t2.class,student_name,teacher_name from students_table t1 right outer
join teacher_table t2 on t1.class = t2.class
使用右外连接大致和内连接相似,但是连接的语句 使用 right outer join 右外连接 使用右连接就是以右边的那个表为基准,比如class那个字段两个表都有,但是学生表没有304,但是教师表有305这个教室,那么只会显示教师表的,学生表的305教室会显示为空
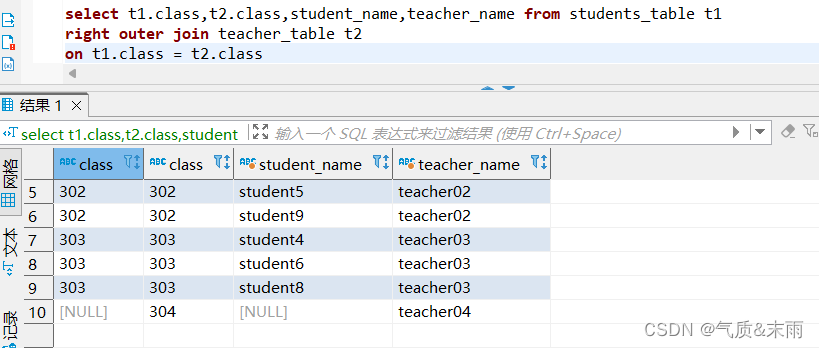
使用join语句的全外连接,连接学生名单表和教室名单表
输入命令:select t1.class,t2.class,student_name,teacher_name from students_table t1 full outer join teacher_table t2 on t1.class = t2.class
使用全外连接,连接的关键字是 full outer join 全外连接 ,使用全外连接会把两个表的数据都查出来,然后哪个表没有那个数据就会显示为空
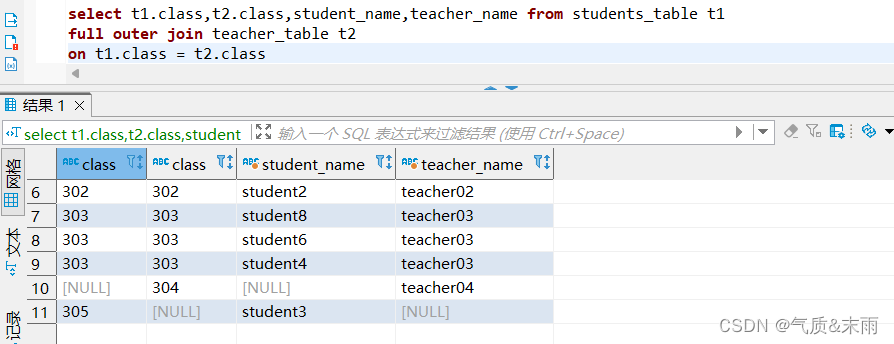
使用join语句的左边连接,连接学生名单表和教室名单表
输入命令:select t1.class,student_name from students_table t1 left semi join teacher_table t2 on t1.class = t2.class
使用左边连接 要使用关键字 left semi join 左半连接 前面select 要查询的字段的时候只会有左边那个表的字段,不然会报错,查询也只会查出左边那个表有的信息
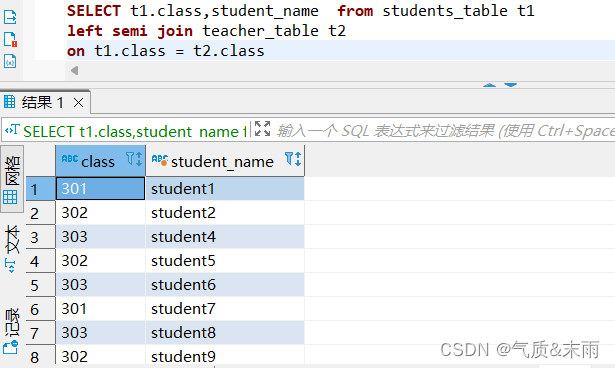
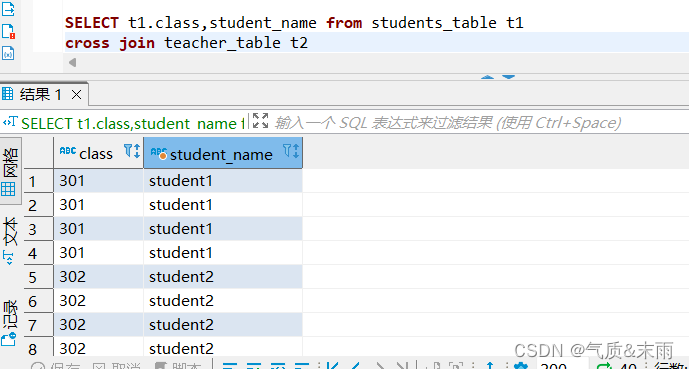
使用join语句的笛卡尔积连接,连接学生名单表和教师名单表
输入命令:select t1.class,student_name from students_table t1 cross join teacher_table t2
