编写的python代码是在借鉴老师给的资料的基础上实现的
进行课堂实践:模仿bing搜索引擎域名收集功能,实现baidu搜索引擎的域名搜集功能时,走了不少弯路,最后终于形成了完整的思路。尤其是在“百度安全验证”问题上耗费的时间之久,就因为忽略了cookie的有效获取
import requests #用于请求网页资源
from bs4 import BeautifulSoup #用于处理获取的网页源码数据
from urllib.parse import urlparse #用于处理url
"""若没有这些模块,可在安装的python文件下执行命令“pip install requests”或“pip install bs4”或“pip install urllib.parse”进行下载"""
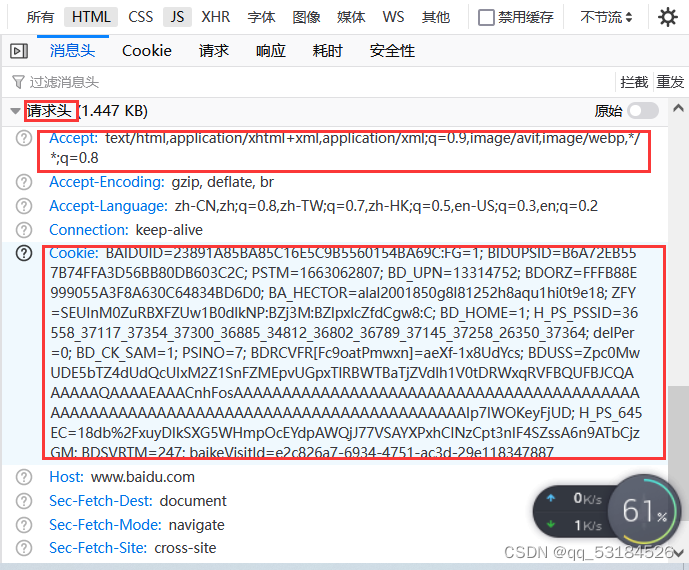
注意:在进行子域名搜集之前,请确保已登录百度,否则获取的cookie不起作用,其他搜索引擎同理
未登录时的界面

获取无效cookie的运行结果
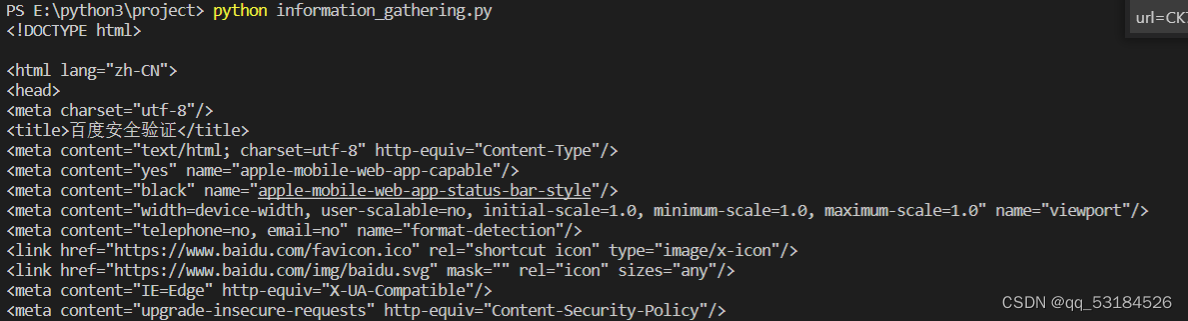
未登录时获取无效cookie来定义请求头,得到的响应内容为“百度安全验证”与“网络不给力,请稍后重试”、“返回首页”、“问题反馈”
出现此问题也还可能是请求头定义不完善被反爬了,从网上搜索的资料看大多是因为请求头缺少“Accept”
已登录后的界面



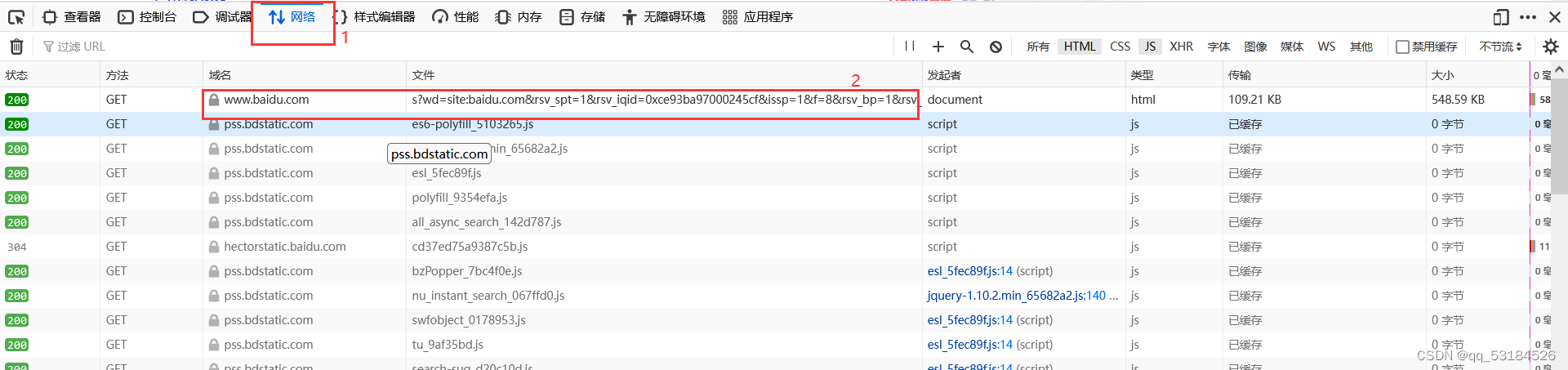
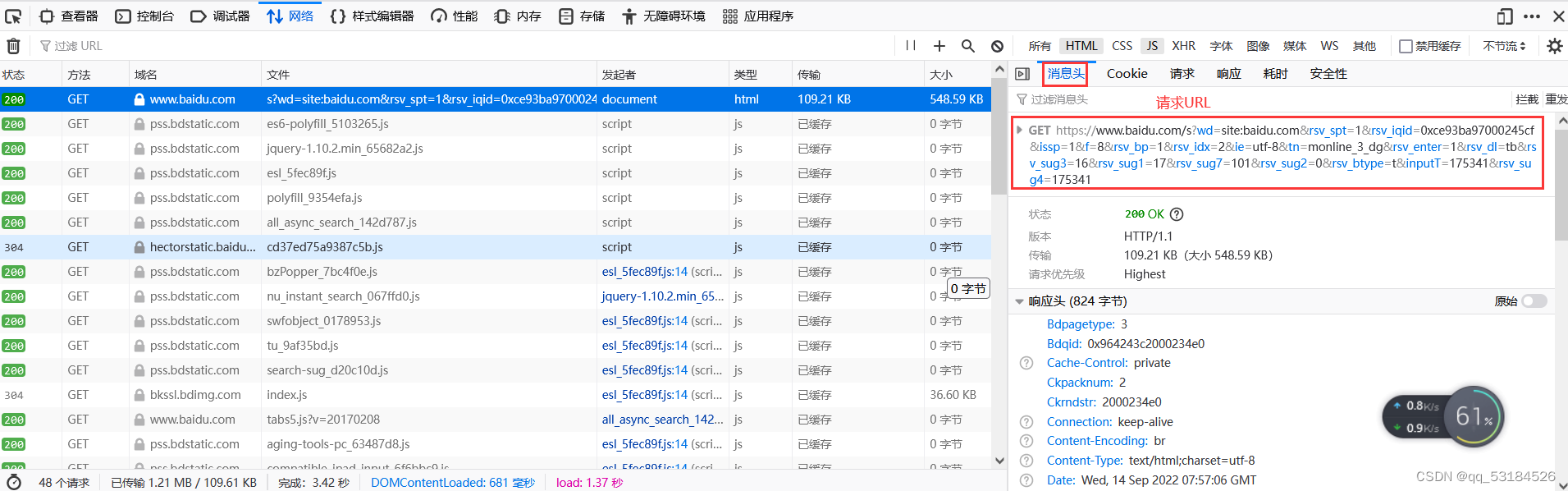
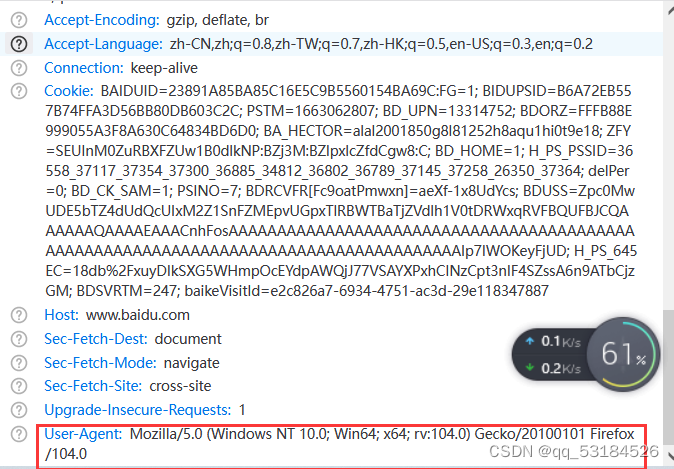
def baidu_search():
Subdomain2 = [] #定义一个空列表用于存储收集到的子域名
#定义请求头,绕过反爬机制
hearders = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:104.0) Gecko/20100101 Firefox/104.0',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'referer':'', #该请求没有来源网页可不填
'cookie':'BAIDUID=23891A85BA85C16E5C9B5560154BA69C:FG=1; BIDUPSID=B6A72EB557B74FFA3D56BB80DB603C2C; PSTM=1663062807; BD_UPN=13314752; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; BA_HECTOR=alal2001850g8l81252h8aqu1hi0t9e18; ZFY=SEUInM0ZuRBXFZUw1B0dlkNP:BZj3M:BZlpxlcZfdCgw8:C; BD_HOME=1; H_PS_PSSID=36558_37117_37354_37300_36885_34812_36802_36789_37145_37258_26350_37364; delPer=0; BD_CK_SAM=1; PSINO=7; BDRCVFR[Fc9oatPmwxn]=aeXf-1x8UdYcs; BDUSS=Zpc0MwUDE5bTZ4dUdQcUIxM2Z1SnFZMEpvUGpxTlRBWTBaTjZVdlh1V0tDRWxqRVFBQUFBJCQAAAAAAQAAAAEAAACnhFosAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIp7IWOKeyFjUD; H_PS_645EC=18db%2FxuyDIkSXG5WHmpOcEYdpAWQjJ77VSAYXPxhCINzCpt3nIF4SZssA6n9ATbCjzGM; BDSVRTM=247; baikeVisitId=e2c826a7-6934-4751-ac3d-29e118347887'
}
#定义请求url
url = "https://www.baidu.com/s?wd=site:baidu.com&rsv_spt=1&rsv_iqid=0xce93ba97000245cf&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=monline_3_dg&rsv_enter=1&rsv_dl=tb&rsv_sug3=16&rsv_sug1=17&rsv_sug7=101&rsv_sug2=0&rsv_btype=t&inputT=175341&rsv_sug4=175341"