使用笛卡尔积连接 使用关键字 cross join 笛卡尔积连接 只需要查询左表的字段然后 使用 cross join字段 连接右表就行了,连相同的字段相等都不用写 笛卡尔积连接会把两个表中相同字段的所有数据全部查询出来,而且两个表相同的数据他也会依次显示两遍出来
对于非常大的数据集,有时候用户需要使用的是一个具有代表性的查询结果,而不是全部查询结果,此时可以用hive抽样查询实现这个需求。hive抽样查询分为随机抽样,分桶抽样和数据块抽样。
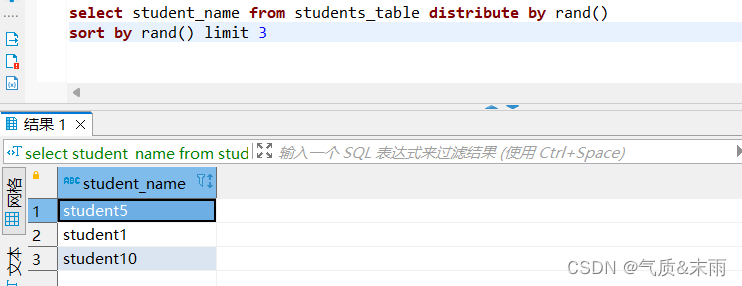
输入命令:select student_name from students_table distribute by rand() sort by rand() limlt 3
随机抽样 先使用 distribute by 和 sort by 进行排序 然后使用 hive 中的 rand()随机函数 加上 limit 3
随机取出三条学生信息
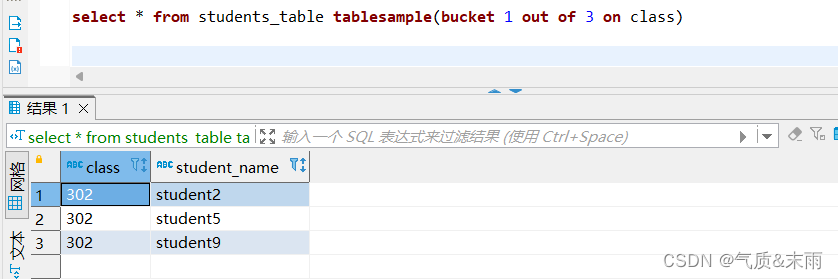
将学生名单表的数据按照班级分为三个桶,查询第一个桶中的数据
输入命令:select * from students_table tablesample(bucket 1 out of 3 on class)
分桶查询 tablesample 函数 backet 是要抽哪一个桶的数据 out of 3 是要 分成三个桶 on 是要分桶的字段 bucket 1 查询出第一个桶里面的数据
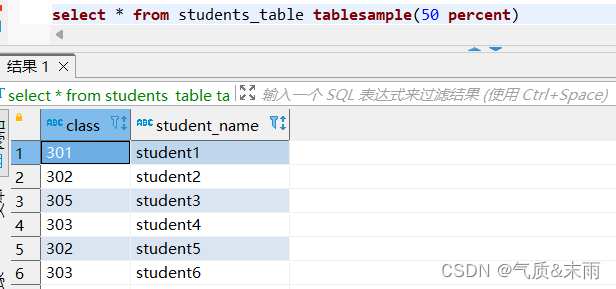
数据库抽样可以根据比例,行数和数据大小抽取hive表中的数据,这里所指的比例和数据大小是跟据hive表的数据文件计算的。
抽取学生名单表 50% 的数据
输入命令: select * from students_table tablesample(50 percent)
数据块抽样使用hive的 tablesample 函数, 里面的参数 50 percent 抽取百分之50的数据
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.