resp = requests.get(url,headers=hearders) #访问url,获取网页源码
#print(resp.content.decode())等价于print(soup),变量soup在下面定义,是解析过的网页内容
soup = BeautifulSoup(resp.content,'html.parser') #创建一个BeautifulSoup对象,第一个参数是网页源码,第二个参数是Beautiful Soup 使用的 HTML 解析器,
#print(soup)
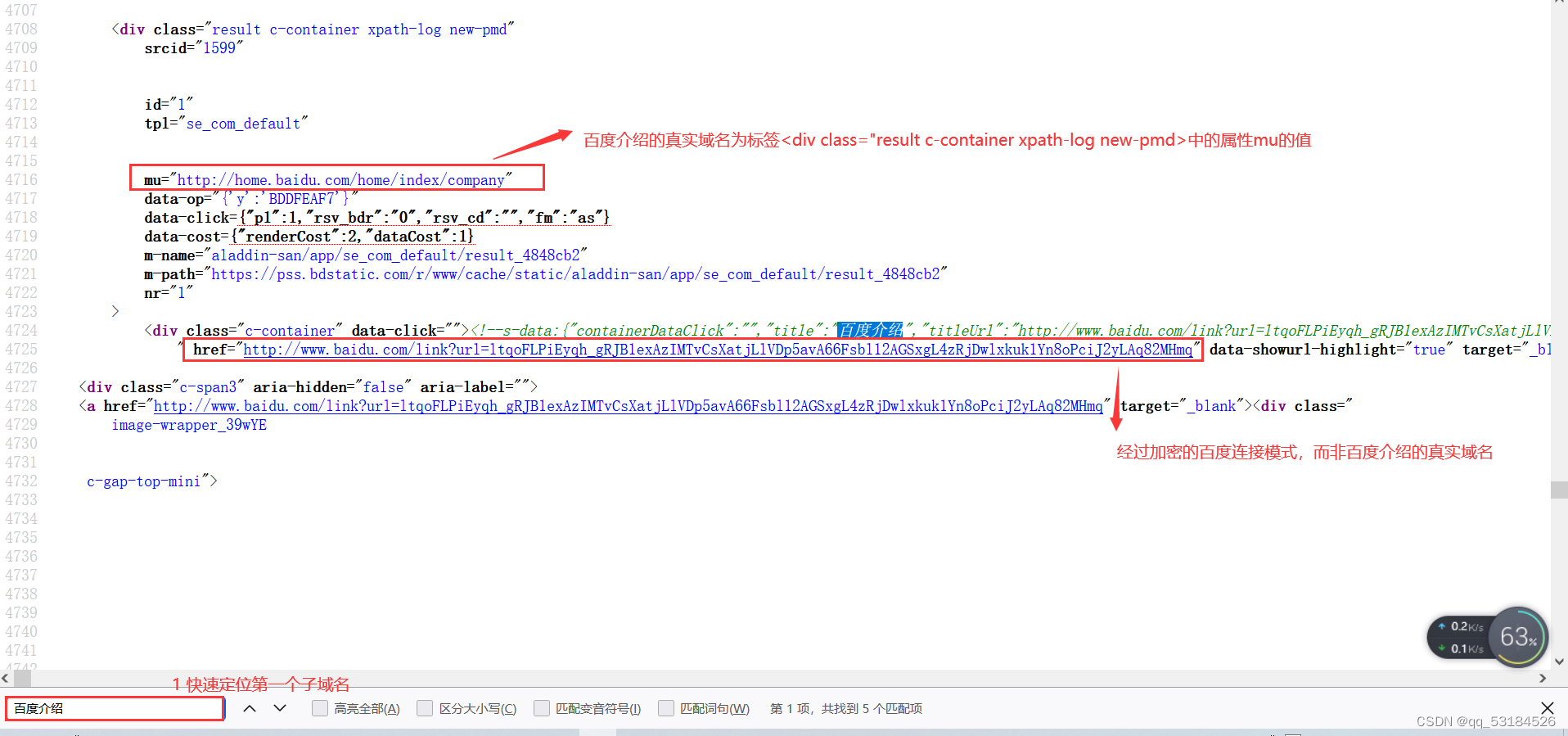
job_bt = soup.find_all('div',class_="result c-container xpath-log new-pmd") #find_all()查找源码中所有<div class_="result c-container xpath-log new-pmd"> 标签的内容
for i in job_bt: #遍历获取的标签
link = i.get('mu') #获取属性mu的值
#urlparse是一个解析url的工具,scheme获取url的协议名,netloc获取url的网络位置
domain = str(urlparse(link).scheme + "://" + urlparse(link).netloc)
if domain in Subdomain2: #如果解析后的domain存在于Subdomain2中则跳过,否则将domain存入子域名表中
pass
else:
Subdomain2.append(domain)
print(domain)
#调用函数baidu_search()
baidu_search()
运行结果

优化:给获取的子域名添加描述
查看网页源码,找到子域名描述的位置

#子域名的描述在标签<div class="result c-container xpath-log new-pmd">下的标签<div class="c-container">下的标签<h3>下的标签<a>的“标题”中
#获取标签“<a>"的“标题”的方法为get_text()
代码
for i in job_bt: #遍历获取的标签
link = i.get('mu') #获取属性mu的值
#获取子域名的描述,注意:变量的命名不可与关键字、方法名等重叠,否则会报错:"str" object is not callable
string=i.find('div',class_="c-container").find('h3').find('a').get_text()
#urlparse是一个解析url的工具,scheme获取url的协议名,netloc获取url的网络位置
domain = str(urlparse(link).scheme + "://" + urlparse(link).netloc)
if domain in Subdomain2: #如果解析后的domain存在于Subdomain2中则跳过,否则将domain存入子域名表中
pass
else:
Subdomain2.append(domain)
print(domain+'\t'+string) #输出进行字符串拼接
运行结果:

关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我希望我的UserPrice模型的属性在它们为空或不验证数值时默认为0。这些属性是tax_rate、shipping_cost和price。classCreateUserPrices8,:scale=>2t.decimal:tax_rate,:precision=>8,:scale=>2t.decimal:shipping_cost,:precision=>8,:scale=>2endendend起初,我将所有3列的:default=>0放在表格中,但我不想要这样,因为它已经填充了字段,我想使用占位符。这是我的UserPrice模型:classUserPrice回答before_val
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search